






 本文介绍了数据分析的六个步骤,包括数据集成、预处理、数据挖掘、可视化和汇报。数据预处理涉及数据清洗、标准化和规约,确保分析结果准确。MaxCompute作为云数据仓库,用于大规模数据分析。此外,文章还提到了多种数据分析方法,如5W2H分析、逻辑树分析和假设检验,以及数据对比和清洗技巧。最后,通过实际案例展示了如何在MaxCompute上进行数据操作和可视化分析。
本文介绍了数据分析的六个步骤,包括数据集成、预处理、数据挖掘、可视化和汇报。数据预处理涉及数据清洗、标准化和规约,确保分析结果准确。MaxCompute作为云数据仓库,用于大规模数据分析。此外,文章还提到了多种数据分析方法,如5W2H分析、逻辑树分析和假设检验,以及数据对比和清洗技巧。最后,通过实际案例展示了如何在MaxCompute上进行数据操作和可视化分析。
数据分析流程六步法
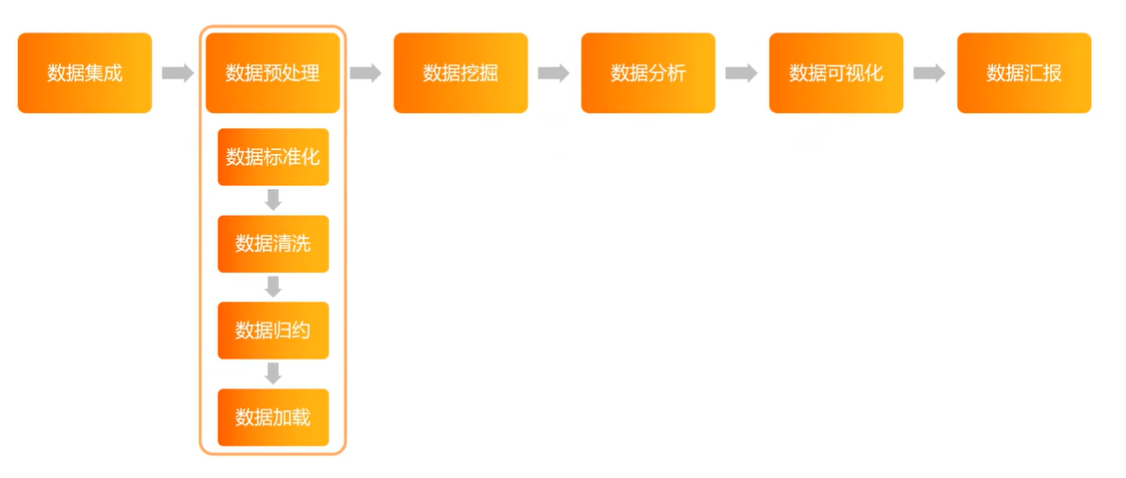
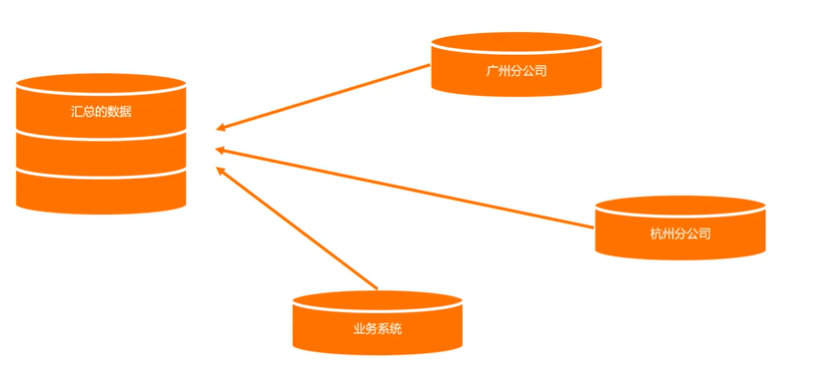
数据集成
数据预处理
数据标准化
统一数据标准
数据清洗
清洗脏数据
数据规约
减少数据样本数量
数据加载
再次保存
数据挖掘
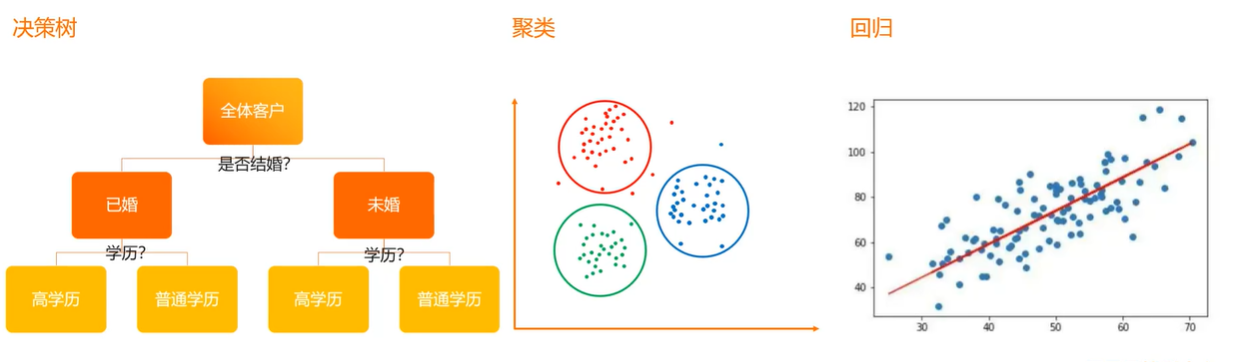
数据分析
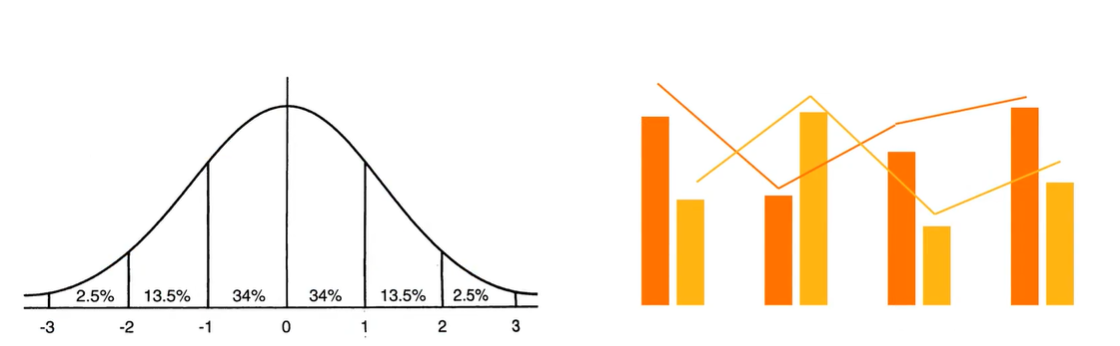
数据可视化

数据汇报

数据分析思维和方法
5W2H分析方法
通过设问抛出问题,再尝试回答问题从而分析问题的方法
5W是指对于所有的现象都追问5个问题:
what (是什么)、when (何时)、where (何地)、why (为什么)、who (是谁)
2H是指再追问2个问题:
how (怎么做)、how much (多少钱)。
5W2H分析方法可以帮助我们解决简单的问题,比如:
如何设计一款产品?
设计一款APP的调查问卷,如何设计问卷 上的问题?
5W2H分析方法很好理解,但是在复杂的商业问题面前不起作用。这是因为复杂的商业问题不会只有一个原因,而是由多个原因引起的。
逻辑树分析方法
将复杂问题分散化,一步步分解问题寻 找分析问题的简单方法
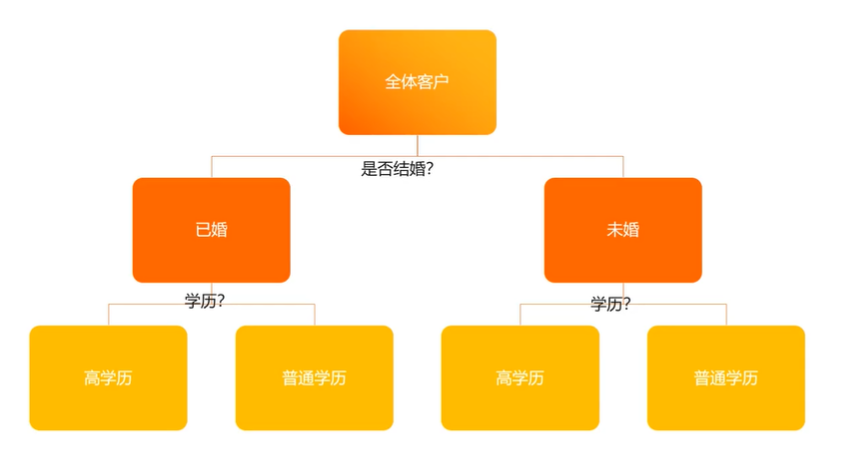
对比分析方法
广泛寻找不同的维度,在不同的维度上进行数据对比的方法
和谁比
和自己、和行业
如何比
较数据整体的大小:平均值、中位数、或某个业务指标数据整体的波动:标准差除以平均值得到的值叫作变异系数。变异系数可用来衡量
整体数据的波动情况。
趋势变化:趋势变化是从时间维度来看数据随着时间发生的变化。常用的方法是时间折线图、环比(和上-一个时间段对比,用于观察短期的数据集)和同比(与去年同一个时间段进行对比,用于观察长期的数据集)。
注意事项
在进行比较的时候,要注意比较对象的规模保持-致。
假设检验分析方法
万物先假设,尝试验证,通过验证结果分析问题
假设检验分析方法分为3步:
(1)提出假设
(2)收集证据
(3)得出结论
假设检验分析方法可以分析问题发生的原因,也叫作归因分析。
如何使用假设检验分析方法?
如何客观地提出假设?
可以从按用户、产品、竞品3个维度提出假设,来检查提出的假设是否有遗漏。
(1)假设用户有问题:可以从用户来源渠道这个维度来拆解分析,或者画出用户使用产品的业务流程图来分析原因
(2)假设产品有问题:可以研究这段时间销售的产品是否符合用户的需求
(3)假设是竞品导致的问题:可以看竞品是不是在搞什么优惠活动,用户跑到竞争对手那里了
我们还可以从4P营销理论出发来提出假设:产品(product) 、价格(price)、渠道(place) 、促销(promotion)
学会分析需求,观察模拟数据
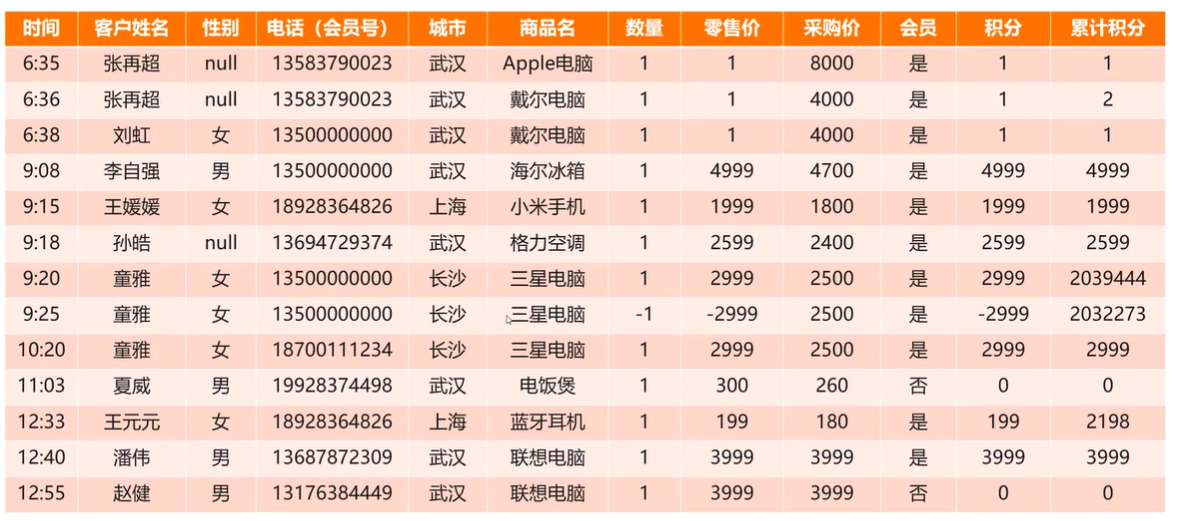
案例:统计销售数量和电脑的平均单价
数据预处理的必要性和方法
为什么要做数据预处理?
