







1. 前言
本文尝试从硬件认识开始介绍Android的显示系统是如何更新画面的,希望能就android系统是如何更新画面的问题,给读者带来一个感性认知。文中将尝试解释从App画出一帧画面到这帧画面是如何到达屏幕并最终被人眼看到的整个过程,这其中会涉及硬件的一些基础知识以及Android系统下一些重要的软件基础组件。本文将先分别介绍画面显示过程中所涉及到的重要组件及其工作原理,然后从Android app渲染第一帧画面开始逐步串联起各个组件,期望最终对于Android系统下画面是如何显示出来的给读者一个宏观的认识。本文适合对Android显示系统有过一定了解的同学阅读。由于文章较长,这里会分成9个章节。
2. 显示硬件基础
无论软件的架构设计多么高端大气上档次,最终都离不开硬件的支持,软件的架构是建构在硬件的运行原理之上的,所以在讨论软件的各个设计之前我们有必要对显示硬件的原理做一个初步的了解。
2.1. 常见显示设备
LCD(Liquid Crystal Display)俗称液晶。
液晶是一种材料,液晶这种材料具有一种特点:可以在电信号的驱动下液晶分子进行旋转,旋转时会影响透光性,
因此我们可以在整个液晶面板后面用白光照(称为背光),可以通过不同电信号让液晶分子进行选择性的透光,此时在液晶面板前面看到的就是各种各样不同的颜色,这就是LCD显示画面的原理。
有些显示器(譬如LED显示器、CRT显示器)自己本身会发光称为主动发光,有些(LCD)本身不会发光只会透光,需要背光的协助才能看起来是发光的,称为被动发光。
其他一些主流的显示设备:
CRT:阴极摄像管显示器。 以前的那种大屁股电视机就是CRT显示,它曾是应用最广泛的显示器之一,不过现在基本没有在使用这种技术了。
OLED:有机发光二极管又称为有机电激光显示(Organic Light-Emitting Diode,OLED),OLED显示技术具有自发光的特性,采用非常薄的有机材料涂层
和玻璃基板,可以做得更轻更薄,可视角度更大,并且能够显著节省电能。目前未成为主流,但是很有市场潜力,将来很可能取代LCD。
LED:主要用在户外大屏幕
2.2. LCD的接口技术
VGA(Video Graphics Array)即视频图形阵列,具有分辨率高、显示速率快、颜色丰富等优点。VGA接口不但是CRT显示设备的标准接口,同样也是LcD液晶显示设备的标准接口,具有广泛的应用范围。相信很多朋友都不会陌生,因为这种接口是电脑显示器上最主要的接口,从块头巨大的CRT显示器时代开始,VGA接口就被使用,并且一直沿用至今。
HDMI(High Definition Multimedia Interface) 高清多媒体接口,是一种全数字化视频和声音发送接口,可以发送未压缩的音频及视频信号。HDMI可用于机顶盒,DVD播放机、个人计算机、电视、游戏主机、综合扩大机、数字音响与电视机等设备。HDMI可以同时发送音频和视频信号,由于音频和视频信号采用同一条线材,大大简化系统线路的安装难度。
DVI(Digital Visual Interface),即数字视频接口。它是1998年9月,在Intel开发者论坛上成立的,由Silicon Image、Intel(英特尔)、Compaq(康柏)、IBM(国际商业机器公司)、HP(惠普)、NEC(日本电气股份有限公司)、Fujitsu(富士通)等公司共同组成的DDWG(Digital Display Working Group,数字显示工作组)推出的接口标准
LVDS(Low Voltage Differential Signaling,即低电压差分信号)接口又称RS-644总线接口,是20世纪90年代才提出的一种数据传输和接口技术。LVDS接口是美国NS美国国家半导体公司为克服以TTL电平方式传输宽带高码率数据时功耗大,电磁干扰大等缺点而研制的一种数字视频信号传输方式。由于其采用低压和低电流驱动方式,因此,实现了低噪声和低功耗。LVDS技术具有低功耗、低误码率、低串扰和低辐射等特点,其传输介质可以是铜质的PCB连线,也可以是平衡电缆。LVDS在对信号完整性、低抖动及共模特性要求较高的系统中得到了越来越广泛的应用,常见于液晶电视中。
MIPI(Mobile Industry Processor Interface)是2003年由ARM, Nokia, ST ,TI等公司成立的一个联盟,目的是把手机内部的接口如摄像头、显示屏接口、射频/基带接口等标准化,从而减少手机设计的复杂程度和增加设计灵活性。MIPI联盟下面有不同的WorkGroup,分别定义了一系列的手机内部接口标准,比如摄像头接口CSI、显示接口DSI、射频接口DigRF、麦克风/喇叭接口SLIMbus等。统一接口标准的好处是手机厂商根据需要可以从市面上灵活选择不同的芯片和模组,更改设计和功能时更加快捷方便。

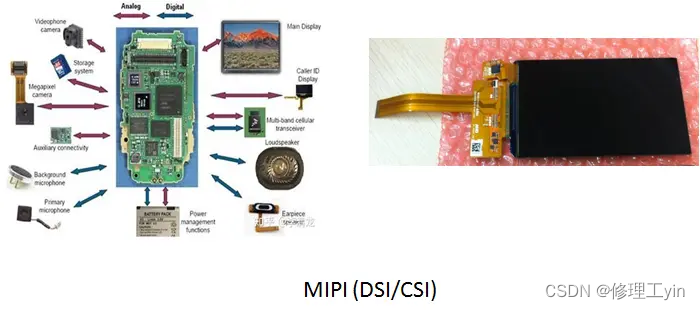
目前手机屏幕和SOC间多使用MIPI接口来传输屏幕数据,其实物如下图所示,图中的条状芯片就是负责更新显示屏的显示内容的芯片DDIC, 它一边通过mipi协议和SOC通信,一边把获取到的显示数据写入到显示存储器GRAM内, 屏幕(Panel)通过不停扫描GRAM来不停更新液晶显示点的颜色,实现画面的更新。

屏幕坐标系
显示屏幕采用如下图所示的二维坐标系,以屏幕左上角为原点,X方向向右,Y轴方向向下,屏幕上的显示单元(像素)以行列式整齐排列,如下图所示,如下图示中以六边形块来代表一个像素点,如无例外说明,本文中所有图示都将以该六边形块来代表屏幕上的一个像素点。

在一个典型的Android显示系统中,一般包括SOC、DDIC、Panel三个部分, SOC负责绘画与多图层的合成,把合成好的数据通过硬件接口按某种协议传输给DDIC,然后DDIC负责把buffer里的数据呈现到Panel上。如下图所示为高通平台上的画面更新简单示意图,首先CPU或GPU负责绘画,画出的多个layer交由MDP进行合成,合成的数据通过mipi协议和DSI总线传输给DDIC, DDIC将数据存到GRAM内(非video屏), Panel不断scanGRAM来显示内容。
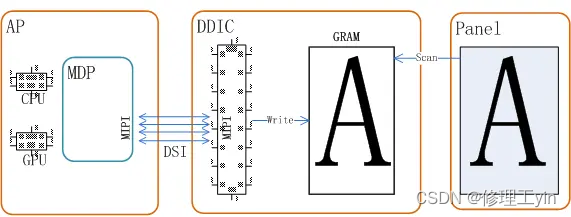
那么对于DDIC来讲它的职责就是按mipi协议和SOC交互,获取到从SOC合成好的一帧画面的数据,然后将数据写入GRAM,对GRAM的写入要符合一定的时序。
2.3. LCD时序
这个写入时序要首先从过去的 CRT 显示器原理说起。CRT 的电子枪按照从上到下一行行扫描,扫描完成后显示器就呈现一帧画面,随后电子枪回到初始位置继续下一次扫描。为了把显示器的显示过程和系统的视频控制器进行同步,显示器(或者其他硬件)会用硬件时钟产生一系列的定时信号。当电子枪换到新的一行,准备进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync;而当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(vertical synchronization),简称 VSync。显示器通常以固定频率进行刷新,这个刷新率就是 VSync 信号产生的频率。尽管现在的设备大都是液晶显示屏了,但原理仍然没有变。
CLK:像素时钟,像素数据只有在时钟上升或下降沿时才有效
ENB:是数据使能信号,当它为高时,CLK信号到达时输出有效数据。
HBP:行同步信号的前肩,水平同步信号的上升沿到ENABLE的上升沿的间隔。
HSW:水平同步信号的低电平(非有效电平)持续时间
HFP:行同步信号的后肩,ENABLE的下降沿到水平同步信号的下升沿的间隔 如下图所示
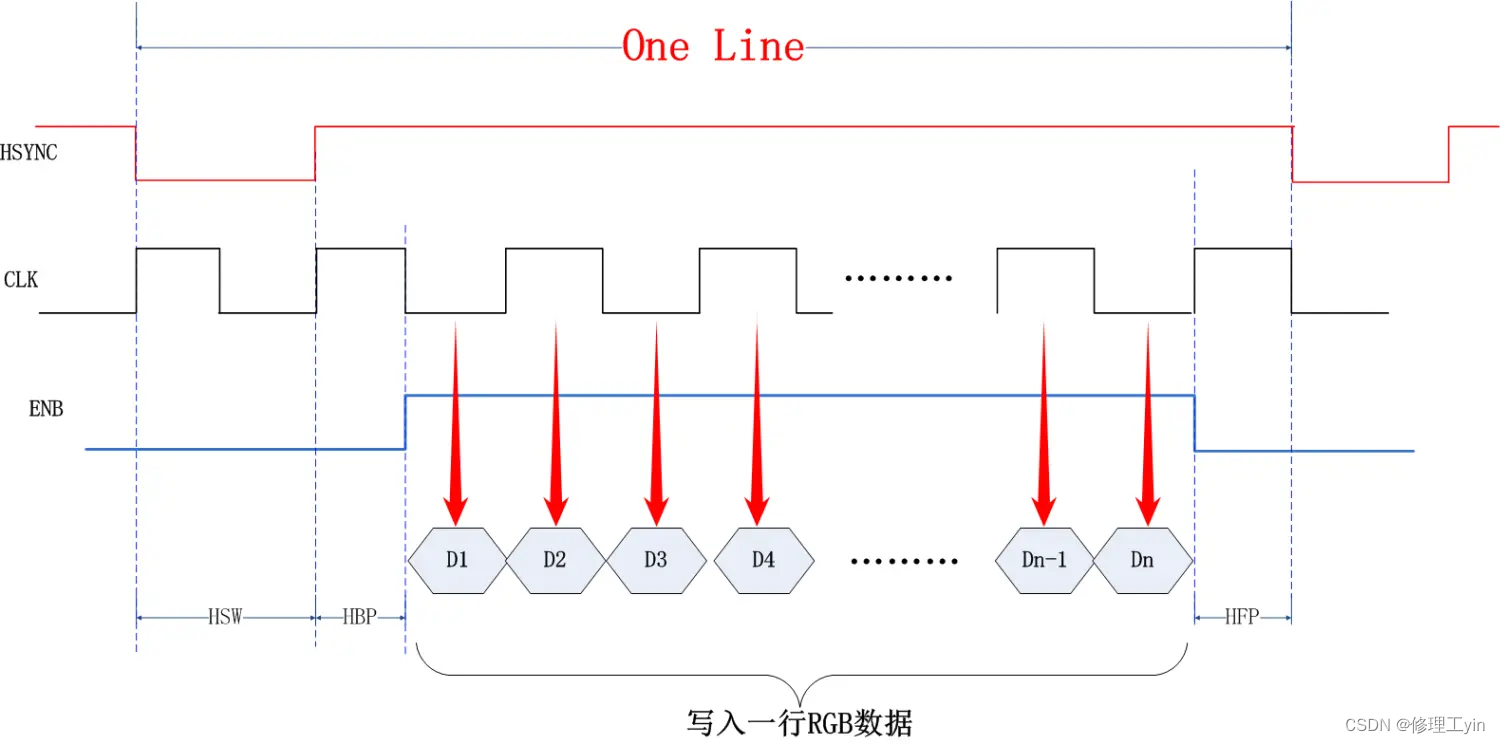
图中从HSYNC的下降沿开始,等待两个CLK产生一个上升沿,在等待一个HBP时间后开始传输一行的像素数据,像素数据只有在像素时钟和上升沿或下降沿时才会写入(这里我们只讨论原理,并不是某个特定平台的具体实现,所以HSW所对应的时钟数字并不是以图中所示为准,具体产品中都会有调整和变化),经过N个像素时钟后成功将一行像素数据写入D1-Dn
类似地,在两帧画面之间也存在一些间隔:
VSW: VSYNC信号下降沿到上升沿间的时间
VBP: 帧同步信号的前肩
VFP:帧同步信号的后肩
VPROCH: 被称为消隐区,它是指 VSW+VBP+VFP , 这个时间段内Panel不更新像素点的颜色
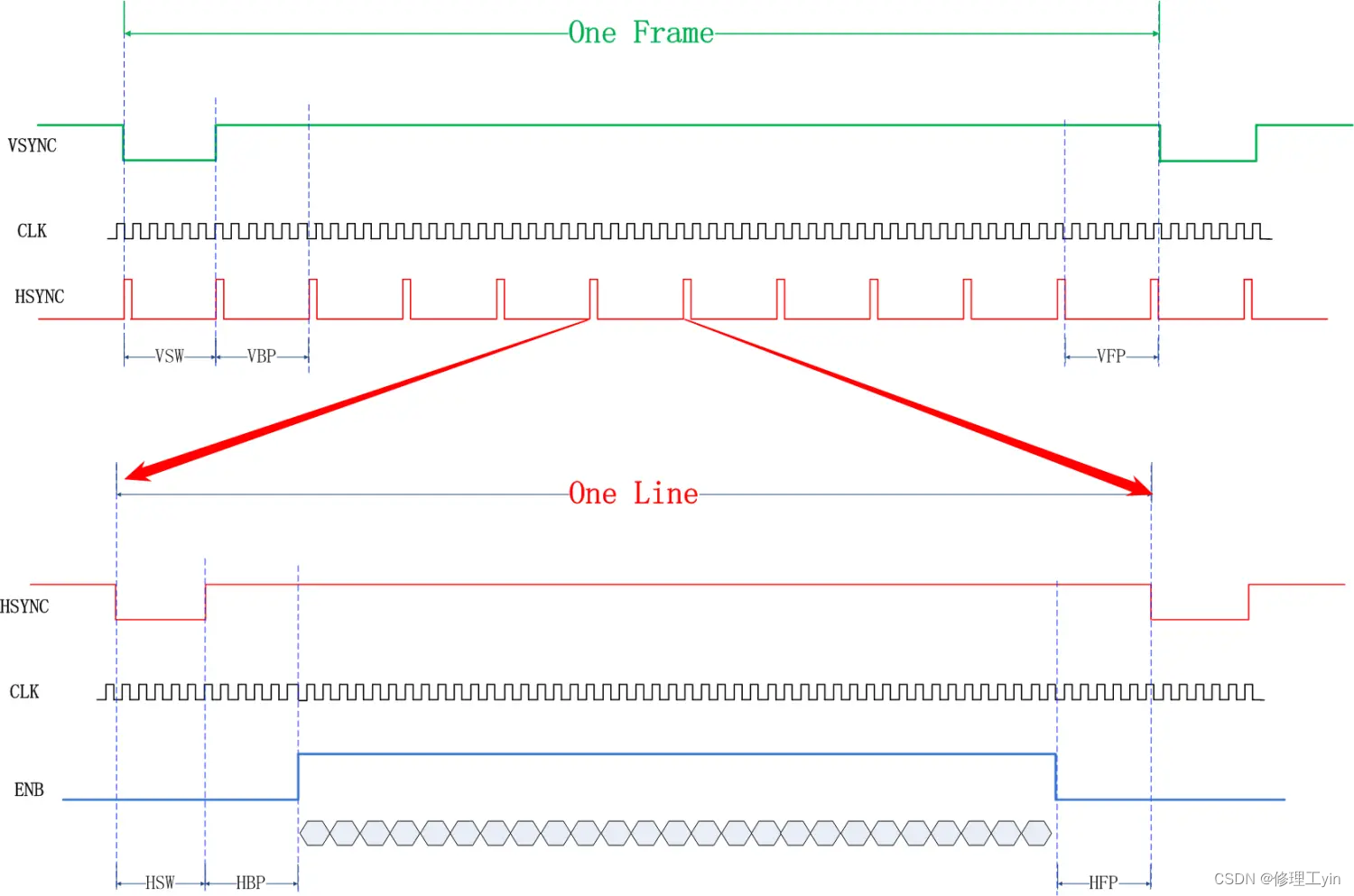
在一个Vsync周期内是由多个Hsync周期组成的,其个数就是屏幕在Y方向的像素点个数,也就是屏幕上有多少行像素点, 每个Hsync周期内传输一行内所有像素点的数据。通常屏厂给的spec文档还会给出类似下面这样的图,但都是表达一个意思,数据是以行为单位写入的,Hsync是协调行和行之间的同步信号,多个行依次写入构成一帧数据,帧和帧数据之间由Vsync信号来同步协调。
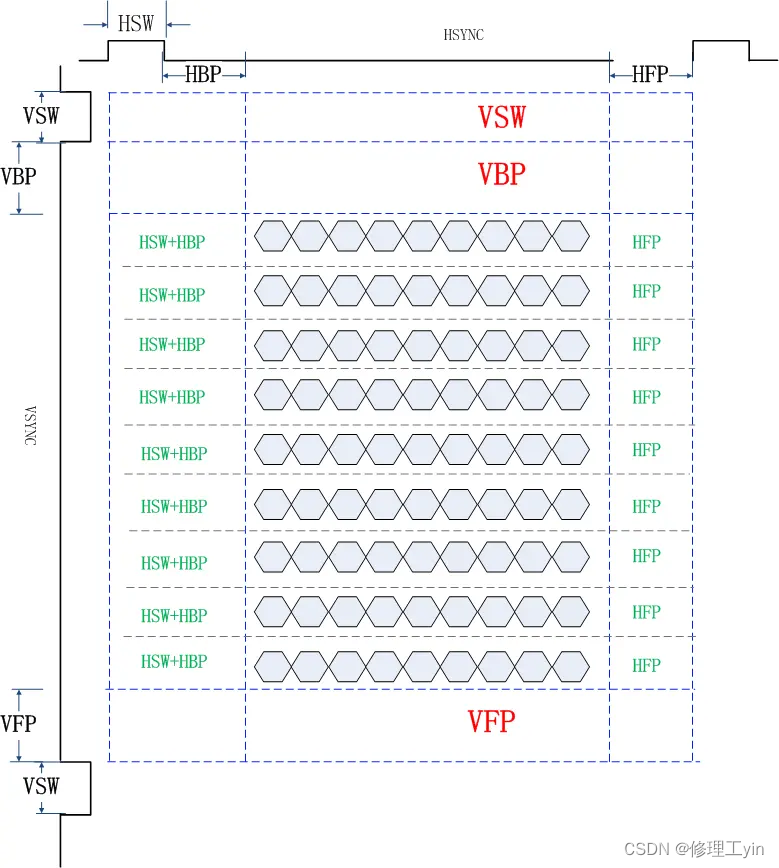
当多帧画面依次输出到屏幕的时候我们就可以看到运动的画面了,通常这个速度到达每秒60帧时人眼就已经感觉画面很流畅了。下图演示了在vsync和hsync同步下两帧画面间的切换时序,以及消隐区(VPorch)在其中的位置关系。在消隐区结束(或开始)时DDIC会向SOC发出一个中断信号,这个信号称为TE信号, SOC这边就是通过该中断信号来判断上一帧数据是否已被DDIC读走,进而决定是否可以将buffer写入下一帧数据。
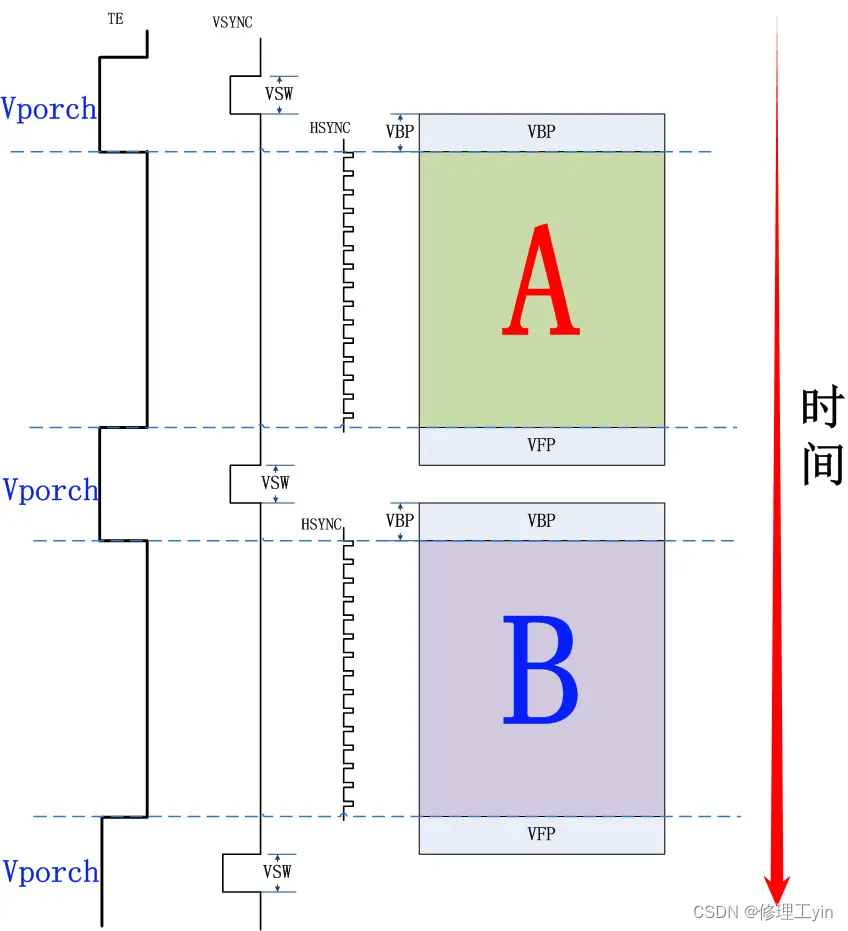
2.4. LCD上的画面更新流程
让我们以下面这张图来说明从SOC到到DDIC再到Panel的画面更新过程,首先SOC准备画面A, DDIC上一帧画面更新完毕进入消隐区,同时向SOC侧发送TE信号,SOC收到TE信号后,A画面的数据开始通过DSI总线向DDIC传输(DSI Write),当消隐区时间结束时开始这一帧数据从数据变为像素点颜色的过程(Disp Scan), Disp Scan是以行为单位将GRAM内一行的数据内容通过改变电流电压等方式改变Panel上像素点的颜色。进而实现一行画面的更新,按下来Disp Scan将以一定速度逐行读取GRAM的内容,而于此同时DSI Write也还在进行中,由于DSI Write较Disp Scan早了一个Vporch的时间,所以Disp Scan扫描到的数据都是A画面的数据。那么人眼会看到画面“逐渐”出现到显示屏上,当A画面的所有行都经Disp Scan到达屏幕后,下一个Vporch开始,DDIC再次向SOC发出TE信号, 下帧B画面的数据开始经过DSI总线传输到DDIC, 如此循环往复可以将连续的A, B, C画面更新到屏幕上。
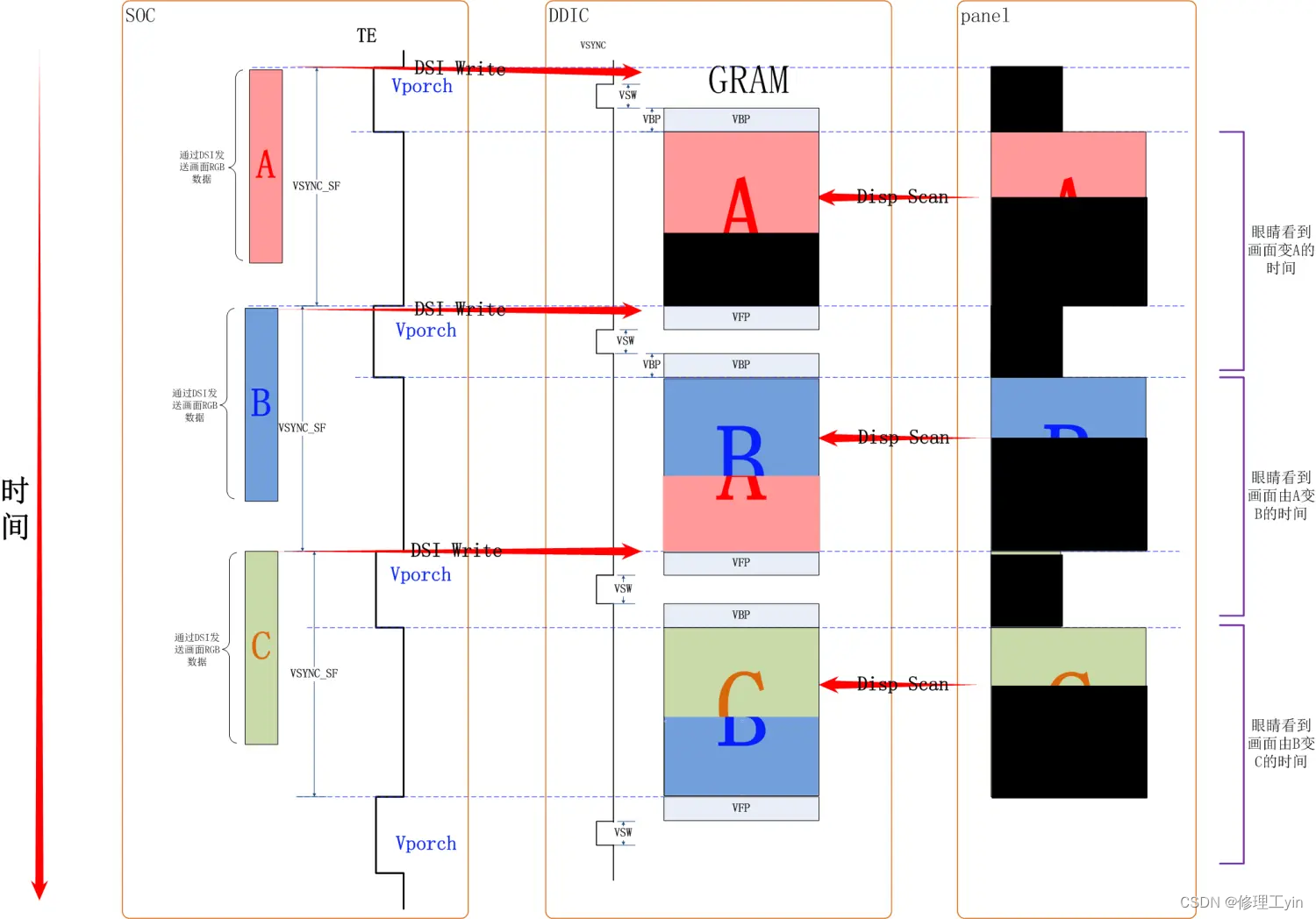
这里我们思考一个问题: 就像上图中所绘一样总会存在一段时间GRAM内的数据会出现一部分是新画面的数据,一部分是旧画面的数据,那么从上帝视角看GRAM里的画面是“撕裂”的,那Disp Scan会不会把这个“撕裂”的画面显示到Panel上呢? 用户有没有可能看到一个“撕裂”的画面呢?
答案是有可能会。
为讨论方便我们这里先把DSI write记作写, 把Disp Scan记作读, 正常情况下,我们会将读速度调到和写速度差不多,由于写是在进入vporch时就开始了,而读的动作是离开vproch时,所以在读和写的这场“百米跑”竞赛中总是写跑在前面,这样保证读始终读到的是同一帧画面的数据,这个过程如下面图1所示。
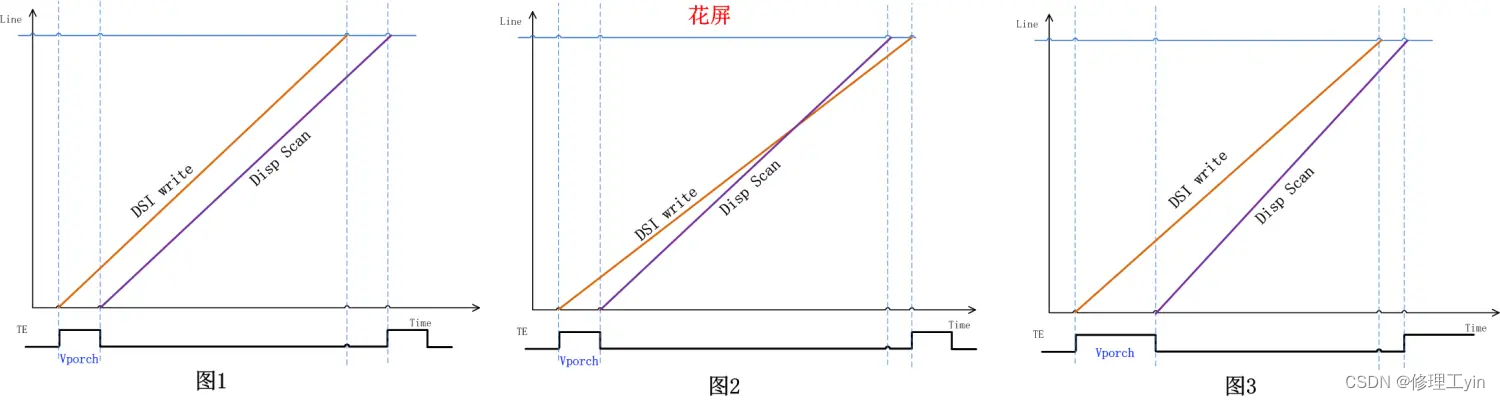
由于读和写的速度受到环境或各种电气因素影响并不是一成不变的,在实际运行过程中会有波动,当读和写两条线离的较近时由于速度波动的存在会出现两条线交叉的情况,如图2所示,那么这时读会先后读到前后两帧的数据,出现花屏现象。
有时我们为了避免由于速率波动引起花屏问题,会放大vporch的时间让读和写尽量拉开距离,这样可以减少花屏现象出现的概率,这里的原理如图3所示
