






1.数据分区算法
分布式数据库系统会根据不同的数据分区算法,将数据分散存储到不同的数据库服务器 节点上,每个节点管理着整个数据集合中的一个子集。常见数据分区规则有:顺序分区与哈希分区
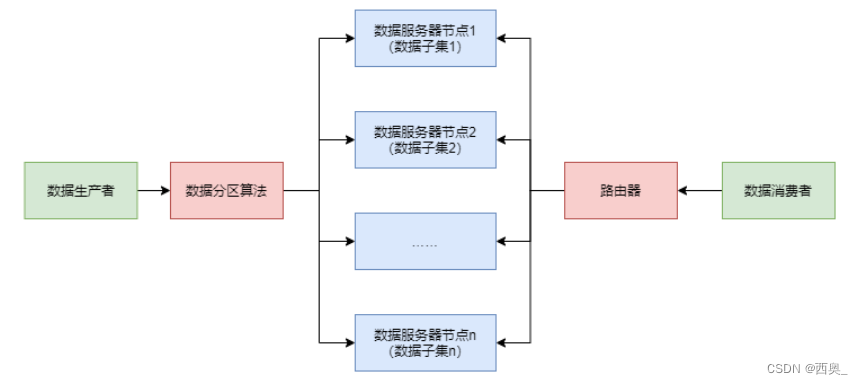
1.1.顺序分区
将数据按照某种顺序平均分配到不同的节点。不同的顺序方式,产生 了不同的分区算法。
1)轮询分区算法:每产生一个数据,就依次分配到不同的节点。该算法适合于数据问题不确定的场景。其 分配的结果是,在数据总量非常庞大的情况下,每个节点中数据是很平均的。但生产者与数 据节点间的连接要长时间保持
2)时间片轮转分区算法:在某人固定长度的时间片内的数据都会分配到一个节点。时间片结束,再产生的数据就 会被分配到下一个节点。这些节点会被依次轮转分配数据。该算法可能会出现节点数据不平 均的情况(因为每个时间片内产生的数据量可能是不同的)。但生产者与节点间的连接只需 占用当前正在使用的这个就可以,其它连接使用完毕后就立即释放
3)数据块分区算法:在整体数据总量确定的情况下,根据各个节点的存储能力,可以将连接的某一整块数据 分配到某一节点
4)业务主题分区算法:业务主题分区算法
1.2.哈希分区
利用数据的哈希值来完成分配,对数据哈希值的不同使用方式产生 了不同的哈希分区算法。哈希分区算法相对较复杂,这里详细介绍几种常见的哈希分区算法
1)节点取模分区算法:前提是每个节点都已分配好了一个唯一序号,对于 N 个节点的分布式系统, 其序号范围为[0, N-1]。然后选取数据本身或可以代表数据特征的数据的一部分作为 key,计 算 hash(key)与节点数量 N 的模,该计算结果即为该数据的存储节点的序号。算法简单,但如果分布式系统扩容或缩容,已 经存储过的数据需要根据新的节点数量 N 进行数据迁移,否则用户根据 key 是无法再找到原 来的数据的。生产中扩容一般采用翻倍扩容方式,以减少扩容时数据迁移的比例
2)一致性哈希分区算法:一致性 hash 算法通过一个叫作一致性 hash 环的数据结构实现。这个环的起点是 0,终 点是 2 32 - 1,并且起点与终点重合。环中间的整数按逆/顺时针分布,故这个环的整数分布 范围是[0, 232 -1]。优点是,节点的扩容与缩容,仅对按照逆/顺时针方向距离该节点最近的 节点有影响,对其它节点无影响。但当节点数量较少时,非常容易形成数据倾斜问题,且节点变化影响的节点数量占比较大, 即影响的数据量较大。所以,该方式不适合数据节点较少的场景
3)虚拟槽分区算法:该算法首先虚拟出一个固定数量的整数集合,该集合中的每个整数称为一个 slot 槽。这 个槽的数量一般是远远大于节点数量的。然后再将所有 slot 槽平均映射到各个节点之上。例 如,Redis 分布式系统中共虚拟了 16384 个 slot 槽,其范围为[0, 16383]。

数据只与 slot 槽有关系,与节点没有直接关系。数据只通过其 key 的 hash(key)映射到 slot 槽:slot = hash(key) % slotNums。其优点解耦了数据与节点,客户端 无需维护节点,只需维护与 slot 槽的关系即可。Redis 数据分区采用的就是该算法。其计算槽点的公式为:slot = CRC16(key) % 16384。 CRC16()是一种带有校验功能的、具有良好分散功能的、特殊的 hash 算法函数。其实 Redis 中计算槽点的公式不是上面的那个,而是:slot = CRC16(key) &16383
2.集群操作
2.1.连接集群
redis -cli -c -p 6380
2.2.写入数据
1)key 单个写入:无论 value 类型为 String 还是 List、Set 等集合类型,只要写入时操作的是一个 key,那 么在分布式系统中就没有问题
2)key 批量操作:系统提供了一种对批量 key 的操作方案,为这些 key 指定一个统一的 group, 让这个 group 作为计算 slot 的唯一值
![]()
2.3.集群查询
1)查询 key 的 slot:通过 cluster keyslot 可以查询指定 key 的 slot
![]()
2)查询 slot 中 key 的数量:通过 cluster countkeysinslot 命令可以查看到指定 slot 所包含的 key 的个数
![]()
3)查询 slot 中的 key:通过 cluster getkeysinslot 命令可以查看到指定 slot 所包含的 key
![]()
2.4.故障转移
分布式系统中的某个 master 如果出现宕机,那么其相应的 slave 就会自动晋升为 master。 如果原 master 又重新启动了,那么原 master 会自动变为新 master 的 slave
3.分布式系统的限制
仅支持 0 号数据库;批量 key 操作支持有限;分区仅限于 key;事务支持有限;不支持分级管理















 3407
3407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









