







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
numeric_features = train.dtypes[train.dtypes != ‘object’].index
计算每个特征的离群样本
for feature in numeric_features:
outs = detect_outliers(train[feature], train[‘SalePrice’],top=5, plot=False)
all_outliers.extend(outs)
输出离群次数最多的样本
print(Counter(all_outliers).most_common())
剔除离群样本
train = train.drop(train.index[outliers])
detect_outliers()是自定义函数,用sklearn库的LocalOutlierFactor算法计算离群点。
到这里, EDA 就完成了。最后,将训练集和测试集合并,进行下面的特征工程。
y = train.SalePrice.reset_index(drop=True)
train_features = train.drop([‘SalePrice’], axis=1)
test_features = test
features = pd.concat([train_features, test_features]).reset_index(drop=True)
features合并了训练集和测试集的特征,是我们下面要处理的数据。
二. 特征工程
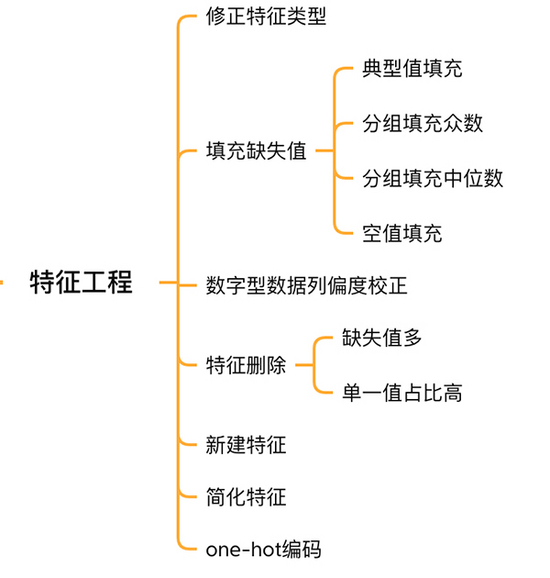
特征工程
2.1 校正特征类型
MSSubClass(房屋类型)、YrSold(销售年份)和MoSold(销售月份)是类别型特征,只不过用数字来表示,需要将它们转成文本特征。
features[‘MSSubClass’] = features[‘MSSubClass’].apply(str)
features[‘YrSold’] = features[‘YrSold’].astype(str)
features[‘MoSold’] = features[‘MoSold’].astype(str)
2.2 填充特征缺失值
填充缺失值没有统一的标准,需要根据不同的特征来决定按照什么样的方式来填充。
# Functional:文档提供了典型值 Typ
features[‘Functional’] = features[‘Functional’].fillna(‘Typ’) #Typ 是典型值
分组填充需要按照相似的特征分组,取众数或中位数
MSZoning(房屋区域)按照 MSSubClass(房屋)类型分组填充众数
features[‘MSZoning’] = features.groupby(‘MSSubClass’)[‘MSZoning’].transform(lambda x: x.fillna(x.mode()[0]))
#LotFrontage(到接到举例)按Neighborhood分组填充中位数
features[‘LotFrontage’] = features.groupby(‘Neighborhood’)[‘LotFrontage’].transform(lambda x: x.fillna(x.median()))
车库相关的数值型特征,空代表无,使用0填充空值。
for col in (‘GarageYrBlt’, ‘GarageArea’, ‘GarageCars’):
features[col] = features[col].fillna(0)
2.3 偏度校正
跟探索SalePrice列类似,对偏度高的特征进行平滑。
# skew()方法,计算特征的偏度(skewness)。
skew_features = features[numeric_features].apply(lambda x: skew(x)).sort_values(ascending=False)
取偏度大于 0.15 的特征
high_skew = skew_features[skew_features > 0.15]
skew_index = high_skew.index
处理高偏度特征,将其转化为正态分布,也可以使用简单的log变换
for i in skew_index:
features[i] = boxcox1p(features[i], boxcox_normmax(features[i] + 1))
2.4 特征删除和新增
对于几乎都是缺失值,或单一取值占比高(99.94%)的特征可以直接删除。
features = features.drop([‘Utilities’, ‘Street’, ‘PoolQC’,], axis=1)
同时,可以融合多个特征,生成新特征。
有时候模型很难学习到特征之间的关系,手动融合特征可以降低模型学习难度,提升效果。
# 将原施工日期和改造日期融合
features[‘YrBltAndRemod’]=features[‘YearBuilt’]+features[‘YearRemodAdd’]
将地下室面积、1楼、2楼面积融合
features[‘TotalSF’]=features[‘TotalBsmtSF’] + features[‘1stFlrSF’] + features[‘2ndFlrSF’]
可以发现,我们融合的特征都是与SalePrice强相关的特征。
最后简化特征,对分布单调的特征(如:100个数据中有99个的数值是0.9,另1个是0.1),进行01处理。
