






Redis 中 Set 类型的底层采用了 hashTable, Hash、ZSet、List 集合的底层实现进行了特殊的设计,使其保证了 Redis 的高性能
1.两种实现方式
Hash与ZSet集合底层的实现有两种:压缩列表zipList,与跳跃列表skipList。这两种实现对于用户来说是透明的,但用户写入不同的数据,系统会自动使用不同的实现。只有同时满足配置文件 redis.conf 中相关集合元素数量阈值与元素大小阈值两个条件,使用的就是压缩列表 zipList,只要有一个条件不满足使用的就是跳跃列表 skipList。如:
1)集合元素个数小于 redis.conf 中 zset-max-ziplist-entries 属性的值,其默认值为 128
2)每个集合元素大小都小于 redis.conf 中 zset-max-ziplist-value 属性的值,其默认值为 64 字节
2.zipList
2.1.zipList简介
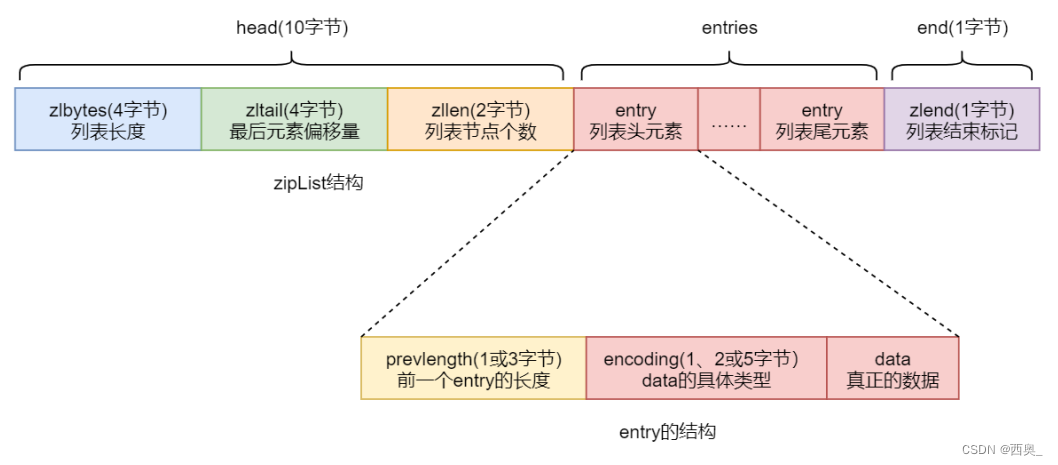
zipList称为压缩列表,是一个经过特殊编码的用于存储字符串或整数的双向链表。 其底层数据结构由 head、entries 与 end 三部分构成。这三部分在内存上是连续存放的
2.2.head
1)zlbytes:占 4 个字节,用于存放 zipList 列表整体数据结构所占的字节数,包括 zlbytes 本身的长度
2)zltail:占 4 个字节,用于存放 zipList 中最后一个 entry 在整个数据结构中的偏移量(字 节)。该数据的存在可以快速定位列表的尾 entry 位置,以方便操作
3)zllen:占 2 字节,用于存放列表包含的 entry 个数。由于其只有 16 位,所以 zipList 最多 可以含有的 entry 个数为 2 16 -1 = 65535 个
2.3.entries
entries 是真正的列表,由很多的列表元素 entry 构成。由于不同的元素类型、数值的不同,从而导致每个 entry 的长度不同
1)prevlength:用于记录上一个 entry 的长度,以实现逆序遍历。默认长度为 1 字节, 只要上一个 entry 的长度<254 字节,prevlength 就占 1 字节,否则其会自动扩展为 3 字节长度
2)encoding:该部分用于标志后面的 data 的具体类型。如果 data 为整数类型,encoding固定长度为 1 字节。如果 data 为字符串类型,则 encoding 长度可能会是 1 字节、2 字 节或 5 字节。data 字符串不同的长度,对应着不同的 encoding 长度
