







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
DenseNets 不是从极深或极宽的架构中汲取表征能力,而是通过特征重用来利用网络的潜力,产生易于训练且参数效率高的浓缩模型。连接不同层学习的特征图会增加后续层输入的变化并提高效率。这构成了 DenseNets 和 ResNets 之间的主要区别。与也连接来自不同层的特征的 Inception 网络 [36, 37] 相比,DenseNets 更简单、更高效。
还有其他显着的网络架构创新已经产生了有竞争力的结果。网络中的网络 (NIN) [22] 结构将微型多层感知器包含在卷积层的过滤器中,以提取更复杂的特征。在深度监督网络(DSN)[20]中,内部层由辅助分类器直接监督,这可以加强早期层接收到的梯度。梯形网络 [27, 25] 将横向连接引入自动编码器,在半监督学习任务上产生令人印象深刻的准确性。在 [39] 中,提出了深度融合网络 (DFN),通过组合不同基础网络的中间层来改善信息流。具有最小化重建损失的路径的网络增强也被证明可以改进图像分类模型 [43]
======================================================================
考虑通过卷积网络的单个图像 x 0 x_{0} x0。 该网络由 L 层组成,每一层都实现了一个非线性变换 H ℓ ( ⋅ ) H_{\ell} (·) Hℓ(⋅),其中 ℓ \ell ℓ索引了层。 H ℓ ( ⋅ ) H_{\ell} (·) Hℓ(⋅) 可以是诸如批量归一化 (BN) [14]、整流线性单元 (ReLU) [6]、池化 [19] 或卷积 (Conv) 等操作的复合函数。 我们将 ℓ t h \ell^{th} ℓth的输出表示为 x ℓ x_{\ell} xℓ。
ResNets。 传统的卷积前馈网络将 ℓ t h \ell^{th} ℓth的输出作为输入连接到 ( ℓ + 1 ) t h (\ell+1)^{th} (ℓ+1)th层 [16],从而产生以下层转换: x ℓ = H ℓ ( x ℓ − 1 ) \mathbf{x}_{\ell}=H_{\ell}\left(\mathbf{x}_{\ell-1}\right) xℓ=Hℓ(xℓ−1)。 ResNets [11] 添加了一个跳过连接,它绕过了具有恒等函数的非线性变换:
x ℓ = H ℓ ( x ℓ − 1 ) + x ℓ − 1 (1) \mathbf{x}_{\ell}=H_{\ell}\left(\mathbf{x}_{\ell-1}\right)+\mathbf{x}_{\ell-1} \tag{1} xℓ=Hℓ(xℓ−1)+xℓ−1(1)
ResNets 的一个优点是梯度可以直接通过恒等函数从后面的层流到前面的层。 然而,恒等函数和 H ℓ H_{\ell} Hℓ的输出是通过求和组合的,这可能会阻碍网络中的信息流动。
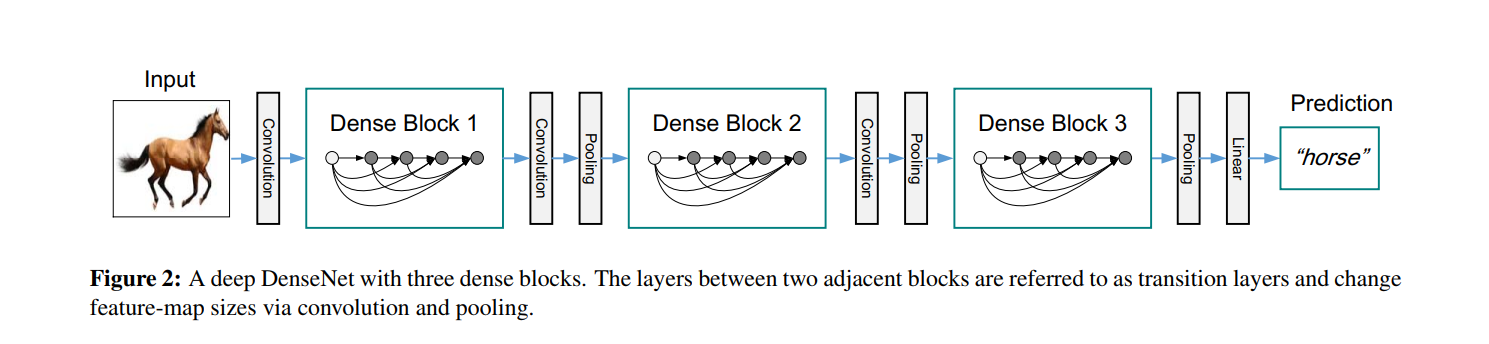
密集连接。 为了进一步改善层之间的信息流,我们提出了一种不同的连接模式:我们引入了从任何层到所有后续层的直接连接。 图 1 示意性地说明了生成的 DenseNet 的布局。 因此, ℓ t h \ell^{th} ℓth层接收所有前面层的特征图, x 0 , … , x ℓ − 1 \mathbf{x}_{0}, \ldots, \mathbf{x}_{\ell-1} x0,…,xℓ−1,作为输入:
