







Abstract
核心内容:
这篇论文研究了如何将基于大规模数据训练的视觉语言模型(Vision-Language Models,VLMs)集成到端到端驾驶系统中,以提升泛化能力和与用户交互的能力。当前的方法通常通过单轮视觉问答(VQA)来适配VLMs至驾驶任务,但论文指出人类驾驶决策过程是多步骤的,包括定位关键对象、估计对象间的交互并采取行动。
关键洞察:
作者提出了一种新的任务——图形VQA(Graph VQA),将感知、预测和规划任务结构化为图的形式,通过问答对的方式模拟人类的推理过程。
方法:
- 数据集:构建了名为DriveLM-Data的数据集,基于nuScenes和CARLA框架。
- 模型:提出了一种基于VLM的基线方法(DriveLM-Agent),用于联合执行图形VQA任务和端到端驾驶任务。
实验结果:
- Graph VQA提供了一个简单而有原则的框架,用于推理驾驶场景。
- DriveLM-Data为该任务提供了具有挑战性的基准。
- DriveLM-Agent性能表现:
- 在端到端自动驾驶任务中,与当前最先进的专用架构相比,具有竞争力。
- 在零样本场景(未见的传感器配置)下的效果尤为显著。
- 消融实验表明,性能提升主要来自于对预测和规划问答对的丰富标注。
数据与代码:
论文提到所有数据、模型及评估服务器均可通过 GitHub 获取。
关键词:
- 视觉语言模型(VLM)
- 端到端自动驾驶
- 图形VQA
Fig. 1: We present DriveLM

从提供的图1可以看到,论文的内容结构化描述了DriveLM方法的任务、数据集、指标和基线方法。以下是图中的重要信息解析:
1. Graph Visual Question Answering (GVQA) 任务:
-
核心理念:
- 使用问答对(QA pairs)来建模驾驶场景中多层次逻辑依赖:
- 对象级别(Object-Level):表示对象间的交互。
- 任务级别(Task-Level):感知(Perception, P 1 P_1 P1)→预测(Prediction, P 2 P_2 P2)→规划(Planning, P 3 P_3 P3)→行为(Behavior, B B B)→运动(Motion, M M M)。
- 目标是通过问答对逐步推理。
- 使用问答对(QA pairs)来建模驾驶场景中多层次逻辑依赖:
-
示例问答对:
- ( P 1 (P_1 (P1):感知:问当前场景中有哪些重要对象?
- ( P 2 (P_2 (P2):预测:这些对象可能会移动到哪里?
- ( P 3 (P_3 (P3):规划:考虑这些对象后,自动驾驶车辆的安全行动是什么?
2. DriveLM-Agent:
- 基于视觉语言模型(Vision Language Models)的基线方法:
- 输入:场景图像和上下文问题。
- 输出:回答相关的行为或运动决策。
- 支持感知、预测和规划任务的联合推理。
3. 数据集 (DriveLM-Data):
- 从nuScenes和CARLA中构建,涵盖以下内容:
- 场景中的关键对象(如车辆、行人)的注释。
- 问答对,包含感知、预测和规划。
- 提供用于模型训练的结构化数据。
4. 评估指标 (DriveLM-Metrics):
- 图形VQA:
- 用于评价模型在问答任务中的性能。
- 示例:基于GPT评分预测回答与真实回答的接近程度。
- 轨迹预测:
- 预测自动驾驶车辆的运动轨迹。
- 指标:位移误差(Displacement Error)与真实轨迹的对比。
- 泛化能力:
- 测试模型在未见场景(unseen scenes)和未见对象(unseen objects)下的表现。
5. 重要亮点:
- 逐步推理能力:
- 模仿人类驾驶决策过程,通过逐步构建感知、预测和规划层次。
- 零样本泛化:
- 在未见场景和未见传感器配置(如不同传感器类型)上表现良好。
- 挑战性基准:
- 为复杂驾驶场景提供新的研究基准。
1 Introduction
1. 引言 (Introduction):
-
背景问题:
- 自动驾驶(AD)的现状:
- 当前AD系统缺乏关键能力,例如泛化性(对未见场景和传感器配置的适应)。
- 需要增强与人类用户交互的能力,例如可解释性。
- 与人类驾驶差异:
- 人类驾驶不依赖几何化的鸟瞰图(BEV),而是基于对象感知、预测和规划( P 1 , P 2 , P 3 P_1, P_2, P_3 P1,P2,P3)进行决策。
- 人类通过多步骤推理(识别关键对象、推测运动及计划行动)完成驾驶任务。
- 自动驾驶(AD)的现状:
-
VLMs的潜力:
- VLMs通过互联网数据学习到的泛化能力可以支持AD中的决策规划。
- 已被应用于简单的机器人任务,显示出对未见输入的良好适应能力。
- 可以实现多步骤推理,涵盖对象关系及逻辑依赖。
-
现有方法的不足:
- 仅关注场景级或单对象级的视觉问答(VQA)。
- 未能有效模拟人类的多步骤推理过程。
-
论文贡献:
提出Graph Visual Question Answering (GVQA),通过图结构将 P 1 P_1 P1到 P 3 P_3 P3的推理过程转化为问答对,模拟人类驾驶决策。
2. 任务 (Task):
- Graph VQA:
- 将感知、预测和规划问题建模为有向图,节点代表QA对,边表示逻辑依赖。
- 不同于传统VQA任务,其核心在于多层次的逻辑推理。
- 综合了驾驶场景中的感知、行为预测和运动规划。
3. 数据集 (Datasets):
- DriveLM-Data:
- 包括:
- DriveLM-nuScenes:基于nuScenes场景数据生成的QA标注。
- DriveLM-CARLA:结合CARLA仿真环境,通过规则算法生成。
- 特点:
- 提供比其他基准更丰富的每帧注释。
- 支持评估零样本泛化能力。
- 包括:
4. 基线方法 (Baseline):
-
DriveLM-Agent:
- 利用轨迹标记器(trajectory tokenizer)结合图形提示(graph prompting)将逻辑依赖作为上下文输入VLMs。
- 简单有效地将VLM应用于端到端AD。
-
实验结果:
- GVQA挑战性:需要更好建模逻辑依赖的能力。
- 泛化能力增强:在未见传感器和场景配置上表现突出(例如Waymo数据)。
- 问题级消融分析:从预测和规划阶段的QA对中提取的语义信息对驾驶决策最为关键。
Fig. 2: Annotation Pipeline:
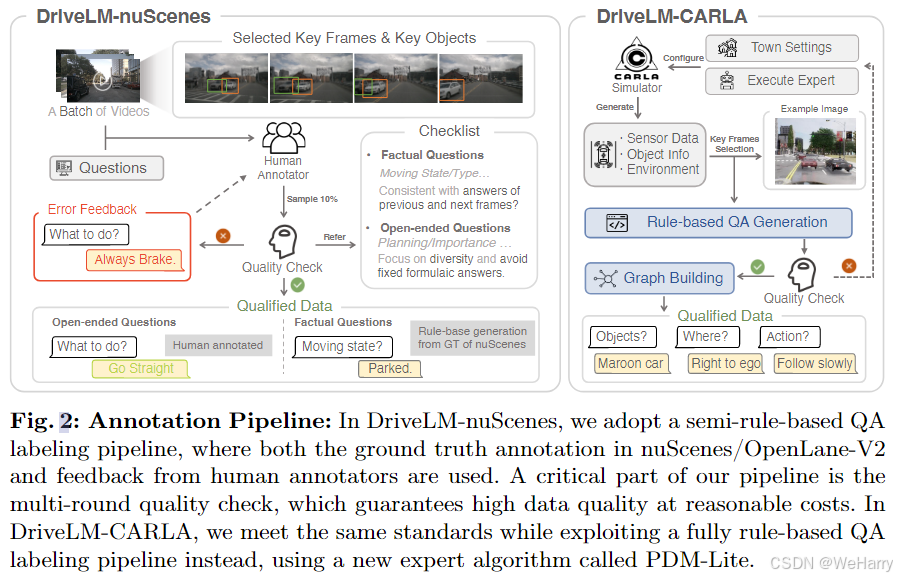
图2展示了DriveLM数据集(DriveLM-nuScenes和DriveLM-CARLA)的注释流程,以下是分部分解析:
1. DriveLM-nuScenes
-
流程:
- 初始输入:从nuScenes数据集中提取一批视频帧及关键对象。
- 问答生成:
- 基于真实标注生成事实型问题(Factual Questions),例如对象的移动状态。
