






2024.6.10-已更新至第五章,往后先弃坑一下
[1]付志能.基于文本及价量数据的股票及股指期货超短线预测研究[D].华南理工大学,2021.DOI:10.27151/d.cnki.ghnlu.2021.000194.
第一章 绪论(名词解释)
1.1研究的背景和意义
市场信息->量价信息+文本信息(股吧、新闻)(非结构化数据)(有专门的模型)
量化程序思路->即便只分析个股,仍不能忽略大环境
服从大数定律,所以更多人偏向短期多次的超短期交易
1.2研究的内容

分位数网格->传统模式是输出一个,而分位数网络是给出多个置信区间下的范围
非对称阈值->即手动控制权重,维护数据的平衡
随机占优模型->很多时间序列模型都要假设金融数据满足一定的分布,随机占优模型不用。随机占优模型通常是在给定随机变量的分布和决策变量的取值下,优化目标的最优解或最优策略。这可能包括最优的决策变量取值、最大化的期望效用值或最小化的期望成本值。
两个统计学名词
- 尖峰->如果尖峰度较高,表示分布中的数据在峰值附近更为集中
- 有偏->有偏描述了概率分布的偏斜程度,即数据分布的不对称性。右偏与左偏
插值网->插值网是一种用于在数据点之间估计数值的方法。它通常用于对离散数据进行平滑处理或填充缺失值。(线性orOther?)

①具体如何对应?
GPT的回答:对于尖峰的数据,可以在尖峰附近使用更密集的网格,以更精细地描述数据分布的特征。让我们暂且作为问题①保留。
"实证研究还分析了2015年股灾、中金所的股指期货严格监 管措施、中金所的逐步松绑政策对股指期货及股票的市场有效性的影响,发现中金所 的严格监管措施对市场有效性的损伤比股灾更为严重,而且中金所的逐步松绑政策对 市场有效性的修复作用很有限。"
2015年股灾是中国股市历史上的一次重大事件,其影响涉及到股票市场、股指期货市场以及监管政策等多个方面。
2015年股灾:
2015年6月中旬至7月初,中国股票市场发生了一轮剧烈的下跌,导致股票价格急剧下跌,投资者损失惨重。这次股灾的起因复杂,包括过度杠杆、股市炒作热情过高、监管措施不力等多种因素的综合作用。政府出台了一系列措施,包括暂停新股发行、暂停熔断机制等,以遏制市场的恐慌情绪和价格下跌。
中金所股指期货严格监管措施:
在股灾发生后,为了维护金融市场的稳定,中国证监会和中国金融期货交易所(中金所)采取了一系列严格的监管措施,尤其是对于股指期货市场。这些措施包括加大对期货市场违规行为的处罚力度、加强期货市场风险管理和监测等。目的是通过加强监管,遏制期货市场的过度波动,减少市场风险,保护投资者利益。
中金所的逐步松绑政策:
随着时间的推移,中国证监会和中金所逐步松绑了部分股指期货市场的限制措施,以促进市场的稳定发展。这些政策包括逐步恢复股指期货合约的交易、调整交易保证金标准、优化交易机制等。这些举措旨在提高市场的流动性、降低交易成本、增加市场活跃度,从而促进股票和股指期货市场的有效性和稳定性。
总的来说,2015年股灾对中国股票市场和股指期货市场都造成了严重的冲击,导致投资者信心受损、市场波动加剧。监管部门和交易所采取了一系列措施来应对市场的不稳定性,包括严格监管措施和逐步松绑政策,以维护市场的稳定并促进市场的健康发展。这些措施在一定程度上缓解了市场的恐慌情绪,有助于重建投资者信心和市场秩序。