x ℓ = H ℓ ( [ x 0 , x 1 , … , x ℓ − 1 ] ) (2) \mathbf{x}_{\ell}=H_{\ell}\left(\left[\mathbf{x}_{0}, \mathbf{x}_{1}, \ldots, \mathbf{x}_{\ell-1}\right]\right) \tag{2} xℓ=Hℓ([x0,x1,…,xℓ−1])(2)
其中 [ x 0 , x 1 , … , x ℓ − 1 ] \left[\mathbf{x}_{0}, \mathbf{x}_{1}, \ldots, \mathbf{x}_{\ell-1}\right] [x0,x1,…,xℓ−1] 指的是层$ 0,…,\ell-1$ 中产生的特征图的串联。 由于其密集的连接性,我们将这种网络架构称为密集卷积网络 (DenseNet)。为了便于实现,我们将等式(2) 中 H ℓ ( ⋅ ) H_{\ell} (·) Hℓ(⋅)的多个输入连接成单个张量。
复合功能。 受 [12] 的启发,我们将 H ℓ ( ⋅ ) H_{\ell} (·) Hℓ(⋅) 定义为三个连续操作的复合函数:批量归一化 (BN) [14],然后是整流线性单元 (ReLU) [6] 和 3 × 3 卷积( Conv)。
池化层。 当特征图的大小发生变化时,等式(2)中使用的连接操作是不可行的。 然而,卷积网络的一个重要部分是改变特征图大小的下采样层。 为了在我们的架构中进行下采样,我们将网络划分为多个密集连接的密集块; 参见图 2。我们将块之间的层称为过渡层,它们进行卷积和池化。 我们实验中使用的过渡层由一个批量归一化层和一个 1×1 卷积层和一个 2×2 平均池化层组成。
**增长率。**如果每个函数 H ℓ H_{\ell} Hℓ产生 k 个特征图,那么 ℓ t h \ell ^{th} ℓth 层有$ k_{0}+ k × (\ell − 1) $个输入特征图,其中 k0 是输入层中的通道数。 DenseNet 和现有网络架构之间的一个重要区别是 DenseNet 可以有非常窄的层,例如,k = 12。我们将超参数 k 称为网络的增长率。我们在第 4 节中表明,相对较小的增长率足以在我们测试的数据集上获得最先进的结果。对此的一种解释是,每一层都可以访问其块中的所有先前特征图,因此可以访问网络的“集体知识”。人们可以将特征图视为网络的全局状态。每层都将自己的 k 个特征图添加到这个状态。增长率调节每层对全局状态贡献多少新信息。全局状态一旦写入,就可以从网络内的任何地方访问,并且与传统网络架构不同,不需要在层与层之间复制它 。
Bottleneck layers。 虽然每一层只产生 k 个输出特征图,但它通常有更多的输入。 在 [37, 11] 中已经注意到,可以在每个 3×3 卷积之前引入 1×1 卷积作为Bottleneck layers,以减少输入特征图的数量,从而提高计算效率。 我们发现这种设计对 DenseNet 特别有效,我们将我们的网络称为具有这样一个瓶颈层的网络,即 H ℓ H_{\ell} Hℓ 的 BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3) 版本, 作为 DenseNet-B。 在我们的实验中,我们让每个 1×1 卷积产生 4k 个特征图。