为了保证分析结果正确
GIGO原则(Garbage In Garbage Out)
不能为分析目标产生价值的数据称为脏数据
数据质量六大要素:完整性、唯一性、及时性、有效性、准确性、一致性
有效性与准确性的区分
有效性:数据格式错误
准确性:数据格式正确,但不合常理
有哪些脏数据
空缺值
未填写或未填写造成的默认值
无意义值
包括录入错误、统计维度错误、计算错误、无关数据
噪声数据
不符合逻辑的值,或因为某些特殊情况产生的数据
数据清洗保证数据质量
常见数据清洗的方法
编程法
如: Python、 Java、 C、PHP等
Excel法常用函数和查找替换
如: VLOOKUP、COUNTIFS、 查找与替换功能
Excel手动计算填充(平均数,中位数,众数填充,默认值填充)
如: AVERAGE、MEDIAN、 MODE
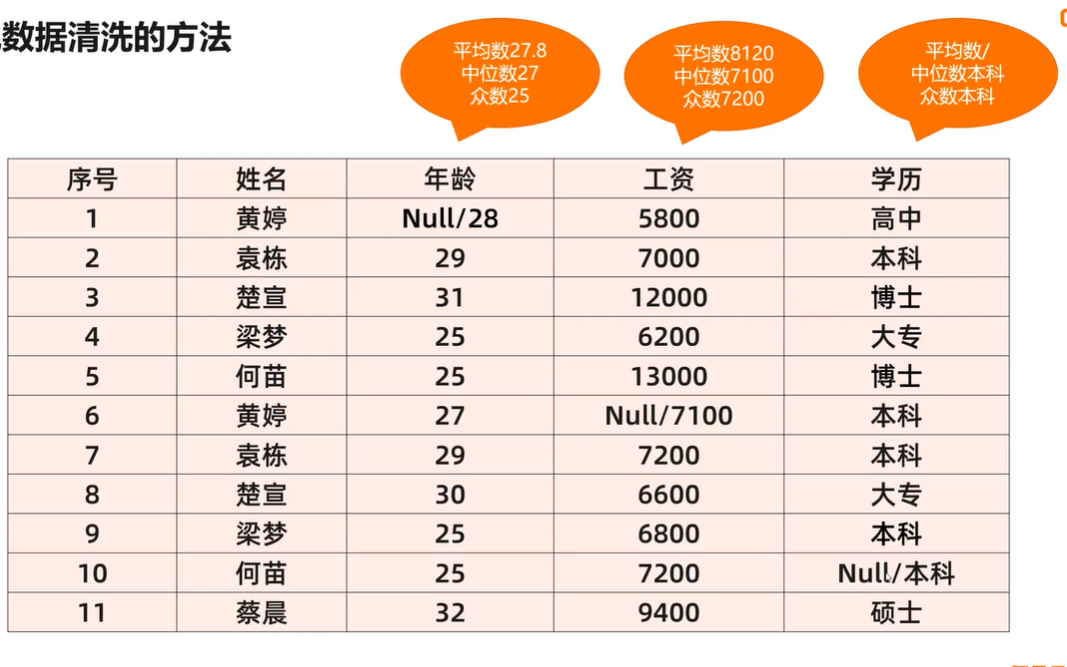
数据特征
中位数
一些数据中从小到大顺序排列时,正中间的数据叫做中位数,不受最大值和最小值的小大波动,反映出真实的集中趋势
适用场景:全体员工的工资的代表性
平均数
通过全体数据的计算而得出的结果,具有整体水平的代表性,会随着每个数据的变化而变化,小范围数据比较适合适用平均数
适用场景:各个班级(门店)的平均成绩
众数
出现次数最多的数据,也不受到最大值最小值的变化影响,需要统计计数才能得出,能反应出多数数据代表的意义
适用场景:学历、评级等离散型数据的统计需求
常见数据清洗的方法
MaxCompute数据挖掘分析数据
什么是MaxCompute
MaxCompute是适用于数据分析场景的企业级SaaS (Software as a Service)模式云数据仓库,以Serverless架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您可以经济并高效地分析处理海量数据。

MaxCompute主要功能

MaxCompute位置
制作数据可视化并分享
QuickBI云上数据可视化分析
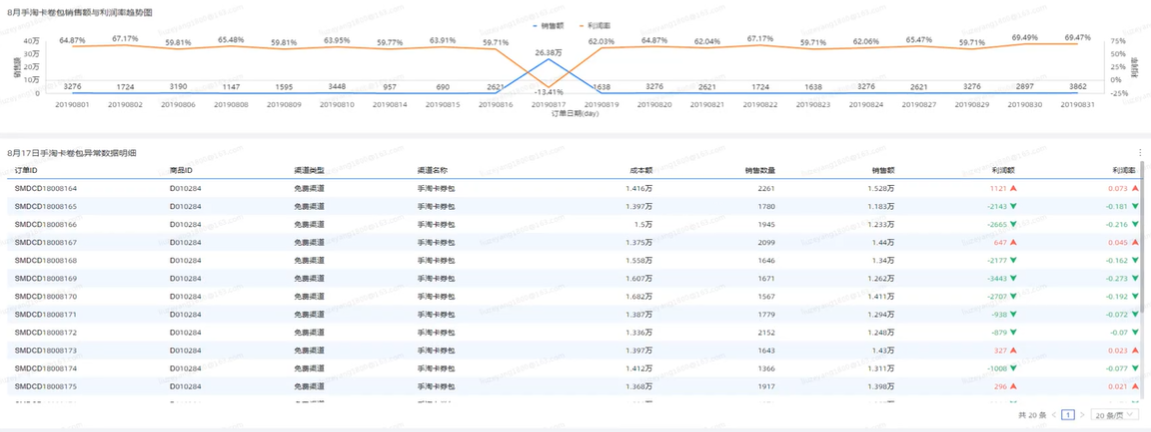
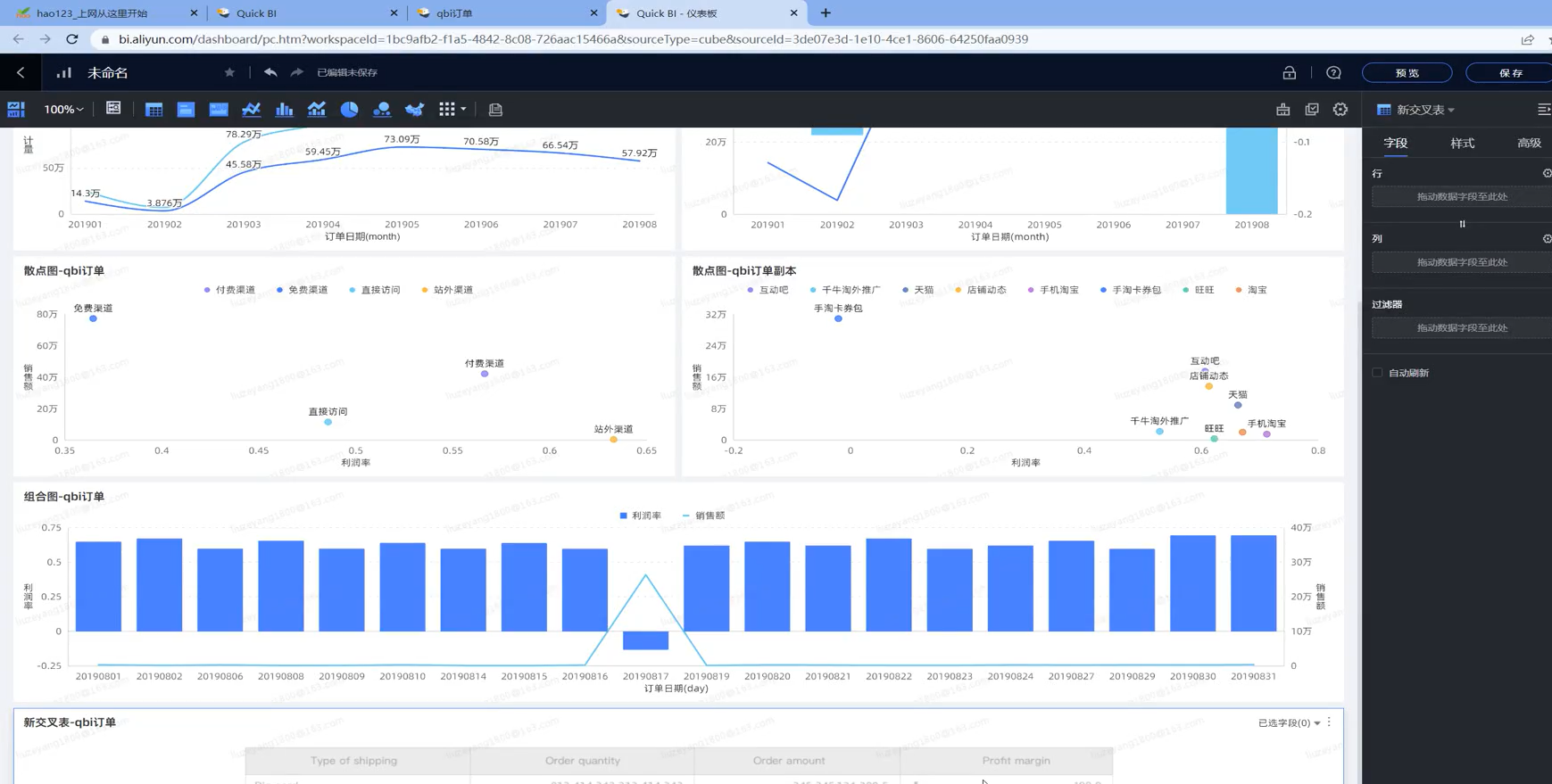
[实验] 基于MaxCompute的热门话题分析
创建资源
开始实验之前,您需要先创建实验相关资源。
在实验室页面,单击创建资源。