隔夜跳空->相邻两个交易日之间开盘价和前一个交易日收盘价之间存在显著的价格差距

参数迁移->参数迁移是指从一个任务或领域中学习到的模型参数被转移到另一个相关任务或领域中。这种方法适用于目标任务数据量较小或与预训练数据有一定相似性的情况。
分类器优化->分类器优化是指对分类器(如神经网络中的输出层)进行调整和优化,以提高其性能和泛化能力。
总结一下:
- 改进了随机占优模型(插值网+分位数网格+非对称阈值解决数据的缺失、尖峰、有偏问题)
- 基于交易日分段编码(?)构造分层LSTM模型+基于股票交叉影响构造另一个模型,两者相结合,得到超短线股指期货预测模型。
- 重构多元时间序列模型:引入被预测资产和其他资产的权重+用情感词典法引入股吧情感因子作为外生变量
- 将优化后的BERT文本解析模型配上自制的关键词库,分析新闻对股票的极性
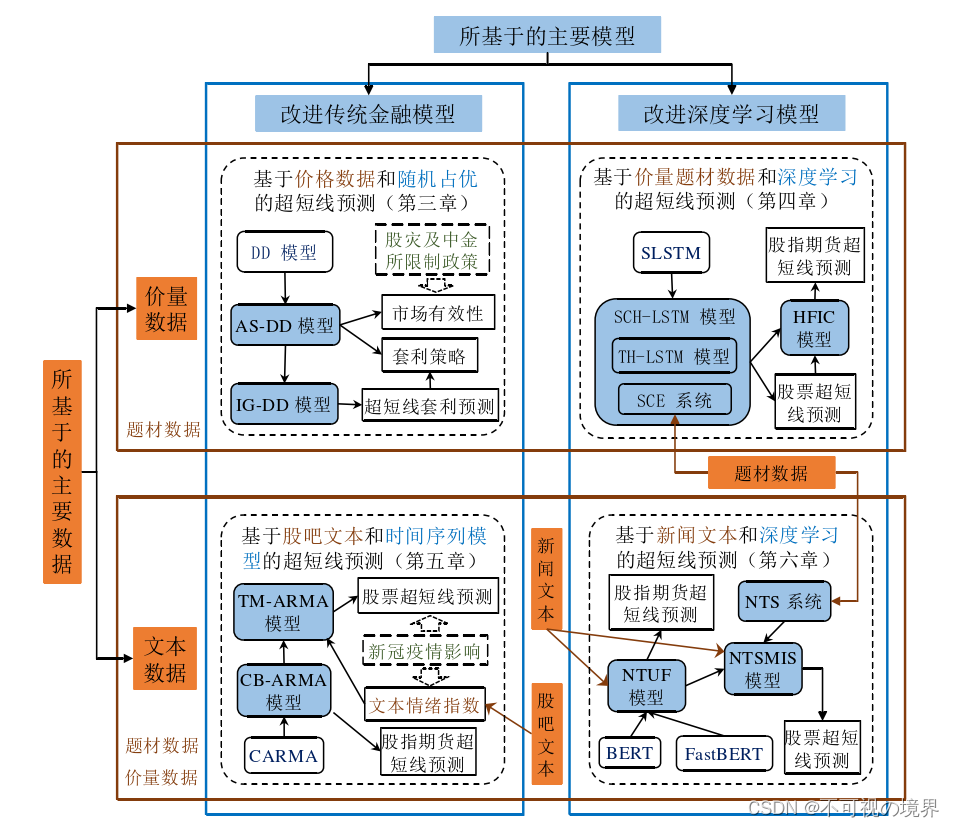
第二章 文献综述

简单理解为算了以最低收益率为底,发生概率×值获得期望收益率超出最低收益率多少,然后升序排序,投资者偏好超出最低的那一只股票。(?)

高维稀疏向量是指在一个高维度的向量空间中,大部分元素都是零(稀疏),只有少数元素具有非零值(高维)。在文本处理中,词袋模型通常将每个文档表示为一个向量,其中每个维度对应一个词语,而向量的每个元素表示对应词语在文档中出现的频率或者其他统计信息。

单纯的贴张图。。
第三章 基于价格数据和随机占优的股指期货超短线预测

通过对一阶随机占优和二阶随机占优的研究,作者划分了不同时间下的有效市场和无效市场。

作者解释了分位数网格和非对称阈值在模型里的作用(和之前的理解差不多,)继而提出了IG-DD模型用于超短线投资
(申し訳ございません,这里放总结是因为那部分文章没保存下来,放张图试图萌混过关>_<)


优化

运行流程

②避免隔夜跳空就是不持仓过夜?
绪论里提到的交易日编码呢?

在量化金融中,二阶和三阶随机占优通常指的是对价格序列进行二阶和三阶微分的过程。这种微分可以揭示价格变化的加速度和变化率的变化率,提供更多关于价格动态的信息。
在这种情况下,一阶随机占优通常是通过价格序列的一阶微分来计算的,代表价格的变化率。而二阶和三阶随机占优分别是通过价格序列的二阶和三阶微分来计算的,代表价格变化率的变化率和加速度的变化率。
由于二阶和三阶微分涉及对价格序列进行更多次数的导数操作,因此更高阶的随机占优可能会受到数据噪音的影响,且更容易受到价格序列的短期波动的影响。因此,尽管二阶和三阶随机占优提供了更多关于价格动态的信息,但在某些情况下,由于其更高的灵敏度,可能会更容易受到数据的干扰。
总的来说,一阶随机占优通常涉及价格的一阶变化率,而二阶和三阶随机占优涉及价格变化率的变化率和加速度的变化率,尽管它们提供了更多的信息,但也更容易受到噪音和短期波动的影响。因此,在实践中,需要综合考虑不同阶段的随机占优,并结合其他指标和模型来进行交易决策。
第四章 基于价量题材数据和深度学习的股票及股指期货超短线预测
4.1 TH-LSTM
 SLSTM模型解释
SLSTM模型解释