- 开放型问题(Open-ended Questions),例如“该怎么办?”注重规划和多样性。
- 人工检查:
- 对10%的问题进行人工审核。
- 校验问题是否与前后帧一致、答案是否多样化。
- 如果有问题,提供反馈(如建议答案“Always Brake”)。
- 质量检查:通过多轮检查生成合格的问答数据。
-
特点:
- 半规则化(Semi-Rule-Based):结合真实标注和人工检查。
- 提高数据多样性并确保问答质量。
2. DriveLM-CARLA
-
流程:
- 仿真数据生成:
- 在CARLA模拟器中配置环境(如城镇设置)。
- 执行专家算法获取传感器数据、对象信息及环境状态。
- 问答生成:
- 基于规则的算法(Rule-Based QA Generation)构建问题。
- 使用图构建模块(Graph Building)关联对象、动作和环境信息。
- 质量检查:与DriveLM-nuScenes类似,确保生成的问答数据符合标准。
- 仿真数据生成:
-
特点:
- 完全规则化(Fully Rule-Based):使用新专家算法PDM-Lite。
- 更高的自动化程度,减少人工干预。
3. 两者对比
- DriveLM-nuScenes:
- 更注重结合真实数据和人工标注,适用于复杂真实场景。
- DriveLM-CARLA:
- 借助仿真环境和规则算法,快速生成高质量数据,适用于构建大规模数据集。
总结:
这套注释流程结合了真实场景和仿真环境的优势,通过规则算法和人工审核,确保生成的问答数据高质量且多样性。两种方法相辅相成,为GVQA任务提供了全面的数据支持。
2 DriveLM: Task, Data, Metrics
核心目标:
DriveLM致力于模仿人类驾驶推理过程,将驾驶决策分解为以下阶段:
- 关键对象的识别和定位。
- 对象可能的未来动作和交互。
- 基于所有信息的自车规划。
这启发了作者提出**Graph Visual Question Answering (GVQA)**任务,作为模仿人类推理过程的代理任务。
本节内容:
- GVQA任务的定义与构建:
- 在2.1节中详细说明GVQA任务的表述方式。
- DriveLM数据集:
- 2.2节介绍数据集的构建及其与驾驶场景的结合。
- DriveLM评价指标:
- 2.3节总结用于评估的方法和指标体系。
推动研究发展:
- 公开评估平台:
- 将建立一个公开的排行榜(leaderboard),用于评估不同方法在GVQA和端到端驾驶任务中的表现。
- 目标是深入探索语言模型与自动驾驶的结合。
总结:
这部分明确了DriveLM项目的任务设定、数据支持和评价方法,并提供了研究框架的全景图。
2.1 DriveLM-Task: GVQA
1. 任务表示为图结构
-
图定义:
- 图
G
=
(
V
,
E
)
G = (V, E)
G=(V,E):
- V V V:顶点,每个顶点是一个问答对 ( q , a ) (q, a) (q,a),与场景中的一个或多个关键对象关联。
-
E
E
E:边,表示问答对之间的逻辑依赖关系。
- 例如,当前问题可以从父节点或祖父节点获取上下文。
- 图
G
=
(
V
,
E
)
G = (V, E)
G=(V,E):
-
GVQA与传统VQA的区别:
- GVQA的问答对之间有明确的逻辑依赖,这些依赖通过图中的边进行建模。
2. 边的定义
-
对象级依赖(Object-Level Edges):
- 表示不同对象之间的交互影响。
- 例如,“规划”节点依赖于“行人感知”节点。
-
任务级依赖(Task-Level Edges):
- 表示不同推理阶段之间的逻辑链:
- 感知(Perception, P 1 P_1 P1:关键对象的识别、描述和定位。
- 预测(Prediction, P 2 P_2 P2:关键对象可能动作/交互的估计。
- 规划(Planning, P 3 P_3 P3:自动驾驶车辆的安全动作规划。
- 行为(Behavior, B B B:驾驶决策的分类。
- 运动(Motion, M M M:车辆未来轨迹的路径点。
- 表示不同推理阶段之间的逻辑链:
3. 运动(Motion, M M M)的定义
- 轨迹为二维坐标点序列: M = { ( x 0 , y 0 ) , ( x 1 , y 1 ) , … , ( x N , y N ) } M = \{(x_0, y_0), (x_1, y_1), \dots, (x_N, y_N)\} M={(x0,y0),(x1,y1),…,(xN,yN)}。
- 每个点表示车辆在固定时间间隔后的偏移。
- 距离计算公式:
{ x , y } dist = { ( δ x , 1 , δ y , 1 ) , … , ( δ x , N , δ y , N ) } \{x, y\}_{\text{dist}} = \{(\delta_{x,1}, \delta_{y,1}), \dots, (\delta_{x,N}, \delta_{y,N})\} {x,y}dist={(δx,1,δy,1),…,(δx,N,δy,N)}
其中 δ x , i = x i − x i − 1 \delta_{x,i} = x_i - x_{i-1} δx,i=xi−xi−1, δ y , i = y i − y i − 1 \delta_{y,i} = y_i - y_{i-1} δy,i=yi−yi−1。
4. 行为(Behavior, B B B)的定义
- 行为表示为轨迹的速度和方向的类别组合:
- 速度类别 ( B s p B_{sp} Bsp): { f a s t 2 , f a s t 1 , m o d e r a t e , s l o w 1 , s l o w 2 } \{fast2, fast1, moderate, slow1, slow2\} {fast2,fast1,moderate,slow1,slow2}。
- 转向类别 ( B s t B_{st} Bst): { l e f t 2 , l e f t 1 , s t r a i g h t , r i g h t 1 , r i g h t 2 } \{left2, left1, straight, right1, right2\} {left2,left1,straight,right1,right2}。
- 示例: B = ( B s p , B s t ) B = (B_{sp}, B_{st}) B=(Bsp,Bst)。
- 表示从简单行为(例如转弯)到更抽象行为(如变道、超车)的潜力。
总结
这一部分系统地定义了GVQA任务的核心——通过图结构建模问答对及其逻辑依赖,涵盖从感知到规划的完整推理过程。同时,为行为和运动提供了具体的数学描述,为后续建模奠定了基础。
Table 1: Comparison of DriveLM-nuScenes & -CARLA with Existing Datasets.
