






一、个人任务
我的任务主要有以下两个
- 对后端进行单元测试及集成测试等,找出存在的功能、性能等问题
- 针对存在的问题进一步改进后端
二、任务1——测试后端
这里主要展示几个不同类型的后端问题
1.问题1:requests.exceptions.SSLError: HTTPSConnectionPool(host=‘huggingface.co‘, port=443): Max ret
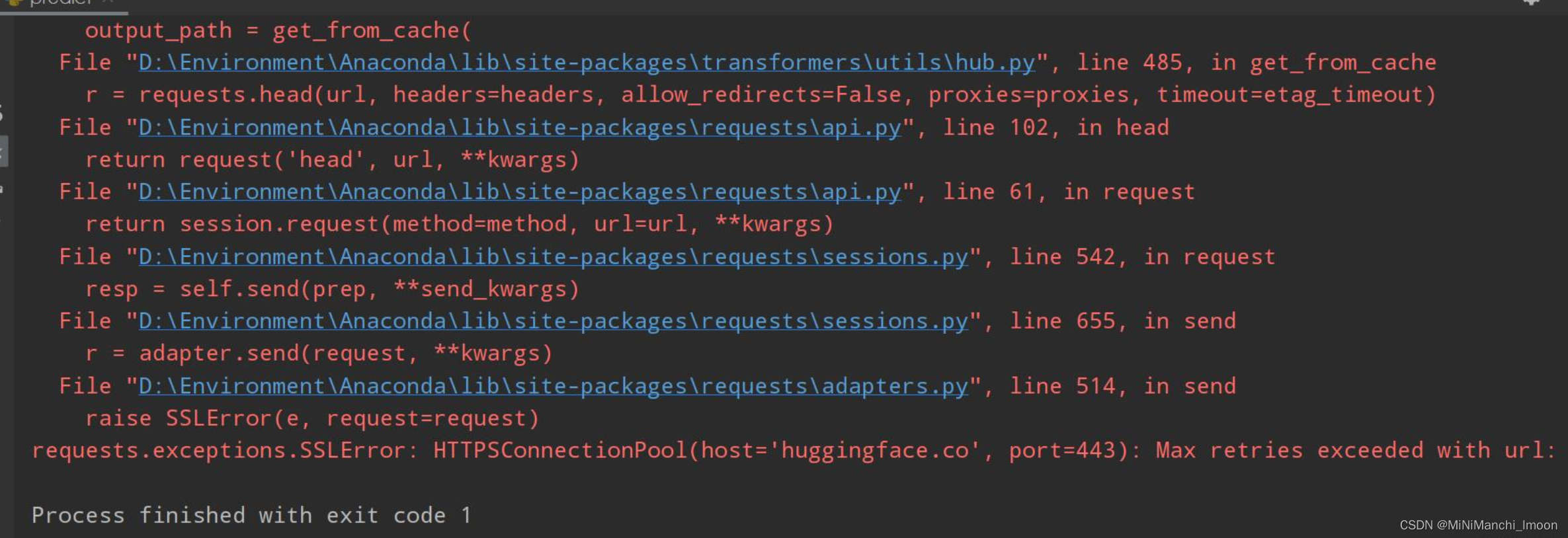
解决过程:出现问题的原因是运行程序的时候没有联网,但是使用了未下载的chatGLM模型。我们可以将模型手动下载,然后放入到对应文件夹即可。
2.问题2:文件编码格式报错

解决过程:
对于Unicode字符,python解释器需要先将Unicode字符编码为GBK,然后再写入csv文件。但是由于该Unicode字符串中包含一些GBK中无法显示的字符,导致此时提示“’gbk’ codec can’t encode”的错误。
解决方法:尝试了许多网上的解决方案,最后设置了一下输出结果存放的csv文件的编码格式,解决了问题。
3.ValueError: not enough values to unpack (expected 2, got 1)
- 分析原因:原因:由于自定义的idf语料库的txt文件中,存在空行或换行符\n,以及存在△、$等特殊字符。
- 解决方法:写了两个函数,用于去除空行、换行符和特殊字符,只保留中文和英文字符。
# 去掉每行头尾空格及空行、换行符\n
def clearBlankLine(lines):
result = []
for line in lines:
line = line.strip() # 去掉每行头尾空格
if not len(line): # 如果是空行
continue
result.append(line)
return result
# 去掉特殊字符,只保留中英文字符
def clearSpecialSymbols(lines):
result = []
for line in lines:
valid1 = re.search('^[a-zA-Z]',line)
valid2 = re.search('^[\u4e00-\u9fa5]',line)
if valid1 or valid2:
result.append(line)
return result
4.RuntimeError: view size is not compatible with input tensor‘s size and stride
分析问题:在PyTorch中,view() 函数用于重新调整张量(Tensor)的形状,而不改变其数据。然而,view() 操作有一个重要的前提:新形状下的元素必须是连续存储的(contiguous)。这意味着张量中的元素在内存中是连续排列的,没有间隔或“空洞”。
解决问题:为了解决这个问题,可以使用 .contiguous() 方法来返回张量的一个连续副本。这个操作会重新排列张量中的元素,以确保它们在内存中是连续存储的。然后,就可以在这个连续副本上使用 view() 了。
使用下面这一行代码即可
out = out.contiguous().view(out.size()[0], -1)
5.TypeError: can't multiply sequence by non-int of type 'numpy.float64'
can't multiply sequence by non-int of type 'float'
分析问题:这个问题表明,我们正在将这些序列中的任何一个(通常是一个字符串和一个元组)与一个浮点数(小数)相乘。但是我们可以将一个序列与一个数字相乘,如下,不会报错
site_name = 'freeCodeCamp '
print(site_name * 2)
# freeCodeCamp freeCodeCamp
print(site_name * 3)
# freeCodeCamp freeCodeCamp freeCodeCamp
stringfied_num = '10 '
print(stringfied_num * 3)
# 10 10 10解决方法:进行np.array(),将这个序列变成矩阵就可以
三、任务2——改进后端
对后端初步的改进是主要是针对后端进行分层处理,主要分为以下几层:
- 分离数据库连接和查询逻辑:创建一个数据库服务层来处理数据库连接和查询。
- 定义数据模型:用于表示从数据库中检索到的数据。
- 创建服务层:处理业务逻辑,如根据用户ID检索记录。
- 创建控制器:处理HTTP请求,调用服务层函数,并返回适当的HTTP响应。
- 添加错误处理和日志记录(此处未详细展示)。
初步是针对数据库连接和数据模型的优化,我适当的增加更多的功能、异常处理、日志记录以及注释,使得代码更加健壮和易于理解。
1.数据库连接和查询逻辑(优化后)
# -*- coding:utf-8 -*-
"""
功能:连接数据库,封装了操作数据库的增删改查等常见操作函数
"""
import pymysql
import logging
class DBUtils(object):
_db_conn = None
_db_cursor = None
def __init__(self, host, user, password, db, port=3306, charset='utf8'):
"""
初始化数据库连接
:param host: 数据库主机名
:param user: 数据库用户名
:param password: 数据库密码
:param db: 数据库名
:param port: 数据库端口,默认为3306
:param charset: 字符集,默认为utf8
"""
self.connect_to_db(host, user, password, db, port, charset)
def connect_to_db(self, host, user, password, db, port=3306, charset='utf8'):
