







3.2.了解训练效率
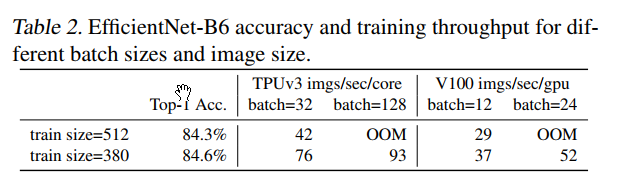
我们研究了 EfficientNet (Tan & Le, 2019a) 的训练瓶颈,以下也称为 EfficientNetV1,以及一些提高训练速度的简单技术。使用非常大的图像尺寸进行训练很慢:正如之前的作品 (Radosavovic et al., 2020) 所指出的那样,EfficientNet 的大图像尺寸会导致大量内存使用。由于 GPU/TPU 上的总内存是固定的,我们必须以较小的批大小训练这些模型,这大大减慢了训练速度。一个简单的改进是应用 FixRes(Touvron 等人,2019 年),通过使用比推理更小的图像尺寸进行训练。如表 2 所示,较小的图像尺寸导致较少的计算并支持大批量,从而将训练速度提高多达 2.2 倍。值得注意的是,正如 (Touvron et al., 2020; Brock et al., 2021) 中所指出的,使用较小的图像尺寸进行训练也会导致准确性稍好一些。但与 (Touvron et al., 2019) 不同的是,我们不会在训练后对任何层进行微调。在第 4 节中,我们将探索更高级的训练方法,通过在训练期间逐步调整图像大小和正则化
Depthwise convolutions在早期层中很慢:EfficientNet 的另一个训练瓶颈来自广泛的Depthwise convolutions(Sifre,2014)。 Depthwise 卷积比常规卷积具有更少的参数和 FLOP,但它们通常不能充分利用现代加速器。最近,Fused-MBConv 在 (Gupta & Tan, 2019) 中提出,后来在 (Gupta & Akin, 2020; Xiong et al., 2020; Li et al., 2021) 中使用,以更好地利用移动或服务器加速器。如图2所示,它用单个常规conv3x3替换了MBConv中的深度conv3x3和扩展conv1x1(Sandler等人,2018; Tan&Le,2019a),如图2所示。为了系统地比较这两个构件,我们逐步替换了原始的MBConv在 EfficientNetB4 中使用 Fused-MBConv(表 3)。在早期阶段 1-3 中应用时,Fused-MBConv 可以在参数和 FLOPs 的开销很小的情况下提高训练速度,但是如果我们用 Fused-MBConv(阶段 1-7)替换所有块,那么它会显着增加参数和 FLOPs,同时也减慢了训练。找到这两个构建块 MBConv 和 Fused-MBConv 的正确组合非常重要,这促使我们利用神经架构搜索来自动搜索最佳组合。

图 2. MBConv 和 Fused-MBConv 的结构

每个阶段均等地扩展是次优的:EfficientNet 使用简单的复合扩展规则同等地扩展所有阶段。例如,当深度系数为 2 时,网络中的所有阶段都会使层数增加一倍。然而,这些阶段对训练速度和参数效率的贡献并不相同。在本文中,我们将使用非均匀缩放策略来逐步添加 到后期阶段。此外,EfficientNets 积极扩大图像大小,导致大量内存消耗和缓慢训练。为了解决这个问题,我们稍微修改了缩放规则并将最大图像尺寸限制为较小的值。
3.3.训练感知 NAS 和扩展
为此,我们学习了多种设计选择以提高训练速度。为了搜索这些选择的最佳组合,我们现在提出一种具有培训意识的NAS。
NAS 搜索:我们的训练感知 NAS 框架主要基于之前的 NAS 工作(Tan 等人,2019 年;Tan & Le,2019a),但旨在共同优化现代加速器的准确性、参数效率和训练效率。具体来说,我们使用 EfficientNet 作为我们的主干。 我们的搜索空间是一个类似于 (Tan et al., 2019) 的基于阶段的分解空间,它由卷积运算类型 fMBConv、Fused-MBConvg、层数、内核大小 f3x3、5x5g、扩展率 f1 的设计选择组成, 4, 6g。另一方面,我们通过(1)删除不必要的搜索选项(例如池化跳过操作)来减小搜索空间大小,因为它们从未在原始 EfficientNet 中使用; (2) 从主干中重用相同的通道大小,因为它们已经在 (Tan & Le, 2019a) 中搜索过。由于 搜索空间更小,我们可以应用强化学习(Tan 等人,2019 年)或简单地在与 EfficientNetB4 大小相当的更大网络上进行随机搜索。具体来说,我们对多达 1000 个模型进行了采样,并对每个模型进行了大约 10 个 epoch 的训练,并减少了用于训练的图像大小。我们的搜索奖励结合了模型精度 A、归一化训练步骤时间 S 和参数大小 P,使用简单的加权乘积 A·Sw·Pv,其中 w = -0.07 和 v = -0.05 是根据经验确定的超参数平衡类似于(Tan et al., 2019)的权衡。
EfficientNetV2 架构:表 4 显示了我们搜索的模型 EfficientNetV2-S 的架构。 与 EfficientNet 主干相比,我们搜索的 EfficientNetV2 有几个主要区别:(1)第一个区别是 EfficientNetV2 广泛使用 MBConv(Sandler et al., 2018; Tan & Le, 2019a)和新添加的 fused-MBConv(Gupta & Tan, 2019) 在早期层。 (2) 其次,EfficientNetV2 更喜欢 MBConv 的较小扩展率,因为较小的扩展率往往具有较少的内存访问开销。 (3) 第三,EfficientNetV2 更喜欢较小的 3x3 内核大小,但它增加了更多层以补偿较小内核大小导致的感受野减少。 (4) 最后,EfficientNetV2 完全删除了原始 EfficientNet 中的最后一个 stride-1 阶段,可能是由于其较大的参数大小和内存访问开销。
EfficientNetV2 缩放:我们使用与 (Tan & Le, 2019a) 类似的复合缩放来扩展 EfficientNetV2-S 以获得 EfficientNetV2-M/L,并进行一些额外的优化:(1) 我们将最大推理图像大小限制为 480,因为非常 大图像通常会导致昂贵的内存和训练速度开销; (2) 作为启发式方法,我们还逐渐向后期阶段(例如表 4 中的阶段 5 和 6)添加更多层,以在不增加太多运行时开销的情况下增加网络容量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1089
1089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