继续思考下一问题: 从上面的分析可以看出Panel上的像素数据是一行行更新下来的,那人眼为什么没有看到更新了一半的画面呢?
这个问题我并不知道答案,这可能涉及到人眼的生物学构造,人眼对事物的成像原理等复杂的原理,总之是在这个时间尺度内人眼看不到。
接下来我们从另一角度来研究一下这个问题,我们把视角切换到上帝视角,假如存在上帝之眼的话,他应该能看到这个更新了一半的画面,我们尝试用高速摄影机来模拟“上帝之眼”。
首先我们先准备一些测试代码, 我们写一个测试用apk, 下面这段代码是向Android框架注册一个Choreographer的监听,Choreographer是Android提供的一个获取vsync信号的通道。当下图中doFrame被调用到时我们这里可以暂时粗略理解为是上面所讨论的TE信号, 这里收到Vsync信号后通过Pthread的Condition通知到另一线程。这用于模拟一个vsync的消息泵。
Choreographer.getInstance().postFrameCallback(new Choreographer.FrameCallback() {
@Override
public void doFrame(long frameTimeNanos) {//当vsync信号来时会调用到这里
Global.lock.lock();
try {
Global.syncCondition.signal();//通知另一条线程更新画面
} catch (Exception e) {
e.printStackTrace();
} finally {
Global.lock.unlock();
}
Choreographer.getInstance().removeFrameCallback(this);
Choreographer.getInstance().postFrameCallback(this);
}
});下面代码中每收到一个vsync信号都会去画一帧画面,同时给帧编号编号加1(相当于给每一帧一个编号),如果当前的编号为奇数则画绿色,如果为偶数则画蓝色,那么画面应该是蓝绿交替出现:
public class MySurfaceView extends SurfaceView implements SurfaceHolder.Callback, Runnable {
.......
@Override
public void run() {
while(true) {
Global.lock.lock();
try {
Global.syncCondition.await();//在这里等待vsync到来的通知消息
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
Global.lock.unlock();
}
draw();//画蓝色或绿色
}
}
........
private void draw() {
Canvas mCanvas = null;
try {
mCanvas = mSurfaceHolder.lockCanvas();
if(autoNum %2 == 0) {
mPaint.setColor(Color.BLUE);//如果为双数则画面画成蓝色
} else {
mPaint.setColor(Color.GREEN);//如果为单数则画面画成绿色
}
mCanvas.drawRect(0, 0, getRight(), getBottom(), mPaint);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (mCanvas != null) {
mSurfaceHolder.unlockCanvasAndPost(mCanvas);
}
}
autoNum++;//数字加1
}
}下面是高速摄影机看到的画面变化情况,从下图中可以看出来,画面从绿变蓝的过程中总是能看到先是上面部分变蓝色,接下来才会看到全部变蓝,由蓝变绿也是同样的现象,先是图像上面变成绿色接下来全部变绿色,在“上帝之眼”看来画面的变化是有前后两个画面各占一部分的情况的,这情况是上面是新画面下面是旧画面,但人眼是看不出来这种画面。
下面的图中发现画面是颜色渐变的,这是因为通过高速摄影机是画面再次感光形成的影像,由于物理世界中光线是有衍射及曝光时长因素的,所以最终在高速摄影机留下的图中是颜色渐变的。

2.5. 本章小结
在本章节中,我们了解到了一些显示硬件的一些组成要件,以及屏幕是如何按时序更新画面的,以及在画面更新过程中屏和SOC间的一些互动是如何完成的。那么接下来我们再来了解下SOC内部是如何把画面送过来的。
3. DRM
DRM,英文全称 Direct Rendering Manager, 即 直接渲染管理器。
DRM是linux内核的一个子系统,它提供一组API,用户空间程序可以通过它发送画面数据到GPU或者专用图形处理硬件(如高通的MDP),也可以使用它执行诸如配置分辨率,刷新率之类的设置操作。原本是设计提供给PC使用来支持复杂的图形设备,后来也用于嵌入式系统上。目前在高通平台手机Android系统上的显示系统也是使用的这组API来完成画面的渲染更新。
在DRM之前Linux内核已经有一个叫FBDEV的API,用于管理图形适配器的帧缓存区,但不能用于满足基于3D加速的现代基于GPU的视频硬件的需求,FBDEV社区维护者也较少; 且无法提供overlay hw cursor这样的features; 开发者们本身就鼓励以后迁移到DRM上。
3.1. 基本组件
DRM主要由如下部分组成:
KMS(Kernel Mode Setting): 主要是配置信息管理,如改变分辨率,刷新率,位深等
DRI(Direct Rendering Infrastructure): 可以通过它直接访问一些硬件接口
GEM(Graphics Execution Manager): 主要负责内存管理,CPU, GPU对内存的访问控制由它来完成。
DRM Driver in kernel side: 访问硬件
在高通平台上其中部分模块所处位置见下图:
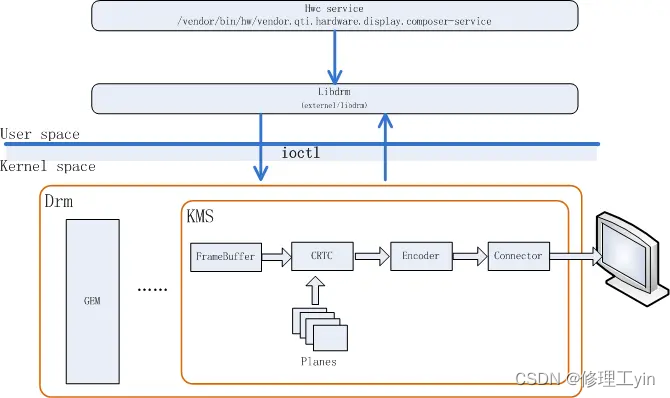
其中KMS由frame buffer, CRTC, Encoder, Connector等组件组成
CRTC
CRT controller,目前主要用于显示控制,如显示时序,分辨率,刷新率等控制,还要承担将framebuffer内容送到display,更新framebuffer等。
Encoder
负责将数据转换成合适的格式,送给connector,比如HDMI需要TMDS信息, encoder就将数据转成HDMI需要的TMDS格式。
Connector
它是具体某种显示接口的代表,如 hdmi, mipi等。用于传输信号给外部硬件显示设备,探测外部显示设备接入。
Planes
一个Plane代表一个image layer, 最终的image由一个或者多个Planes组成
在Android系统上DRM就是通过KMS一面接收userspace交付的应用画面,一面通过其connector来向屏幕提交应用所绘制的画面。
3.2. DRM使用示例
如下仅是示意代码,篇幅所限只摘取了完整代码中的部分关键代码,代码演示的是初始化,创建surface, 在surface上作画(这里只是画了一张全红色的画面),然后通过page flip方式将画面更新到屏幕的过程。
1. 定义一些全局变量:
......
#include <drm_fourcc.h>
#include <drm.h>
......
static drmModeCrtc *main_monitor_crtc;
static drmModeConnector *main_monitor_connector;
static int drm_fd = -1;
static drmModeRes *res = NULL;2. 打开drm设备节点/dev/dri/card0
uint64_t cap = 0;
drm_fd = open("/dev/dri/card0", O_RDWR, 0);
ret = drmGetCap(drm_fd, DRM_CAP_DUMB_BUFFER, &cap);
res = drmModeGetResources(drm_fd);3. 找到所使用的connector及其mode
int i = 0;
//find main connector
for(i = 0; i < res->count_connectors;i++) {
drmModeConnector *connector;
connector = drmModeGetConnector(drm_fd, res->connectors[i]);
if(connector) {
if((connector->count_modes > 0) && connector->connection == DRM_MODE_CONNECTED)) {
main_monitor_connector = connector;
break;
}
drmModeFreeConnector(connector);
}
}
......
uint32_t select_mode = 0;
for(int modes = 0; modes < main_monitor_connector->count_modes; modes++) {
if(main_monitor_connector->modes[modes].type & DRM_MODE_TYPE_PREFERRED) {
select_mode = modes;
break;
}
}4. 获取当前显示器的一些信息如宽高
drmModeEncoder *encoder = drmModeGetEncoder(drm_fd, main_monitor_connector->encoder_id);
int32_t crtc = encoder->crtc_id;
drmModeFreeEncoder(encoder);
drmModeCrtc *main_monitor_crtc = drmModeGetCrtc(fd, crtc);
main_monitor_crtc->mode = mina_monitor_connector->modes[select_mode];
int width = main_monitor_crtc->mode.hdisplay;
int height = main_monitor_crtc->mode.vdisplay5. 创建一个画布
struct GRSurface *surface;
struct drm_mode_create_dumb create_dumb;
uint32_t format;
int ret;
surface = (struct GRSurface*)calloc(1, sizeof(*surface));
format = DRM_FORMAT_ARGB8888;
......
create_dumb.height = height;
create_dumb.width = width;
create_dumb.bpp = drm_format_to_bpp(format);
create_dumb.flags = 0;
ret = drmIoctl(drm_fd, DRM_IOCTL_MODE_CREATE_DUMB, &create_dumb);
surface->handle = create_dumb.handle;
......
//创建一个FrameBuffer
ret = drmModeAddFB2(drm_fd, width, height, fromat, handles, pitches, offsets, &(surface->fb_id), 0);
......
ret = drmIoCtl(drm_fd, DRM_IOCTL_MODE_MAP_DUMB, &map_dumb);
......