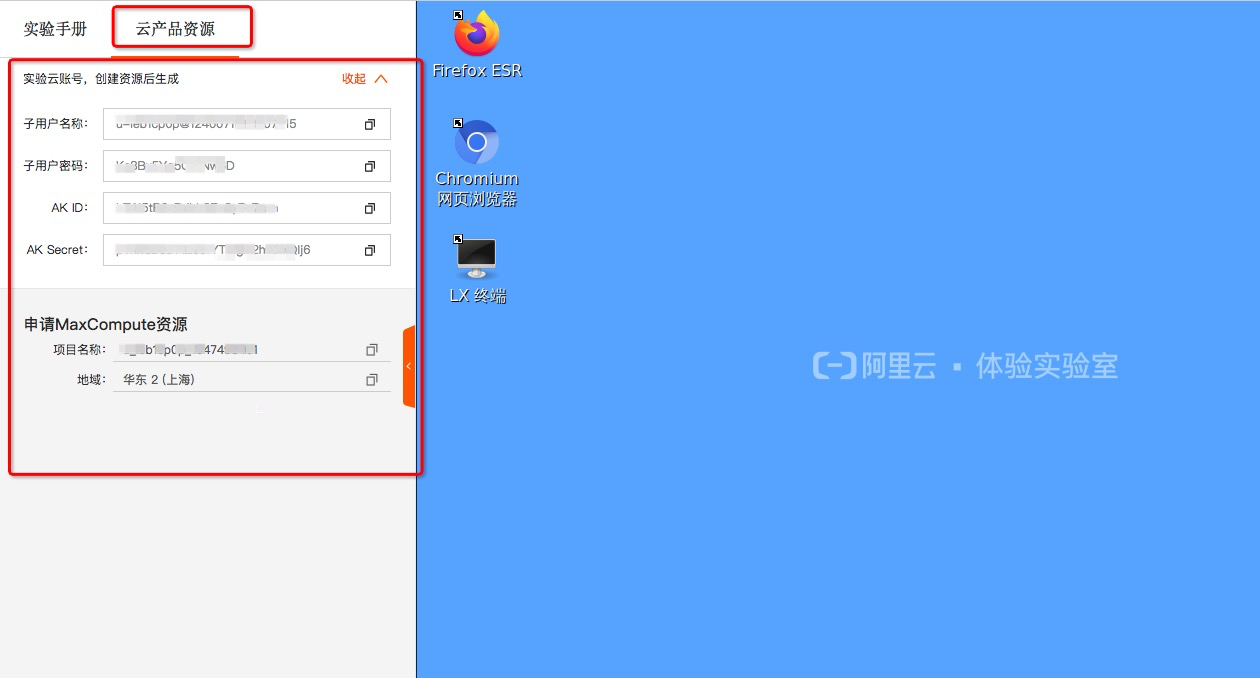
(可选)在实验室页面左侧导航栏中,单击云产品资源列表,可查看本次实验资源相关信息(例如IP地址、用户信息等)。
说明:资源创建过程需要3~5分钟。完成实验资源的创建后,您可以在 云产品资源 列表查看已创建的资源信息,例如:子用户名称、子用户密码、AK ID、AK Secret、资源中的项目名称等。
实验环境一旦开始创建则进入计时阶段,建议学员先基本了解实验具体的步骤、目的,真正开始做实验时再进行创建。
资源创建成功,可在左侧的资源卡片中查看相关资源信息以及RAM子账号信息
登录阿里云控制台
双击打开虚拟桌面的Chromium浏览器。
在RAM用户登录框中单击下一步,并复制粘贴页面左上角的子用户密码到用户密码输入框,单击登录。
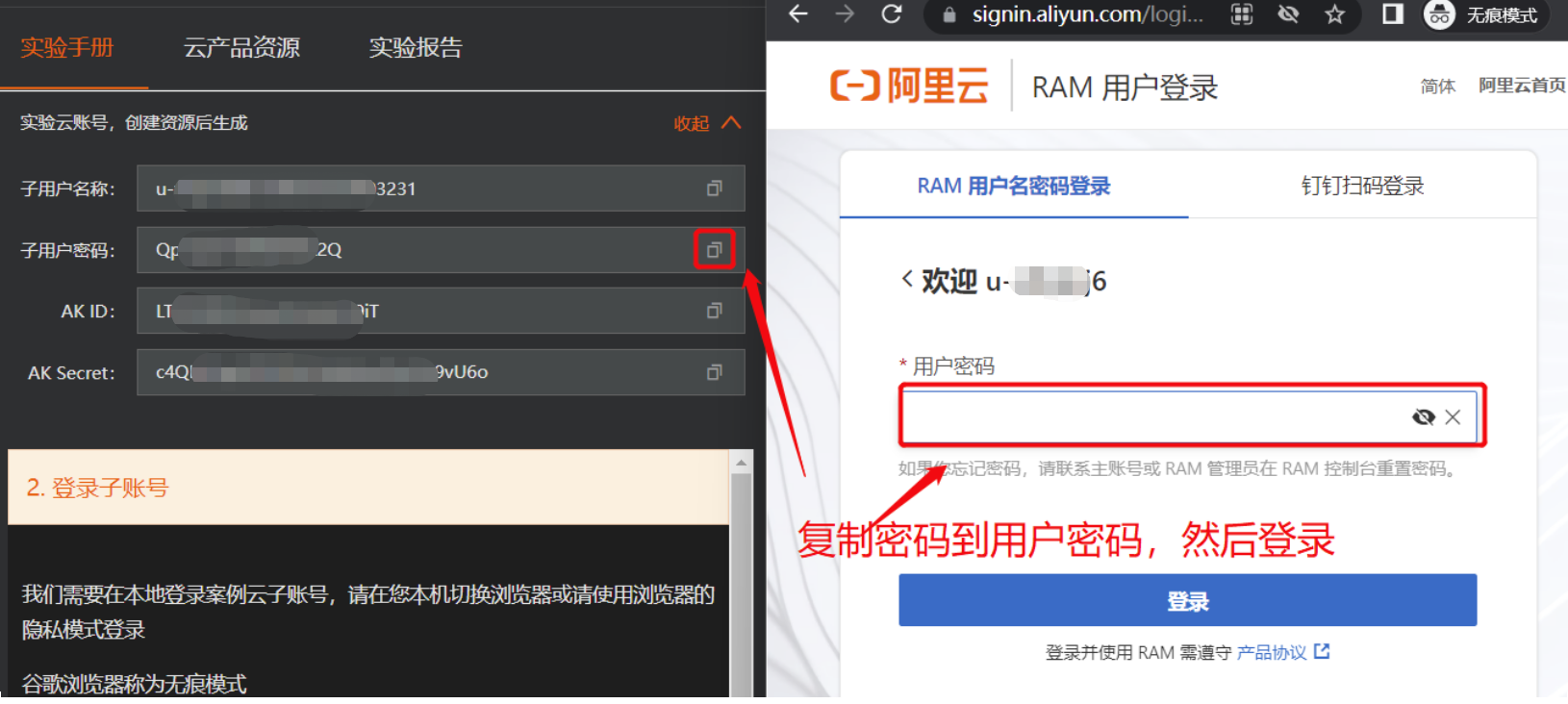
返回如下页面,表示您已成功登录阿里云控制台。
上传数据
上传数据之前需要先进入DataWorks控制台,创建表,再往表中导入数据。
首先我们进入DataWorks工作空间
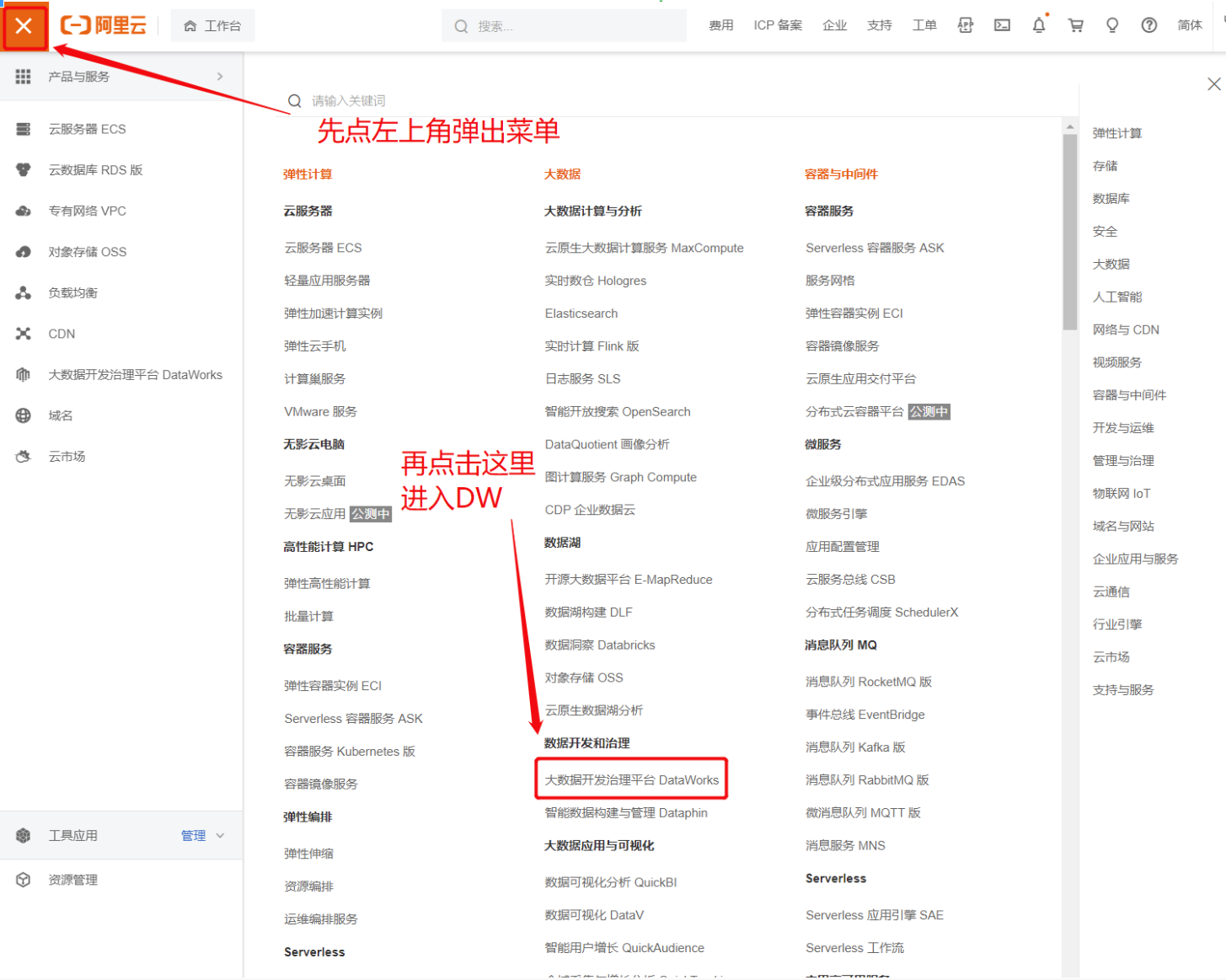
单击左上角的

图标,弹出菜单。
在菜单栏的中间部位,单击大数据开发治理平台DataWorks。
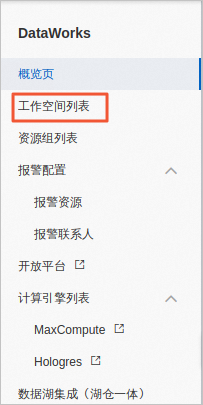
在左侧导航栏中,单击工作空间列表。
在工作空间列表页面顶部,选择资源所在地域。例如下图中,地域切换为华东2(上海)。
说明:您可在云资源产品列表中查看实验室分配的DataWorks资源所在地域。
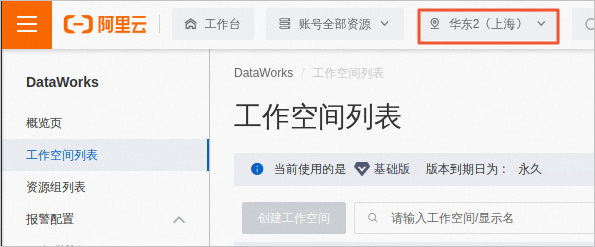
在工作空间列表页面,单击数据开发,进入开发界面。
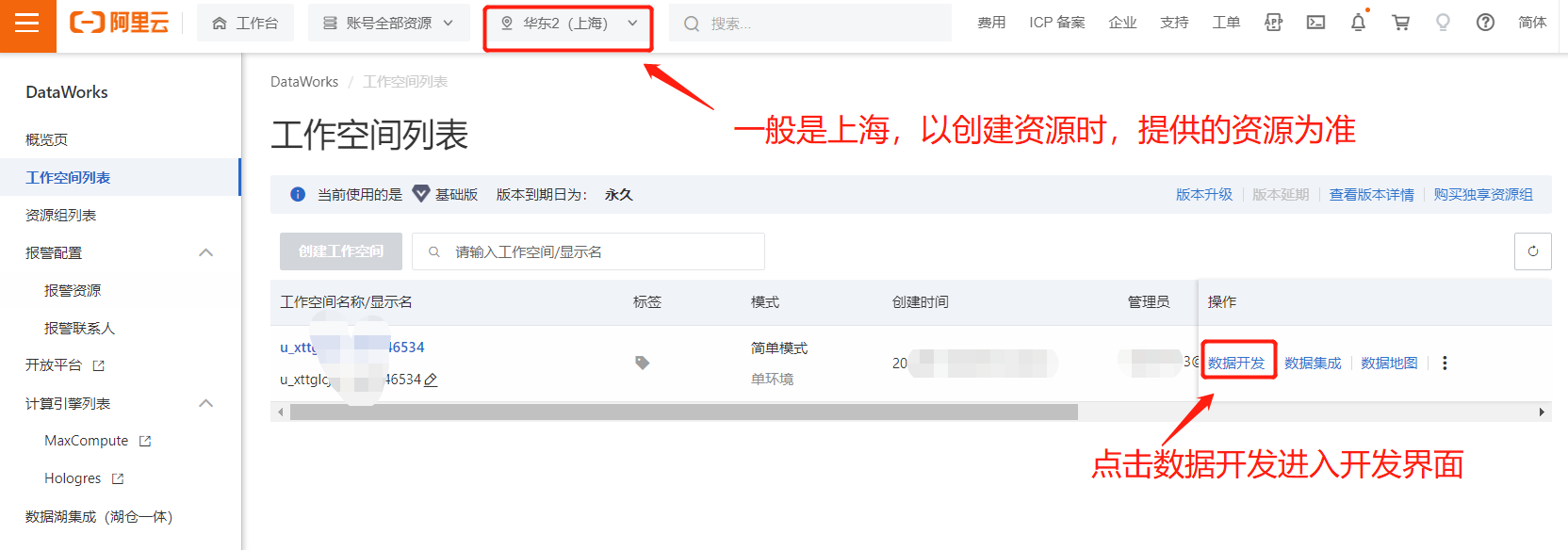
在数据开发页面,需要创建一个ODPS SQL查询,ODPS即MaxCompute的别名。
6.1 在左侧导航栏中,单击临时查询。
6.2 在临时查询面板,单击上方加号按钮。
6.3 在下拉菜单栏中,单击新建。
6.4 在次级菜单栏中,单击ODPS SQL。
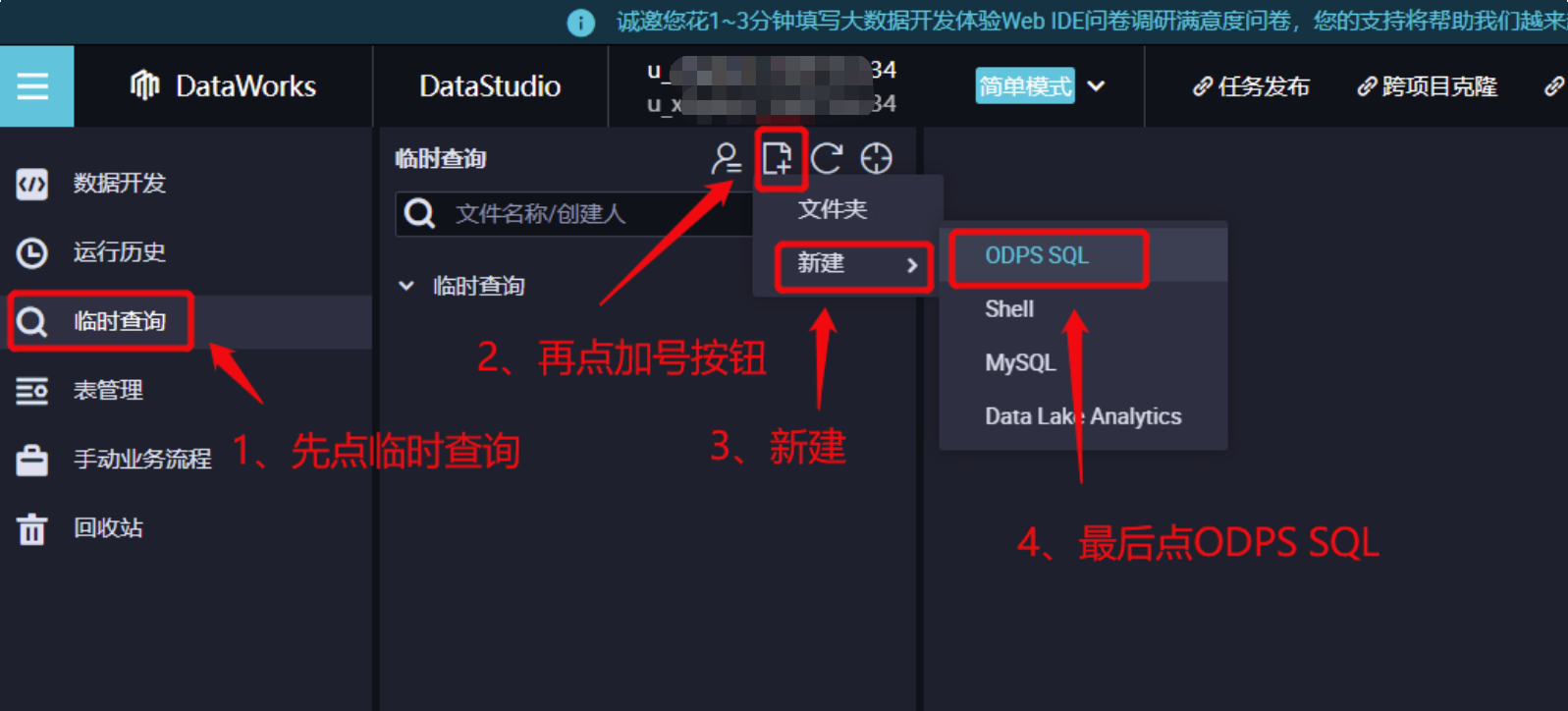
新建节点。
7.1 在新建节点对话框中,路劲选择临时查询。