压缩。 为了进一步提高模型的紧凑性,我们可以减少过渡层的特征图数量。 如果一个密集块包含 m 个特征图,我们让下面的过渡层生成 bθmc 输出特征图,其中 0 <θ ≤1 被称为压缩因子。 当 θ = 1 时,跨过渡层的特征图数量保持不变。 我们将 θ<1 的 DenseNet 称为 DenseNet-C,我们在实验中设置 θ = 0.5 θ = 0.5 θ=0.5。 当同时使用 θ < 1 的瓶颈层和过渡层时,我们将我们的模型称为 DenseNet-BC。
**实施细节。**在除 ImageNet 之外的所有数据集上,我们实验中使用的 DenseNet 具有三个密集块,每个块都有相同的层数。在进入第一个密集块之前,对输入图像执行具有 16 个(或 DenseNet-BC 增长率的两倍)输出通道的卷积。对于内核大小为 3×3 的卷积层,输入的每一侧都填充了一个像素以保持特征图大小固定。我们使用 1×1 卷积,然后是 2×2 平均池化作为两个连续密集块之间的过渡层。在最后一个密集块的末尾,执行全局平均池化,然后附加一个 softmax 分类器。三个密集块中的特征图大小分别为 32×32、16×16 和 8×8。我们使用配置 fL = 40 的基本 DenseNet 结构进行实验; k = 12g,fL = 100; k = 12g 和 fL = 100; k = 24g。对于 DenseNetBC,配置 fL = 100 的网络; k=12g,fL=250; k = 24g 且 fL = 190; k = 40g 被评估。
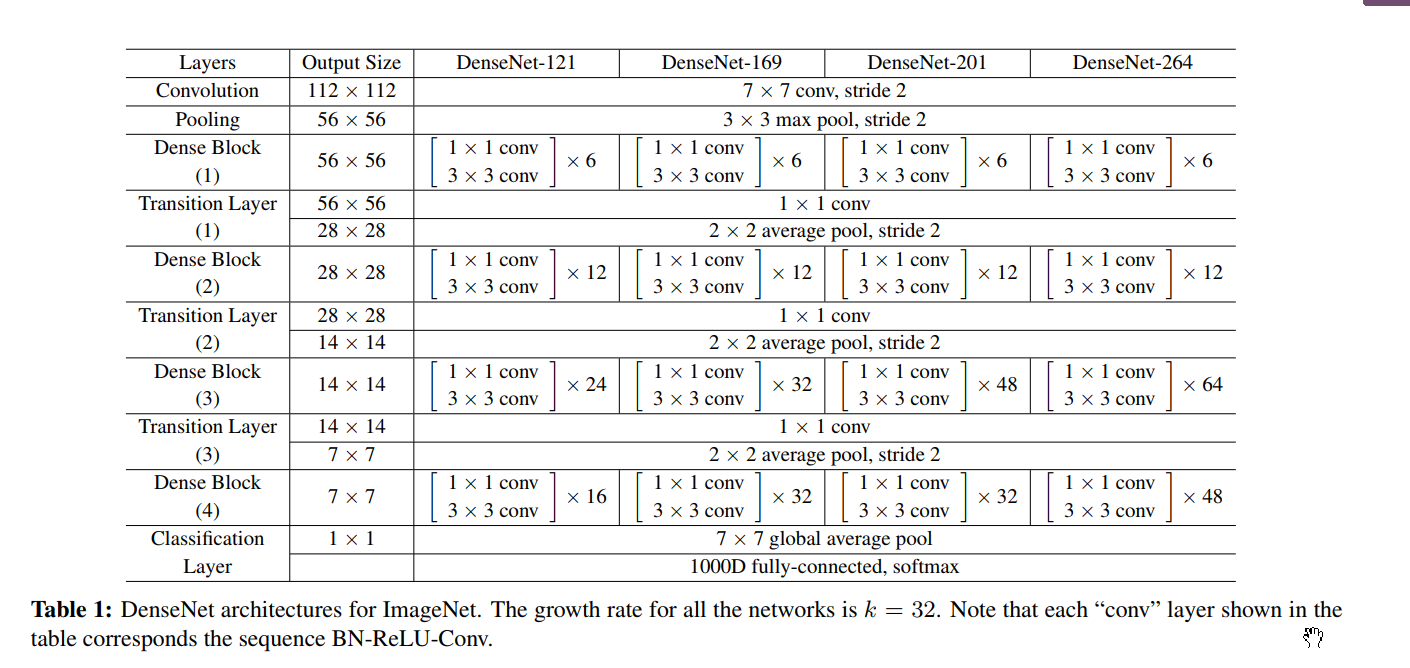
在我们对 ImageNet 的实验中,我们在 224×224 输入图像上使用具有 4 个密集块的 DenseNet-BC 结构。 初始卷积层包含 2k 个大小为 7×7、步幅为 2 的卷积; 所有其他层中的特征图数量也来自设置 k。 我们在 ImageNet 上使用的确切网络配置如表 1 所示。
===============================================================
我们凭经验证明了 DenseNet 在几个基准数据集上的有效性,并与最先进的架构进行了比较,特别是与 ResNet 及其变体。
CIFAR。 两个 CIFAR 数据集 [15] 由 32×32 像素的彩色自然图像组成。 CIFAR-10 (C10) 由来自 10 个类别的图像和来自 100 个类别的 CIFAR-100 (C100) 组成。 训练集和测试集分别包含 50,000 和 10,000 张图像,我们保留 5,000 张训练图像作为验证集。 我们采用广泛用于这两个数据集的标准数据增强方案(镜像/移位)[11、13、17、22、28、20、32、34]。 我们在数据集名称(例如,C10+)的末尾用“+”标记表示这个数据增强方案。 对于预处理,我们使用通道均值和标准差对数据进行归一化。 对于最终运行,我们使用所有 50,000 张训练图像并在训练结束时报告最终测试错误。
SVHN。 街景房屋号码 (SVHN) 数据集 [24] 包含 32×32 彩色数字图像。 训练集中有 73,257 张图像,测试集中有 26,032 张图像,还有 531,131 张用于额外训练的图像。 按照惯例 [7, 13, 20, 22, 30] 我们使用所有训练数据而不进行任何数据增强,并从训练集中分割出一个包含 6,000 张图像的验证集。 我们在训练期间选择验证错误最低的模型并报告测试错误。 我们遵循 [42] 并将像素值除以 255,使它们在 [0; 1] 范围