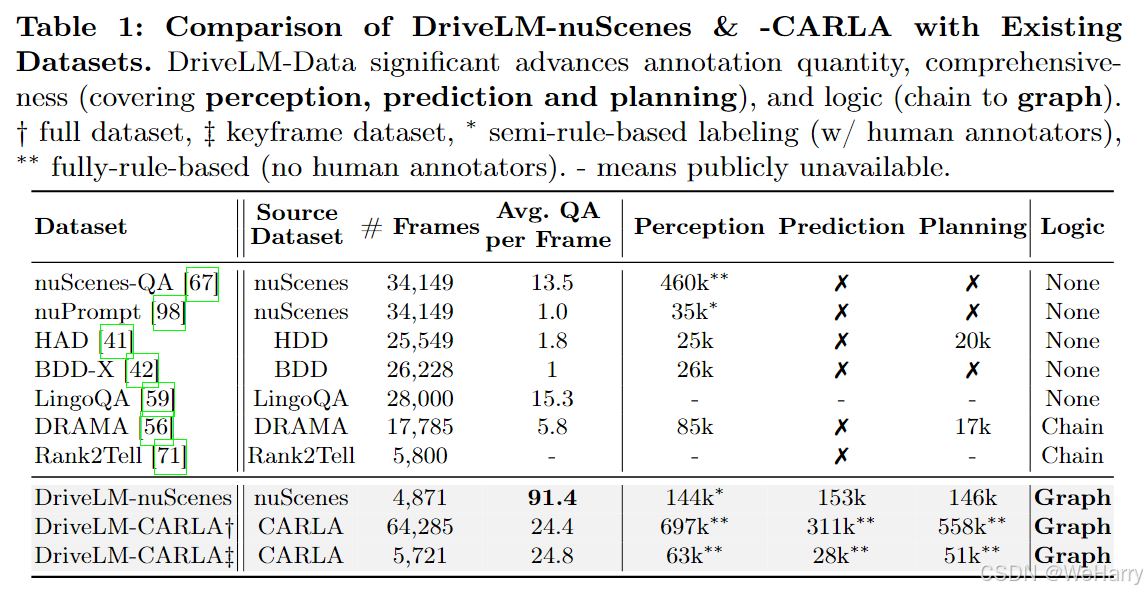
表1展示了DriveLM数据集(DriveLM-nuScenes和DriveLM-CARLA)与现有数据集的对比分析。以下是详细解读:
1. 数据集列的比较维度:
- Source Dataset:数据来源。
- # Frames:帧数,即数据集中包含的图像帧总数。
- Avg. QA per Frame:每帧平均问答对的数量。
- Perception/Prediction/Planning:是否覆盖感知、预测和规划任务。
- Logic:逻辑建模的形式(无逻辑、链式逻辑或图逻辑)。
2. 现有数据集的特点:
- nuScenes-QA:
- 来源:nuScenes。
- 每帧问答对数量:13.5。
- 涵盖感知任务,不涉及预测或规划。
- 无逻辑建模。
- nuPrompt:
- 来源:nuScenes。
- 每帧问答对数量:10。
- 涵盖感知、规划任务,但不涉及预测。
- 无逻辑建模。
- HAD、BDD-X:
- 主要覆盖感知任务,部分包含规划。
- 无逻辑建模。
- LingoQA、DRAMA、Rank2Tell:
- DRAMA数据集较为全面,支持感知和规划,且有链式逻辑。
- Rank2Tell问答对数量较少,逻辑建模能力有限。
3. DriveLM数据集的优势:
-
帧数与问答数量:
- 虽然DriveLM-nuScenes和DriveLM-CARLA的帧数较少(如DriveLM-nuScenes有4,871帧),但每帧平均问答对数量显著高于其他数据集(如nuScenes-QA的13.5 vs. DriveLM-nuScenes的91.4)。
- 表明其注释更加丰富和细致。
-
任务覆盖:
- DriveLM数据集全面覆盖感知(Perception)、预测(Prediction)和规划(Planning)任务,而多数现有数据集仅支持部分任务。
- 提供了多层次、多任务的标注。
-
逻辑建模:
- DriveLM数据集基于图逻辑建模(Graph Logic),相比链式逻辑具有更高的复杂性和灵活性。
-
注释方式:
- DriveLM-nuScenes:半规则化标注(人工与算法结合)。
- DriveLM-CARLA:完全规则化标注(无人工标注)。
4. 关键亮点:
- DriveLM数据集通过丰富的注释和覆盖感知、预测、规划任务,为图形VQA-GVQA提供了更具挑战性和广泛适用性的基准。
- Graph Logic的引入,增强了任务间的逻辑依赖建模,适合复杂驾驶场景的推理任务。
2.2 DriveLM-Data
1. DriveLM-nuScenes 数据集
-
注释过程:
- 步骤:
- 从视频剪辑中选择关键帧。
- 确定关键对象。
- 为关键对象注释帧级问答对( P 1 P_1 P1-感知、 P 2 P_2 P2-预测、 P 3 P_3 P3-规划)。
- 部分感知问答(Perception QA)从nuScenes和OpenLane-V2真实标注生成,其余问答由人工专家标注。
- 问题模板:
- 由5位领域专家设计,模拟人类驾驶决策逻辑。
- 提供“跳过选项”以应对不兼容的问题。
- 步骤:
-
质量控制:
- 数据分批进行多轮质量检查。
- 检查每批次中10%的数据,若未达标,重新标注整批数据。
-
特点:
- 覆盖感知、预测和规划全过程。
- 提供比现有数据集更大的规模和复杂的逻辑结构。
2. DriveLM-CARLA 数据集
-
数据收集:
- 基于CARLA仿真器,使用Leaderboard 2.0框架生成。
- 新的专家算法PDM-Lite,解决Leaderboard 2.0的新场景挑战。
-
PDM-Lite的特点:
- 基于智能驾驶模型(Intelligent Driver Model, IDM)。
- 使用简单成本函数,减少复杂性,提高生成效率。
- 在CARLA验证路线上,Driving Score (DS)从2%提升至44%。
-
注释过程:
- 根据专家决策的变化(如加速到刹车)选择关键帧。
- 提取静态和动态对象的状态信息,构建问答对。
- 38个驾驶场景中,基于手工设计的句子模板生成问题和答案。
-
规模和优点:
- 数据量达1.6M个问答对。
- CARLA数据集成为最大规模驾驶语言基准,在文本内容上超越现有基准。
3. DriveLM 数据集的价值
- 覆盖从感知到规划的复杂驾驶任务,体现更全面的驾驶逻辑。
- 高质量的标注和灵活扩展性使其适用于大规模自动驾驶研究。
2.3 DriveLM-Metrics
1. GVQA评估指标的三部分
DriveLM-Metrics用于评估GVQA任务,包括以下三个关键组件:
-
运动阶段(Motion, ( M M M):
- 评价标准:
- 平均位移误差(Average Displacement Error, ADE):预测轨迹与真实轨迹间的平均误差。
- 最终位移误差(Final Displacement Error, FDE):预测轨迹终点与真实终点的误差。
- 碰撞率(Collision Rate):预测轨迹与障碍物的碰撞比例。
- 使用来自nuScenes和Waymo基准的标准方法。
- 评价标准:
-
行为预测(Behavior, ( B B B):
- 分类准确率(Classification Accuracy):
- 分解为方向(Steering)和速度(Speed)两个方面的分类准确率。
- 分类准确率(Classification Accuracy):
-
P 1 P_1 P1- P 3 P_3 P3的性能:
- SPICE指标:
- 主要用于视觉问答(VQA)和图像描述任务。
- 计算预测答案的结构相似性(如语法结构)与真实答案对齐程度,忽略语义内容。
- GPT Score:
- 测量答案的语义一致性。
- 方法:将预测答案和真实答案作为问题提示输入ChatGPT-3.5,解析返回的文本,生成语义准确性得分。
- SPICE指标:
2. ChatGPT在GPT Score中的作用
- 具体操作:
- 将预测答案、真实答案和提示语(要求计算数值分数)输入到ChatGPT-3.5。
- 解析ChatGPT返回的文本,得出分数。
- 意义:
- 更高的分数表示更好的语义对齐。
3. 亮点总结
- 运动和行为评估采用了传统标准(如ADE和分类准确率),适合自动驾驶场景。
- P 1 P_1 P1- P 3 P_3 P3阶段的评估结合了SPICE和GPT Score,兼顾结构和语义的准确性,增强了GVQA任务的全面性。
- 使用ChatGPT-3.5进行语义对齐评估展示了生成式AI在自动驾驶领域的应用潜力。
Fig. 3: DriveLM-Agent Pipeline.