//这里通过mmap的方式把画布对应的buffer映射到本进程空间来
surface->data =(unsigned char*)mmap(NULL, height*create_dumb.pitch, PROT_READ|PROT_WRITE, MAP_SHARED, drm_fd, map_dumb.offset);
drmModeSetCrtc(drm_fd, main_monitor_crtc->crtc_id,
0, //fb_id
0, 0,//x,y
NULL, //connectors
0,//connector_count
NULL);//mode 6. 在画布上作画,这里是画了一个纯红色的画面
int x, y;
unsigned char* p = surface->data;
for(y = 0; y < height; y++) {
unsigned char *px = p;
for(x = 0; x < width; x++){
*px++ = 255;//r
*px++ = 0; //g
*px++ = 0; //b
*px++ = 255; //a
}
p += surface->row_bytes;
}7. 通过page flip将画面送向屏幕
drmModePageFlip(drm_fd, main_monitor_crtc->crtc_id, surface->fb_id, 0, NULL); 需要注意的是/dev/dri/card0的使用方式是独占的,也就是如果一个进程open了这个节点,其他进程是无法再打开的,在android平台测试时要运行测试程序时需要将原来的进程先kill掉,如在高通平台上要先kill掉这个进程:vendor.qti.hardware.display.composer-service,由于它会自动重启,所以要将它的执行文件 /vendor/bin/hw/vendor.qti.hardware.display.composer-service 重命名或删掉,才能做测试.
3.3. 本章小结
在本章节中我们认识了linux给userspace提供的屏幕操作的接口,通过一个简单例子粗略地了解了这些接口的一个用法,让我们知晓了可以通过这组api来向屏幕来提交我们所绘制的画面。那么在Android的display架构中是谁在使用这组api呢?
4. Userspace的帧数据流
在Android系统上应用要绘制一个画面,首先要向SurfaceFlinger申请一个画布,这个画布所使用的buffer是SurfaceFlinger通过allocator service(vendor.qti.hardware.display.allocator-service)来分配出来的,allocator service是通过ION从kernel开辟出来的一块共享内存,这里申请的都是每个图层所拥有独立buffer, 这个buffer会共享到HWC Service里,由SurfaceFlinger来作为中枢控制这块buffer的所有权,其所有权会随状态不同在App, SurfaceFlinger, HWC Service间来回流转。
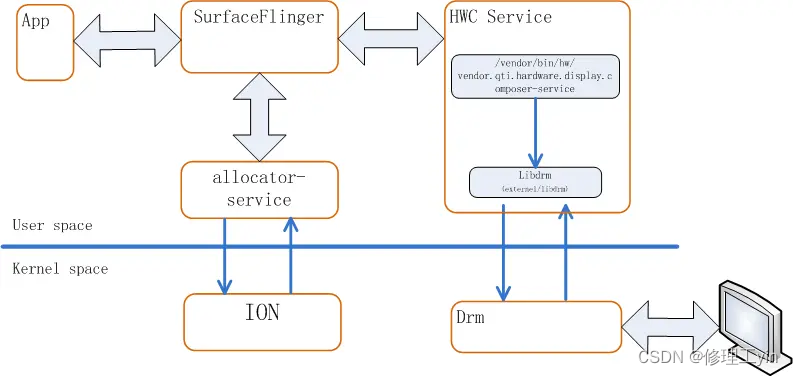
而HWC Service正是那个使用libdrm和kernel打交道的人 ,它负责把SurfaceFlinger交来的图层做合成,将合成后的画画提交给DRM去显示。
4.1. App到SurfaceFlinger
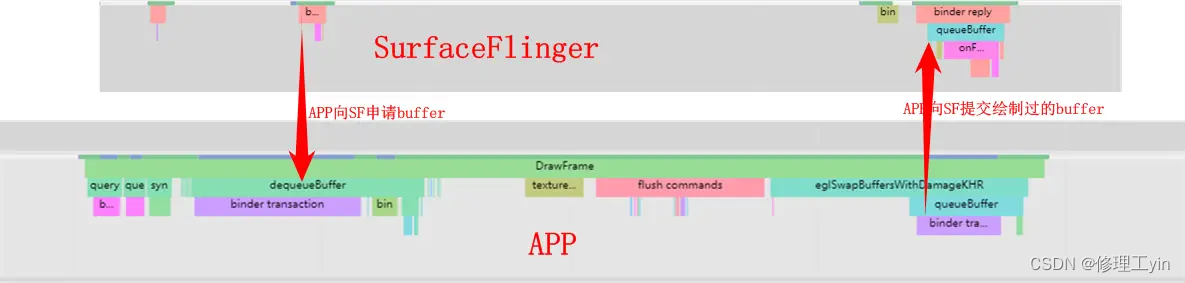
应用首先通过Surface的接口向SurfaceFlinger申请一块buffer, 需要留意的是Surface刚创建时是不会有buffer被alloc出来的,只有应用第一次要绘制画面时dequeueBuffer会让SurfaceFlinger去alloc buffer, 在应用侧会通过importBuffer把这块内存映射到应用的进程空间来,这个过程可以在systrace上观察到:

之后App通过dequeueBuffer拿到画布, 通过queueBuffer来提交绘制好的数据, 这个过程可以在如下systrace上观察到:
HWC Service负责将SurfaceFlinger送来的图层做合成,形成最终的画面,然后通过drm的接口更新到屏幕上去(注意:在DRM一章中给出的使用DRM的例子子demo的是通过page flip方式提交数据的,但hwc service使用的是另一api atomic commit的方式提交数据的,drm本身并不只有一种方式提交画面)
4.2. SurfaceFlinger到HWC Service
HWC Service的代码位置在 hardware/qcom/display, HWC Service使用libdrm提交帧数据的地方我们可以在systrace上观察到:
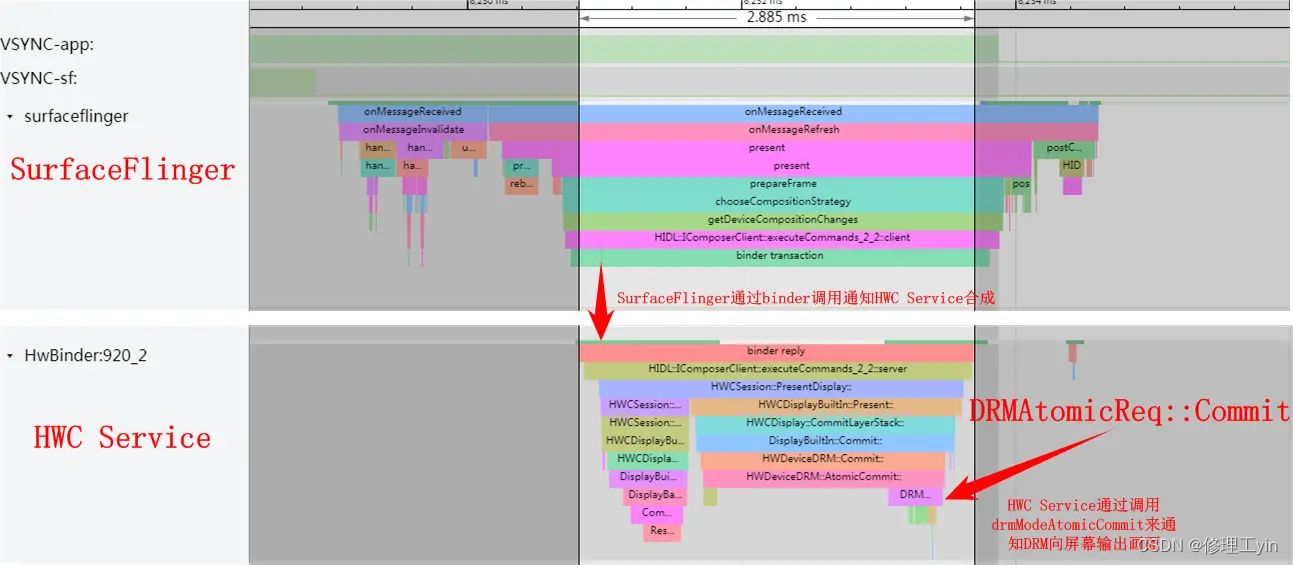
而上图中的DRMAtomicReq::Commit会调用到
drmModeAtomicCommit这个接口,该接口定义在 externel/libdrm/xf86drmMode.h, 其原型如下
........
extern int drmModeAtomicCommit(int fd, drmModeAtomicReqPtr req, uint32_t flags, void *user_data);
.......PageFlip方式的接口也是定义在这里:
........
extern int drmModePageFlip(int fd, uint32_t crtc_id, uint32_t fb_id, uint32_t flags, void *user_data);
........4.3. HWC Service到kernel
hwc service通过drmModeAtomicCommit接口向kernel提交合成数据:
代码位置位于:hardware/qcom/display/sde-drm/drm_atomic_req.cpp
int DRMAtomicReq::Commit(bool synchronous, bool retain_planes) {
DTRACE_SCOPED();//trace
......
int ret = drmModeAtomicCommit(fd_, drm_atomic_req_, flags, nullptr);
......
}drmModeAtomicCommit通过ioctl调用到kernel:
kernel/msm-5.4/techpack/display/msm/msm_atomic.c
static void _msm_drm_commit_work_cb(struct kthread_work *work) {
......
SDE_ATRACE_BEGIN("complete_commit");
complete_commit(commit);
SDE_ATRACE_END("complete_commit");
......
}
static struct msm_commit *commit_init(struct drm_atomic_state *state, bool nonblock) {
......
kthread_init_work(&c->commit_work, _msm_drm_commit_work_cb);//将callback注册到commit_work
......
}
static void msm_atomic_commit_dispatch(struct drm_device *dev,
struct drm_atomic_state *state, struct msm_commit *commit) {
......
kthread_queue_work(&priv->disp_thread[j].worker, &commit->commit_work);//向消息队列中加入一个消息,disp thread处理到该消息时会调用到_msm_drm_commit_work_cb
......
}
drmModeAtomicCommit的ioctl会触发msm_atomic_commit_dispatch,然后通知disp thread也就是如下图所示的crtc_commit线程去处理这个消息,然后执行
complete_commit函数,这个过程见下图:
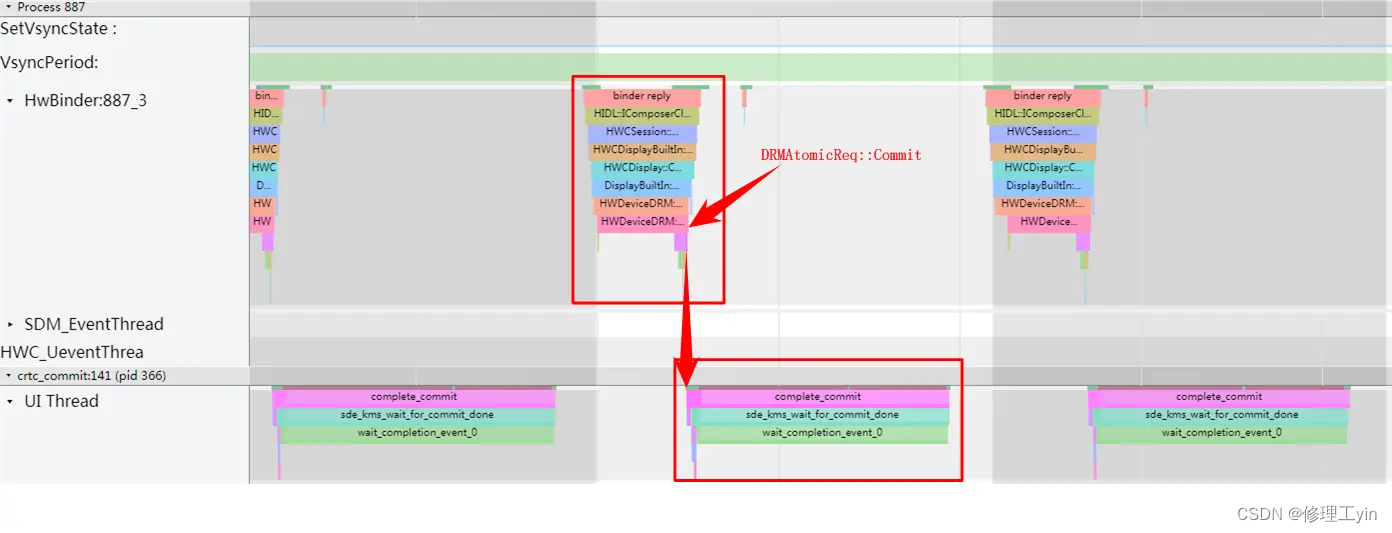
4.4. 本章小结
在本章中我们了解了APP绘画的画布是由SurfaceFlinger提供的,而画布是一块共享内存,APP向SurfaceFlinger申请到画布,是将共享内存的地址映射到自身进程空间。 App负责在画布上作画,画完的作品提交给SurfaceFlinger, 这个提交操作并不是把内存复制一份给SurfaceFlinger,而是把共享内存的控制权交还给SurfaceFlinger, SurfaceFlinger把拿来的多个应用的共享内存再送给HWC Service去合成, HWC Service把合成的数据交给DRM去输出完成app画面显示到屏幕上的过程。为了更有效地利用时间这样的共享内存不止一份,可能有两份或三份,即常说的double buffering, triple buffering.
那么我们就需要设计一个机制可以管理buffer的控制权,这个就是BufferQueue.
5. BufferQueue
BufferQueue要解决的是生产者和消费者的同步问题,应用程序生产画面,SurfaceFlinger消费画面;SurfaceFlinger生产画面而HWC Service消费画面。用来存储这些画面的存储区我们称其为帧缓冲区buffer, 下面我们以应用程序作为生产者,SurfaceFlinger作为消费者为例来了解一下BufferQueue的内部设计。
5.1. Buffer State的切换
在BufferQueue的设计中,一个buffer的状态有以下几种:
FREE :表示该buffer可以给到应用程序,由应用程序来绘画
DEQUEUED:表示该buffer的控制权已经给到应用程序侧,这个状态下应用程序可以在上面绘画了
QUEUED: 表示该buffer已经由应用程序绘画完成,buffer的控制权已经回到SurfaceFlinger手上了
ACQUIRED:表示该buffer已经交由HWC Service去合成了,这时控制权已给到HWC Service了
Buffer的初始状态为FREE, 当生产者通过dequeueBuffer来申请buffer成功时,buffer状态变为了DEQUEUED状态, 应用画图完成后通过queueBuffer把buffer状态改到QUEUED状态, 当SurfaceFlinger通过acquireBuffer操作把buffer拿去给HWC Service合成, 这时buffer状态变为ACQUIRED状态,合成完成后通过releaseBuffer把buffer状态重新改为FREE状态。状态切换如下图所示:
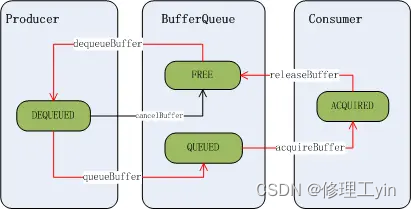
从时间轴上来看一个buffer的状态总是这样循环变化:
FREE->DEQUEUED->QUEUED->ACQUIRED->FREE
应用程序在DEQUEUED状态下绘画,而HWC Service在状态为ACQUIRED状态下做合成:
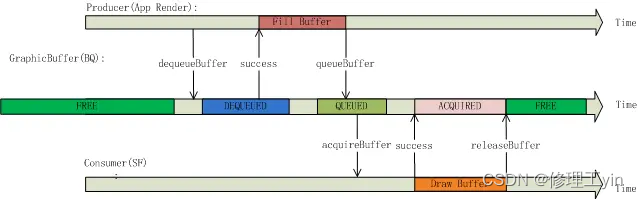
5.2. BufferSlot
每一个应用程序的图层在SurfaceFlinger里称为一个Layer, 而每个Layer都拥有一个独立的BufferQueue, 每个BufferQueue都有多个Buffer,Android 系统上目前支持每个Layer最多64个buffer, 这个最大值被定义在frameworks/native/gui/BufferQueueDefs.h, 每个buffer用一个结构体BufferSlot来代表。
每个BufferSlot里主要有如下重要成员:
struct BufferSlot{
......
BufferState mBufferState;//代表当前Buffer的状态 FREE/DEQUEUED/QUEUED/ACQUIRED
....
sp<GraphicBuffer> mGraphicBuffer;//代表了真正的buffer的存储空间
......
uint64_t mFrameNumber;//表示这个slot被queued的编号,在应用调dequeueBuffer申请slot时会参考该值
......
sp<Fence> mFence;//在Fence一章再来看它的作用
.....
}64个BufferSlot可以分成两个部分,used Slots和Unused Slots, 这个比较好理解,就是使用中的和未被使用的,而Used Slots又可以分为Active Slots和UnActive Slots, 处在DEQUEUED, QUEUED, ACQUIRED状态的被称为Active Slots, 剩下FREE状态的称为UnActive Slots, 所以所有Active Slots都是正在有人使用中的slot, 使用者可能是生产者也可能是消费者。而FREE状态的Slot根据是否已经为其分配过内存来分成两个部分, 一是已经分配过内存的,在Android源码中称为mFreeBuffers, 没有分配过内存的称为mFreeSlots, 所以如果我们在代码中看到是从mFreeSlots里拿出一个BufferSlot那说明这个BufferSlot是还没有配置GraphicBuffer的, 这个slot可能是第一次被使用到。其分类如下图所示:
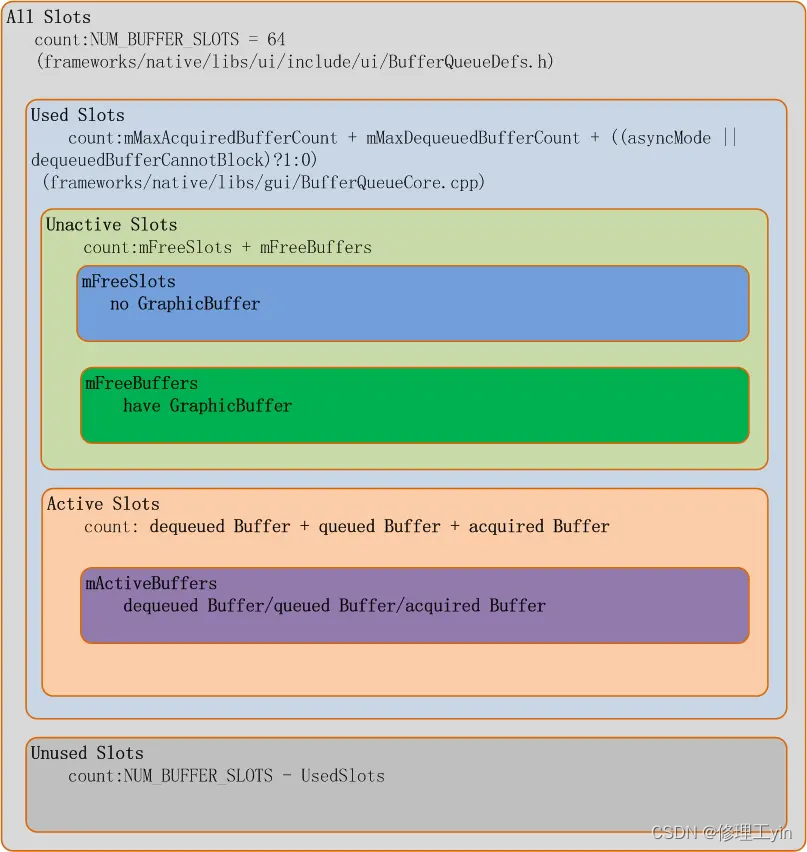
我们来看一下,应用上帧时SurfaceFlinger是如何管理分配这些Slot的。
应用侧对图层buffer的操作接口是如下文件:
frameworks/native/libs/gui/Surface.cpp
应用第一次dequeueBuffer前会通过connect接口和SurfaceFlinger建立“连接”:
int Surface::connect(int api, const sp<IProducerListener>&listener, bool reportBufferRemoval){
ATRACE_CALL();//应用第一次上帧前可以在trace 中看到这个
......
int err = mGraphicBufferProducer->connect(listener, api, mProducerControlledByApp, &output);//这里通过binder调用和SurfaceFlinger建立联系
......
}应用在第一次dequeueBuffer时会先调用requestBuffer:
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
ATRACE_CALL();//这里可以在systrace中看到
......