7.2 给节点自定义任意名称,比如临时SQL 。
7.3 单击确认。

创建好临时查询后,下面创建数据表。
CREATE TABLE `ttext` (
`ttext_id` string,
`user_id` string,
`user_name` string,
`user_age` int,
`gender` string,
`city_name` string,
`created_at` datetime ,
`ttitle` string,
`reposts_count` int,
`comments_count` int,
`attitudes_count` int
) 通过以上SQL代码可以创建一个承载数据的表格。
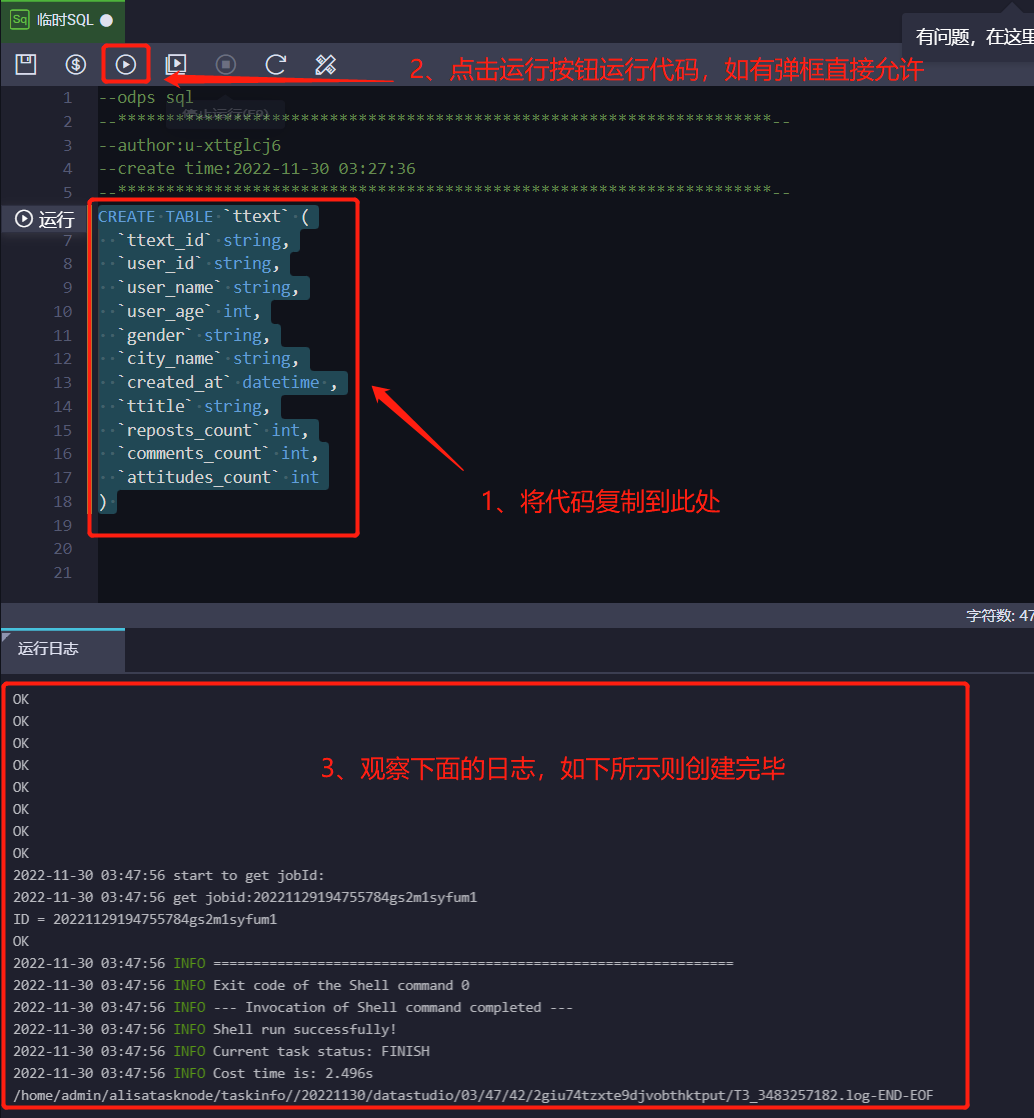
8.1 将上述SQL代码复制粘贴到临时SQL的窗口中
8.2 单击上方运行按钮运行代码,如有弹框直接允许。
8.3 观察下面的日志,如下图中所示则创建完毕(此步骤无需操作)
创建好表格后,下面我们导入数据。
9.1 复制下方地址,在Chromium网页浏览器中,打开新页签,粘贴并访问,下载数据。
https://files.alicdn.com/tpsservice/b9f833b45bc3aec88506e97f36e1f6c9.csv9.2 在左侧导航栏中,单击表管理。
9.3 在表管理面板,单击上方导入按钮。
9.4 在将本地数据导入开发表对话框中,至少输入待查询的表前三个字母tte,会弹出ttext表。
9.5 单击下一步。

导入开发表设置。
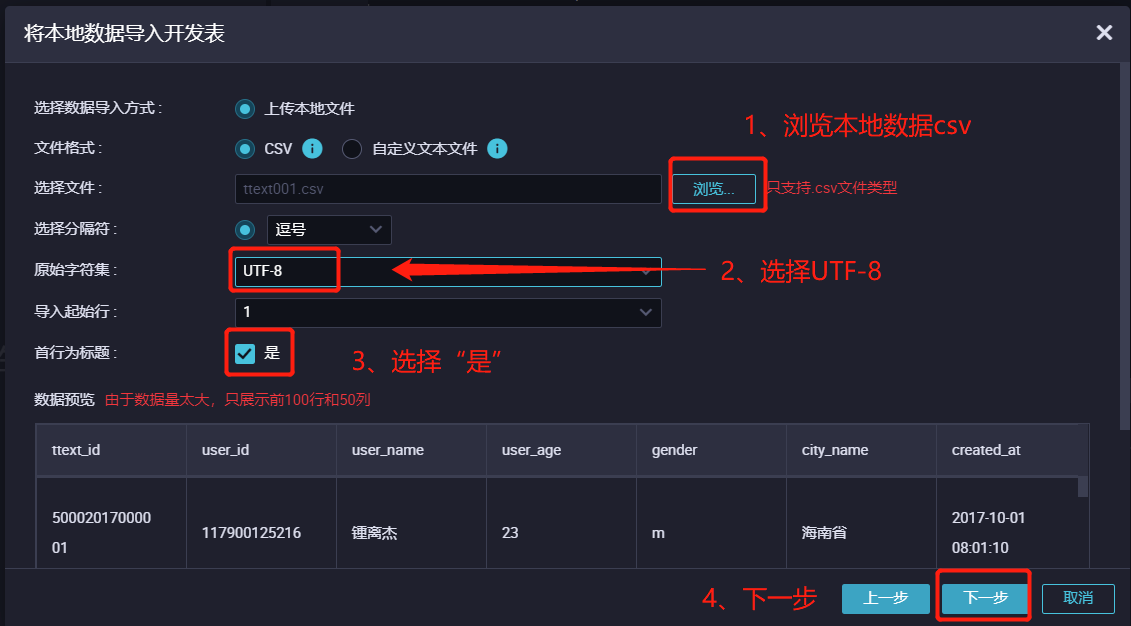
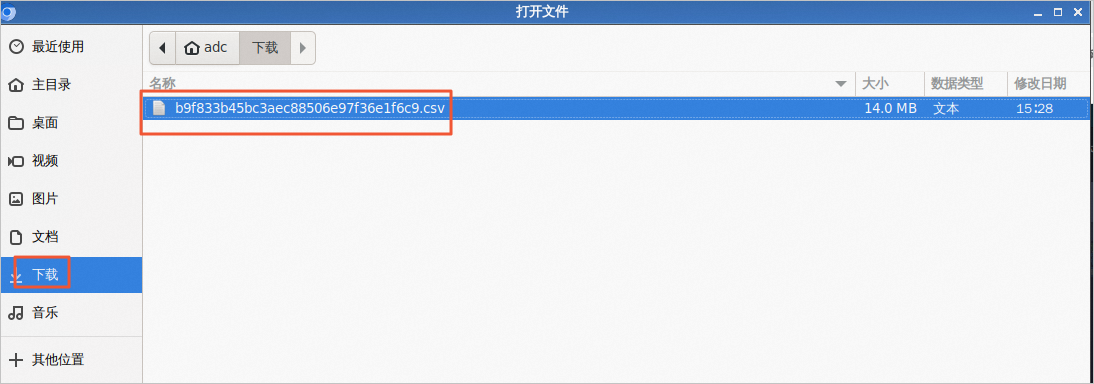
10.1 浏览本地数据CSV,在下载目录中双击刚刚下载好的数据文件。
10.2 选择UTF-8字符集。
10.3 首行为标题选择是。
10.4 单击下一步。
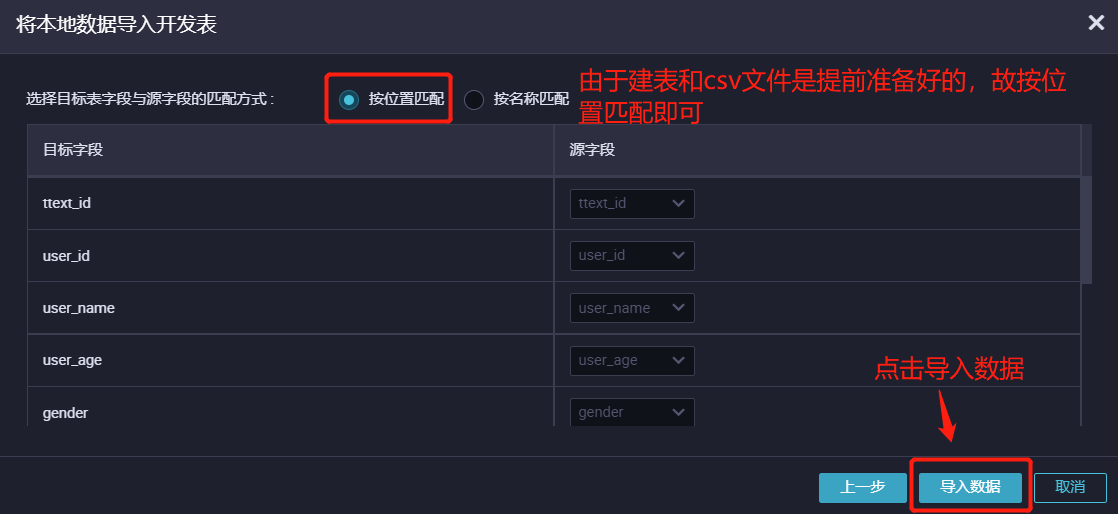
导入开发表设置字段匹配。
11.1 选择按位置匹配,由于建表和CSV文件是提前准备好的,故按位置匹配即可。
11.2 单击导入数据。
导入数据大约需要1~2分钟时间,请耐心等待。
进行热点话题分析
需求1:2017年10月发送推文最多的10个城市是哪几个?这几个城市的用户共计发送了多少条推文?