"""
建立数据库连接
:param host: 数据库主机名
:param user: 数据库用户名
:param password: 数据库密码
:param db: 数据库名
:param port: 数据库端口
:param charset: 字符集
"""
try:
self._db_conn = pymysql.connect(host=host, user=user, password=password, port=port, db=db, charset=charset)
self._db_cursor = self._db_conn.cursor()
logging.info("数据库连接成功")
except pymysql.MySQLError as e:
logging.error(f"数据库连接失败: {e}")
raise
def __del__(self):
"""
析构函数,关闭数据库连接
"""
self.close_connection()
def close_connection(self):
"""
关闭数据库连接和游标
"""
try:
if self._db_cursor:
self._db_cursor.close()
self._db_cursor = None
if self._db_conn:
self._db_conn.close()
self._db_conn = None
logging.info("数据库连接已关闭")
except Exception as e:
logging.error(f"关闭数据库连接时发生错误: {e}")
def reconnect(self, host, user, password, db, port=3306, charset='utf8'):
"""
重新建立数据库连接
:param host: 数据库主机名
:param user: 数据库用户名
:param password: 数据库密码
:param db: 数据库名
:param port: 数据库端口
:param charset: 字符集
"""
try:
self._db_conn.close()
self._db_conn = None
self._db_cursor = None
self.connect_to_db(host, user, password, db, port, charset)
except Exception as e:
logging.error(f"重新连接数据库时发生错误: {e}")
def execute_sql(self, sql_str, args=None):
"""
执行SQL语句,并返回受影响的行数
:param sql_str: SQL语句
:param args: 参数列表
:return: 受影响的行数
"""
try:
if args is None:
args = ()
self._db_cursor.execute(sql_str, args)
return self._db_cursor.rowcount
except pymysql.MySQLError as e:
logging.error(f"执行SQL语句时发生错误: {e}, SQL: {sql_str}")
return -1
def get_one(self, sql_str, args=None):
"""
查询单个结果,返回具体的数据内容
:param sql_str: SQL语句
:param args: 参数列表
:return: 查询结果(单个)
"""
try:
result = self.execute_sql(sql_str, args)
if result == -1:
return None
return self._db_cursor.fetchone()
except pymysql.MySQLError as e:
logging.error(f"获取单个结果时发生错误: {e}")
return None
# 查询特定
def get_oneById(self, sql_str, args):
"""
查询单个结果,返回具体的数据内容
:param sql_str: sql语句
:param args: 参数列表
:return: result
"""
try:
if self._db_conn is None or self._db_cursor is None:
# 如果连接或游标为空,可能需要重新连接或初始化游标
self.connect_to_db() # 调用连接数据库的方法
if args is None:
args = () # 如果没有提供参数,则使用空元组
self._db_cursor.execute(sql_str, args) # 使用参数执行SQL语句
result = self._db_cursor.fetchone()
return result
except Exception as e:
logging.error(f"执行SQL查询时发生错误: {e}")
return None # 或者可以抛出一个异常
def execute_many(self, sql_str, args_list):
"""
执行多条SQL语句(通常用于批量插入或更新)
"""
try:
self._db_cursor.executemany(sql_str, args_list)
return self._db_cursor.rowcount
except Exception as e:
logging.error(f"执行多条SQL语句时发生错误: {e}")
return -1
# 查询多个结果
def get_all(self, sql_str, args=None):
"""
查询多个结果,返回元组对象
:param sql_str: sql 语句
:param args: 参数列表
:return: result
"""
try:
if self._db_conn is not None:
self._db_cursor.execute(sql_str, args=args)