//这里尝试去dequeueBuffer,因为这时SurfaceFlinger对应Layer的slot还没有分配buffer,这时SurfaceFlinger会回复的flag会有BUFFER_NEEDS_REALLOCATION
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps?&frameTimestamps:nullptr);
......
if((result & IGraphicBufferProducer::BUFFER_NEEDS_REALLOCATION) || gbuf == nullptr) {
......
//这里检查到dequeueBuffer返回的结果里带有BUFFER_NEEDS_REALLOCATION标志就会发出一次requestBuffer
result = mGraphicBufferProducer->requestBuffer(buf, &gbuf);
......
}
......
}在SurfaceFlinger这端,第一次收到dequeueBuffer时发现分配出来的slot没有GraphicBuffer, 这时会去申请对应的buffer:
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
if ((buffer == NULL) ||
buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage))//检查是否已分配了GraphicBuffer
{
......
returnFlags |= BUFFER_NEEDS_REALLOCATION;//发现需要分配buffer,置个标记
}
......
if (returnFlags & BUFFER_NEEDS_REALLOCATION) {
......
//新创建一个新的GraphicBuffer给到对应的slot
sp<GraphicBuffer> graphicBuffer = new GraphicBuffer(
width, height, format, BQ_LAYER_COUNT, usage,
{mConsumerName.string(), mConsumerName.size()});
......
mSlots[*outSlot].mGraphicBuffer = graphicBuffer;//把GraphicBuffer给到对应的slot
......
}
......
return returnFlags;//注意在应用第一次请求buffer, dequeueBuffer返回时对应的GraphicBuffer已经创建完成并给到了对应的slot上,但返回给应用的flags里还是带有BUFFER_NEEDS_REALLOCATION标记的
}应用侧收到带有BUFFER_NEEDS_REALLOCATION标记的返回结果后就会调requestBuffer来获取对应buffer的信息:
从上面可以看出requestBuffer的主要作用就是把GraphicBuffer传递到应用侧,这里思考一个问题,既然SurfaceFlinger在响应dequeueBuffer时就已经为slot新创建了GraphicBuffer, 为什么还需要应用侧再次调用requestBuffer时再把GraphicBuffer传给应用呢? 为什么dequeueBuffer不直接返回呢?这不是多花费一次跨进程通信的时间吗? 为什么设计成了这个样子呢?
我们再来看一下应用侧接口dequeueBuffer的函数设计:
frameworks/native/libs/gui/IGraphicBufferProducer.h
virtual status_t dequeueBuffer(int* buf, sp<Fence>* fence, uint32_t width, uint32_t height,
PixelFormat format, uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps);注意第一个参数只是返回一个int值,它表示的是64个slot里的哪一个slot, 其他参数里也不会返回这个slot所对应的GraphicBuffer的信息,但这个slot拿到应用侧后,应用是要拿到确确实实的GraphicBuffer才能把共享内存mmap到自已进程空间,才能在上面绘画。而显然这个接口的设计并不会带来GraphicBuffer的信息,那设计之初为什么不把这个信息放进来呢? 因为这个接口调用太频繁了,比如在90FPS的设备上,一秒钟该接口要执行90次,太频繁了,而且这个信息只需要传递一次就可以了,如果每次这个接口都要带上GraphicBuffer的信息,传输了很多冗余数据,所以不如加入一个新的api(requestBuffer)来完成GraphicBuffer传递的事情.
应用侧在requestBuffer后会拿到GraphicBuffer的信息,然后会通过importBuffer在本进程内通过binder传过来的parcel包把GraphicBuffer重建出来:
frameworks/native/libs/ui/GraphicBuffer.cpp
status_t GraphicBuffer::unflatten(
void const*& buffer, size_t& size, int const*& fds, size_t& count) {
......
if (handle != 0) {
buffer_handle_t importedHandle;
//获取从SurfaceFlinger传过来的buffer
status_t err = mBufferMapper.importBuffer(handle, uint32_t(width), uint32_t(height),
uint32_t(layerCount), format, usage, uint32_t(stride), &importedHandle);
......
}
......
}如下图所示,从App侧看,前三帧都会有requestBuffer, 都会有importBuffer,在第4帧时就没有requestBuffer/importBuffer了,因为我们当前系统一共使用了三个buffer,从systrace上可以看到这个区别:

当一个surface被创建出来开始上帧时其流程如下图所示,应用所使用的画布是在前三帧被分配出来的,从第四帧开始进入稳定上帧期,这时会重复循环利用前三次分配的buffer。
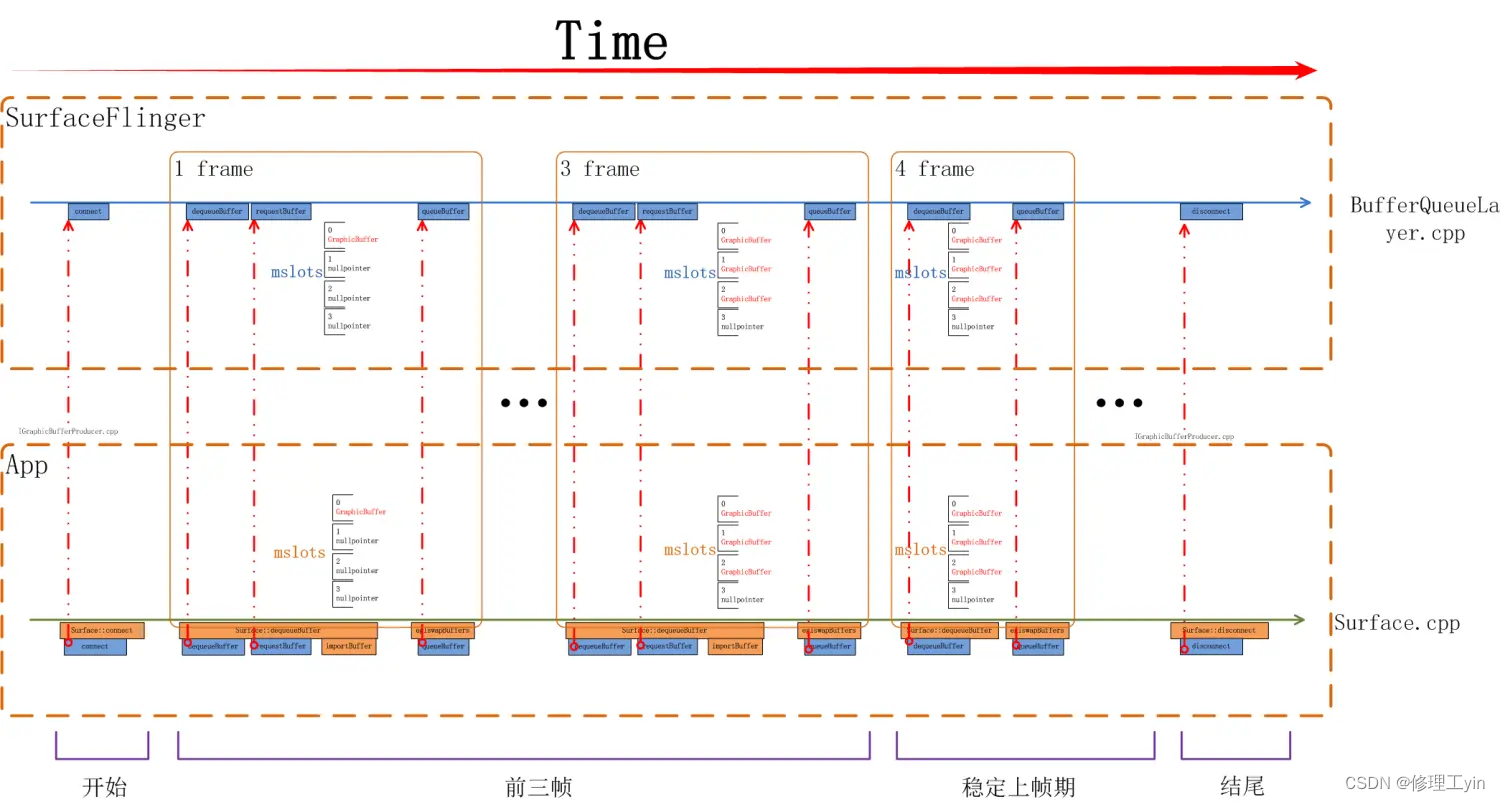
思考一个问题,在三个buffer的系统中一定是前三帧中触发分配GraphicBuffer吗? 如果某个应用有一个SurfaceView自已决定上帧的帧率,而这个帧率非常低,如低到一秒一帧,那前三秒会把三个Buffer分配出来吗?我们需要了解一下多buffer下SurfaceFlinger的管理策略是什么。
5.3. Buffer管理
前文提到了每个图层Layer都有最多64个BufferSlot, 如下图所示,每个BufferSlot都会记录有自身的状态(BufferState),以及自已的GraphicBuffer指针mGraphicBuffer.

但不是每个Layer都能使用到那么多,每个Layer最多可使用多少个Layer是在这里设置的:
frameworks/native/services/surfaceflinger/BufferQueueLayer.cpp
void BufferQueueLayer::onFirstRef() {
......
// BufferQueueCore::mMaxDequeuedBufferCount is default to 1
if (!mFlinger->isLayerTripleBufferingDisabled()) {
mProducer->setMaxDequeuedBufferCount(2);//3 buffer时这里设为2, 是因为在BufferQueueCore那里会+1
}
......
}我们重新回忆下BufferSlot的几个状态,FREE ,代表该buffer可以给到应用程序,由应用程序来绘画, 这样的Slot SurfaceFlinger会根据是否有给它分配有GraphicBuffer分到两个队列里, 有GraphicBuffer的分配到mFreeBuffers里, 没有GraphicBuffer的分配到mFreeSlots里; 当应用申请走一个Slot时,该Slot状态会切换到DEQUEUED状态,该Slot会被放入mActiveBuffers队列里; 当应用绘画完成后Slot状态会切到QUEUED状态,所有QUEUED状态的Slot会被放入mQueue队列里; 当一个Slot被HWC Service拿去合成后状态会变为ACQUIRED, 这个Slot会被从mQueue队列中取出放入mActiveBuffers队列里;
我们先来看一个BufferSlot管理的场景:
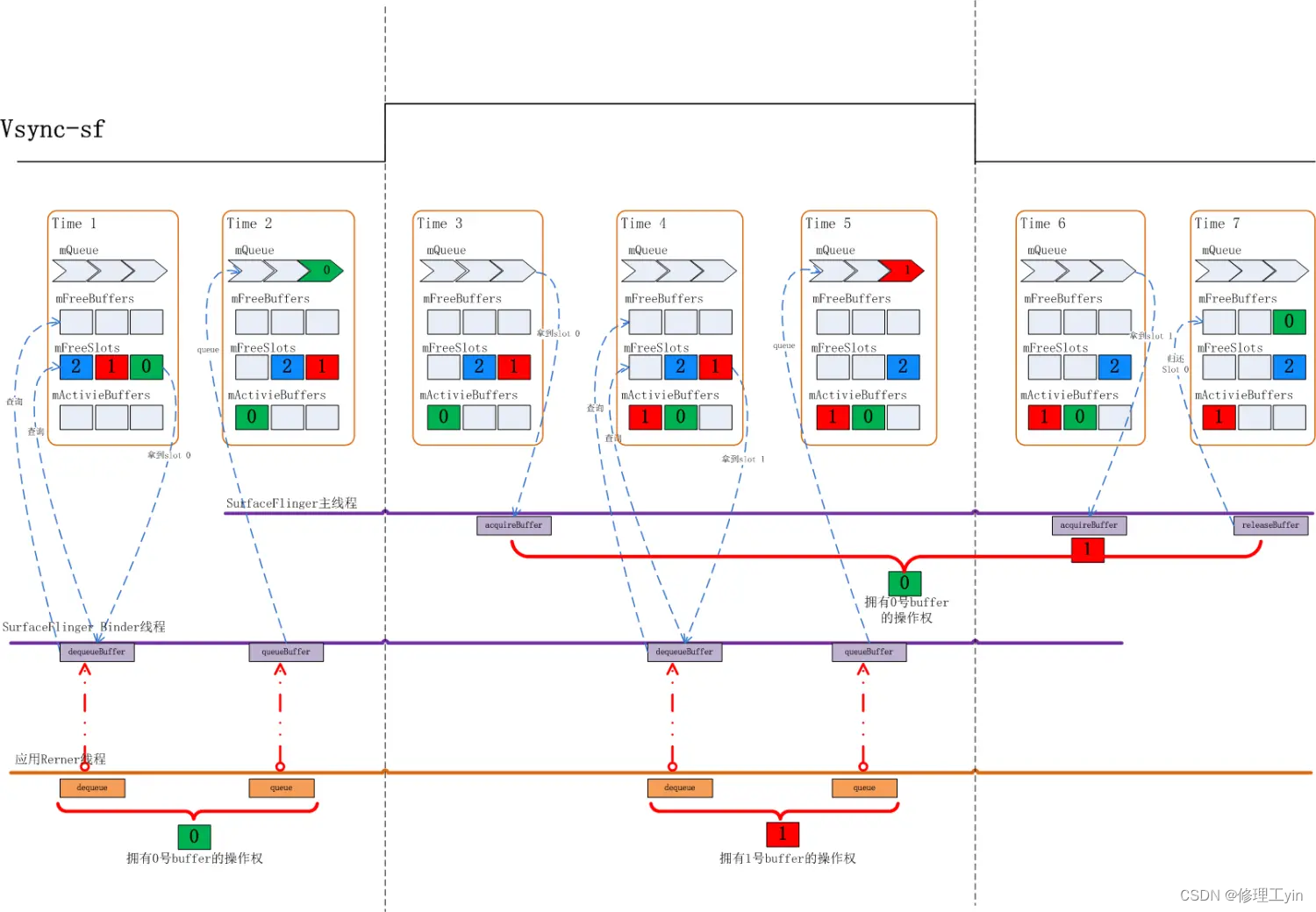
Time1: 在上图中,初始状态下,有0, 1, 2这三个BufferSlot, 由于它们都没有分配过GraphicBuffer, 所以它们都位于mFreeSlots队列里,当应用来dequeueBuffer时,SurfaceFlinger会先检查在mFreeBuffers队列中是否有Slot, 如果有则直接分配该Slot给应用。显然此时mFreeBuffers里是空的,这时Surfaceflinger会去mFreeSlots里去找出第一个Slot, 这时就找到了0号Slot, dequeueBuffer结束时应用就拿到了0号Slot的使用权,于此同时SurfaceFlinger也会为0号Slot分配GraphicBuffer, 之后应用将通过requestBuffer和importBuffer来获取到该Slot的实际内存空间。
应用dequeueBuffer之后0号Slot切换到DEQUEUED状态,并被放入mActiveBuffers列表。
Time2:应用完成绘制后通过queueBuffer来提交绘制好的画面,完成后0号Slot状态变为QUEUED状态,放入mQueue队列,此时1,2号Slot还停留在mFreeSlots队列中。
Time3: 上面这个状态会持续到下一个Vsync-sf信号到来,当Vsync-sf信号到来时,SurfaceFlinger主线程会检查mQueue队列中是否有Slot, 有就意味着有应用上帧,这时它会把该Slot从mQueue中取出放入mActiveBuffers队列,并将Slot的状态切换到ACQUIRED, 代表这个Slot已被拿去做画面合成。那么这之后0号Slot被从mQueue队列拿出放入mActivieBuffers里。
Time4:接下来应用继续调用dequeueBuffer申请buffer, 此时0号Slot在mActiveBuffers里,1,2号在mFreeSlots里,SurfaceFlinger仍然是先检查mFreeBuffers里有没有Slot, 发现还是没有,再检查mFreeSlots里是否有,于是取出了1号Slot给到应用侧,同时1号Slot状态切换到DEQUEUED状态, 放入mActiveBuffers里,
Time5:1号Slot应用绘画完毕,通过queueBuffer提交上来,这时1号Slot状态由DEQUEUED状态切换到了QUEUED状态,进入mQueue队列,之后将维持该状态直到下一个Vsync-sf信号到来。
Time6: 此时Vsync-sf信号到来,发现mQueue中有个Slot 1, 这时SurfaceFlinger主线程会把它取出,把状态切换到ACQUIRED, 并放入mActiveBuffers里。
Time7:这时0号Slot HWC Service使用完毕,通过releaseBuffer还了回来,0号Slot的状态将从ACQUIRED切换回FREE, Surfaceflinger会把它从mActivieBuffers里拿出来放入mFreeBuffers里。注意这时放入的是mFreeBuffers里而不是mFreeSlots里,因为此时0号Slot是有GraphicBuffer的。
在上述过程中SurfaceFlinger收到应用dequeueBuffer请求时处在FREE状态的Slot都还没有分配过GraphicBuffer, 由之前的讨论我们知道这通常发生在一个Surface的前几帧时间内。如3 buffer下的前三帧。
我们再来看一下申请buffer时mFreeBuffers里有Slot时的情况:
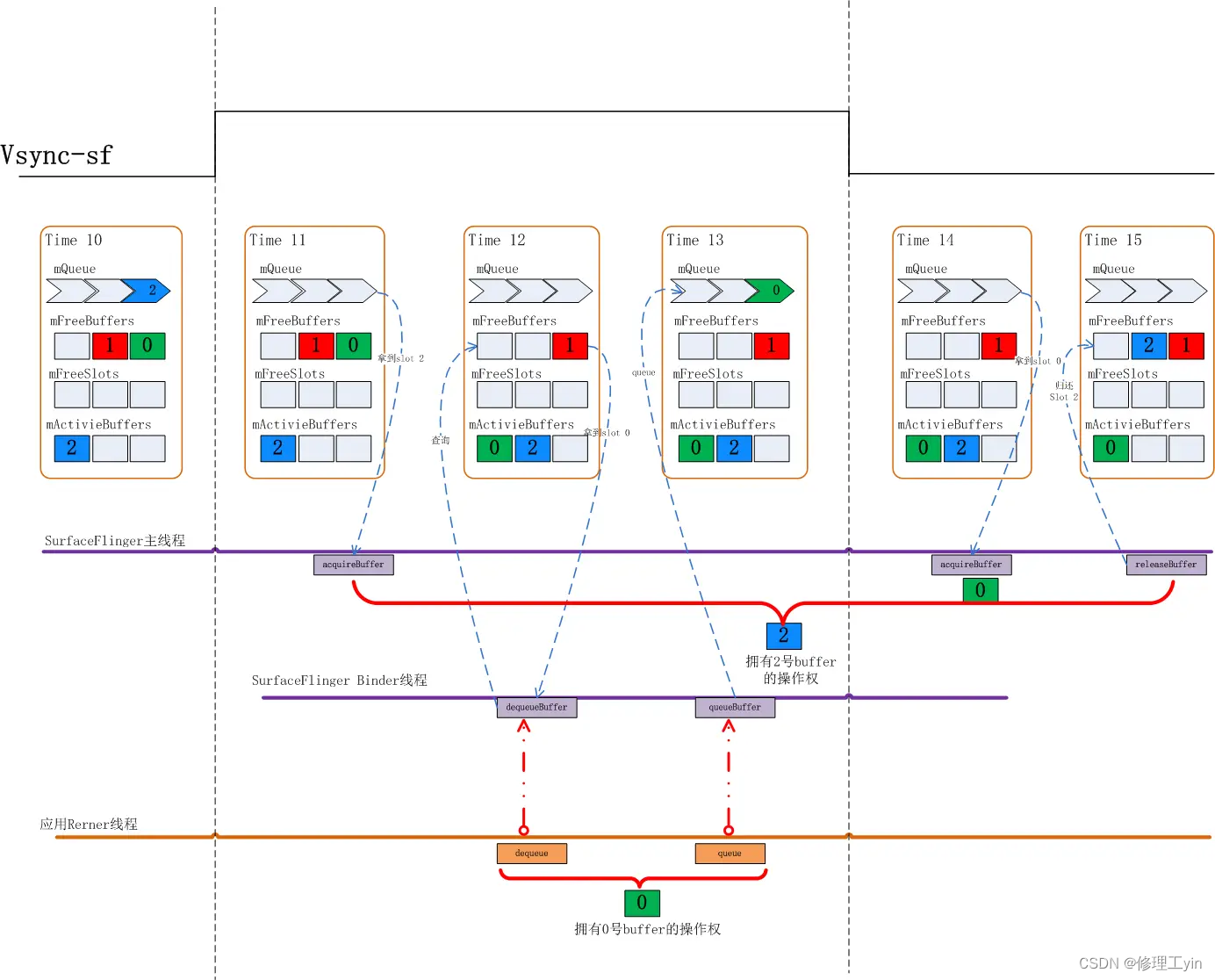
Time11:当下的状态是0,1两个Slot都在mFreeBuffers里,2号Slot在mActiveBuffers里,这时应用来dequeueBuffer
Time12: SurfaceFlinger仍然会先查看mFreeBuffers列表看是否有可用的Slot, 发现0号可用,于是0号Slot状态由FREE切换到DEQUEUED状态,并被放入mActiveBuffers里
Time13:应用对0号Slot的绘图完成后提交上来,这时状态从DEQUEUED切换到QUEUED状态,0号Slot被放入mQueue队列,之后会维持该状态直到下一下Vsync-sf信号到来
Time14:这时Vsync-sf信号到来,SurfaceFlinger主线程中检查mQueue队列中是否有Slot, 发现0号Slot, 于是通过 aquireBuffer操作把0号Slot状态切换到ACQUIRED
这个过程中应用申请buffer时已经有处于FREE状态的Slot是分配过GraphicBuffer的,这种情况多发生在Surface的稳定上帧期。
再来关注一下acquireBuffer和releaseBuffer的过程:
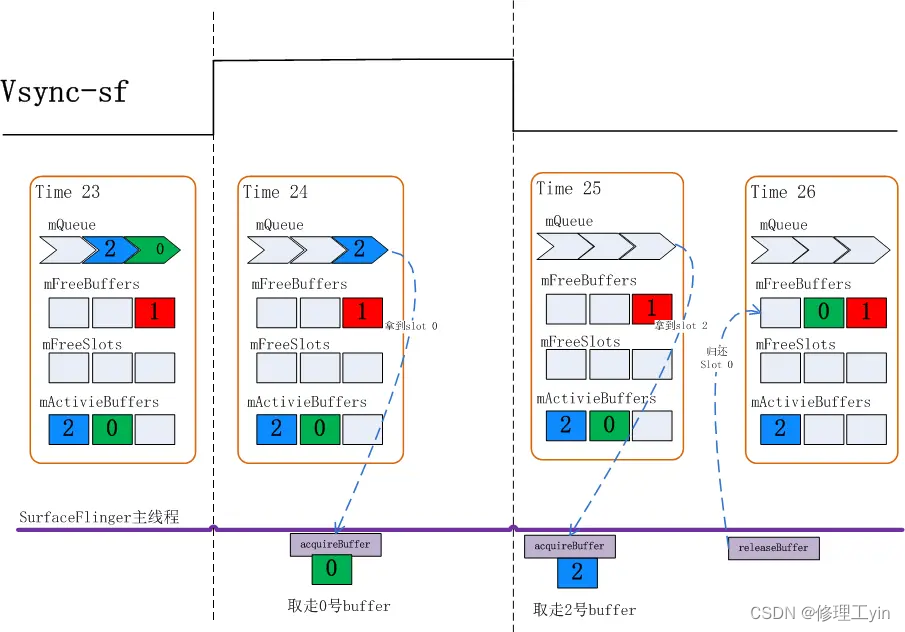
Time 23: 当前状态mQueue里有两个buffer
Time 24:Vsync-sf信号到达,从mQueue队列里取走了0号Slot,
Time 25: 再一次Vsync-sf到来,这时SurfaceFlinger会先查看mQueue队列是否有buffer,发现有2号Slot, 会先取走2号Slot
Time 26: 此时0号Slot已经被HWC Service使用完毕,需要把Slot还回来,0号Slot在此刻进入mFreeBuffers队列。
这里需要注意的是两个时序:
- 每次Vsync-sf信号到来时总是先查看mQueue队列看是否有Layer上帧,然后才会走到releaseBuffer把HWC Service使用的Slot回收回来
- 本次Vsync-sf被aquireBuffer取走的Slot总是会在下一个Vsync-sf时才会被release回来
由上述过程不难看出,如果应用上帧速度较慢,比如其上帧周期时长大于两倍屏幕刷新周期时,每次应用来dequeueBuffer时前一次queueBuffer的BufferSlot都已经被release回来了,这时总会在mFreeBuffers里找到可用的,那么就不需要三个Slot都分配出GraphicBuffer.