执行SQL。
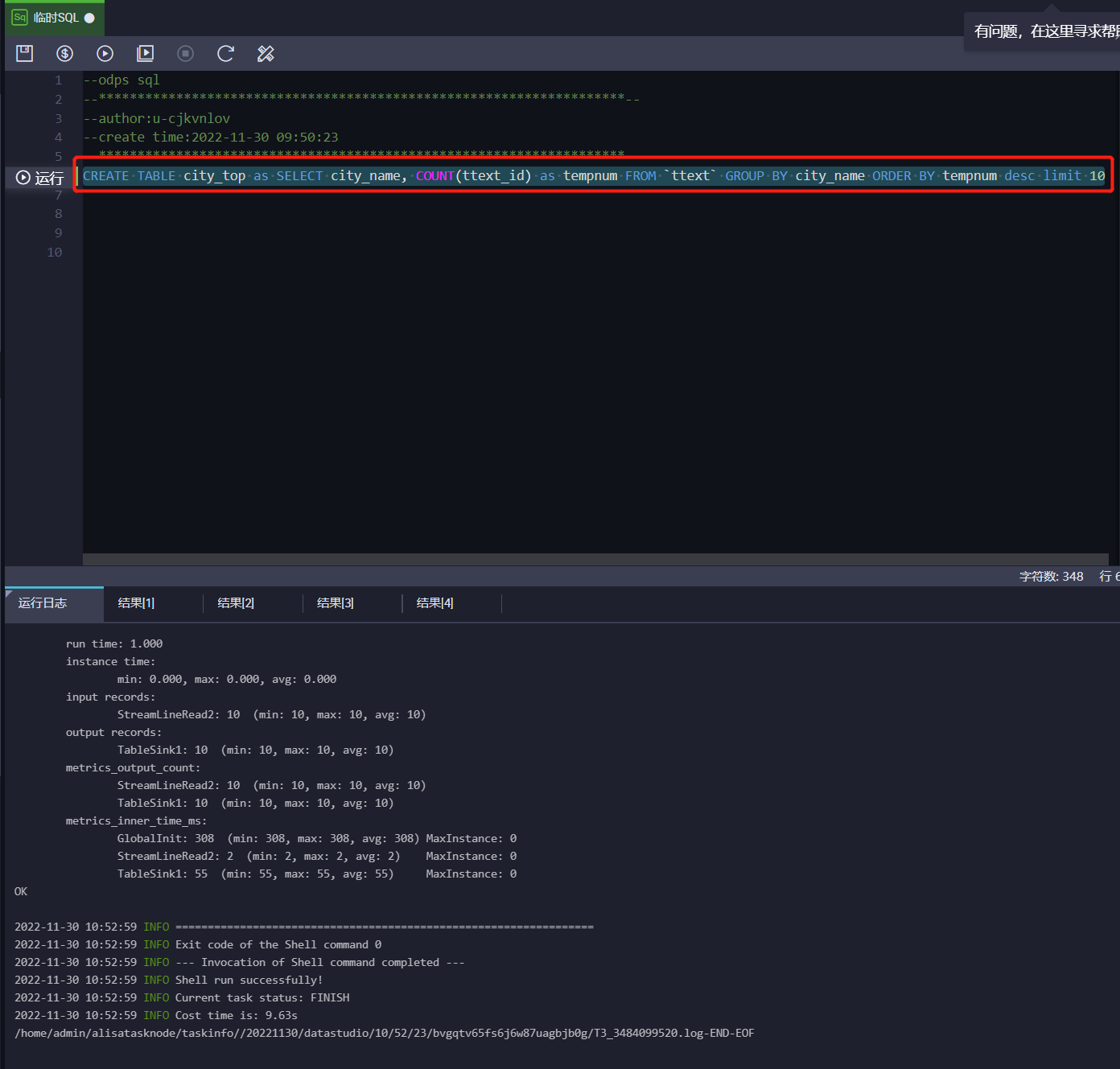
1.1 将如下SQL代码,复制粘贴到临时SQL的窗口中,单击上方运行按钮运行代码,如有弹框直接允许。
CREATE TABLE city_top as SELECT city_name, COUNT(ttext_id) as tempnum FROM `ttext` GROUP BY city_name ORDER BY tempnum desc limit 101.2 SQL解释:该SQL会查询各个城市各有多少条推文数量,并降序显示前十名的城市和推文数量,最后
把查询的前十名数据存储到一个叫做city_top的表中,便于下一步做可视化。
创建的city_top表可以在公共表处查询,如果您的界面没有公共表可根据如下操作进行开启。
2.1 在左侧导航栏中,单击左下角设置按钮。
2.2 在设置页面的模块管理区域,单击公共表。
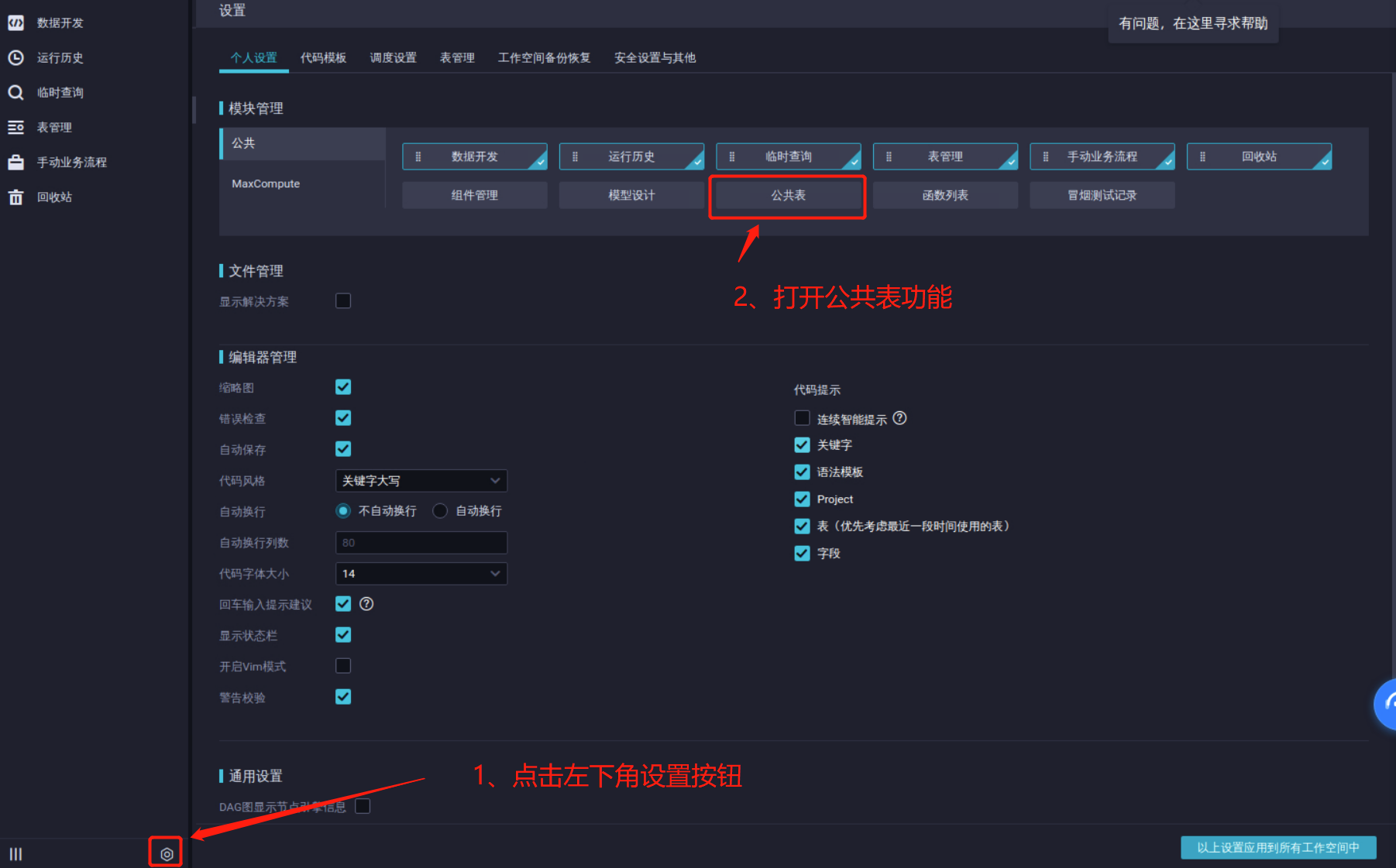
在左侧导航栏中,此时您可以看到公共表按钮,查询city_top表。
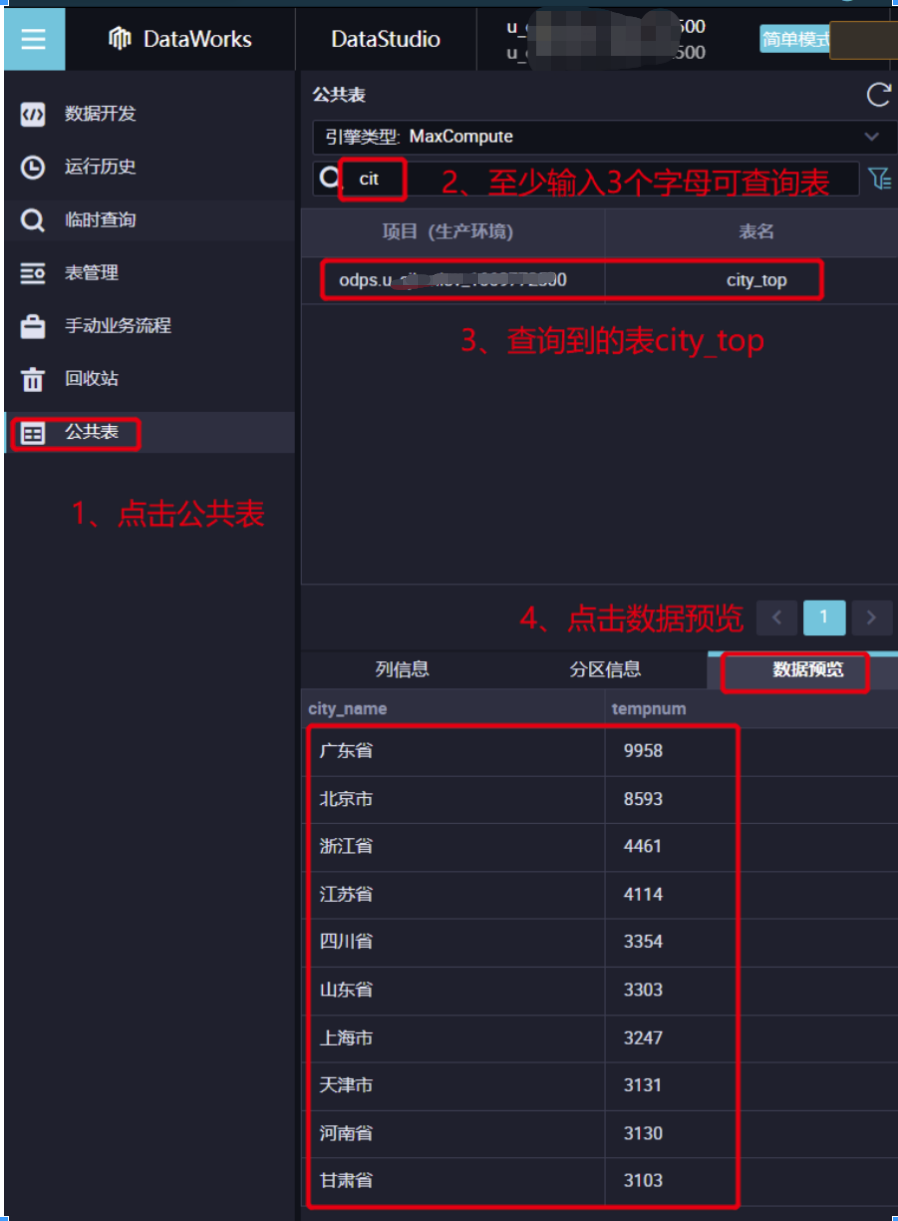
3.1 在左侧导航栏中,单击公共表。
3.2 在公共表面板的查询输入框中,至少输入3个字母可查询表,例如输入cit,即可查询city_top表。
3.3 看到查询到的city_top表,并双击。
3.4 单击数据预览,查看数据。
需求2:2017年10月所有用户中性别男女比例是多少?