result = self._db_cursor.fetchall()
return result
else:
logging.error("请检查数据库连接")
except Exception as e:
logging.error(e)
# 插入数据
def insert(self, sql_str, args=None):
"""
向数据库插入数据,返回影响行数(int)
:param sql_str: sql 语句
:param args: 参数列表
:return: affect_rows
"""
try:
if self._db_conn is not None:
affect_rows = self._db_cursor.execute(sql_str, args=args)
self._db_conn.commit()
return affect_rows
else:
logging.error("请检查数据库连接")
except Exception as e:
self._db_conn.rollback()
logging.error(e)
# 修改数据
def modify(self, sql_str, args=None):
"""
更新数据,返回影响行数(int)
:param sql_str: sql 语句
:param args: 参数列表
:return: affect_rows
"""
return self.insert(sql_str=sql_str, args=args)
# 删除数据
def delete(self, sql_str, args=None):
"""
删除数据,返回影响行数(int)
:param sql_str: sql 语句
:param args: 参数列表
:return: affect_rows
"""
return self.insert(sql_str=sql_str, args=args)
def __del__(self):
"""
程序运行结束后,会默认调用 __del__ 方法
销毁对象
"""
if self._db_conn is not None:
self._db_cursor.close()
self._db_conn.close()
2.定义数据模型
这一部分主要是针对图片地址的处理,进行base64编码解码
import base64
import binascii
class Record:
def __init__(self, **kwargs):
self.__dict__.update(kwargs)
def to_dict(self):
# 对图片地址进行额外处理,解码base64
if 'question' in self.__dict__ and isinstance(self.__dict__['question'], str):
try:
# 尝试解码base64字符串为字节数据
decoded_bytes = decode_base64(self.__dict__['question'])
# 我们只是简单地将字节数据存储在'question'属性中
self.__dict__['question'] = decoded_bytes
except (ValueError, binascii.Error):
# 如果解码失败,可以记录错误或采取其他措施
print("Error decoding base64 string for 'question'")
return self.__dict__.copy() # 返回字典的副本,避免外部修改影响实例内部状态
def decode_base64(encoded_str):
# 真正的base64解码逻辑
try:
# 添加'data:image/jpeg;base64,'这样的前缀的字符串需要先去除这些前缀
decoded_bytes = base64.b64decode(encoded_str)
return decoded_bytes
except (ValueError, binascii.Error) as e:
# 如果解码失败,抛出异常或返回None等
print(f"Error decoding base64 string: {e}")
return None 四、总结
1、测试阶段
在本次任务中,我主要负责对后端进行单元测试和集成测试,以发现潜在的功能和性能问题。
-
单元测试:我针对后端代码中的关键模块和函数编写了详细的单元测试案例,确保每个模块都能按照预期工作。通过单元测试,我发现了几个逻辑错误和边界条件处理不当的问题,并立即进行了修复。
-
集成测试:在单元测试通过后,我进行了集成测试,模拟了实际业务场景中的请求和响应。通过集成测试,我发现了几个模块间交互时出现的问题,如数据不一致、接口调用错误等。针对这些问题,我进行了深入的分析和调试,最终解决了这些问题。
-
性能测试:在测试过程中,我还对后端进行了性能测试,包括响应时间、吞吐量、并发处理能力等指标。通过性能测试,我发现了一些性能瓶颈和优化点,为后续的改进提供了方向。
2、改进阶段
在测试阶段发现问题后,我针对这些问题进行了后端的改进工作。
-
代码优化:针对逻辑错误和边界条件处理不当的问题,我重新审查了相关代码,并进行了优化和重构。通过优化代码结构、提高代码可读性和可维护性,我减少了潜在的错误和缺陷。
-
模块间交互优化:针对模块间交互时出现的问题,我重新梳理了模块间的依赖关系和调用流程,并进行了必要的调整和优化。通过优化模块间的交互方式,我提高了系统的稳定性和可靠性。
-
性能优化:针对性能测试中发现的问题,我进行了针对性的优化工作。通过优化数据库查询、减少不必要的网络请求、使用缓存等技术手段,我提高了系统的响应速度和吞吐量。
3、总结
通过本次任务,我对有效的测试和改进。测试阶段不仅帮助我发现了后端存在的问题。在改进阶段,我通过优化代码、调整模块间交互方式和提高系统性能等措施,成功解决了存在的问题,并提高了后端的质量和稳定性。
















 4271
4271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