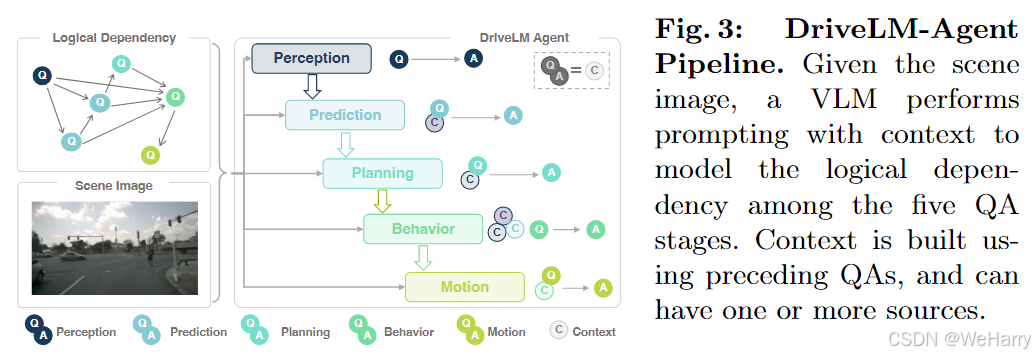
图3展示了DriveLM-Agent Pipeline的具体工作流程,以下是关键解读:
1. 任务流程概述
- 输入:
- 场景图像。
- 与图形逻辑相关的上下文信息。
- 输出:
- 基于视觉语言模型(VLM)的逐步推理,完成从感知到运动的问答任务。
2. 逻辑依赖(Logical Dependency)
- 图结构建模:
- 每个节点代表一个问答对(QA),依赖关系通过箭头连接。
- 这些依赖逻辑定义了五个阶段之间的关系(感知→预测→规划→行为→运动)。
3. 逐步推理过程
-
Pipeline中每阶段的工作:
- 感知(Perception):
- 确定场景中的关键对象。
- 预测(Prediction):
- 推断这些对象的可能交互或未来动作。
- 规划(Planning):
- 根据感知和预测的结果规划自车的安全动作。
- 行为(Behavior):
- 分类并细化驾驶决策。
- 运动(Motion):
- 生成自车未来的具体轨迹。
- 感知(Perception):
-
上下文构建:
- 每个阶段的问答(QA)会基于前一个阶段的上下文进行生成。
- 上下文可以来源于一个或多个问答的结果,以保持逻辑一致性。
4. 亮点总结
- 层次化逻辑:
- 通过多阶段问答逐步推理,模拟了人类驾驶过程的逻辑顺序。
- 上下文依赖:
- 上下文信息的传递增强了模型对复杂驾驶场景的理解能力。
- VLM的作用:
- 将视觉和语言处理结合,使系统具备处理多模态输入的能力。
3 DriveLM-Agent: A GVQA Baseline
1. DriveLM-Agent 概述
- DriveLM-Agent是为GVQA任务设计的基线方法,基于通用的**视觉语言模型(VLM)**构建。
- 核心目标:
- 将场景图像输入转换为目标车辆的运动模式(Motion, M M M)。
- 通过不同的VQA阶段(感知 P 1 P_1 P1、预测 P 2 P_2 P2、规划 P 3 P_3 P3、行为 B B B、运动 M M M)逐步推理。
2. 模型选择
- 基于BLIP-2模型:
- 优点:架构简单、灵活性高,便于微调(fine-tuning)。
- 可扩展性:方法可以推广至其他VLM架构。
3. Pipeline的阶段划分
-
基础层次( P 1 P_1 P1 - P 3 P_3 P3):
- 包括感知、预测和规划阶段。
- 这些阶段是推理解构驾驶场景的基础层,帮助模型理解场景及其逻辑结构。
-
行为阶段(Behavior, B B B):
- 汇总来自 P 1 P_1 P1- P 3 P_3 P3的信息。
- 将目标驾驶动作转换为语言描述。
-
运动阶段(Motion, M M M):
- 将行为描述转化为可执行的驾驶轨迹。
- 例如:生成具体的路径点和运动方向。
4. 逻辑依赖的处理
- 上下文利用:
- 为了实现问答对之间的逻辑依赖,DriveLM-Agent在图形VQA中连接的每个节点间引入上下文。
- 上下文帮助维持阶段之间的信息连贯性,强化逻辑推理。
5. 亮点总结
- DriveLM-Agent通过逐层推理,模仿人类驾驶决策的分阶段思维。
- 其依托于预训练VLM的知识库,能够灵活适应各种驾驶场景。
- 方法设计兼具灵活性和扩展性,为更复杂的驾驶任务提供基准。
3.1 Prompting with Context
1. 多步推理的必要性
-
问题背景:
- 将图像直接翻译为运动轨迹(Motion, M M M)是极具挑战的。
- 类似人类驾驶的多步骤推理策略更适合视觉语言模型(VLM),可以有效利用模型存储的知识并提高可解释性。
-
解决方案:
- 在推理过程中,利用前一步骤的问答结果作为上下文,辅助当前阶段的问题解答。
2. 上下文构建方法
-
具体机制:
- 对于每条图中的边
e
=
(
v
p
,
v
c
)
∈
E
e = (v_p, v_c) \in E
e=(vp,vc)∈E:
- 将父节点( v p v_p vp)的问答内容附加到当前节点( v c v_c vc)的问题前,作为上下文提示。
- 添加前缀“Context:”以标明上下文来源。
- 上下文可以包含来自多个父节点的问答,并通过串联方式形成上下文序列。
- 对于每条图中的边
e
=
(
v
p
,
v
c
)
∈
E
e = (v_p, v_c) \in E
e=(vp,vc)∈E:
-
可扩展性:
- 这是GVQA任务逻辑依赖建模的众多实现方式之一。
- 在推理时,允许使用特定子图(通过启发式采样),以适应计算资源限制。
3. 行为阶段的上下文聚合
-
驾驶行为的多样性:
- 驾驶场景中存在多种需要响应的潜在情况。
- 尽管情况多样,但这些事件通常可以被离散化为一组行为。
- 例如:“适时刹车”可以适用于红灯信号、停车标志或前方障碍物等多种情况。
-
行为生成的目标:
- 在行为阶段生成一个自然语言描述,表明车辆的预期动作。
- 这一描述反映了从 P 1 P_1 P1- P 3 P_3 P3阶段汇总的所有重要信息。
-
行为的作用:
- 行为描述起到了总结的作用,将图结构中所有关键信息整合为可预测的行为决策。
- 这一设计被证明对基于VLM的驾驶任务至关重要。
4. 总结
- 上下文提示(Prompting with Context)通过信息的层层传递,增强了模型的逻辑一致性和多阶段推理能力。
- 行为阶段的上下文聚合简化了复杂场景的推理过程,为轨迹生成提供了高效的行为描述。
3.2 Trajectory Tokenization for Motion
1. 问题背景
- 使用通用视觉语言模型(VLMs)直接生成精确的数值结果(如细粒度轨迹点)是非平凡的。
- 当前方法(如RT-2)通过专用的轨迹标记模块(trajectory tokenization module)处理机器人动作。
2. 轨迹标记化模块
- DriveLM-Agent 的扩展:
- 将图像和行为描述作为输入,通过轨迹标记模块输出驾驶轨迹。
- 具体实现:
- 将轨迹点的坐标分配到256个离散区间(bins)。
- 区间划分基于训练集轨迹的统计数据。
- 使用BLIP-2语言标记器(language tokenizer)重新定义这些离散区间的tokens。
3. 模型训练与微调
- BLIP-2架构:
- 使用BLIP-2作为基础架构。
- 通过独立的LoRA权重(Low-Rank Adaptation)进行微调:
- 数据集包含针对运动阶段(motion stage)的所有问答对(QAs)。
- 简化与扩展:
- BLIP-2的标记模块用于标记化任务,但也可以通过轻量级的LLM(如ChatGPT)或专门的驾驶架构(如接受命令的模型)实现相同功能。
4. 亮点总结
- 标记化方法的优势:
- 通过离散化的轨迹点表示,降低生成细粒度轨迹的复杂性。
- 灵活性:
- 模块可与轻量级语言模型(LLM)或专用架构结合,适配多种驾驶场景。
- 微调设计:
- LoRA权重的独立训练提升了模型的适应性,同时降低了训练成本。
4 Experiments
1. 研究问题
实验主要解决以下关键问题:
- VLM的适配性:
- 如何有效地重新利用视觉语言模型(VLM)来实现端到端自动驾驶?