执行SQL。
1.1 将如下SQL代码,复制粘贴到临时SQL的窗口中,单击上方运行按钮运行代码,如有弹框直接允许。
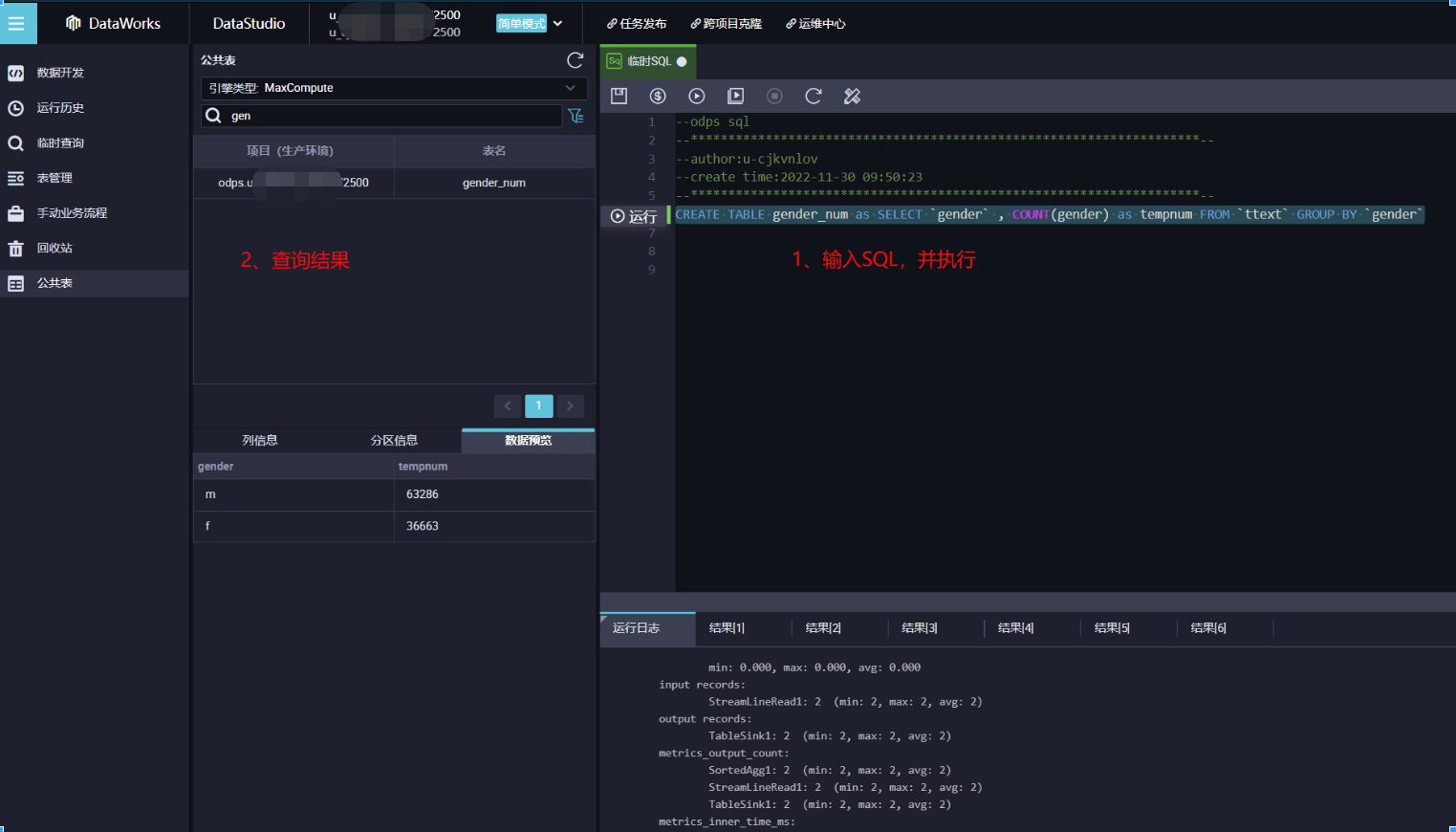
CREATE TABLE gender_num as SELECT `gender` , COUNT(gender) as tempnum FROM `ttext` GROUP BY `gender`1.2 SQL解释:按照性别分别查询男女的推文数量,并存储到gender_num的表中,便于下一步做可视化。
在公共表面板中,查询gender_num表。
2.1 在公共表面板的查询输入框中,至少输入3个字母可查询表,例如输入gen,即可查询gender_num表。
2.2 看到查询到的gender_num表,并双击。
2.3 单击数据预览,查看数据。
需求3:2017年10月所有用户年龄分布图集中趋势如何?
执行SQL。
1.1 将如下SQL代码,复制粘贴到临时SQL的窗口中,单击上方运行按钮运行代码,如有弹框直接允许。
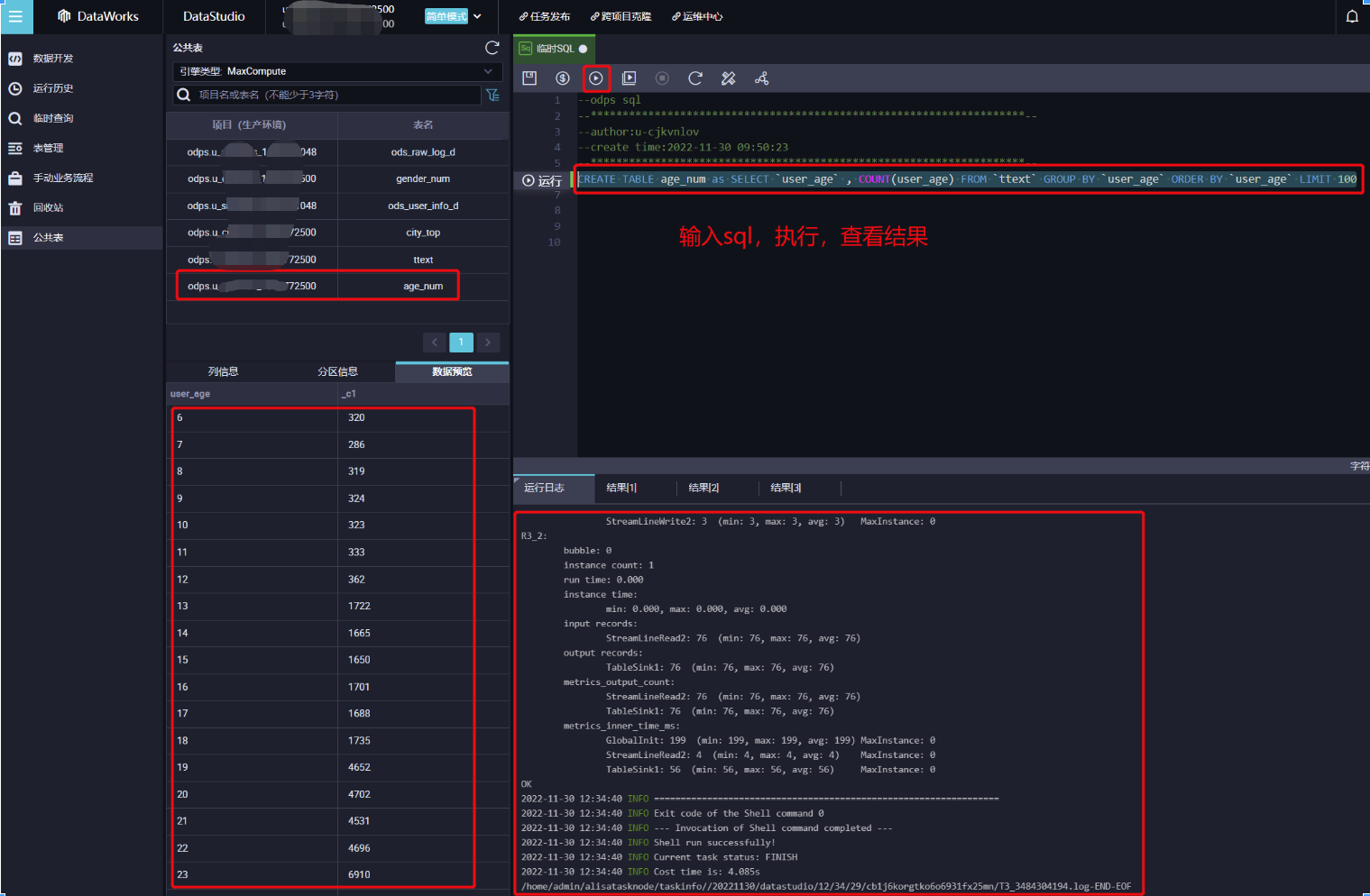
CREATE TABLE age_num as SELECT `user_age` , COUNT(user_age) FROM `ttext` GROUP BY `user_age` ORDER BY `user_age` LIMIT 1001.2 SQL解释:按照年龄分组查询各个年龄的用户总数,并按照年龄排序,最后存储到age_num的表中,便于下一步做可视化。
在公共表面板中,查询age_num表。
2.1 在公共表面板的查询输入框中,至少输入3个字母可查询表,例如输入age,即可查询age_num表。
2.2 看到查询到的age_num表,并双击。
2.3 单击数据预览,查看数据。
需求4:2017年10月哪些事件在互联网上热议,最热门的三个事件是什么
1、诺贝尔奖
2、麦当劳改名金拱门
3、十九大召开
4、拉斯维加斯持枪杀人事件
5、美国退出联合国教科文组织
6、鹿晗新女友
7、羞羞的铁拳上映
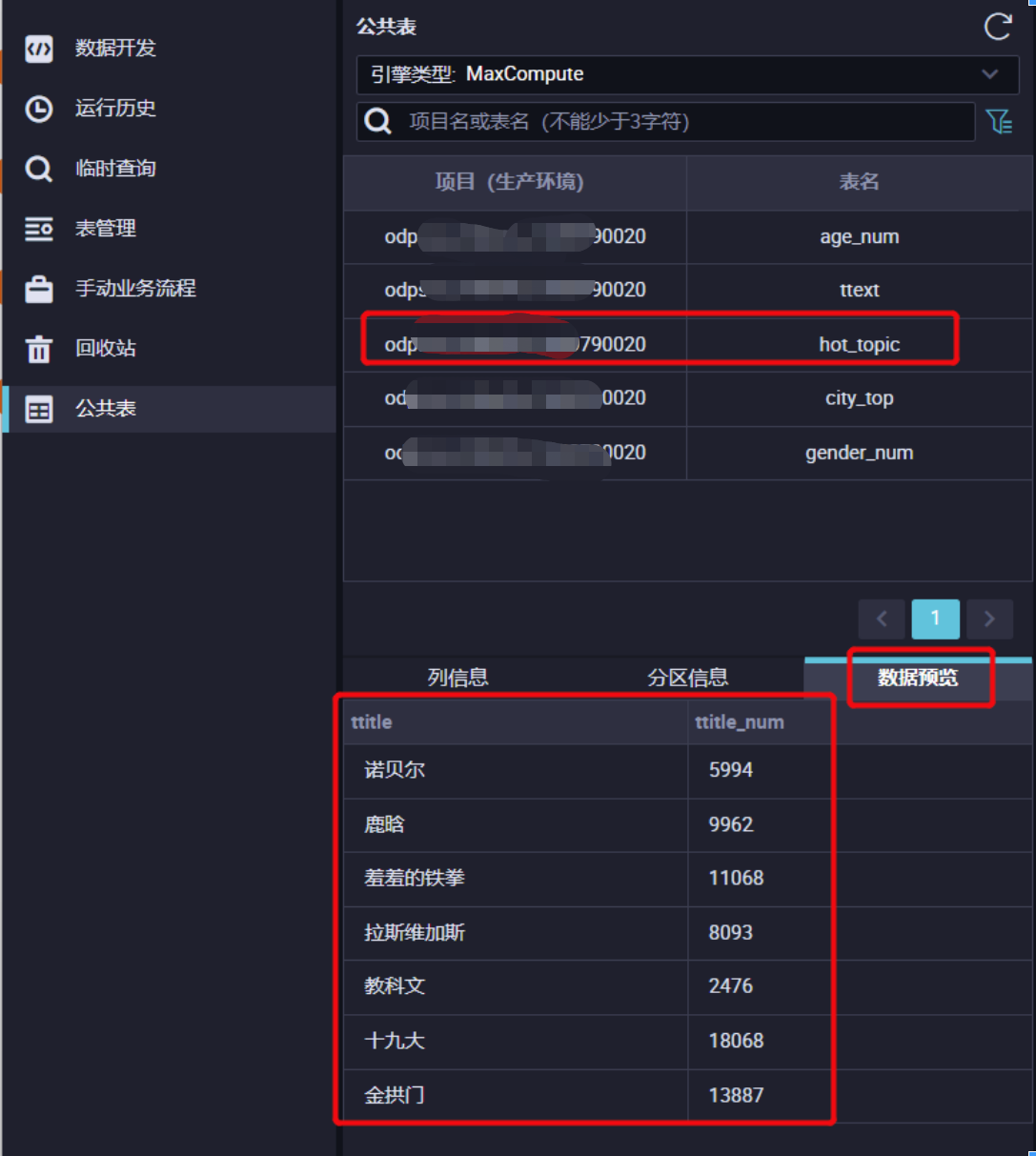
热门话题关键字:诺贝尔,金拱门,十九大,拉斯维加斯,教科文,鹿晗,羞羞铁拳。
执行创建hot_topic表的SQL代码。
1.1 将如下SQL代码,复制粘贴到临时SQL的窗口中,单击上方运行按钮运行代码,如有弹框直接允许。
CREATE TABLE hot_topic
(
ttitle STRING,
ttitle_num bigint
);1.2 SQL解释:创建一个用来存储热门话题的数据表
执行向hot_topic表插入数据的SQL代码。
2.1 将如下SQL代码,复制粘贴到临时SQL的窗口中,单击上方运行按钮运行代码,如有弹框直接允许。