在应用上帧过程中所涉及到的BufferSlot我们可以通过systrace来观察:
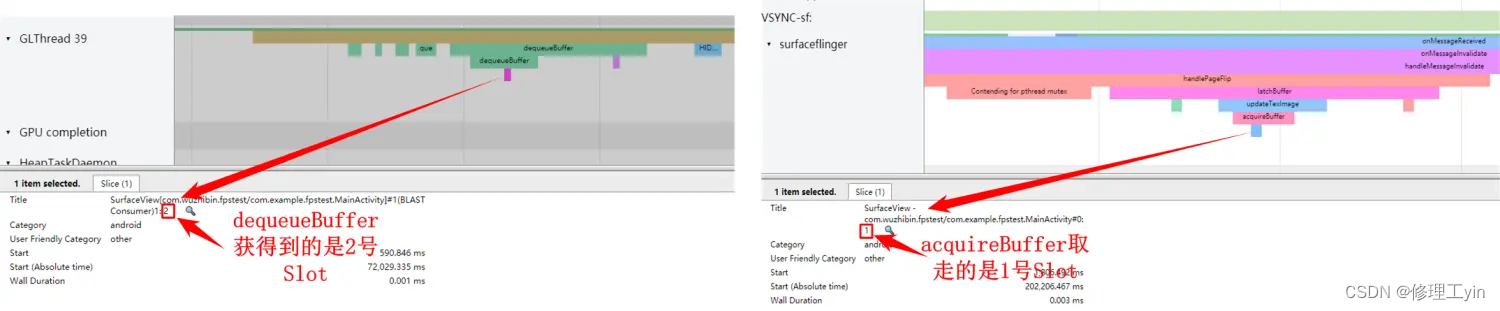
这两个图中显示可以从systrace中看到每次dequeueBuffer和acquireBuffer所操作到的Slot是哪个,当然releaseBuffer也可以在systrace上找到:

从trace里我们还应注意到,releaseBuffer是在postComposition里调用到的,这段代码如下:
frameworks/native/services/surfaceflinger/surfaceflinger.cpp
void SurfaceFlinger::postComposition(){
ATRACE_CALL();
......
for(auto& layer:mLayersWithQueuedFrames){//这里只要主线程执行到这个postComposition函数就一定会让集合中的layer去执行releasePendingBuffer, 而这个releasePendingBuffer里就会调用到releaseBuffer
layer->releasePendingBuffer(dequeueReadyTime);
}
......
}mLayersWithQueuedFrames里的Layer是在这里被加入进来的:
bool SurfaceFlinger::handlePageFlip(){
......
mDrawingState.traverse([&](Layer* layer){
.......
if(layer != nullptr && layer->hasReadyFrame()){//这里是判断这个Layer是否有buffer更新,也就是mLayersWithQueuedFrames里放的是有上帧的layer
......
mLayersWithQueuedFrames.push_back(layer);
......
}
.......
});
......
}在Layer的releasePendingBuffer里会把对应的Slot的状态切到FREE状态,切换到FREE状态后,是很可能被应用dequeueBuffer获取到的,那么怎么能确定buffer已经被HWC Service使用完了呢?如果HWC Service还没有使用完成,而应用申请到了这个buffer,buffer中的数据会出错,怎么解决这个问题呢,这就要靠我们下一章要讨论的Fence来解决。
我们再从帧数据更新的流程上来看下bufferSlot的管理,从systrace(屏幕刷新率为90HZ)上可以观察到的应用上帧的全景图:
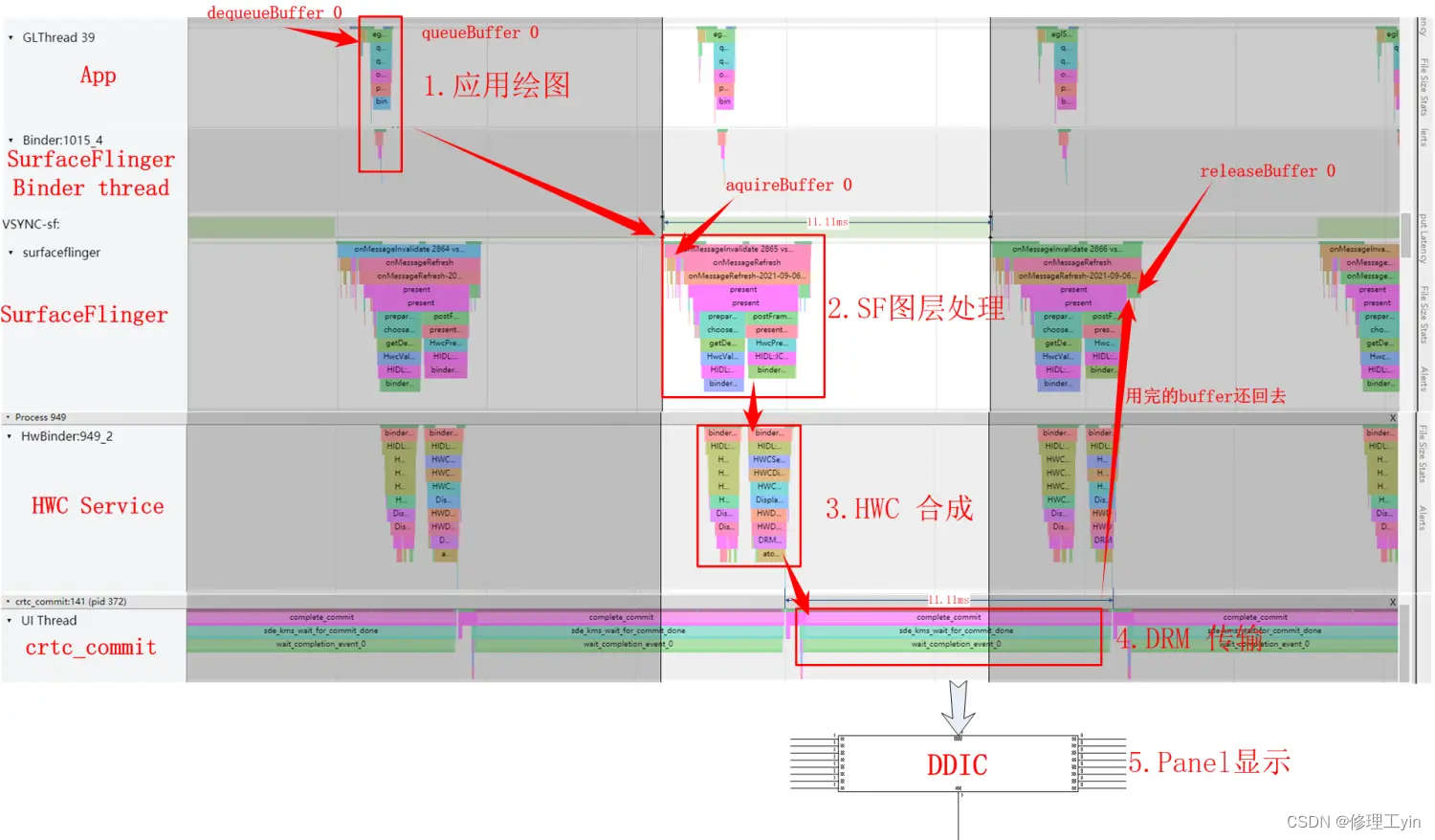
首先应用(这里是以一个SurfaceView上帧为例)通过dequeueBuffer拿到了BufferSlot 0, 开始第1步绘图,绘图完成后通过queueBuffer将Slot 0提交到SurfaceFlinger, 下一个Vsync-sf信号到达后,开始第2步图层处理,这时SurfaceFlinger通过aquireBuffer把Slot 0拿去给到HWC Service,与此同时进入第3步HWC Service开始把多个图层做合成,合成完成后通过libdrm提供的接口通知DRM模块通过DSI传输给DDIC, Panel 通过Disp Scan Gram把图像显示到屏幕。
5.4. 代码接口
以应用为生产者SurfaceFlinger为消费者为例,BufferQueue的Slot管理核心代码如BufferQueueCore、BufferQueueProducer、BufferQueueConsumer组成, 生产者这边还有一个Surface它是应用侧操作BufferQueue的接口:
相关代码路径如下:
Surface.cpp (frameworks\native\libs\gui)
BufferQueueCore.cpp (frameworks\native\libs\gui)
BufferQueueProducer.cpp (frameworks\native\libs\gui)
BufferQueueConsumer.cpp (frameworks\native\libs\gui)
IGraphicBufferProducer.cpp (frameworks\native\libs\gui)
IGraphicBufferConsumer.cpp (frameworks\native\libs\gui)
IConsumerListener.h (frameworks\native\libs\gui\include\gui)由于Android规定,BufferQueue的buffer必须是在Consumer侧来分配,所以BufferQueue的核心Slot管理代码是在SurfaceFlinger进程空间内执行的,它们关系可以用如下图来表示:
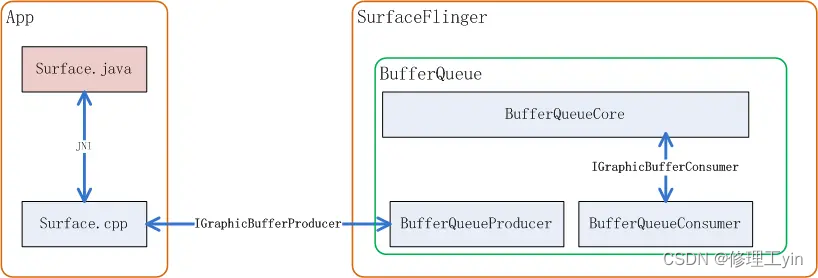
相关代码路径:
IGraphicBufferProducer用来规定了BufferQueue向生产者提供的接口有哪些,比如请求buffer用到的dequeueBuffer, 提交buffer用到的queueBuffer等等:
class IGraphicBufferProducer : public RefBase {
......
virtual status_t connect(const sp<IProducerListener>& listener,
int api, bool producerControlledByApp, QueueBufferOutput* output) = 0;
virtual status_t requestBuffer(int slot, sp<GraphicBuffer>* buf) = 0;
virtual status_t dequeueBuffer(int* slot, sp<Fence>* fence, uint32_t w, uint32_t h,
PixelFormat format, uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) = 0;
virtual status_t queueBuffer(int slot, const QueueBufferInput& input,
QueueBufferOutput* output) = 0;
virtual status_t disconnect(int api, DisconnectMode mode = DisconnectMode::Api) = 0;
......
}connect接口是在开始时上帧前调用一次,主要用来让生产者和消费者沟通一些参数,比如api 版本,buffer的尺寸,个数等; disconnect用于在生产者不再生产断开连接,用以通知消费端清理一些资源。
IGraphicBufferConsumer则规定了消费者和BufferQueueCore的接口有哪些,比如查询从mQueue队列中取出buffer,和还buffer到BufferQueue:
class IGraphicBufferConsumer : public RefBase {
......
virtual status_t acquireBuffer(BufferItem* buffer, nsecs_t presentWhen,
uint64_t maxFrameNumber = 0) = 0;
virtual status_t releaseBuffer(int buf, uint64_t frameNumber, EGLDisplay display,
EGLSyncKHR fence, const sp<Fence>& releaseFence) = 0;
......
