






摘要
本研究利用目标说话人的空间位置、语音特征和嘴唇运动等所有可用信息,提出了一种通用的多模态目标语分离框架。
提出了一种基于注意因子的多模态高级语义信息融合方法.首先将混合音频分解为一组声学子空间,然后利用来自其他模态的目标信息,利用可学习的注意力方案增强这些子空间声学嵌入。
1 介绍
现状:纯语音分离 大多数监督方法基于频谱图掩蔽,估计目标说话人在混合频谱图的每个时频(T-F) bin处的权重(掩码)。混合频谱图与预测掩模之间的乘积作为目标语音频谱图。
加入视觉的多模态语音分离,视觉信息能够提供额外的言语和说话人相关线索。提高了实验效果,原因在于:
1)视觉信息(如嘴唇运动、面部嵌入)通常不受声环境的影响;
2)实验证明,视觉信息能够提供额外的言语和说话人相关线索。
本文:
1)我们引入了一个多模态目标语分离框架,充分利用了目标语信息,包括方向信息、嘴唇运动和语音特征。
2)在此框架下,研究并提出了几种目标语音分离任务的多模态融合方法;
3)实验证明了该框架对模态缺失或噪声干扰的鲁棒性
2 相关工作
纯音频语音分离:大多数基于频谱图掩蔽,可以与定向特征、对应的方向特征、说话人的先验知识(说话人嵌入)、干扰说话人的说话人嵌入关联。
视听目标语分离:Gabbay等人探讨了说话人的嘴唇运动与语音谱图之间的关系,并提出了一种视频转声音的方法。纯视觉驱动
设计了一个视听框架,其中嘴唇运动作为视觉信息。这两种方法在具有一致视频和音频输入的现实世界样本和未见过的语言中泛化得很好。
3 方法
3.1总览
在这项工作中,我们通过利用目标说话人的方向、嘴唇运动和说话人嵌入的目标信息,解决了从多通道语音混合中分离目标说话人的任务。
虽然视觉信息不受复杂声环境的影响,但缺乏对说话人面部的视觉访问(例如,转弯和障碍物)可能会导致潜在目标缺失。
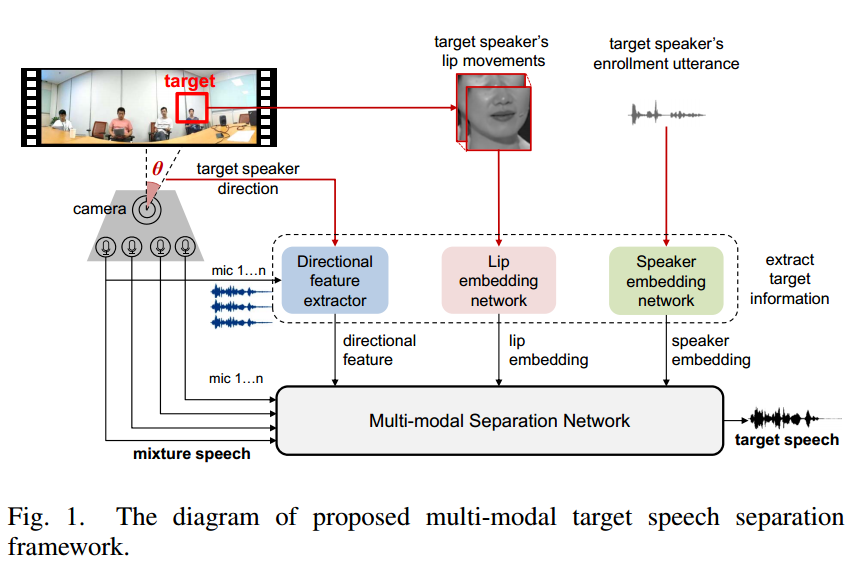
输入:
(i)有噪声的多通道混合波形,
(ii)通过人脸检测计算的目标说话人的方向,
(iii)唇区裁剪的视频帧,
(iv)目标说话人的注册音频。系统直接输出估计的单音目标语音,同时抑制所有其他干扰信号
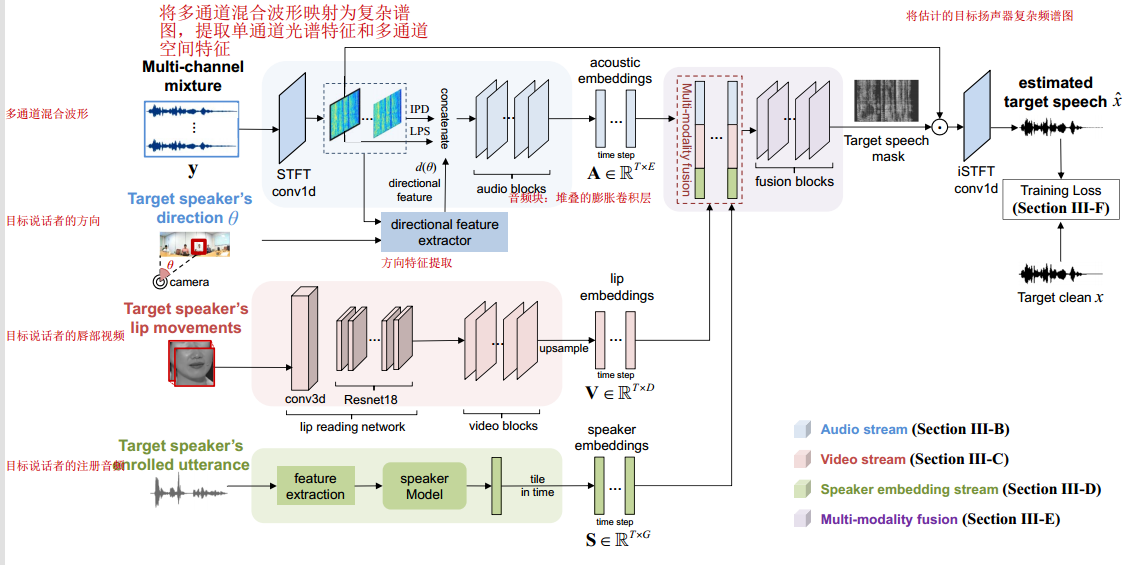
3.2音频流