INSERT INTO hot_topic SELECT"诺贝尔", COUNT(ttitle) FROM `ttext` WHERE ttitle like '%诺贝尔%'2.2 SQL解释:针对不同的热门话题关键字分别执行查询并将结果存储到刚才创建的表中,以上代码需要编写7次执行7次,每次针对不同的关键字,最终将在hot_topic形成7条数据
在公共表面板中,查询hot_topic表。
2.1 在公共表面板的查询输入框中,至少输入3个字母可查询表,例如输入hot,即可查询hot_topic表。
2.2 看到查询到的hot_topic表,并双击。
2.3 单击数据预览,查看数据。

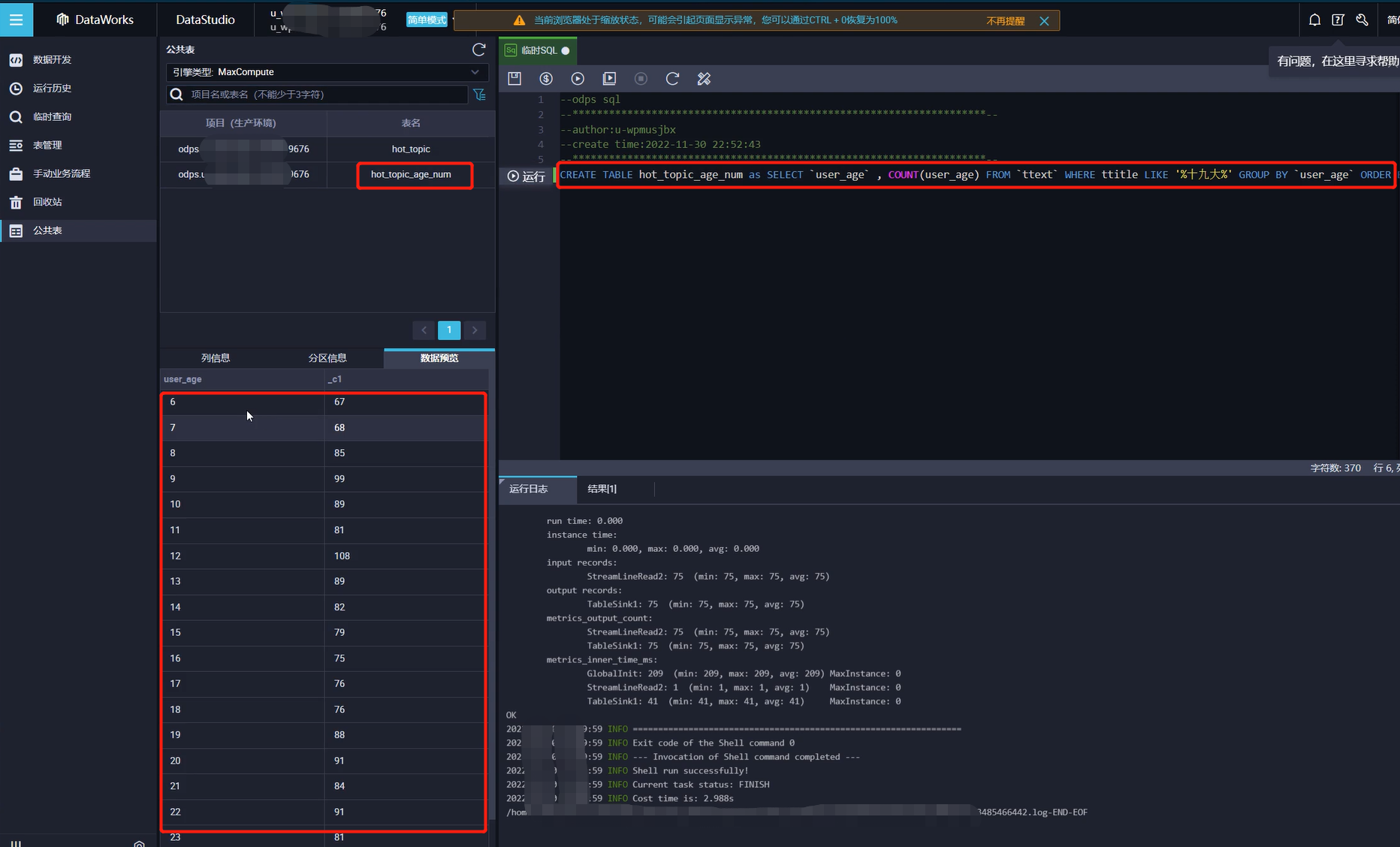
需求5:最热门的话题是哪个年龄段的用户讨论的
执行SQL。
1.1 将如下SQL代码,复制粘贴到临时SQL的窗口中,单击上方运行按钮运行代码,如有弹框直接允许。
CREATE TABLE hot_topic_age_num as SELECT `user_age` , COUNT(user_age) FROM `ttext` WHERE ttitle LIKE '%十九大%' GROUP BY `user_age` ORDER BY `user_age` LIMIT 1001.2 SQL解释:在需求3的基础上,增加一个条件查询,限制话题是“十九大”的话题,然后再统计年龄分布。
在公共表面板中,查询hot_topic_age_num表。
2.1 在公共表面板的查询输入框中,至少输入3个字母可查询表,例如输入hot,即可查询hot_topic_age_num表。
2.2 看到查询到的hot_topic_age_num表,并双击。
2.3 单击数据预览,查看数据。
数据可视化
本实验中使用的可视化功能基于DataWorks自带的电子表格的可视化功能。
首先需要打开电子表格。在左上角,单击

菜单图标,选择电子表格来制作可视化。
在电子表格页面,单击新建电子表格。

导入数据,导入的数据实际上就是我们前面从MaxCompute上分析得出的结论数据。
3.1 复制下方地址,在Chromium网页浏览器中,打开新页签,粘贴并访问,下载数据。
https://files.alicdn.com/tpsservice/3af99496968aa19075252ce864061773.xlsx3.在右上角选择导入>本地文件,在下载目录中双击刚刚下载的数据文件。
3.3 导入数据后可以从下面的标签页来切换5个需求的数据。
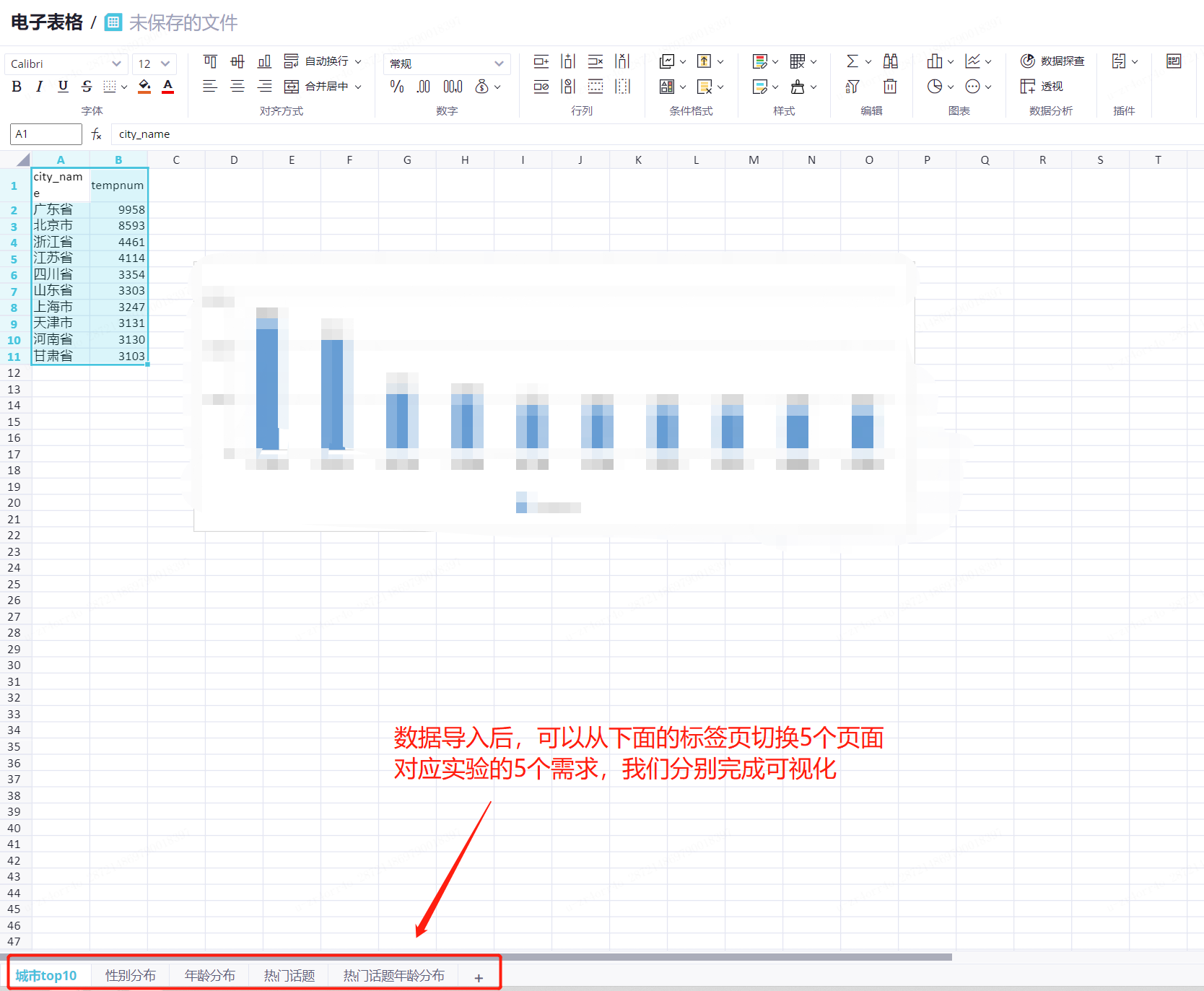
需求1:2017年10月发送推文最多的10个城市是哪几个?这几个城市的用户共计发送了多少条推文?