- 泛化能力:
- VLM在未见的传感器配置下是否能够表现出良好的泛化能力?
- 问答影响:
- 感知、预测和规划问题的回答对最终行为决策的影响如何?
- 任务表现:
- VLM在GVQA任务中的表现如何,特别是在感知、预测和规划任务上?
此外,针对更多的VLM在DriveLM-nuScenes和DriveLM-CARLA数据集上的实验结果,扩展内容提供在补充材料中。
2. 实验设置
微调方法:
- 所有微调均采用LoRA(Low-Rank Adaptation)。
DriveLM-nuScenes:
- 模型:BLIP-2。
- 训练设置:
- 数据:训练集(train split)。
- 训练轮数:10 epochs。
- 批量大小:每个GPU 2。
- 硬件:8个V100 GPUs。
- 时间:约7小时。
DriveLM-CARLA:
- 模型:BLIP-2。
- 训练设置:
- 数据:训练集的关键帧(keyframes)。
- 训练轮数:6 epochs。
- 硬件:4个A100 GPUs。
- 时间:约6小时。
3. 亮点总结
- VLM重新利用:
- 通过微调(LoRA),VLM能够适配复杂的自动驾驶任务。
- 高效训练:
- 实验采用BLIP-2,结合LoRA权重微调,仅需较少的计算资源即可完成。
- 数据多样性:
- 在DriveLM-nuScenes和DriveLM-CARLA上的训练设置分别针对真实场景和仿真环境进行了优化。
4.1 VLMs for End-to-End Driving
1. 实验目标
- 评估视觉语言模型(VLMs)在DriveLM-nuScenes上的能力,重点是:
- 行为和运动阶段的上下文提示对驾驶推理的影响。
- 生成未来轨迹的能力(以路径点的形式)。
- 使用DriveLM-nuScenes的关键帧来缓解开放式规划中数据分布不匹配的问题。
2. 基线方法(Baselines)
-
Command Mean:
- 每个帧与三个驾驶指令之一相关联(“左转”、“右转”、“直行”)。
- 输出与当前测试帧指令匹配的训练集轨迹的平均值。
-
UniAD-Single:
- 将现有的UniAD模型调整为单帧输入以进行公平对比。
- 之前的方法依赖于视频输入,这一调整确保实验一致性。
-
BLIP-RT-2:
- BLIP-2微调版本,仅针对运动阶段执行轨迹标记化任务。
- 不包含上下文输入或问答(VQA)训练数据。
3. DriveLM-Agent 的变体
- 提出三种变体以测试上下文的影响:
- 2-stage:
- 预测行为,然后预测运动。
- 不使用来自感知、预测和规划( P 1 P_1 P1- P 3 P_3 P3)的上下文信息。
- Chain:
- 使用 P 1 P_1 P1- P 3 P_3 P3构建问答图,仅将最后一个节点( P 3 P_3 P3)传递到行为阶段。
- Graph:
- 使用 P 1 P_1 P1- P 3 P_3 P3的所有问答作为行为阶段的上下文。
- 2-stage:
4. 实验结果
-
BLIP-RT-2 vs. UniAD-Single:
- BLIP-RT-2表现不如UniAD-Single,表明单阶段方法无法与当前最优方法匹敌。
- 没有推理过程的单阶段方法难以处理复杂场景。
-
DriveLM-Agent 的表现:
- 显著提升了性能,超越UniAD-Single。
- 表明合适的上下文提示能够极大增强VLMs在端到端驾驶任务中的竞争力。
-
Chain和Graph版本的观察:
- 在不涉及泛化的实验中,Chain和Graph版本未显示明显优势。
- 表明上下文在某些条件下的影响有限。
-
视频输入的重要性:
- 单帧输入的VLM性能低于使用视频输入的模型。
- 暗示视频输入对于处理此类任务可能是必要的。
5. 总结
- 通过上下文提示(特别是行为预测阶段的中间步骤),VLM可以在复杂驾驶任务中展现出强大的推理能力。
- 视频输入可能是进一步提高VLM性能的关键。
Table 2: Open-loop Planning on DriveLM-nuScenes and Zero-shot Generalization across Sensor Configurations on Waymo.