3)data:真正存储的数据。数据类型只能是整数类型或字符串类型。不同的数据占用的字 节长度不同
2.4.end
zlend:占 1 个字节,值固定为 255,即二进制位为全 1,表示 一个 zipList 列表的结束
3.listPack
ziplist,实现复杂,为了逆序遍历,每个 entry 中包含前一个 entry 的长度,这样会导致在 ziplist 中间修改或者插入 entry 时需要进行级联更新。在高并发的写操作场景下会极度降低 Redis 的性能。为了实现更紧凑、更快的解析,更简单的实现,重写 ziplist, 命名为 listPack。在 Redis 7.0 中,已经将 zipList 全部替换为了 listPack,但为了兼容性,在配置中也保留 了 zipList 的相关属性
3.1.listPack简介
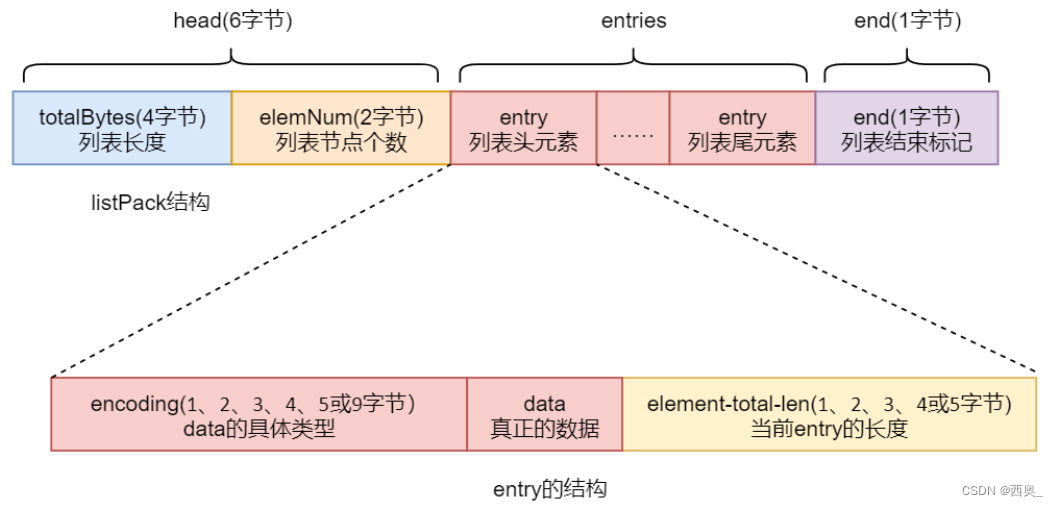
listPack 也是一个经过特殊编码的用于存储字符串或整数的双向链表。其底层数据结构也由head、entries 与 end 三部分构成,且这三部分在内存上也是连续存放的
3.2.head
1)totalBytes:占 4 个字节,用于存放 listPack 列表整体数据结构所占的字节数,包括 totalBytes 本身的长度
2)elemNum:占 2 字节,用于存放列表包含的 entry 个数。其意义与 zipList 中 zllen 的相同
3.3.entries
没有了记录前一个 entry 长度的 prevlength,而增加了记录当前 entry 长度的 element-total-len。仍然可以实现逆序遍历,但却避免了由于在列表中间修改或插入 entry 时引发的级联更新
1)encoding:该部分用于标志后面的 data 的具体类型。如果 data 为整数类型,encoding 长度可能会是 1、2、3、4、5 或 9 字节。不同的字节长度,其标识位不同。如果 data 为字符串类型,则 encoding 长度可能会是 1、2 或 5 字节。data 字符串不同的长度,对应着不同的 encoding 长度
2)data:真正存储的数据。数据类型只能是整数类型或字符串类型。不同的数据占用的字 节长度不同
3)element-total-len:该部分用于记录当前 entry 的长度,用于实现逆序遍历。由于其特殊 的记录方式,使其本身占有的字节数据可能会是 1、2、3、4 或 5 字节
4.skipList
4.1.skipList简介
跳跃列表是一种随机化的数据结构,基于并联的链表,实现简单, 查找效率较高。在链表的基础上增加了跳跃功能,使得在查找元素时,能够提供较高的效率
4.2.skipList 原理