ImageNet。 ILSVRC 2012 分类数据集 [2] 包含 120 万张用于训练的图像和 50,000 张用于验证的图像,从 1 开始; 000班。 我们采用与 [8, 11, 12] 中相同的数据增强方案来训练图像,并在测试时应用大小为 224×224 的单次或 10 次裁剪。 遵循 [11, 12, 13],我们报告了验证集的分类错误。
所有网络都使用随机梯度下降 (SGD) 进行训练。 在 CIFAR 和 SVHN 上,我们分别使用批量大小 64 进行 300 和 40 轮训练。 初始学习率设置为 0.1,并在训练 epoch 总数的 50% 和 75% 处除以 10。 在 ImageNet 上,我们以 256 的批量大小训练模型 90 个时期。 学习率最初设置为 0.1,并在第 30 和 60 轮降低 10 倍。请注意,DenseNet 的幼稚实现可能包含内存效率低下的问题。 为了减少 GPU 上的内存消耗,请参阅我们关于 DenseNets [26] 的内存高效实现的技术报告。
遵循 [8],我们使用 1 0 − 4 10^{−4} 10−4 的权重衰减和 0.9 的 Nesterov 动量 [35] 没有阻尼。 我们采用[10]引入的权重初始化。 对于没有数据增强的三个数据集,即 C10、C100 和 SVHN,我们在每个卷积层(第一个除外)之后添加一个 dropout 层 [33],并将 dropout 率设置为 0.2。 对于每个任务和模型设置,测试错误仅评估一次。
我们训练具有不同深度 L 和增长率 k 的 DenseNets。 CIFAR 和 SVHN 的主要结果如表 2 所示。为了突出总体趋势,我们将所有优于现有最先进技术的结果用黑体标出,将总体最佳结果标为蓝色。
**准确性。**可能最明显的趋势可能来自表 2 的底行,这表明 L = 190 和 k = 40 的 DenseNet-BC 在所有 CIFAR 数据集上始终优于现有的最新技术。在 C10+ 上的错误率为 3.46%,在 C10+ 上为 17.18% C100+ 显着低于宽 ResNet 架构 [42] 实现的错误率。我们在 C10 和 C100(没有数据增强)上的最佳结果更加令人鼓舞:两者都比使用 drop-path 正则化的 FractalNet 低近 30% [17]。在 SVHN 上,使用 dropout,L = 100 和 k = 24 的 DenseNet 也 超过了目前由宽 ResNet 取得的最佳结果。然而,与较短的对应物相比,250 层 DenseNet-BC 并没有进一步提高性能。这可能是因为 SVHN 是一项相对容易的任务,极深的模型可能会过度拟合训练集。
**容量。**如果没有压缩或瓶颈层,DenseNets 会随着 L 和 k 的增加而表现得更好。我们将这主要归因于模型容量的相应增长。 C10+ 和 C100+ 列最好地证明了这一点。在 C10+ 上,随着参数数量从 1.0M、超过 7.0M 增加到 27.2M,误差从 5.24% 下降到 4.10%,最终下降到 3.74%。在 C100+ 上,我们观察到类似的趋势。这表明 DenseNets 可以利用更大更深模型的增强表示能力。它还表明它们没有过拟合或残差网络的优化困难 [11]。