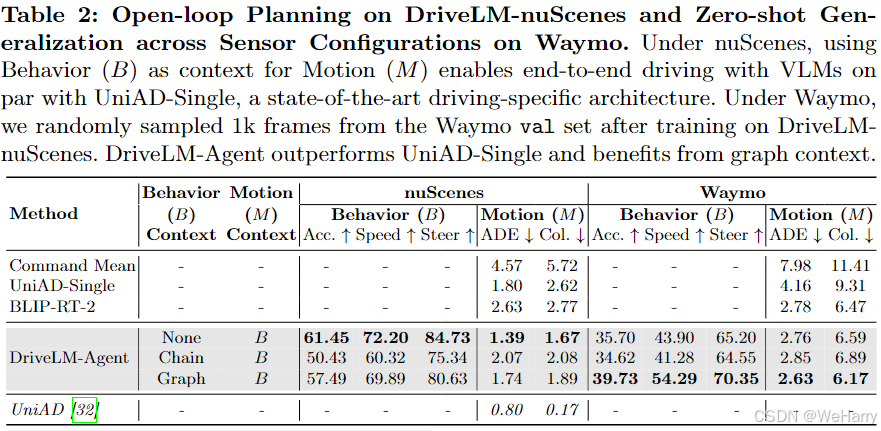
表2展示了在DriveLM-nuScenes和Waymo数据集上的开放式规划实验结果,重点在于行为( B B B)和运动( M M M)阶段的上下文提示对模型表现的影响。
1. 表格内容解析
列定义
- Behavior (B) Context:行为阶段是否使用上下文。
- Motion (M) Context:运动阶段是否使用上下文。
- nuScenes 指标:
- Acc.:行为预测的分类准确率。
- Steer:方向分类准确率。
- ADE:平均位移误差(Average Displacement Error)。
- Col.:碰撞率(Collision Rate)。
- Waymo 指标:
- 与nuScenes类似,但主要测试模型的零样本泛化能力(Zero-shot Generalization)。
模型对比
-
Command Mean:
- 简单基线,仅基于指令的平均轨迹输出。
- 在两数据集上的ADE和Col.均较高,表现有限。
-
UniAD-Single:
- 使用单帧输入的UniAD模型。
- 在nuScenes上有较高的分类和方向准确率,ADE与碰撞率较低。
- 在Waymo数据集上的泛化能力有限。
-
BLIP-RT-2:
- 不使用上下文的单阶段VLM。
- 在nuScenes和Waymo上的表现均不如UniAD-Single。
-
DriveLM-Agent(三种变体):
- None:不使用上下文。
- 在nuScenes上的分类准确率最高(Acc. 61.45,Steer 72.20)。
- ADE和碰撞率表现最佳(ADE 1.39,Col. 1.67)。
- 在Waymo上表现有限。
- Chain:使用链式上下文。
- nuScenes和Waymo上的表现均稍逊于None版本。
- Graph:使用图结构上下文。
- 在Waymo上表现显著提升,尤其是分类准确率(Acc. 70.35)和方向准确率(Steer 54.29)。
- ADE显著降低(2.75),碰撞率最低(5.23)。
- None:不使用上下文。
-
UniAD(完整版本):
- 表现最优(nuScenes ADE 0.80,Col. 0.17)。
- 表明视频输入在行为预测中的优势。
2. 关键结论
-
上下文提示的作用:
- 在nuScenes上,简单的None版本表现最佳,表明过多上下文可能引入噪声。
- 在Waymo上,Graph版本显著提升了模型的泛化能力,特别是在碰撞率上的改进(从11.41降至5.23)。
-
模型对比:
- BLIP-RT-2不使用上下文,无法匹敌UniAD-Single。
- DriveLM-Agent在Waymo上优于UniAD-Single,但与完整的UniAD相比仍有差距,表明视频输入的潜在优势。
3. 总结
- DriveLM-Agent通过上下文提示在零样本泛化任务中表现出色,特别是在图结构上下文的支持下。
- 视频输入(如UniAD)在多帧任务中具有潜在的性能优势。
- 不同上下文策略的影响取决于任务的场景复杂度和数据集特性。
Fig. 4: Qualitative Results of DriveLM-Agent.
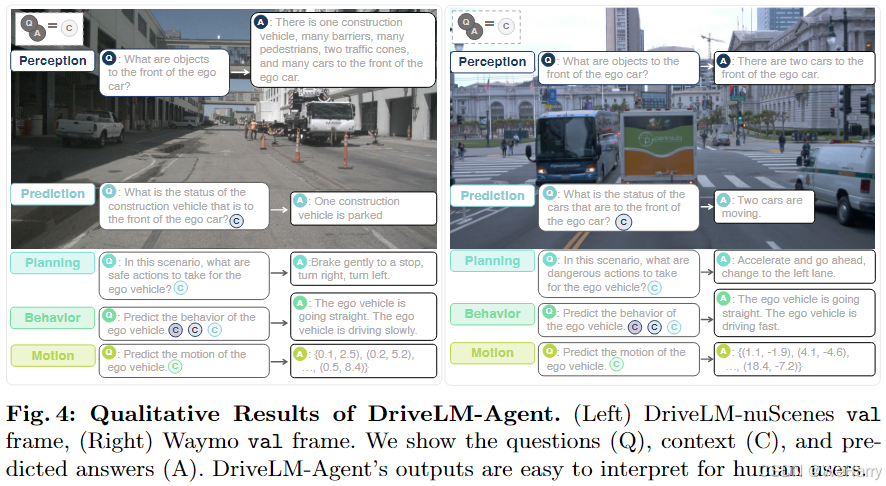
图4展示了DriveLM-Agent在DriveLM-nuScenes和Waymo验证集中的定性结果(Qualitative Results)。以下是详细解析:
1. 任务框架
每个场景包含以下几个阶段:
- 感知(Perception):
- 确定场景中的关键对象。
- 预测(Prediction):
- 推断关键对象的状态或可能动作。
- 规划(Planning):
- 设计自车的安全行为。
- 行为(Behavior):
- 总结自车的动作意图。
- 运动(Motion):
- 生成车辆的具体运动轨迹(路径点)。
2. DriveLM-nuScenes 场景 (左图)
问题与答案:
- 感知 (Q):
- “前方有哪些对象?”
- 答案 (A):一个建筑车、多个行人、两辆交通锥、许多车辆。
- 预测 (Q):
- “前方建筑车的状态是什么?”
- 答案 (A):建筑车停着。
- 规划 (Q):
- “在这种情况下,ego车的安全操作是什么?”
- 答案 (A):刹车停车,然后右转或直行。
- 行为 (Q):
- “预测ego车的行为是什么?”
- 答案 (A):车辆将缓慢行驶。
- 运动 (Q):
- “预测ego车的运动轨迹。”
- 答案 (A):具体路径点示例: ( 0.1 , 2.5 ) , ( 0.2 , 5.2 ) (0.1, 2.5), (0.2, 5.2) (0.1,2.5),(0.2,5.2)。
观察:
- 场景中有多个动态和静态对象。
- 系统准确识别了建筑车的状态,并生成了可行的规划(刹车停车并规划路径)。
3. Waymo 场景 (右图)
问题与答案:
- 感知 (Q):
- “前方有哪些对象?”
- 答案 (A):前方有两辆车。
- 预测 (Q):
- “前方车辆的状态是什么?”
- 答案 (A):两辆车正在移动。
- 规划 (Q):
- “在这种情况下,ego车的危险操作是什么?”
- 答案 (A):加速前进并换到左车道。
- 行为 (Q):
- “预测ego车的行为是什么?”
- 答案 (A):车辆将直行且加速。
- 运动 (Q):
- 答案 (A):具体路径点示例: ( 1.1 , − 1.9 ) , ( 4.1 , − 4.6 ) (1.1, -1.9), (4.1, -4.6) (1.1,−1.9),(4.1,−4.6)。
观察:
- 系统能够准确识别动态对象(前方车辆正在移动)。
- 提供了主动的规划建议(加速并换道)。
4. 总结
- 解释性:
- 问答形式让输出对人类用户更易理解。
- 适应性:
- DriveLM-Agent能够处理静态和动态场景,适应不同的道路条件(如建筑车或动态车辆)。
- 路径规划:
- 生成的运动轨迹包含精确的路径点,提供了清晰的驾驶意图。
4.2 Generalization Across Sensor Configurations
1. 实验背景
- 挑战性任务:将训练好的模型(Section 4.1中的模型)应用于一个新的域(Waymo数据集),且不进行额外训练。
- Waymo数据集的限制:
- 不包含后置摄像头图像。
- 因此,对于UniAD-Single,仅使用前置摄像头输入,并且无需适配。
2. 实验结果
-
UniAD-Single:
- 在新传感器配置下表现不佳。
- 性能下降至低于BLIP-RT-2,表明单帧方法在泛化任务上的局限性。
-
DriveLM-Agent:
- 多阶段方法的优势:
- 提升了预测速度(Speed Prediction)的准确率,从43.90%(无上下文)上升到54.29%(使用完整图结构上下文)。
- 证明图结构上下文可以有效增强模型的泛化能力。
- Chain Approach:
- 未能提供足够的上下文支持。
- 速度预测的准确率仅为41.28%,低于无上下文版本。
- 多阶段方法的优势:
3. 定性结果观察
-
DriveLM-Agent 在 nuScenes 和 Waymo 的表现:
- 一般能够提供直观且有意义的答案。
- 但在某些情况下(如Waymo感知、nuScenes规划)可能会出现异常。
-
GVQA的优势:
- 即使在感知阶段存在不足,DriveLM-Agent仍能够在Waymo上给出有意义的预测和规划答案。
- 这表明GVQA在交互式驾驶系统中的潜力。
4. 总结
-
模型泛化能力:
- DriveLM-Agent相比UniAD-Single展示了更好的跨传感器配置泛化能力。
- 图结构上下文在多阶段推理任务中的重要性得到了验证。
-
未来方向:
- 在新域(如Waymo)中改进感知阶段的表现,可以进一步提升预测和规划结果的可靠性。
4.3 Question-wise Analysis in DriveLM-nuScenes
1. 分析目标
- 研究不同类型的问答对(QA pair)作为上下文对行为预测性能的影响。
- 方法:
- 从不同阶段(感知、预测、规划)中选取具有代表性的QA对。
- 使用不同组合的QA对训练BLIP-2模型,并将这些QA对作为行为预测问题的上下文。
2. 各阶段的代表性问题
感知阶段( P 1 P_1 P1):
- P 1 – 1 P_{1\text{–}1} P1–1: 当前场景中有哪些重要对象?