}5.5. 本章小结
让我们用一张图来总结说明一下在Triple Buffer下应用连续上帧过程中三个buffer的使用情况,以及在此过程中应用, SurfaceFlinger是如何配合的:
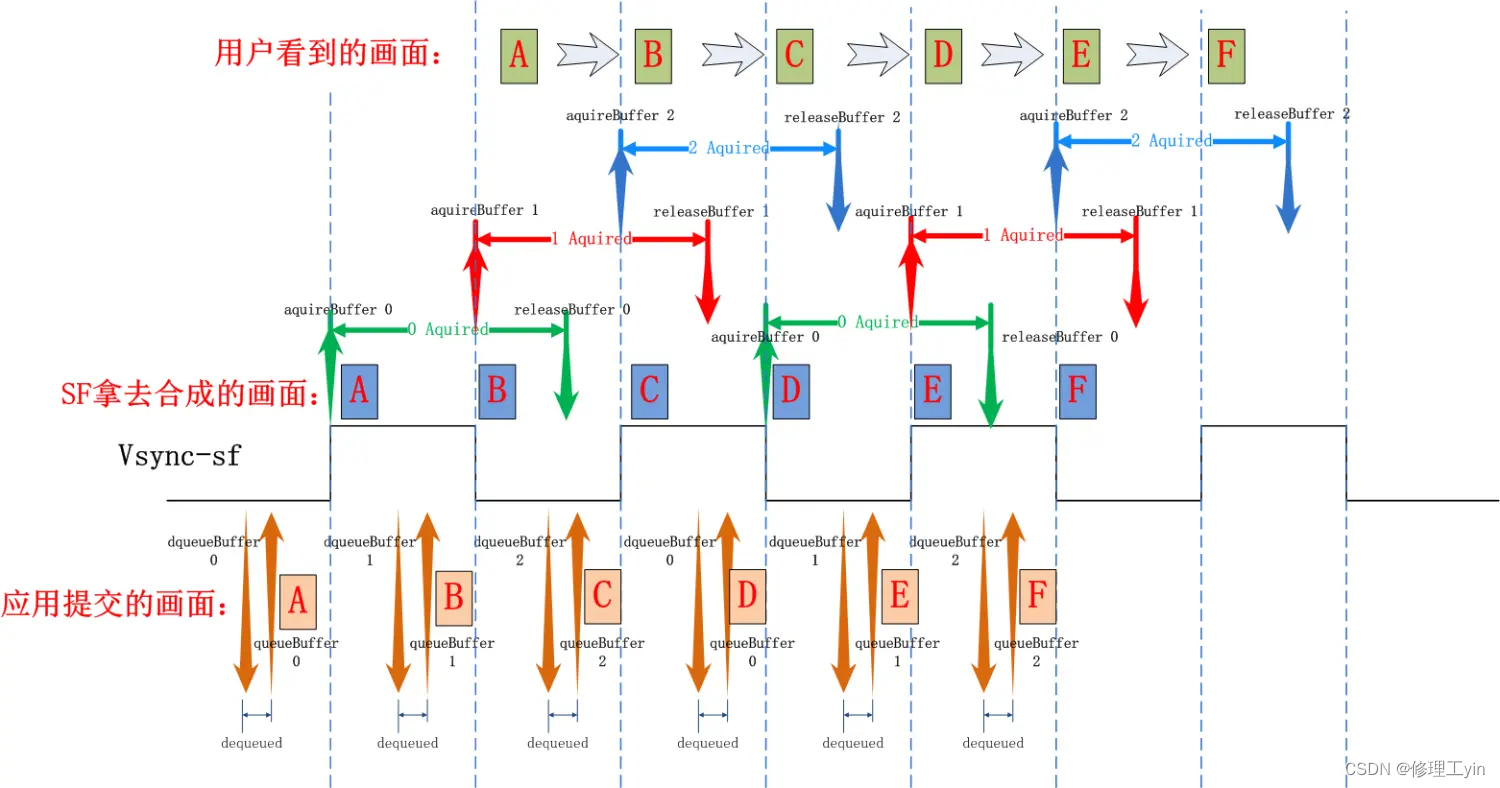
应用在每个Vsync信号到来后都会通过dequeueBuffer/queueBuffer来申请buffer和提交绘图数据,Surfaceflinger都会在下一个vsync信号到来时取走buffer去做合成和显示, 并在下一下个vsync时将buffer还回来,再次循环。
6. Fence
Fence这个英文单词通常代表栅栏,篱笆,围墙,代表了此处是否可以通行。它是内核提供的不同硬件间同步机制,在userspace层我们可以将它视为是一把锁,它代表了某个硬件对共享资源的占用情况。
6.1. 为什么要有Fence
一般凡是共享的资源都要建立一个同步机制来管理,比如在多线程编程中对临界资源的通过加锁实现互斥访问,再比如BufferQueue中Surfaceflinger和应用对共享内存(帧缓冲)的访问中有bufferstate来标识共享内存控制权的方法来做同步。没有同步机制的无序访问极可能造成数据混乱。
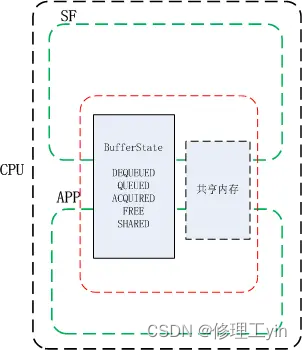
上面图中的BufferState的方式只是解决了在CPU管理之下,当下共享内存的控制权归属问题,但当共享资源是在两个硬件之中时,情况就不同了,比如当一个帧缓冲区共享内存给到GPU时,GPU并不清楚CPU还有没有在使用它,同样地,当GPU在使用共享内存时,CPU也不清楚GPU是否已使用完毕,如下面这个例子:
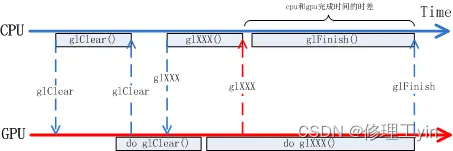
CPU调用OpenGL函数绘图过程的一个简化版流程如上图所示,首先CPU侧调用glClear清空画布,再调用glXXX()来画各种各样的画面,对于CPU来讲在glXXX()执行完毕后,它的绘图工作已经完成了。但其实glXXX()的具体工作是由GPU来完成的,CPU侧的glXXX()只是在向GPU传达任务而已,任务传达完并不意味着任务已经完成了。真正任务做完是在GPU把glXXX()所对应的工作做完才是真正的任务完成了。从CPU下达完任务到GPU完成任务间存在时差,而且这个时差受GPU工作频率影响并不是一个定值。在OpenGL的语境中CPU可以通过glFilish()来等待GPU完成所有工作,但这显然浪费了CPU本可以并行工作的时间,这段时间CPU没有用来做别的事情。
在上面的例子中CPU下达了要在画布上绘画的指令给GPU, 而GPU什么时候画完时间是不确定的,这里的画布就是共享资源,CPU和GPU的工作完全是异步的。Fence提供了一种方式来处理不同硬件对共享资源的访问控制。
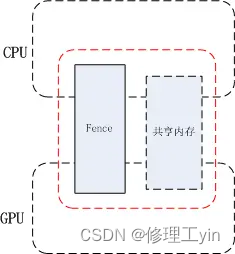
我们可以这样来理解Fence的工作原理: Fence是一个内核driver, 对一个Fence对象有两种操作, signal和wait, 当生产者(App)向GPU下达了很多绘图指令(drawCall)后GPU开始工作,这里CPU就认为绘图工作已经完成了,之后把创建的Fence对象通过binder通知给消费者(SurfaceFlinger),SurfaceFlinger收到通知后,此时SurfaceFlinger并不知道GPU是否已经绘图完毕,即GPU是否已对共享资源访问完毕,消费者先通过Fence对象的wait方法等待,如果GPU绘图完成会调用Fence的signal, 这时消费者就会从Fence对象的wait方法中跳出。即wait方法结束时就是GPU工作完成时。这个signal由kernel driver来完成。有了Fence的情况下,CPU在完成自已的工作后就可以继续做别的事情,到了真正要使用共享资源时再通过Fence wait来和GPU同步,尽最大可能做到了让不同硬件并行工作。
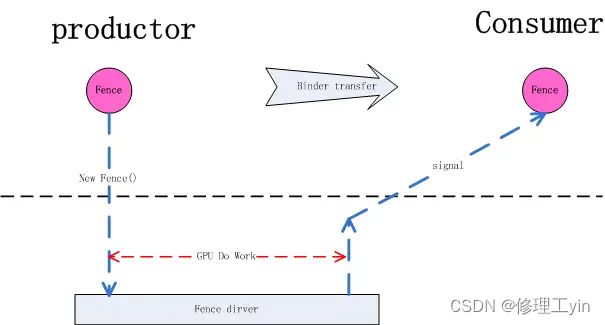
6.2. 与BufferQueue协作方式
我们以App(productor)和SurfaceFlinger(Consumer)间的交互来看下Fence在其中的作用:
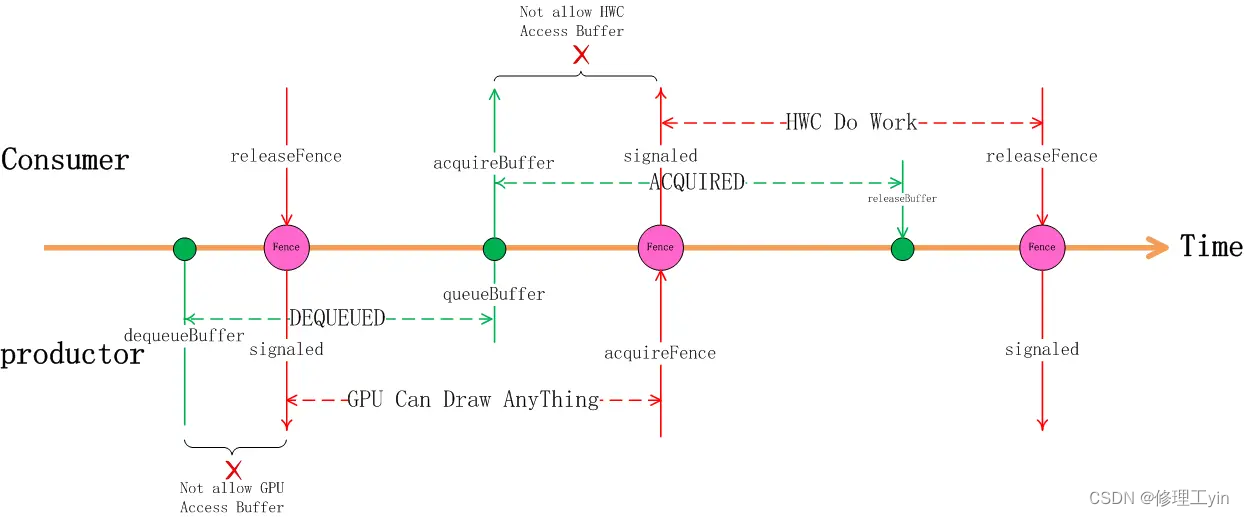
首先App通过dequeueBuffer获得某一Slot的使用权,这时Slot的状态切换到DEQUEUED状态,随着dequeueBuffer函数返回的还有一个releaseFence对象,这时因为releaseFence还没有signaled, 这意味着虽然在CPU这边已经拿到了buffer的使用权,但别的硬件还在使用这个buffer, 这时的GPU还不能直接在上面绘画,它要等releaseFence signaled后才能绘画。 接下来我们先假设GPU的工作花费的时间较长,在它完成之前CPU侧APP已经完成了queueBuffer动作,这时Slot的状态已切换为QUEUED状态,或者vsync已经到来状态变为ACQUIRED状态, 这在CPU侧代表该buffer给HWC去合成了,但这时HWC的硬件MDP还不能去读里面的数据,它还需要等待acauireFence的signaled信号,只有等到了acquireFence的signaled信号才代表GPU的绘画工作真正做完了,GPU已经完成了对帧缓冲区的访问,这时HWC 的硬件才能去读帧缓冲区的数据,完成图层合成的工作。
同样地,当SurfaceFlinger执行到releaseBuffer时,并不能代表HWC 已经完全完成合成工作了,很有可能它还在读取缓冲区的内容做合成, 但不妨碍releaseBuffer的流程执行,虽然HWC还在使用缓冲区做合成,但帧缓冲区的Slot有可能被应用申请走变成DEQUEUED状态,虽然Slot是DEQUEUED状态这时GPU并不能直接存取它,它要等代表着HWC使用完毕的releaseFence的signaled信号。
应用侧申请buffer的同时会获取到一个fence对象(releaseFence):
frameworks/native/libs/gui/Surface.cpp
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
ATRACE_CALL();
.....
sp<Fence> fence;
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps ? &frameTimestamps
: nullptr);
.....
}对应SurfaceFlinger侧:
frameworks/native/libs/gui/BufferQueueProducer.cpp
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
ATRACE_CALL();
.......
*outFence = (mCore->mSharedBufferMode &&
mCore->mSharedBufferSlot == found) ?
Fence::NO_FENCE : mSlots[found].mFence;//把Slot里记录的mFence对象返回出去,就是应用侧拿到的releaseFence
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;//不妨思考下这里为什么可以清成NO_FENCE?
.......
}应用侧上帧时要创建一个fence来代表GPU的功能还在进行中,提交buffer的同时把fence对象传给SurfaceFlinger:
frameworks/native/libs/gui/Surface.cpp
int Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd) {
ATRACE_CALL();
......
sp<Fence> fence(fenceFd >= 0 ? new Fence(fenceFd) : Fence::NO_FENCE);//创建一个fence, 这个就是SurfaceFlinger侧的acquireFence
......
IGraphicBufferProducer::QueueBufferInput input(timestamp, isAutoTimestamp,//将fence放入input参数
static_cast<android_dataspace>(mDataSpace), crop, mScalingMode,
mTransform ^ mStickyTransform, fence, mStickyTransform,
mEnableFrameTimestamps);
......
status_t err = mGraphicBufferProducer->queueBuffer(i, input, &output);//把这个fence传给surfaceflinger
......
}对应的SurfaceFlinger侧从binder里获取到应用侧传来的fence对象(这个称为acquireFence):
frameworks/native/libs/gui/BufferQueueProducer.cpp
status_t BufferQueueProducer::queueBuffer(int slot,
const QueueBufferInput &input, QueueBufferOutput *output) {
ATRACE_CALL();
......
sp<Fence> acquireFence;
......
input.deflate(&requestedPresentTimestamp, &isAutoTimestamp, &dataSpace,
&crop, &scalingMode, &transform, &acquireFence, &stickyTransform,
&getFrameTimestamps);
......
mSlots[slot].mFence = acquireFence;//queueBuffer完成时Slot的mFence放的是acquireFence
......
}我们来通过systrace观察一个因GPU工作时间太长,从而让DRM工作线程卡在等Fence的情况:
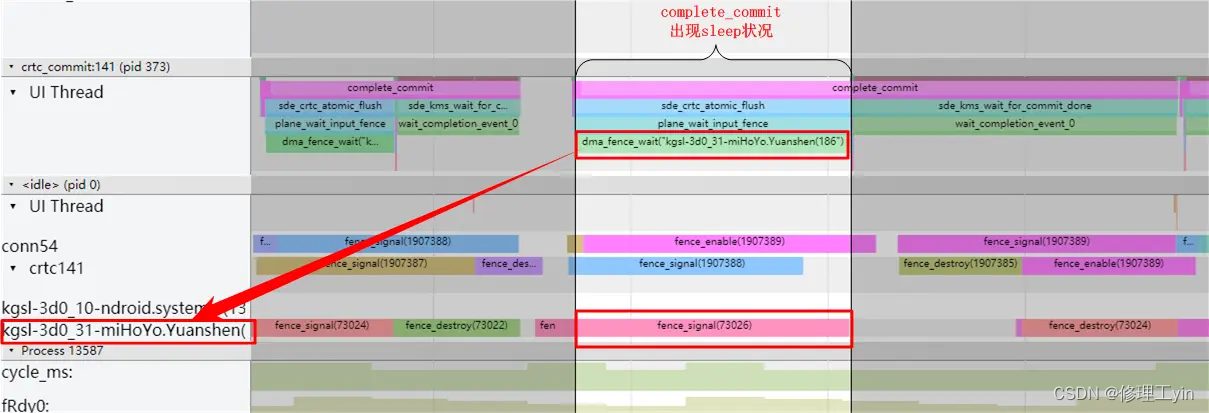
如上图所示,complete_commit函数(从上面4.3章我们了解过这个函数是执行SOC准备传输数据到DDIC的过程)执行时前面有一段时间是陷于等待状态了,那么它在等谁呢,从图中所示我们可以看出它在等下73026号fence的signal信号。这种情况说明drm内部的dma要去读这miHoYo.yuanshen这个应用的buffer时发现应用的GPU还没有把画面画完,它不得不等待它画完才能开始读取,但既然都已经送到crtc_commit了,至少在CPU这侧,该Slot的BufferState已经是ACQUIRED状态。
6.3 本章小结
在本章节中我们了解了不同硬件间同步工作的一种方法,了解了Fence在App画面更新过程中的使用情况。
7. 画面更新流程
在我们前面几个章节的讨论中,我们从最底层的显示硬件,SOC和DDIC的接口, linux和Userspace的图形接口以及APP与SurfaceFlinger,HWC service三者的关系,了解了帧数据流动所经过的关键节点,并重点讨论了帧buffer是如何管理的,以及在流动过程中是如何做到同步的。接下来我们将从应用侧角度来从上到下看一下应用所绘制的画面是如何使用到我们上面所设计的流程中的。
7.1. 画布的申请
从前文5.4的讨论可知,应用侧对图层的操作是以Surface为接口的,其定义如下所示,它包含了一些更新画面相关的核心api, 比如dequeueBuffer/queueBuffer/connect/disconnect等等。
Surface.h (frameworks\native\libs\gui\include\gui)
class Surface
: public ANativeObjectBase<ANativeWindow, Surface, RefBase>
{
......
protected:
virtual int dequeueBuffer(ANativeWindowBuffer** buffer, int* fenceFd);
virtual int cancelBuffer(ANativeWindowBuffer* buffer, int fenceFd);
virtual int queueBuffer(ANativeWindowBuffer* buffer, int fenceFd);
virtual int perform(int operation, va_list args);
......
virtual int connect(int api);
......
public:
virtual int disconnect(int api,
IGraphicBufferProducer::DisconnectMode mode =
IGraphicBufferProducer::DisconnectMode::Api);
}那么应用要想画出它的画面,第一个要解决的问题就是应用侧的Surface对象是如何创建? 它又是如何与SurfaceFlinger建立联系的?下面我们将从代码逻辑中找寻到它的建立过程。
在Android系统中每个Activity都有一个独立的画布(在应用侧称为Surface,在SurfaceFlinger侧称为Layer), 无论这个Activity安排了多么复杂的view结构,它们最终都是被画在了所属Activity的这块画布上,当然也有一个例外,SurfaceView是有自已独立的画布的,但此处我们先只讨论Activity画布的建立过程。
首先每个应用都会创建有自已的Activity, 进而Android会为Activity创建一个ViewRootImpl, 并调用到它的performTraversals这个函数(篇幅所限这部分流程请读者自行阅读源码)。
该函数里会调用到relayoutWindow函数:
frameworks/base/core/java/android/view/ViewRootImpl.java
private void performTraversals() {
......
relayoutResult = relayoutWindow(params, viewVisibility, insetsPending);
......
}relayoutWindow函数里会调用到WindowSession的relayout函数,这个函数是一个跨进程调用,mWindowSession可以看作是WMS在应用侧的代表:
frameworks/base/core/java/android/view/ViewRootImpl.java
private int relayoutWindow(WindowManager.LayoutParams params, int viewVisibility,
boolean insetsPending) throws RemoteException {
......
int relayoutResult = mWindowSession.relayout(mWindow, mSeq, params,
(int) (mView.getMeasuredWidth() * appScale + 0.5f),
(int) (mView.getMeasuredHeight() * appScale + 0.5f), viewVisibility,
insetsPending ? WindowManagerGlobal.RELAYOUT_INSETS_PENDING : 0, frameNumber,
mTmpFrame, mTmpRect, mTmpRect, mTmpRect, mPendingBackDropFrame,
mPendingDisplayCutout, mPendingMergedConfiguration, mSurfaceControl, mTempInsets,
mTempControls, mSurfaceSize, mBlastSurfaceControl);
......
}随着代码的执行让我们把视角切换到system_server进程(WMS的relayoutWindow函数),这里会调用createSurfaceControl去创建一个SurfaceControl:
frameworks/base/services/core/java/com/android/server/wm/WindowManagerService.java
public int relayoutWindow(Session session, IWindow client, int seq, LayoutParams attrs,
int requestedWidth, int requestedHeight, int viewVisibility, int flags,
long frameNumber, Rect outFrame, Rect outContentInsets,
Rect outVisibleInsets, Rect outStableInsets, Rect outBackdropFrame,
DisplayCutout.ParcelableWrapper outCutout, MergedConfiguration mergedConfiguration,
SurfaceControl outSurfaceControl, InsetsState outInsetsState,
InsetsSourceControl[] outActiveControls, Point outSurfaceSize,
SurfaceControl outBLASTSurfaceControl) {
......
try {
result = createSurfaceControl(outSurfaceControl, outBLASTSurfaceControl,
result, win, winAnimator);
} catch (Exception e) {
......
}SurfaceControl的创建过程,注意这里创建工作是调用winAnimator来完成的,注意下面那句surfaceController.getSurfaceControl会把创建出来的SurfaceControl通过形参outSurfaceControl传出去:
frameworks/base/services/core/java/com/android/server/wm/WindowManagerService.java
private int createSurfaceControl(SurfaceControl outSurfaceControl,
SurfaceControl outBLASTSurfaceControl, int result,
WindowState win, WindowStateAnimator winAnimator) {
......
WindowSurfaceController surfaceController;
try {
Trace.traceBegin(TRACE_TAG_WINDOW_MANAGER, "createSurfaceControl");
surfaceController = winAnimator.createSurfaceLocked(win.mAttrs.type, win.mOwnerUid);
} finally {
Trace.traceEnd(TRACE_TAG_WINDOW_MANAGER);
}
if (surfaceController != null) {
surfaceController.getSurfaceControl(outSurfaceControl);
......
}
......
}我们先看下创建过程,创建了一个WindowSurfaceController,进而再创建SurfaceControll:
frameworks/base/services/core/java/com/android/server/wm/WindowStateAnimator.java
WindowSurfaceController createSurfaceLocked(int windowType, int ownerUid) {
......
/*WindowSurfaceController mSurfaceController;*/
mSurfaceController = new WindowSurfaceController(attrs.getTitle().toString(), width,
height, format, flags, this, windowType, ownerUid);
......
}WindowSurfaceController.java (frameworks\base\services\core\java\com\android\server\wm)
WindowSurfaceController(String name, int w, int h, int format,
int flags, WindowStateAnimator animator, int windowType, int ownerUid) {
......
final SurfaceControl.Builder b = win.makeSurface()
.setParent(win.getSurfaceControl())
.setName(name)
.setBufferSize(w, h)
.setFormat(format)
.setFlags(flags)
.setMetadata(METADATA_WINDOW_TYPE, windowType)
.setMetadata(METADATA_OWNER_UID, ownerUid)
.setCallsite("WindowSurfaceController");
......
}SurfaceControl.java (frameworks\base\core\java\android\view)
public static final @android.annotation.NonNull Creator<SurfaceControl> CREATOR
= new Creator<SurfaceControl>() {
public SurfaceControl createFromParcel(Parcel in) {
return new SurfaceControl(in);
}
public SurfaceControl[] newArray(int size) {
return new SurfaceControl[size];
}
};private SurfaceControl(SurfaceSession session, String name, int w, int h, int format, int flags,
SurfaceControl parent, SparseIntArray metadata, WeakReference<View> localOwnerView,
String callsite){
......
mNativeObject = nativeCreate(session, name, w, h, format, flags,
parent != null ? parent.mNativeObject : 0, metaParcel);
......