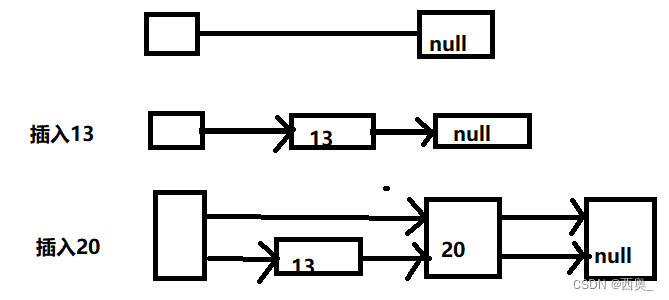
对链表的增删改查需要从头开始遍历操作,因此为了提升查找效率,在偶数结点上增加一个指针,让其指向下一个偶数结点

这样所有偶数结点就连成了一个新的链表(简称高层链表),高层链表包含的节点个数只是原来链表的一半。想查找某个数据时,先沿着高层链表进行查找。当遇到第一个比待查数据大的节点时,立即从该大节点的前一个节点回到原链表中进行查找。若想插入20,则先从(8,19,31,42)开始遍历,遍历到31时,从19开始顺着低链表遍历,找到比20大的23,然后再19和23间插入。若链表元素较多,为了进一步提升查找效率,可以将原链表构建为三层链表,或再高层级链表
4.3.存在问题
对链表分层级的方式从原理上确实提升了查找效率,但由于固定序号的元素拥有固定层级,所以列表元素出现增加或删除的情况下,会导致列表整体元素层级大调整,大大降低系统性能
4.4.算法优化
采用随机分配层级方式。在确定了总层级后,每添加一个新的元素时会自动为其随机分配一个层级。这种随机性就解决了节点序号与层级间的固定关系问题
每一个节点的层级数都是随机分配的,而且新插入一个节点不会影响 到其它节点的层级数。只需要修改插入节点前后的指针,而不需对很多节点都进行调整。这 就降低了插入操作的复杂度。在查找数据的时先在高 层级链表中进行查找,然后逐层降低
5.quickList

5.1.quickList简介
快速列表,quickList 本身是一个双向无循环链表,它的每一个节点都是一个 zipList。从Redis3.2版本开始,对于List的底层实现,使用quickList替代了zipList 和 linkedList
quickList 本质上是 zipList 和 linkedList 的混合体。其将 linkedList 按段切分,每一段使用 zipList 来紧凑存储若干真正的数据元素,多个 zipList 之间使用双向指针串接起来。对于每个 zipList 中最多可存放多大容量的数据元素,在配置文件中通过 list-max-ziplist-size 属性可以指定
5.2.检索操作
对于 List 元素的检索,都是以其索引 index 为依据的。quickList 由一个个的 zipList 构成, 每个 zipList 的 zllen 中记录的就是当前 zipList 中包含的 entry 的个数,即包含的真正数据元素的个数。根据要检索元素的 index,从 quickList 的头节点开始,逐个对 zipList 的 zllen 做 sum 求和,直到找到第一个求和后 sum 大于 index 的 zipList,那么要检索的这个元素就在这个 zipList 中
5.3.插入操作
假设要插入的元素的大小为 insert,而查找到的插入位置所在的 zipList 当前的大小为 Bytes
1)当 insert+ Bytes<= list-max-ziplist-size 时,直接插入到 zipList 中相应位置 即可
2)当 insert+ Bytes> list-max-ziplist-size,且插入的位置位于该 zipList 的首部位置,此时需要查看该 zipList 的前一个 zipList 的大小 prev_Bytes:
若 insert+ prev_Bytes<= list-max-ziplist-size 时,直接将元素插入到前一个 zipList 的尾部位置即可
若 insert + prev_Bytes> list-max-ziplist-size 时,直接将元素自己构建为一个新 的 zipList,并连入 quickList 中
3)当 insert + Bytes > list-max-ziplist-size,且插入的位置位于该 zipList 的尾 部位置,此时需要查看该 zipList 的后一个 zipList 的大小 next_Bytes:
若 insert + next_Bytes<= list-max-ziplist-size 时,直接将元素插入到后一个 zipList 的头部位置即可
若 insert + next_Bytes> list-max-ziplist-size 时,直接将元素构建一个新的 zipList,并连入 quickList 中
4)当 insert + Bytes > list-max-ziplist-size,且插入的位置位于该 zipList 的中间位置,则将当前 zipList 分割为两个 zipList 连接入 quickList 中,然后将元素插入到分割后的前面 zipList 的尾部位置
5.4.删除操作
在相应的 zipList 中删除元素后,考虑该 zipList 中是否还有元素。如果没有其它元素了,则将该 zipList 删除,将其前后两个 zipList 相连接。















 973
973











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