- P 1 – 2 P_{1\text{–}2} P1–2: 对象 X X X 的运动状态是什么?
- P 1 – 3 P_{1\text{–}3} P1–3: 对象 X X X 的视觉描述是什么?
预测阶段( P 2 P_2 P2):
- P 2 – 1 P_{2\text{–}1} P2–1: 对象 X X X 的未来状态是什么?
- P 2 – 2 P_{2\text{–}2} P2–2: 对象 X X X 是否会进入自车的移动方向?
- P 2 – 3 P_{2\text{–}3} P2–3: 自车在接近下一个可能位置时,首先/第二/第三会注意到什么对象?
规划阶段( P 3 P_3 P3):
- P 3 – 1 P_{3\text{–}1} P3–1: 自车可基于对象 X X X 的观察采取哪些行动?
- P 3 – 2 P_{3\text{–}2} P3–2: 自车的哪些行动可能导致与对象 X X X 的碰撞?
- P 3 – 3 P_{3\text{–}3} P3–3: 在这种情况下,自车有哪些安全行动?
3. 问题选择的依据
- 统计学:这些问题占所有QA对的60%,是三个阶段中最有代表性的问题。
- 主观重要性:这些问题能很好地模拟人类驾驶所需的信息。
4. 实验结果
-
观察点:
- 使用来自预测和规划阶段的QA对(ID 4-9)进行训练,相较于仅使用感知阶段的QA对(ID 1-3),性能显著提升。
- 添加规划阶段的QA对(ID 7-9)后,性能相比只使用预测阶段的QA对(ID 4-6)没有明显提升。
-
原因:
- 其他车辆的未来状态(预测阶段)已包含行为决策所需的大部分信息。
- 规划阶段的额外信息对行为预测的贡献较小。
5. 总结
- 关键结论:
- 预测阶段的QA对对行为预测最为重要。
- 规划阶段的附加信息可能对提升性能的作用有限。
- 应用价值:
- 结果表明,可以在实际系统中优先优化预测阶段的信息获取与建模。
4.4 Performance for P 1 P_1 P1− P 3 P_3 P3 via GVQA
1. 实验目标
- 建立基线结果,用于评估在GVQA任务中 P 1 P_1 P1- P 3 P_3 P3(感知、预测和规划)阶段的表现。
- 研究上下文信息对任务性能的影响。
2. 实验设置
模型:
- BLIP-2:
- 未在DriveLM数据集上微调的预训练模型。
- 用于零样本推理。
- DriveLM-Agent:
- 在DriveLM数据集上微调的模型。
上下文条件:
- 无上下文(None):
- 训练和测试中均不提供任何上下文。
- 类似标准VQA的设置,输入图像和问题,输出答案。
- 真实上下文(GT):
- 测试时提供真实的上下文信息(ground truth)。
- 模拟理想情况下的表现上限。
3. 实验结果
-
数据集的挑战性:
- DriveLM-nuScenes:
- 更具挑战性,所有上下文设置下的分数均低于DriveLM-CARLA。
- 可能因为nuScenes中人工标注的答案多样性更高。
- DriveLM-CARLA:
- 使用规则生成的答案,表现较为稳定,但多样性不足。
- DriveLM-nuScenes:
-
模型表现:
- DriveLM-Agent:
- 在所有上下文条件下显著优于BLIP-2。
- 展现了微调后的图结构模型在GVQA任务中的潜力。
- BLIP-2:
- 作为零样本模型,表现较弱。
- 表明预训练模型需要进一步微调以适应驾驶任务的复杂性。
- DriveLM-Agent:
4. 结论
- 上下文信息的重要性:
- 提供真实上下文(GT)显著提升了模型性能。
- 图结构上下文在提高模型理解驾驶任务方面显示出显著潜力。
- 模型设计的有效性:
- DriveLM-Agent展示了在多阶段任务上的强大能力,特别是在微调之后。
- BLIP-2虽然适合作为基线,但在复杂驾驶任务中表现有限。
Table 3: Question-wise analysis in DriveLM-nuScenes.
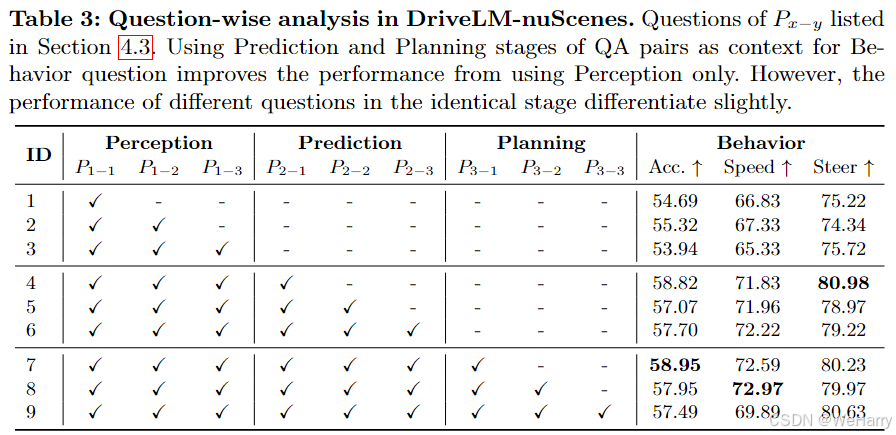
表3: DriveLM-nuScenes中的逐问题分析
内容:
- 不同的问答组合(QA pairs)作为上下文用于行为预测问题,研究这些组合对性能的影响。
- 指标:
- Acc.: 行为预测的分类准确率。
- Speed: 速度预测的分类准确率。
- Steer: 转向预测的分类准确率。
观察:
-
仅感知阶段(ID 1-3):
- 使用
P
1
P_1
P1(感知)阶段的问题,性能较低:
- I D 1 ID 1 ID1: Acc. = 54.69,Speed = 66.83,Steer = 75.22。
- 添加更多感知问题(如 P 1 – 2 P_{1\text{–}2} P1–2, P 1 – 3 P_{1\text{–}3} P1–3)性能略有提升,但幅度不大。
- 使用
P
1
P_1
P1(感知)阶段的问题,性能较低:
-
感知 + 预测阶段(ID 4-6):
- 引入预测阶段问题(
P
2
P_2
P2)显著提升性能:
- I D 4 ID 4 ID4: Acc. = 58.82,Speed = 71.83,Steer = 80.98。
- 证明预测问题(如对象的未来状态)对行为预测的影响较大。
- 引入预测阶段问题(
P
2
P_2
P2)显著提升性能:
-
感知 + 预测 + 规划阶段(ID 7-9):
- 添加规划阶段问题(
P
3
P_3
P3)后,性能略有提升,但幅度有限:
- I D 7 ID 7 ID7: Acc. = 58.95,Speed = 72.59,Steer = 80.23。
- 表明规划阶段的信息对行为预测的额外贡献有限。
- 添加规划阶段问题(
P
3
P_3
P3)后,性能略有提升,但幅度有限:
结论:
- 预测阶段( P 2 P_2 P2)的问题对行为预测的贡献最大。
- 感知和规划阶段的问题对性能的影响相对较小。
Table 4: Baseline P1−3 Results.