}
到这里我们看到会通过JNI去创建C层的对象:
android_view_SurfaceControl.cpp (frameworks\base\core\jni)
static jlong nativeCreate(JNIEnv* env, jclass clazz, jobject sessionObj,
jstring nameStr, jint w, jint h, jint format, jint flags, jlong parentObject,
jobject metadataParcel) {
ScopedUtfChars name(env, nameStr);//Surface名字, 在SurfaceFlinger侧就是Layer的名字
......
sp<SurfaceComposerClient> client;
......
status_t err = client->createSurfaceChecked(
String8(name.c_str()), w, h, format, &surface, flags, parent, std::move(metadata));
......
}C层的Surface在创建时去调用SurfaceComposerClient的createSurface去创建, 这个SurfaceComposerClient可以看作是SurfaceFlinger在Client端的代表
android_view_SurfaceControl.cpp (frameworks\base\core\jni)
status_t SurfaceComposerClient::createSurfaceChecked(const String8& name, uint32_t w, uint32_t h,
PixelFormat format,
sp<SurfaceControl>* outSurface, uint32_t flags,
SurfaceControl* parent, LayerMetadata metadata,
uint32_t* outTransformHint) {
......
err = mClient->createSurface(name, w, h, format, flags, parentHandle, std::move(metadata),
&handle, &gbp, &transformHint);
......
}SurfaceComposerClient.cpp (frameworks\native\libs\gui)
sp<SurfaceControl> SurfaceComposerClient::createSurface(const String8& name, uint32_t w, uint32_t h,
PixelFormat format, uint32_t flags,
SurfaceControl* parent,
LayerMetadata metadata,
uint32_t* outTransformHint) {
sp<SurfaceControl> s;
createSurfaceChecked(name, w, h, format, &s, flags, parent, std::move(metadata),
outTransformHint);
return s;
}
status_t SurfaceComposerClient::createSurfaceChecked(const String8& name, uint32_t w, uint32_t h,
PixelFormat format,
sp<SurfaceControl>* outSurface, uint32_t flags,
SurfaceControl* parent, LayerMetadata metadata,
uint32_t* outTransformHint) {
.......
err = mClient->createSurface(name, w, h, format, flags, parentHandle, std::move(metadata),
&handle, &gbp, &transformHint);
.......
}
跨进程呼叫SurfaceFlinger:
ISurfaceComposerClient.cpp (frameworks\native\libs\gui)
status_t createSurface(const String8& name, uint32_t width, uint32_t height, PixelFormat format,
uint32_t flags, const sp<IBinder>& parent, LayerMetadata metadata,
sp<IBinder>* handle, sp<IGraphicBufferProducer>* gbp,
uint32_t* outTransformHint) override {
return callRemote<decltype(&ISurfaceComposerClient::createSurface)>(Tag::CREATE_SURFACE,
name, width, height,
format, flags, parent,
std::move(metadata),
handle, gbp,
outTransformHint);
}然后流程就来到了SurfaceFlinger进程,由于SurfaceFlinger支持很多不同类型的Layer, 这里我们只以BufferQueueLayer为例, 当SurfaceFlinger收到这个远程调用后会new 一个BufferQueueLayer出来。
SurfaceFlinger.cpp (frameworks\native\services\surfaceflinger)
status_t SurfaceFlinger::createLayer(const String8& name, const sp<Client>& client, uint32_t w,
uint32_t h, PixelFormat format, uint32_t flags,
LayerMetadata metadata, sp<IBinder>* handle,
sp<IGraphicBufferProducer>* gbp,
const sp<IBinder>& parentHandle, const sp<Layer>& parentLayer,
uint32_t* outTransformHint) {
......
case ISurfaceComposerClient::eFXSurfaceBufferQueue:
result = createBufferQueueLayer(client, std::move(uniqueName), w, h, flags,
std::move(metadata), format, handle, gbp, &layer);
......
}至此完成了从一个应用的Activity创建到SurfaceFlinger内部为它创建了一个Layer来对应。那么应用侧又是如何拿到这个Layer的操作接口呢?
续续看代码:
注意到WMS的createSurfaceControl方法中是通过getSurfaceControl将SurfaceControll传出来的:
frameworks/base/services/core/java/com/android/server/wm/WindowSurfaceController.java
void getSurfaceControl(SurfaceControl outSurfaceControl) {
outSurfaceControl.copyFrom(mSurfaceControl, "WindowSurfaceController.getSurfaceControl");
}这个对象会通过WindowSession跨进程传到应用进程里,进而创建出Surface:
frameworks/base/core/java/android/view/ViewRootImpl.java
private int relayoutWindow(WindowManager.LayoutParams params, int viewVisibility,
boolean insetsPending) throws RemoteException {
......
int relayoutResult = mWindowSession.relayout(mWindow, mSeq, params,
(int) (mView.getMeasuredWidth() * appScale + 0.5f),
(int) (mView.getMeasuredHeight() * appScale + 0.5f), viewVisibility,
insetsPending ? WindowManagerGlobal.RELAYOUT_INSETS_PENDING : 0, frameNumber,
mTmpFrame, mTmpRect, mTmpRect, mTmpRect, mPendingBackDropFrame,
mPendingDisplayCutout, mPendingMergedConfiguration, mSurfaceControl, mTempInsets, //这里的mSurfaceControl是从WMS传来的
mTempControls, mSurfaceSize, mBlastSurfaceControl);
......
if (mSurfaceControl.isValid()) {
if (!useBLAST()) {
mSurface.copyFrom(mSurfaceControl);//通过Surface的copyFrom方法从SurfaceControl来创建这个Surface
}
......
}那么拿到Surface对象后怎么就能拿到帧缓冲区的操作接口呢?我们来看Surface的实现:
Surface.java (frameworks\base\core\java\android\view)
public class Surface implements Parcelable {
......
private static native long nativeLockCanvas(long nativeObject, Canvas canvas, Rect dirty)
throws OutOfResourcesException;
private static native void nativeUnlockCanvasAndPost(long nativeObject, Canvas canvas);
......
}这里这个java层的Surface实现有两个方法,一个是nativeLockCanvas一个是nativeUnlockCanvasAndPost, 它其实对应了我们在章节5.4中所述的dequeueBuffer和queueBuffer, 我们继续从代码上看下它的实现过程:
android_view_Surface.cpp (frameworks\base\core\jni)
static jlong nativeLockCanvas(JNIEnv* env, jclass clazz,
jlong nativeObject, jobject canvasObj, jobject dirtyRectObj) {
......
status_t err = surface->lock(&buffer, dirtyRectPtr);
......
}Surface.cpp (frameworks\native\libs\gui)
status_t Surface::lock(
ANativeWindow_Buffer* outBuffer, ARect* inOutDirtyBounds){
......
status_t err = dequeueBuffer(&out, &fenceFd);
......
}
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
ATRACE_CALL();
......
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps ? &frameTimestamps
: nullptr);
......
}到这里我们看到java层Surface的lock方法最终它有去调用到GraphicBufferProducer的dequeueBuffer函数,在第5章中我们有详细了解过dequeueBuffer在获取一个Slot后,如果Slot没有分配GraphicBuffer会在这时给它分配GraphicBuffer, 然后会返回一个带有BUFFER_NEEDS_REALLOCATION标记的flag, 应用侧看到这个flag后会通过requestBuffer和importBuffer接口把GraphicBuffer映射到自已的进程空间。
到此应用拿到了它绘制界面所需的“画布”。
由于上面的代码过程看起来比较繁琐,我们用一张图来概述一下这个流程:
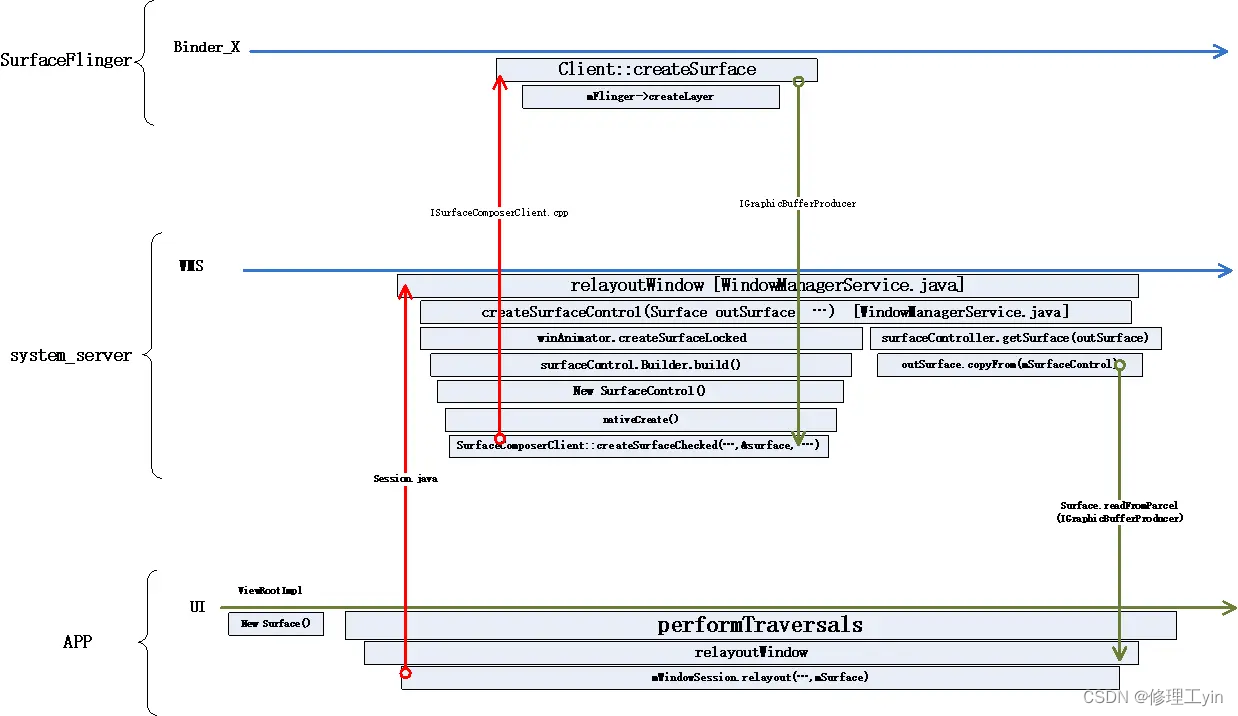
首先在这个过程中涉及到三个进程,APP,system_server, surfaceflinger, 先从应用调用performTraversals中调用relayoutWindow这个函数开始,它跨进程调用到了system_server进程中的WMS模块,这个模块的relayoutWindow又经一系列过程创建一个SurfaceContorl, 在SurfaceControl创建过程中会跨进程调用SurfaceFlinger让它创建一个Layer出来。 之后SurfaceControll对象会跨进程通过参数回传给应用,应用根据SurfaceControl创建出应用侧的Surface对象,而Surface对象通过一些api封装向上层提供拿画布(dequeueBuffer)和提交画布(queueBuffer)的操作接口。这样应用完成了对画布的申请操作。
7.2. 帧数据的绘制过程
上一节我们知道了应用是如何拿到“画布”的,接下来我们来看下应用是如何在绘画完一帧后来提交数据的:
上节中应用的主线程在performTraversals函数中获取到了操作帧缓冲区的Surface对象,这个Surface对象会通过RenderProxy传递给RenderThread, 一些关健代码如下:
performTraversals里初始化RenderThread时会把Surface对象传过去:
private void performTraversals() {
......
if (mAttachInfo.mThreadedRenderer != null) {
try {
hwInitialized = mAttachInfo.mThreadedRenderer.initialize(mSurface);
........
}
......
}在ThreadedRenderer的初始化中调用了setSurface,这个setSurface函数会通过JNI调到native层:
ThreadedRenderer.java (frameworks\base\core\java\android\view)
boolean initialize(Surface surface) throws OutOfResourcesException {
......
setSurface(surface);
......
}android_graphics_HardwareRenderer.cpp (frameworks\base\libs\hwui\jni)
static void android_view_ThreadedRenderer_setSurface(JNIEnv* env, jobject clazz,
jlong proxyPtr, jobject jsurface, jboolean discardBuffer) {
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
......
proxy->setSurface(window, enableTimeout);
......
}最终可以看到setSurface是通过RenderProxy这个对象向RenderThread的消息队列中post了一个消息,在这个消息的处理中会调用Context的setSurface, 这里的mContext是CanvasContext.
RenderProxy.cpp (frameworks\base\libs\hwui\renderthread)
void RenderProxy::setSurface(ANativeWindow* window, bool enableTimeout) {
ANativeWindow_acquire(window);
mRenderThread.queue().post([this, win = window, enableTimeout]() mutable {
mContext->setSurface(win, enableTimeout);
ANativeWindow_release(win);
});
}CanvasContext的setSurface会进一步调用到Surface对象的connect方法(5.4节)和SurfaceFlinger侧协商同步一些参数。
上述过程如下图所示
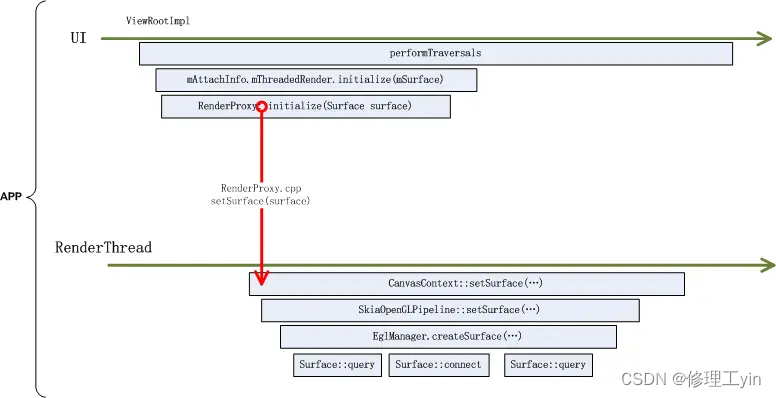
这其中一些关键过程可以在systrace中看到,如下图所示:

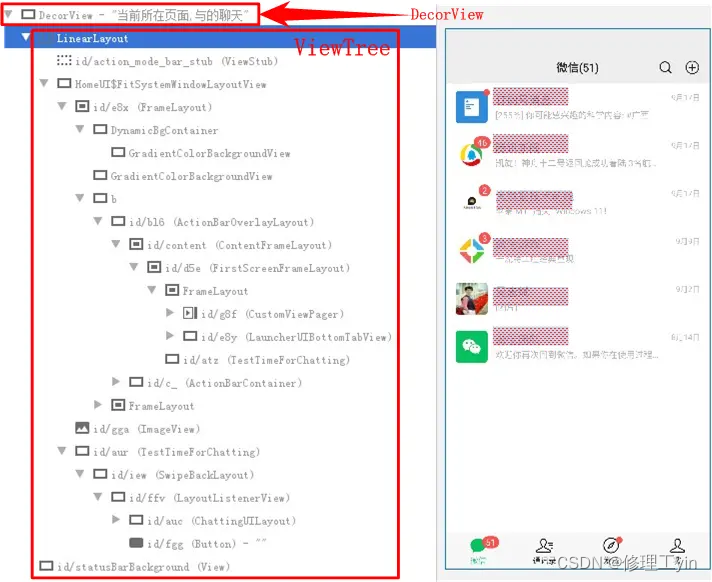
接下来应用主线程收到vsync信号后会开始绘图流程,应用主线程会遍历ViewTree对所有的View完成measure, layout, draw的工作,我们知道Android的应用界面是由很多View按树状结构组织起来的,如下图以微信主界面为例,但无论界面多么复杂它都有一个根View叫DecorView, 而纷繁复杂的界面最终都是由一个个View通过树形结构组织起来的。
限于篇幅我们这里不讨论UI线程的measure和layout部分,这里只来看下draw部分:
首先App每次开始绘画都是收到一个vsync信号才会开始绘图(这里暂不讨论SurfaceView自主上帧的情况),应用是通过Choreographer来感知vsync信号, 在ViewRootImpl里向Choreographer注册一个callback, 每当有vsync信号来时会执行mTraversalRunnable:
ViewRootImpl.java (frameworks\base\core\java\android\view)
void scheduleTraversals() {
if (!mTraversalScheduled) {
......
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);//注册vsync的回调
......
}
}
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();//每次vsync到时调用该函数
}
}而doTraversal()主要是调用performTraversals()这个函数,performTraversals里会调用到draw()函数:
private boolean draw(boolean fullRedrawNeeded) {
......
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
......
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this);//这里传下去的mView就是DecorView
......
}
......
}上面的draw()函数进一步调用了ThreadedRenderer的draw:
ThreadedRenderer.java (frameworks\base\core\java\android\view)
void draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks) {
......
updateRootDisplayList(view, callbacks);
......
}
private void updateRootDisplayList(View view, DrawCallbacks callbacks) {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Record View#draw()");//这里有个trace,我们可以在systrace中观察到它
......
updateViewTreeDisplayList(view);
......
}
private void updateViewTreeDisplayList(View view) {
......
view.updateDisplayListIfDirty();//这里开始调用DecorView的updateDisplayListIfDirty
......
}
接下来代码调用到DecorView的基类View.java:
View.java (frameworks\base\core\java\android\view)
public RenderNode updateDisplayListIfDirty() {
......
final RecordingCanvas canvas = renderNode.beginRecording(width, height);//这里开始displaylist的record
......
draw(canvas);
......
}上面的RecordingCanvas就是扮演一个绘图指令的记录员角色,它会将这个View通过draw函数绘制的指令以displaylist形式记录下来,那么上面的renderNode又个什么东西呢?