上下层的定义,后面有解释:
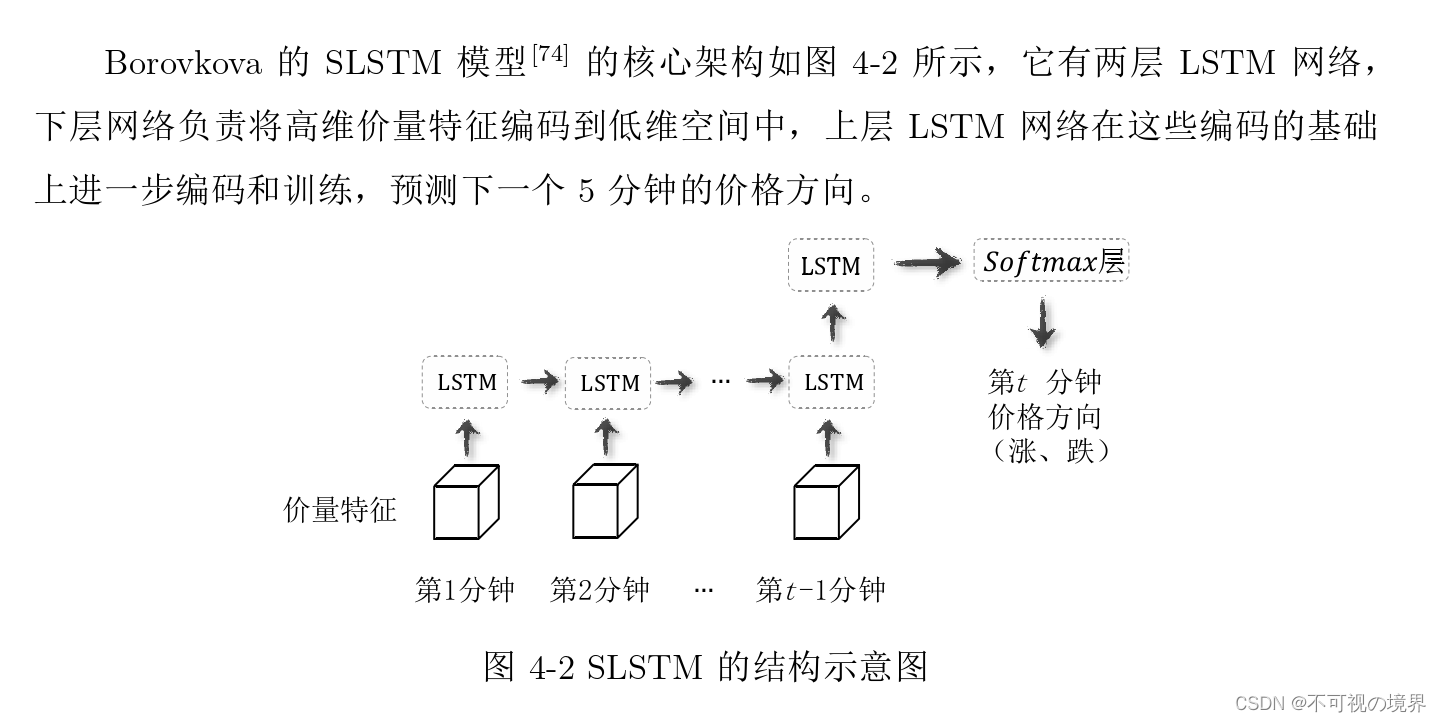

看说法SCE编码并没有数学的量化。(错误的,后面有)
让我们回到这个TH-LSTM模型


是指每天的分钟数据输入到下层,简化为1个“天数据”,然后当日的分钟数据配上其他日子的“天数据”输入到上层,获得最终结果kana。与提升整体速度相应的,单个交易日分钟数据蕴含的信息丢失很多。
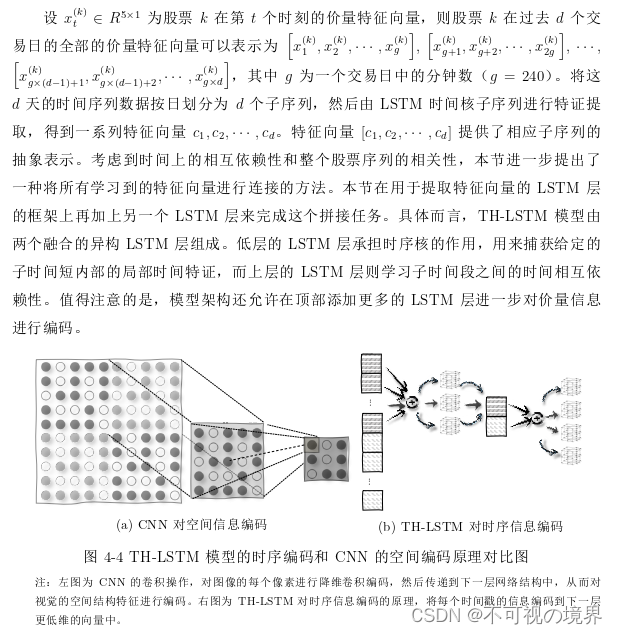
差不多(心虚)
4.2 SCE编码

没啥好说的

(红圈里的乱码是CAJ的锅?)
内积是将两个向量对应位置的元素分别相乘,然后将所有乘积相加起来得到的一个标量值。
如他所说,关联度越强,αt越大。那么Qt究竟是什么呢,快端上来罢


(像极了我论文里的某些故弄玄虚的指标)
 还记得上面说的吗。Xt和Qt是两个基础变量,Xt包含基本面信息,Qt股票题材是否关联(指的是多维上表现为0和1,具体是631个题材因此向量大小是1x631),Vt是Xt的衍生品,αt则是Qt的标准版(即量化后的两股关联度)。互乘起来的原因博主也不懂。。
还记得上面说的吗。Xt和Qt是两个基础变量,Xt包含基本面信息,Qt股票题材是否关联(指的是多维上表现为0和1,具体是631个题材因此向量大小是1x631),Vt是Xt的衍生品,αt则是Qt的标准版(即量化后的两股关联度)。互乘起来的原因博主也不懂。。
4.3 发动米米尔隆的融合!
 将上述两种结合成最终的LSTM模型
将上述两种结合成最终的LSTM模型

TH-LSTM提供技术面因子,SCE系统提供股票关联度因子,两者再结合

4.4 模拟

哥们也不懂为什么是20和600,以后被问我就说作者说引用文献说是这两个数据。

非常易懂了,想要再提高训练强度可以用交叉验证法。(过拟合可能)

本文对于隔夜跳空的优化①输入数据直接分层,将每个交易日单独LSTM一次②预测数据直接跳过第一分钟,规避昨日最后一分钟的数据