features[‘haspool’] = features[‘PoolArea’].apply(lambda x: 1 if x > 0 else 0)
features[‘has2ndfloor’] = features[‘2ndFlrSF’].apply(lambda x: 1 if x > 0 else 0)
2.6 生成最终训练数据
到这里特征工程就做完了, 我们需要从features中将训练集和测试集重新分离出来,构造最终的训练数据。
X = features.iloc[:len(y), :]
X_sub = features.iloc[len(y):, :]
X = np.array(X.copy())
y = np.array(y)
X_sub = np.array(X_sub.copy())
三. 模型训练
因为SalePrice是数值型且是连续的,所以需要训练一个回归模型。
3.1 单一模型
首先以岭回归(Ridge) 为例,构造一个k折交叉验证模型。
from sklearn.linear_model import RidgeCV
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import KFold
kfolds = KFold(n_splits=10, shuffle=True, random_state=42)
alphas_alt = [14.5, 14.6, 14.7, 14.8, 14.9, 15, 15.1, 15.2, 15.3, 15.4, 15.5]
ridge = make_pipeline(RobustScaler(), RidgeCV(alphas=alphas_alt, cv=kfolds))
岭回归模型有一个超参数alpha,而RidgeCV的参数名是alphas,代表输入一个超参数alpha数组。在拟合模型时,会从alpha数组中选择表现较好某个取值。
由于现在只有一个模型,无法确定岭回归是不是最佳模型。所以我们可以找一些出场率高的模型多试试。
# lasso
lasso = make_pipeline(
RobustScaler(),
LassoCV(max_iter=1e7, alphas=alphas2, random_state=42, cv=kfolds))
#elastic net
elasticnet = make_pipeline(
RobustScaler(),
ElasticNetCV(max_iter=1e7, alphas=e_alphas, cv=kfolds, l1_ratio=e_l1ratio))
#svm
svr = make_pipeline(RobustScaler(), SVR(
C=20,
epsilon=0.008,
gamma=0.0003,
))
#GradientBoosting(展开到一阶导数)
gbr = GradientBoostingRegressor(…)
#lightgbm
lightgbm = LGBMRegressor(…)
#xgboost(展开到二阶导数)
xgboost = XGBRegressor(…)
有了多个模型,我们可以再定义一个得分函数,对模型评分。
#模型评分函数
def cv_rmse(model, X=X):
rmse = np.sqrt(-cross_val_score(model, X, y, scoring=“neg_mean_squared_error”, cv=kfolds))
return (rmse)
以岭回归为例,计算模型得分。
score = cv_rmse(ridge)
print(“Ridge score: {:.4f} ({:.4f})\n”.format(score.mean(), score.std()), datetime.now(), ) #0.1024
运行其他模型发现得分都差不多。
这时候我们可以任选一个模型,拟合,预测,提交训练结果。还是以岭回归为例
# 训练模型
ridge.fit(X, y)
模型预测
submission.iloc[:,1] = np.floor(np.expm1(ridge.predict(X_sub)))
输出测试结果
submission = pd.read_csv(“./data/sample_submission.csv”)
submission.to_csv(“submission_single.csv”, index=False)
submission_single.csv是岭回归预测的房价,我们可以把这个结果上传到 Kaggle 网站查看结果的得分和排名。
3.2 模型融合-stacking
有时候为了发挥多个模型的作用,我们会将多个模型融合,这种方式又被称为集成学习。
stacking 是一种常见的集成学习方法。简单来说,它会定义个元模型,其他模型的输出作为元模型的输入特征,元模型的输出将作为最终的预测结果。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
结果上传到 Kaggle 网站查看结果的得分和排名。
3.2 模型融合-stacking
有时候为了发挥多个模型的作用,我们会将多个模型融合,这种方式又被称为集成学习。
stacking 是一种常见的集成学习方法。简单来说,它会定义个元模型,其他模型的输出作为元模型的输入特征,元模型的输出将作为最终的预测结果。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-R0mHoyuK-1713448323687)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