将将多通道混合波形映射为复杂谱图,提取单通道频谱特征和多通道空间特征和提取的目标说话者的空间特征连接,放进一个由堆叠的膨胀卷积层组成的音频块,再通过iSTFT将估计的目标扬声器复杂频谱图转换为波形
1)频谱特征
使用标准STFT模块进行频谱分析,STFT将信号转换为复域,该复域可以分解为幅度分量和相位分量。多通道复谱图Y为:
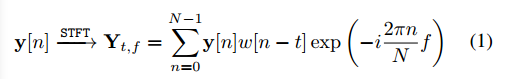
2)空间特征
标准IPD由复谱图通道间相位差计算为:
![]() IPD提取混合物中所有说话人的空间信息,我们称之为与说话人无关的空间特征。
IPD提取混合物中所有说话人的空间信息,我们称之为与说话人无关的空间特征。
3)方向特征
给定目标说话人的方向,提取目标相关的方向特征,提供明确的目标信息。我们使用人脸检测方法来识别和跟踪视频中的目标说话人,并根据摄像机位置估计其方向。
3.3视频流
唇读网络的输入既可以是唇区裁剪后的图像序列[10],也可以是目标说话人的面部嵌入[9]。该网络由一个时空卷积层和一个18层的ResNet[39]组成,以捕捉唇运动的时空动态。以捕捉唇运动的时空动态。
3.4说话人嵌入
说话人嵌入是一种将目标信息告知分离网络并实现目标说话人分离的偏置信号。4个卷积层,然后是一个全连接层。
3.5多模态融合
从一组媒体源中获得三种目标信息,包括来自多通道语音的声学嵌入、来自视频的唇形嵌入和来自目标说话人注册话语的说话人嵌入。
已有的融合方法:
1)串联:集成多模态嵌入的最常见方法是简单地沿着特征轴将它们串联起来。
2)因子注意:在最近的语音识别工作中,为了快速适应声学环境,提出了一个因子层。
我们建议将声学嵌入分解为一组声学子空间(例如,电话,子空间,说话人子空间),并利用来自其他模态的信息选择性地对它们进行聚合。
3)基于规则的注意:将多模式与注意融合的动机在于有效性和有效性,当说话人之间的角度差较小时,应用于空间和方向特征的权重分数相对较低,计算公式为:
![]()
4)为降低学习难度,三模式融合采用分层融合策略。
在每个阶段可以采用不同的融合方法。
例如,首先使用分解注意方法将声学和扬声器嵌入融合在一起。然后,将融合的ASE连接到唇形嵌入中,并组合成三模态嵌入















 2083
2083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