因子数据方面,用变化率而非原值,必须要用原值时进行标准化再食用(值得参考)

评价指标:
是的,准确率(accuracy)、精确率(precision)、召回率(recall)和F1值是分类问题中常见的评价指标,用于评估模型的性能。它们通常用于评估二分类问题,但也可以扩展到多分类问题。
1.准确率(Accuracy):准确率是指模型预测正确的样本数量与总样本数量的比率。它是最简单直观的评价指标之一,计算公式为:
2.精确率(Precision):精确率是指模型在预测为正类别的样本中,确实是正类别的比例。它衡量了模型的预测的准确性,计算公式为:
3.召回率(Recall):召回率是指正类别样本中被模型正确预测为正类别的比例。它衡量了模型对正类别样本的识别能力,计算公式为:
4.F1值(F1 Score):F1值是精确率和召回率的加权调和平均值,综合考虑了两者的性能。它是一个综合评价指标,可以帮助平衡精确率和召回率之间的关系,计算公式为:2AB/(A+B)
A为精确率(Precision),B为召回率(Recall)


竟然还算上交易费用了。。

我释放绝命乱斗。。。

SCE编码对准确率的提升竟然这么小。。

别说了,牛
4.5 SCH-LSTM模型编码器的可视化解析



热力图印证了分类能力
4.6 基于SCH-LSTM模型的股指期货超短线预测研究
(还有高手?)在SCH-LSTM模型的基础上,本节提出一个基于成分股的股票指数超短线预测模 型(UFIC模型),如图4-12所示,分为如下步骤。


基本就是多支股票预测值(-1,0,1)作为权重乘以流通量,再sigma,以此得到股指期货的预测值。


作者发现三个股指有不同,遂用基差论解释
第五章 基于股吧文本和时间序列模型的股票及股指期货超短线预测


就是提升了自回归的权重
















 3374
3374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