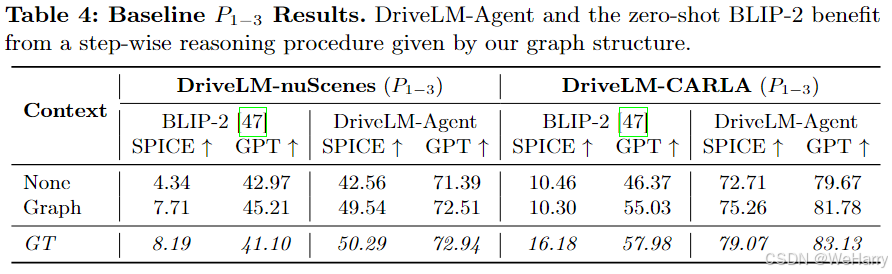
表4: P 1 P_1 P1- P 3 P_3 P3阶段的基线结果
内容:
-
比较DriveLM-Agent和BLIP-2在不同上下文条件下的表现:
- None: 无上下文。
- Graph: 图结构上下文。
- GT: 使用真实上下文。
-
指标:
- SPICE: 计算答案与真实答案的语义相似度。
- GPT: 使用GPT生成的语义对齐分数。
观察:
-
DriveLM-nuScenes:
- None:
- BLIP-2 (SPICE = 4.34, GPT = 42.97),显著低于DriveLM-Agent (SPICE = 42.56, GPT = 71.39)。
- Graph:
- 图上下文显著提升性能:
- BLIP-2:SPICE = 7.71,GPT = 45.21。
- DriveLM-Agent:SPICE = 49.54,GPT = 72.51。
- 图上下文显著提升性能:
- GT:
- 使用真实上下文时性能最高,DriveLM-Agent的GPT分数达到79.94。
- None:
-
DriveLM-CARLA:
- None:
- BLIP-2的表现为 (SPICE = 10.46, GPT = 46.56),DriveLM-Agent显著更高 (SPICE = 55.03, GPT = 72.71)。
- Graph:
- 图结构上下文提升DriveLM-Agent的SPICE分数至56.32,GPT分数至75.26。
- GT:
- 使用真实上下文,DriveLM-Agent表现最佳(SPICE = 79.07, GPT = 83.13)。
- None:
结论:
- DriveLM-Agent显著优于BLIP-2,表明微调后的模型在复杂驾驶任务上的优势。
- 图结构上下文(Graph)能够有效提升模型性能,但与真实上下文(GT)相比仍有差距。
总结
- 表3的逐问题分析表明:预测阶段的问题对行为预测的影响最大,而规划阶段的影响有限。
- 表4的基线结果验证了:DriveLM-Agent通过图结构上下文能够显著提升性能,但仍需进一步优化以接近真实上下文的表现。
5 Related Work
1. Autonomous Driving中的泛化问题
-
问题背景:
- 在自动驾驶(AD)系统中,泛化不足对“长尾问题”(corner cases)造成显著的安全隐患。
- 当前零样本性能不理想,这限制了AD系统应对未知场景或异常物体的能力。
-
已有研究:
- 数据驱动方法:
- 例如:TrafficSim通过仿真收集更多与安全相关的关键数据。
- 利用场景信息:
- 提出基于异常物体检测的方法。
- 局限性:
- 尽管有进展,但在泛化和零样本性能方面仍未达到令人满意的水平。
- 数据驱动方法:
-
本文贡献:
- 引入Graph VQA,结合逻辑推理,提出一种新的泛化方法。
2. Language-grounded Driving
-
现有方法:
- 许多同时期的方法尝试将多模态输入整合到大语言模型(LLMs)中以完成AD任务。
- 示例方法:
- GPT-Driver:将感知的场景状态编码为prompt,依赖LLMs生成合理的驾驶计划。
- LLM-Driver:类似方法,将场景信息用于合理规划。
- DriveGPT4:将原始传感器数据投影为离散tokens,利用LLMs进行控制信号和解释的端到端预测。
-
问题和局限性:
- 这些方法大多停留在初步尝试阶段。
- 在泛化能力和处理零样本问题方面,潜力尚未被充分挖掘。
-
本文贡献:
- 提出了一种新方法:
- 将视觉语言模型(VLMs)与DriveLM的图结构问答(GVQA)结合。
- 实现了零样本端到端规划的性能提升。
- 与现有研究相比,展示了在零样本驾驶任务中的显著优势。
- 提出了一种新方法:
3. 总结
- 创新点:
- 通过GVQA提升逻辑推理能力,解决泛化不足的问题。
- 在端到端驾驶中,提出了一种独特的VLM与LLMs结合的方法。
- 与现有方法对比:
- 本文的图结构问答方法(GVQA)弥补了现有研究在泛化和逻辑推理上的不足。
6 Discussion
1. 工作局限性
(1) 效率约束(Efficiency Constraints)
-
问题:
- 由于依赖LLMs(大语言模型),DriveLM-Agent面临推理时间长的问题。
- 使用图结构时需要多轮预测,导致推理速度约为UniAD的10倍慢。
- 表5数据显示:
- UniAD-Single:1.8 FPS(帧每秒)。
- DriveLM-Agent:0.16 FPS,主要由于吞吐量仅为8.5 tokens/s。
-
可能解决方法:
- LLM在最近几个月性能有显著提升(参考文献74, 100),吞吐量的提升可能缓解这一问题。
(2) 驾驶特定输入(Driving-specific Inputs)
- 问题:
- 当前模型仅处理前视低分辨率图像输入。
- 不支持驾驶特定传感器(如LiDAR)和360度场景的时间维度理解。
- 未来改进方向:
- 引入多模态和多帧输入以丰富上下文信息(例如结合多视角和时间序列数据)。
(3) 闭环规划(Closed-loop Planning)
-
问题:
- 当前实验基于开放环路规划(open-loop scheme),无法准确反映现实中的驾驶情景。
- 在现实中,闭环规划可能更有效,但可能带来更高的训练和计算成本。
-
未来改进方向:
- 扩展到闭环规划,通过引入自车状态输入,提升性能。
- 使用CARLA作为基础环境,推动闭环规划方向的进一步研究。
2. 总结
- 本文展示了如何利用VLMs作为端到端自动驾驶代理,提升泛化能力。
- 提出Graph VQA任务,并配套开发了新的数据集和评估指标。
- 构建了一个简单的基线架构(DriveLM-Agent),并取得了具有前景的结果。
Table 5
表5 数据补充

-
模型对比:
- 参数量(#Params):
- UniAD-Single:131.9M。
- DriveLM-Agent:3.955B(模型更复杂)。
- 训练参数(#Trainable):
- UniAD-Single:58.8M。
- DriveLM-Agent:12.9M。
- 推理成本(FLOPs):
- UniAD-Single:1.7T。
- DriveLM-Agent:24.2T。
- 参数量(#Params):
-
结论:
- DriveLM-Agent性能优越,但推理效率是当前主要瓶颈。


















 1840
1840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