**参数效率。**表 2 中的结果表明 DenseNets 比替代架构(特别是 ResNets)更有效地利用参数。在过渡层具有瓶颈结构和降维的 DenseNetBC 参数效率特别高。例如,我们的 250 层模型只有 1530 万个参数,但它始终优于其他模型,例如 FractalNet 和 Wide ResNets 等参数超过 30M 的模型。我们还强调,L = 100 和 k = 12 的 DenseNet-BC 实现了与使用 90 % 更少的参数。图 4(右图)显示了这两个网络在 C10+ 上的训练损失和测试误差。 1001 层深度 ResNet 收敛到较低的训练损失值,但具有类似的测试错误。我们将在下面更详细地分析这种影响。
**过拟合。**更有效地使用参数的一个积极副作用是 DenseNets 不太容易过度拟合。我们观察到,在没有数据增强的数据集上,DenseNet 架构相对于先前工作的改进特别明显。在 C10 上,改进表示错误相对减少了 29%,从 7.33% 减少到 5.19%。在 C100 上,减少约 30%,从 28.20% 到 19.64%。在我们的实验中,我们观察到在单个设置中潜在的过度拟合:在 C10 上,通过将 k =12 增加到 k =24 产生的参数增长 4 倍导致误差从 5.77% 适度增加到 5.83%。 DenseNet-BC 瓶颈和压缩层似乎是应对这一趋势的有效方法。
我们在 ImageNet 分类任务上评估具有不同深度和增长率的 DenseNet-BC,并将其与最先进的 ResNet 架构进行比较。为了确保两种架构之间的公平比较,我们通过 [8]1 采用公开可用的 ResNet Torch 实现来消除所有其他因素,例如数据预处理和优化设置的差异。我们简单地将 ResNet 模型替换为 DenseNetBC 网络,并保持所有实验设置与用于 ResNet 的设置完全相同。
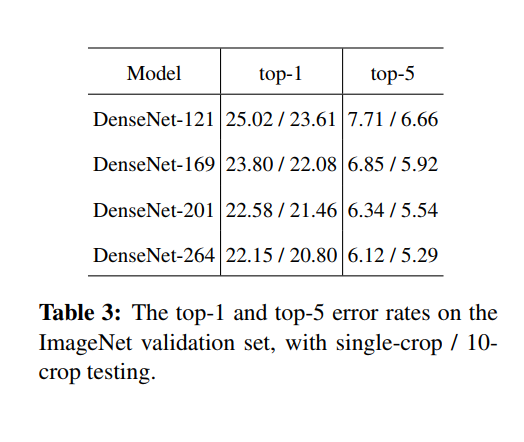
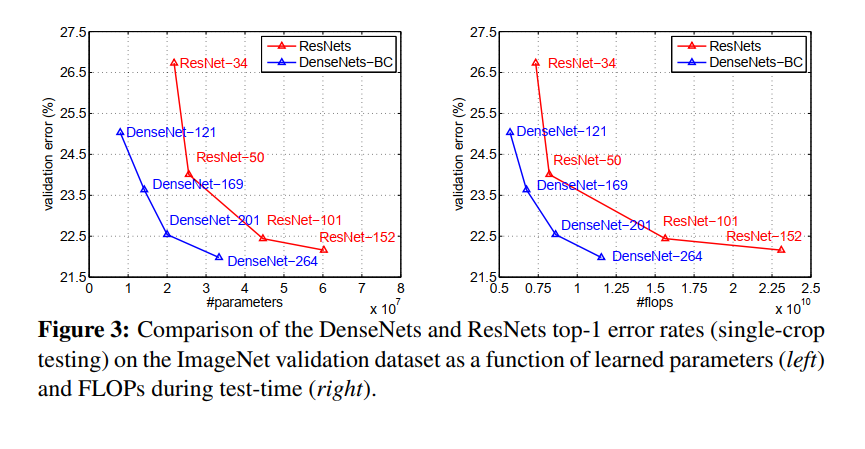
我们在表 3 中报告了 ImageNet 上 DenseNets 的单次和 10 次验证错误。图 3 显示了 DenseNets 和 ResNets 的单次裁剪 top-1 验证错误作为参数数量(左)和 FLOP(对)。图中显示的结果表明,DenseNets 的性能与最先进的 ResNets 相当,同时需要更少的参数和计算来实现可比的性能。例如,具有 20M 参数的 DenseNet-201 模型产生与具有超过 40M 参数的 101 层 ResNet 类似的验证错误。从右侧面板可以观察到类似的趋势,该面板将验证误差绘制为 FLOP 数量的函数:需要与 ResNet-50 一样多的计算的 DenseNet 与需要两倍的 ResNet-101 执行相同计算。
值得注意的是,我们的实验设置意味着我们使用针对 ResNet 而非 DenseNet 优化的超参数设置。可以想象,更广泛的超参数搜索可能会进一步提高 DenseNet 在 ImageNet 上的性能。
5 讨论
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-sVCufVwX-1713437333143)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