在城市top10页签,选中所有数据。
在上方菜单栏中,单击柱状图。
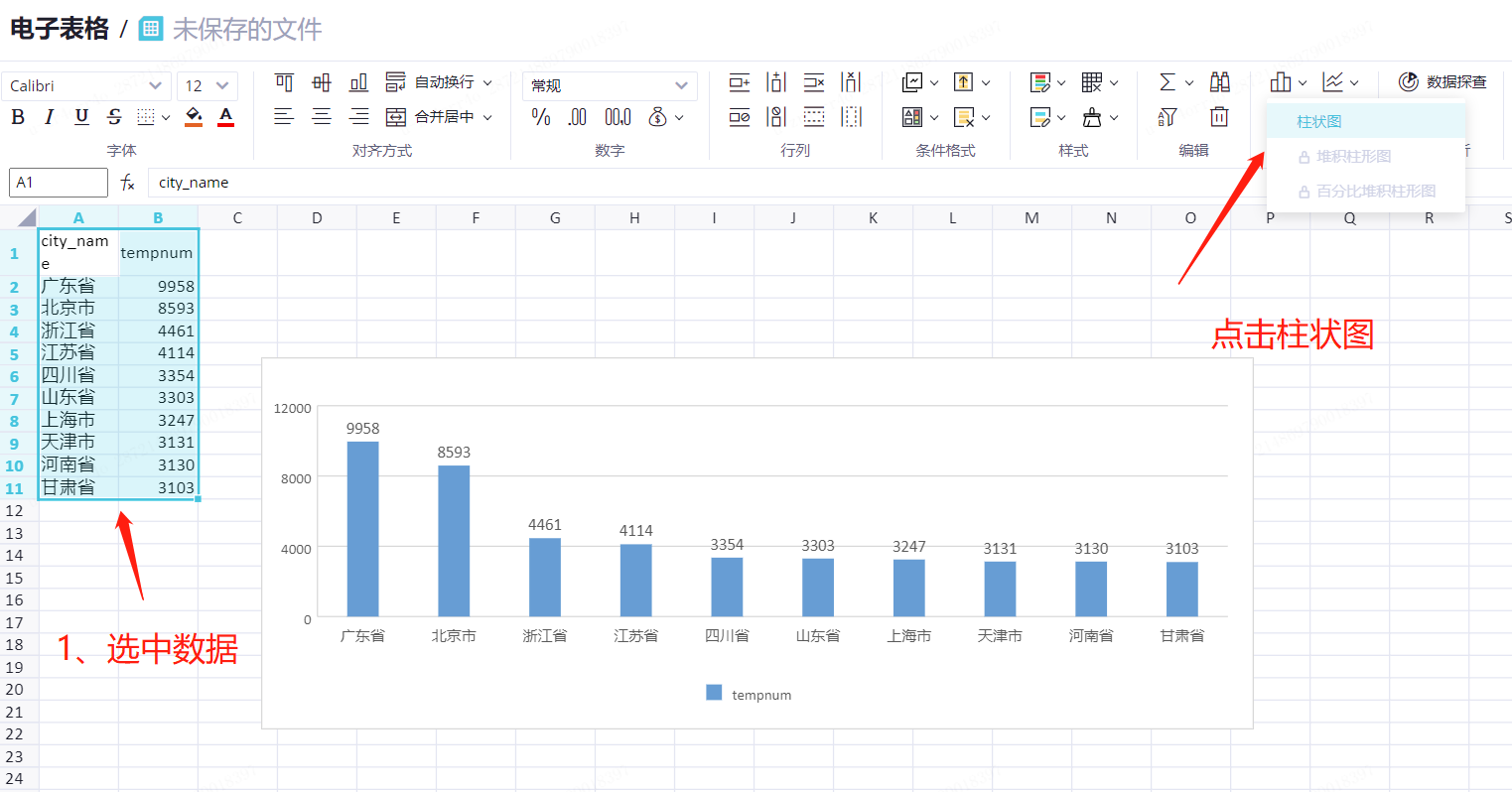
需求2:2017年10月所有用户中性别男女比例是多少?
在性别分布页签,选中所有数据。
在上方菜单栏中,单击饼状图。
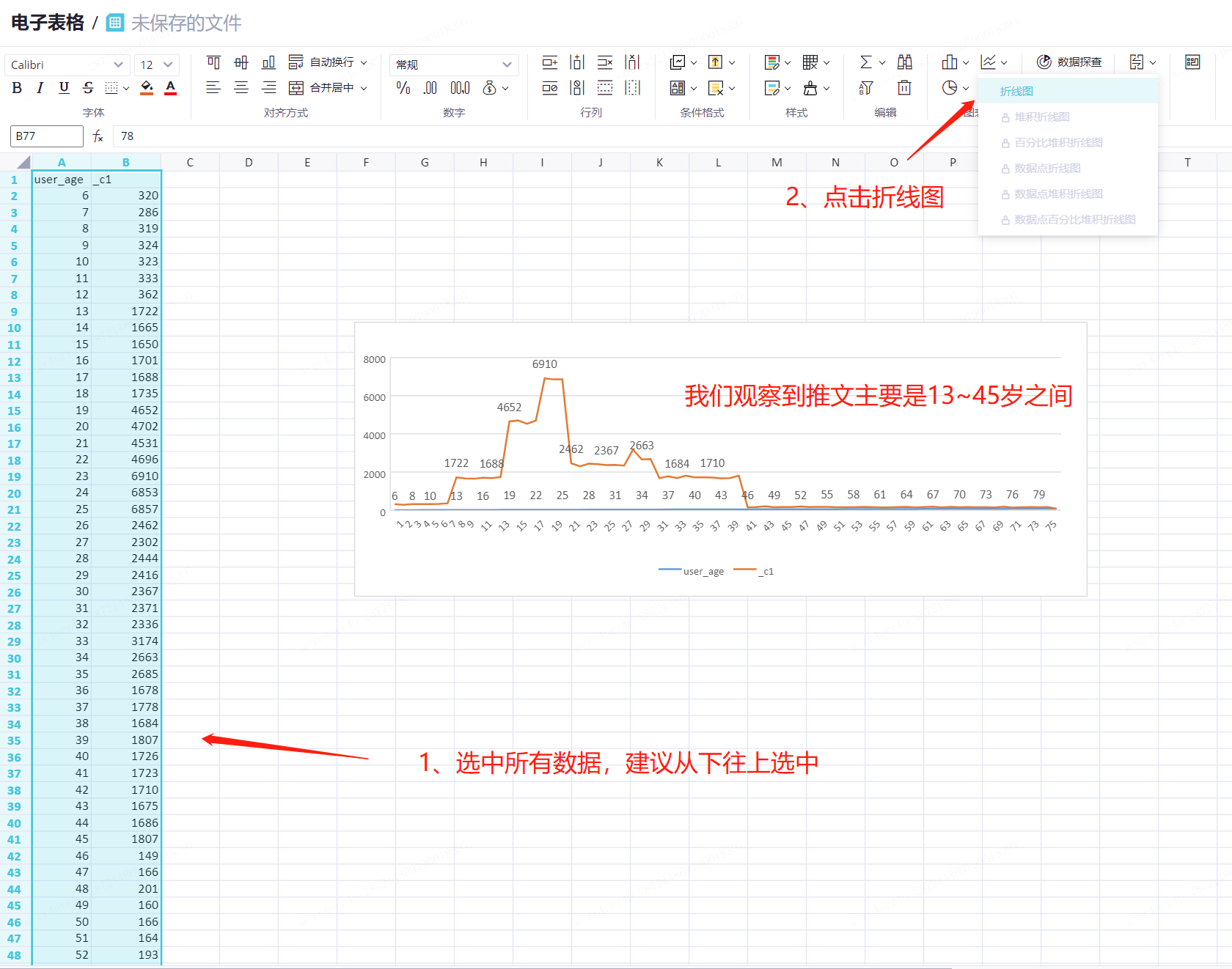
需求3:2017年10月所有用户年龄分布图集中趋势如何?
在年龄分布页签,选中所有数据。
在上方菜单栏中,单击折线图。
我们观察到推文主要是13~45岁之间的用户发送。
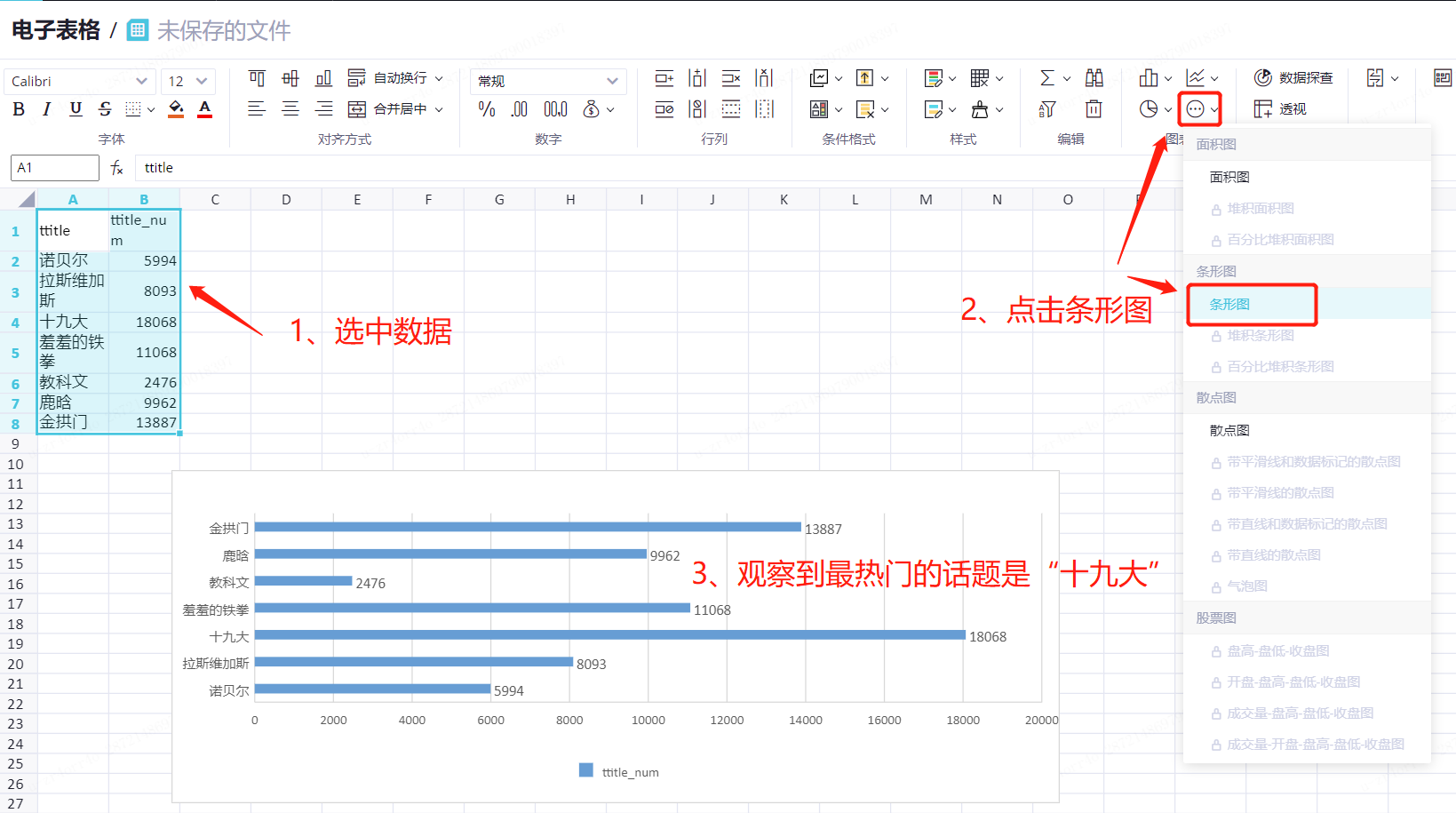
需求4:2017年10月哪些事件在互联网上热议,最热门的三个事件是什么
在热门话题页签,选中所有数据。
在上方菜单栏中,单击条形图。
我们观察到最热门的话题是“十九大”。
需求5:2017年10月最热门的话题是哪个年龄段的用户讨论的
在热门话题年龄分布页签,选中所有数据。
在上方菜单栏中,单击折线图。
我们观察到讨论热门话题“十九大”的年龄分布是26~45岁,比所有话题的年龄分布偏大。

至此实验完毕,谢谢大家 !



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