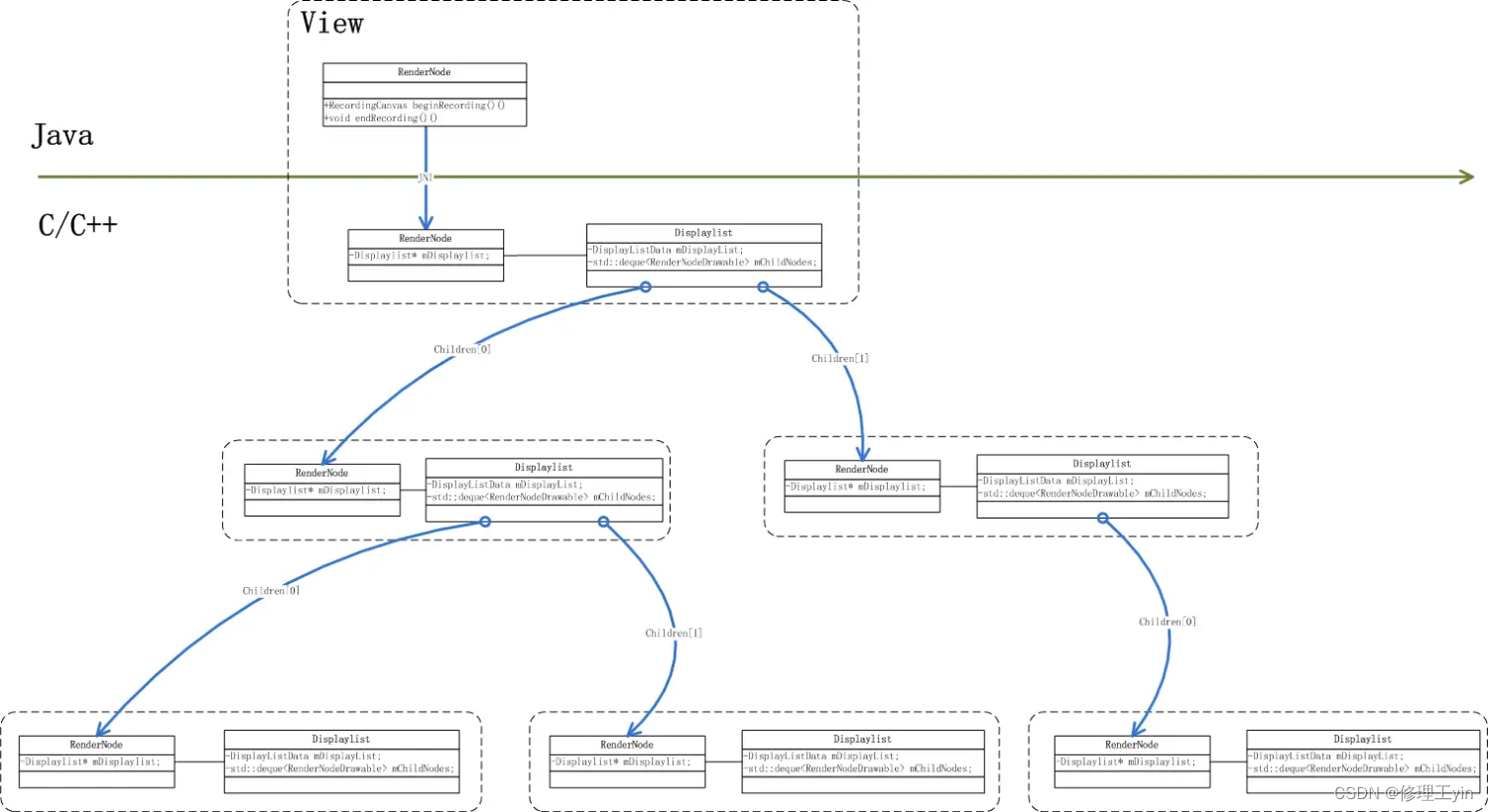
熟悉Web的同学一定会对DOM Tree和Render Tree不陌生,Android里的View和RenderNode是类似的概念,View代表的是实体在空间结构上的存在,而RenderNode代表它在界面呈现上的存在。这样的设计可以让存在和呈现进行分离,便于实现同一存在不同状态下呈现也不同。
在Android的设计里View会对应一个RenderNode, RenderNode里的一个重要数据结构是DisplayList, 每个DisplayList都会包含一系列DisplayListData. 这些DisplayList也会同样以树形结构组织在一起。
当UI线程完成它的绘制工作后,它工作的产物是一堆DisplayListData, 我们可以将其理解为是一堆绘图指令的集合,每一个DisplayListData都是在描绘这个View长什么样子,所以一个View树也可能理解为它的样子由对应的DisplayListData构成的树来描述:
我们再来看下DisplayListData是长什么样子,它定义在下面这个文件中:
RecordingCanvas.h (frameworks\base\libs\hwui)
class DisplayListData final {
......
void drawPath(const SkPath&, const SkPaint&);
void drawRect(const SkRect&, const SkPaint&);
void drawRegion(const SkRegion&, const SkPaint&);
void drawOval(const SkRect&, const SkPaint&);
void drawArc(const SkRect&, SkScalar, SkScalar, bool, const SkPaint&);
......
template <typename T, typename... Args>
void* push(size_t, Args&&...);
......
SkAutoTMalloc<uint8_t> fBytes;
......
}它的组成大体可以看成三个部分,第一部分是一堆以draw打头的函数,它们是最基本的绘图指令,比如画一条线, 画一个矩形,画一段圆弧等等,上面我们摘取了其中几个,后面我们将以drawRect为例来看它是如何工作的; 第二部分是一个push模版函数,后面我们会看到它的作用; 第三个是一块存储区fBytes,它会根据需要放大存储区的大小。
我们来看下drawRect的实现:
RecordingCanvas.cpp (frameworks\base\libs\hwui)
void DisplayListData::drawRect(const SkRect& rect, const SkPaint& paint) {
this->push<DrawRect>(0, rect, paint);
}我们发现它只是push了画 一个Rect相关的参数,那么这个DrawRect又是什么呢?
struct Op {
uint32_t type : 8;
uint32_t skip : 24;
};struct DrawRect final : Op {
static const auto kType = Type::DrawRect;
DrawRect(const SkRect& rect, const SkPaint& paint) : rect(rect), paint(paint) {}
SkRect rect;
SkPaint paint;
void draw(SkCanvas* c, const SkMatrix&) const { c->drawRect(rect, paint); }
};通过上面代码我们不难发现,DrawRect代表的是一段内存布局,这段内存第一个字节存储了它是哪种类型,后面的部分存储有画这个Rect所需要的参数信息,再来看push方法的实现:
template <typename T, typename... Args>
void* DisplayListData::push(size_t pod, Args&&... args) {
......
auto op = (T*)(fBytes.get() + fUsed);
fUsed += skip;
new (op) T{std::forward<Args>(args)...};
op->type = (uint32_t)T::kType;//注意这里将DrawRect的类型编码Type::DrawRect存进了第一个字节
op->skip = skip;
return op + 1;
}这里push方法就是在fBytes后面放入这个DrawRect的内存布局,也就是执行DisplayListData::drawRect方法时就是把画这个Rect的方法和参数存入了fBytes这块内存中, 那么最后fBytes这段内存空间就放置了一条条的绘制指令。
通过上面的了解,我们知道了UI线程并没有将应用设计的View转换成像素点数据,而是将每个View的绘图指令存入了内存中,我们通常称这些绘图指令为DisplayList, 下面让我们跳出这些细节,再次回到宏观一些的角度。
当所有的View的displaylist建立完成后,代码会来到:
RenderProxy.cpp (frameworks\base\libs\hwui\renderthread)
int RenderProxy::syncAndDrawFrame() {
return mDrawFrameTask.drawFrame();
}DrawFrameTask.cpp (frameworks\base\libs\hwui\renderthread)
void DrawFrameTask::postAndWait() {
AutoMutex _lock(mLock);
mRenderThread->queue().post([this]() { run(); });//丢任务到RenderThread线程
mSignal.wait(mLock);
}这边可以看到UI线程的工作到此结束,它丢了一个叫DrawFrameTask的任务到RenderThread线程中去,之后画面绘制的工作转移到RenderThread中来:
DrawFrameTask.cpp (frameworks\base\libs\hwui\renderthread)
void DrawFrameTask::run() {
.....
context->draw();
.....
}CanvasContext.cpp (frameworks\base\libs\hwui\renderthread)
void CanvasContext::draw() {
......
Frame frame = mRenderPipeline->getFrame();//这句会调用到Surface的dequeueBuffer
......
bool drew = mRenderPipeline->draw(frame, windowDirty, dirty, mLightGeometry, &mLayerUpdateQueue,
mContentDrawBounds, mOpaque, mLightInfo, mRenderNodes,
&(profiler()));
......
waitOnFences();
......
bool didSwap =
mRenderPipeline->swapBuffers(frame, drew, windowDirty, mCurrentFrameInfo, &requireSwap);//这句会调用到Surface的queueBuffer
......
}在这个函数中完成了三个重要的动作,一个是通过getFrame调到了Surface的dequeueBuffer向SurfaceFlinger申请了画布, 第二是通过mRenderPipeline->draw将画面画到申请到的画布上, 第三是通过调mRenderPipeline->swapBuffers把画布提交到SurfaceFlinger去显示。
那么在mRenderPipeline->draw里是如何将displaylist翻译成画布上的像素点颜色的呢?
SkiaOpenGLPipeline.cpp (frameworks\base\libs\hwui\pipeline\skia)
bool SkiaOpenGLPipeline::draw(const Frame& frame, const SkRect& screenDirty, const SkRect& dirty,
const LightGeometry& lightGeometry,
LayerUpdateQueue* layerUpdateQueue, const Rect& contentDrawBounds,
bool opaque, const LightInfo& lightInfo,
const std::vector<sp<RenderNode>>& renderNodes,
FrameInfoVisualizer* profiler) {
......
renderFrame(*layerUpdateQueue, dirty, renderNodes, opaque, contentDrawBounds, surface, SkMatrix::I());
......
}SkiaPipeline.cpp (frameworks\base\libs\hwui\pipeline\skia)
void SkiaPipeline::renderFrame(const LayerUpdateQueue& layers, const SkRect& clip,
const std::vector<sp<RenderNode>>& nodes, bool opaque,
const Rect& contentDrawBounds, sk_sp<SkSurface> surface,
const SkMatrix& preTransform) {
......
SkCanvas* canvas = tryCapture(surface.get(), nodes[0].get(), layers);
......
renderFrameImpl(clip, nodes, opaque, contentDrawBounds, canvas, preTransform);
endCapture(surface.get());
......
ATRACE_NAME("flush commands");
surface->getCanvas()->flush();
......
}
在上面的renderFrameImpl中会把在UI线程中记录的displaylist重新“绘制”到skSurface中,然后通过SkCanvas将其转化为gl指令, surface->getCanvas()->flush();这句是将指令发送给GPU执行,这其中是如何“翻译”的细节笔者暂时尚未研究,这里先不做讨论。
总结一下应用通过android的View系统画出第一帧的总的流程,如下图所示:
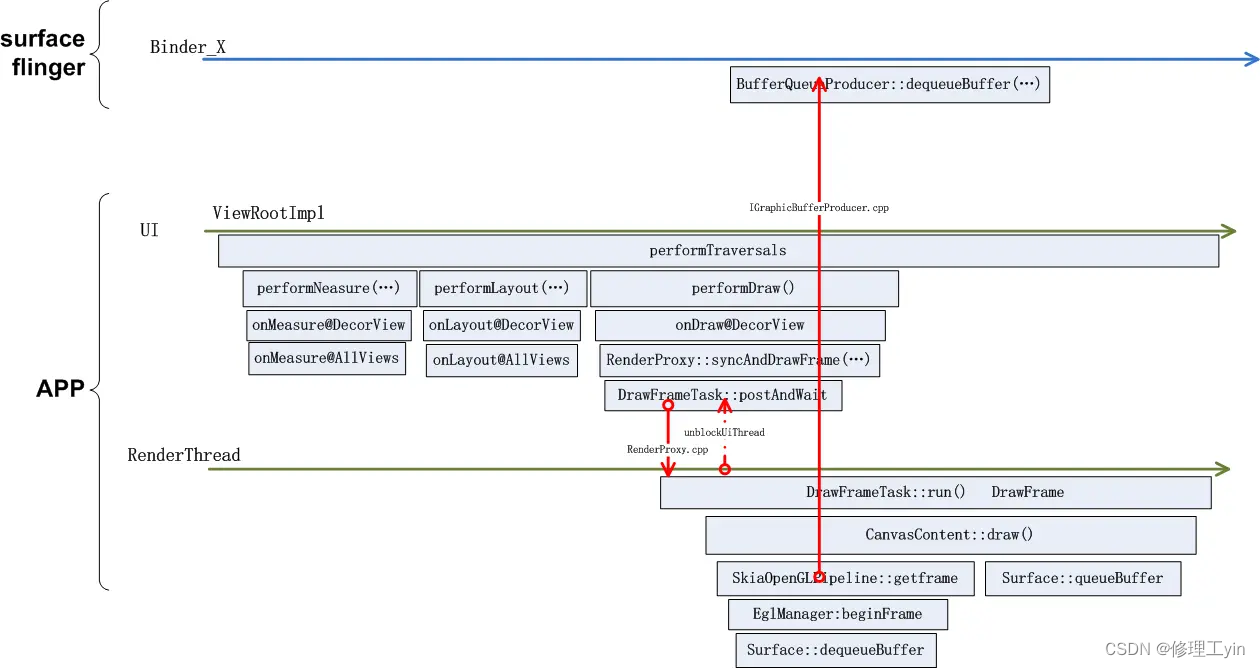
首先是UI线程进行measure, layout然后开始draw, 在draw的过程中会建立displaylist树,将每个view应该怎么画记录下来,然后通过RenderProxy把后续任务下达给RenderThread, RenderThread主要完成三个动作,先通过Surface接口向Surfaceflinger申请buffer, 然后通过SkiaOpenGLPipline的draw方法把displaylist翻译成GPU指令, 指挥GPU把指令变成像素点数据, 最后通过swapBuffer把数据提交给SurfaceFlinger, 完成一帧数据的绘制和提交。
这个过程我们可以在systrace上观察到,如下图所示: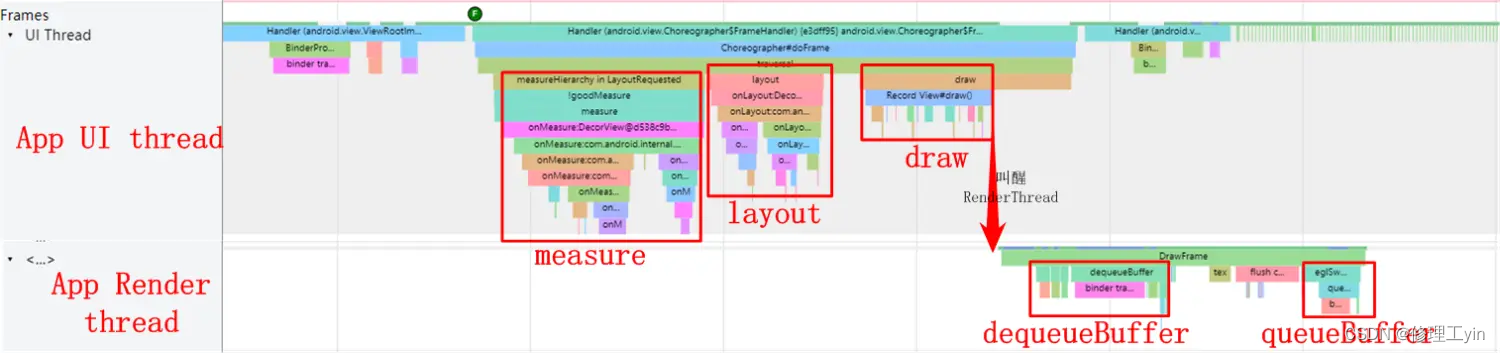

7.3. 帧数据的提交过程
那么应用提交buffer以后SurfaceFlinger会如何处理呢?又是如何提交到HWC Service去合成的呢?
首先响应应用queueBuffer的是一条binder线程, 处理逻辑会走进:
BufferQueueProducer.cpp (frameworks\native\libs\gui)
status_t BufferQueueProducer::queueBuffer(int slot,
const QueueBufferInput &input, QueueBufferOutput *output) {
ATRACE_CALL();
ATRACE_BUFFER_INDEX(slot);
......
if (frameAvailableListener != nullptr) {
frameAvailableListener->onFrameAvailable(item);
}
......
}上面的frameAvailableListener是BufferQueueLayer:
BufferQueueLayer.cpp (frameworks\native\services\surfaceflinger)
void BufferQueueLayer::onFrameAvailable(const BufferItem& item) {
......
mFlinger->signalLayerUpdate();//这里申请下一个vsync-sf信号
......
}由上面代码可知,只要有layer上帧,那么就会申请下一次的vsync-sf信号, 当vsync-sf信号来时会调用onMessageReceived函数来处理帧数据:
SurfaceFlinger.cpp (frameworks\native\services\surfaceflinger)
void SurfaceFlinger::onMessageInvalidate(nsecs_t expectedVSyncTime) {
ATRACE_CALL();
......
refreshNeeded |= handleMessageInvalidate();
......
signalRefresh();//再次向消息队列发送一个消息,消息到达时会调用onMessageRefresh
......
}
bool SurfaceFlinger::handleMessageInvalidate() {
ATRACE_CALL();
bool refreshNeeded = handlePageFlip();
......
}在handleMessageInvalidate里一个比较重要的函数是handlePageFlip():
bool SurfaceFlinger::handlePageFlip()
{
ATRACE_CALL();
......
mDrawingState.traverse([&](Layer* layer) {
if (layer->hasReadyFrame()) {
frameQueued = true;
if (layer->shouldPresentNow(expectedPresentTime)) {
mLayersWithQueuedFrames.push_back(layer);
}
.......
}
......
});
......
for (auto& layer : mLayersWithQueuedFrames) {
if (layer->latchBuffer(visibleRegions, latchTime, expectedPresentTime)) {
mLayersPendingRefresh.push_back(layer);
}
.......
}
......
}这里可以看出来,handlePageFlip里一个重要的工作是检查所有的Layer是否有新buffer提交,如果有则调用其latchBuffer来处理:
BufferLayer.cpp (frameworks\native\services\surfaceflinger)
bool BufferLayer::latchBuffer(bool& recomputeVisibleRegions, nsecs_t latchTime,
nsecs_t expectedPresentTime) {
ATRACE_CALL();
......
status_t err = updateTexImage(recomputeVisibleRegions, latchTime, expectedPresentTime);
......
}BufferQueueLayer.cpp (frameworks\native\services\surfaceflinger)
status_t BufferQueueLayer::updateTexImage(bool& recomputeVisibleRegions, nsecs_t latchTime,
nsecs_t expectedPresentTime) {
......
status_t updateResult = mConsumer->updateTexImage(&r, expectedPresentTime, &mAutoRefresh,
&queuedBuffer, maxFrameNumberToAcquire);
......
}BufferLayerConsumer.cpp (frameworks\native\services\surfaceflinger)
status_t BufferLayerConsumer::updateTexImage(BufferRejecter* rejecter, nsecs_t expectedPresentTime,
bool* autoRefresh, bool* queuedBuffer,
uint64_t maxFrameNumber) {
ATRACE_CALL();
......
status_t err = acquireBufferLocked(&item, expectedPresentTime, maxFrameNumber);
......
}这里调用到了BufferLayerConsumer的基类ConsumerBase里:
status_t ConsumerBase::acquireBufferLocked(BufferItem *item,
nsecs_t presentWhen, uint64_t maxFrameNumber) {
......
status_t err = mConsumer->acquireBuffer(item, presentWhen, maxFrameNumber);
......
}到这里onMessageReceived中的主要工作结束,在这个函数的处理中,SurfaceFlinger主要是检查每个Layer是否有新提交的buffer, 如果有则调用latchBuffer将每个BufferQueue中的Slot 通过acquireBuffer拿走。 之后拿走的buffer(Slot对应的状态是ACQUIRED状态)会被交由HWC Service处理,这部分是在onMessageRefresh里处理的:
void SurfaceFlinger::onMessageRefresh() {
ATRACE_CALL();
......
mCompositionEngine->present(refreshArgs);
......
}CompositionEngine.cpp (frameworks\native\services\surfaceflinger\compositionengine\src)
void CompositionEngine::present(CompositionRefreshArgs& args) {
ATRACE_CALL();
......
for (const auto& output : args.outputs) {
output->present(args);
}
......
}Output.cpp (frameworks\native\services\surfaceflinger\compositionengine\src)
void Output::present(const compositionengine::CompositionRefreshArgs& refreshArgs) {
ATRACE_CALL();
......
updateAndWriteCompositionState(refreshArgs);//告知HWC service有哪些layer要参与合成
......
beginFrame();
prepareFrame();
......
finishFrame(refreshArgs);
postFramebuffer();//这里会调用到HWC service的接口去present display合成画面
}
void Output::postFramebuffer() {
......
auto frame = presentAndGetFrameFences();
......
}HWComposer.cpp (frameworks\native\services\surfaceflinger\displayhardware)
status_t HWComposer::presentAndGetReleaseFences(DisplayId displayId) {
ATRACE_CALL();
......
auto error = hwcDisplay->present(&displayData.lastPresentFence);//送去HWC service合成
......
std::unordered_map<HWC2::Layer*, sp<Fence>> releaseFences;
error = hwcDisplay->getReleaseFences(&releaseFences);
RETURN_IF_HWC_ERROR_FOR("getReleaseFences", error, displayId, UNKNOWN_ERROR);
displayData.releaseFences = std::move(releaseFences);//获取releaseFence, 以便通知到各个Slot, buffer被release后会通过dequeueBuffer给到应用,应用在绘图前会等待releaseFence
......
}Hwc2::Composer是HWC service提供给Surfaceflinger侧的一些接口,挑些有代表的如下
class Composer final : public Hwc2::Composer {
......
Error createLayer(Display display, Layer* outLayer) override;//通知HWC要新加一个layer
Error destroyLayer(Display display, Layer layer) override;//通知hwc 有个layer被destory掉了
......
Error presentDisplay(Display display, int* outPresentFence) override;//合成画面
......
Error setActiveConfig(Display display, Config config) override;//设置一些参数,如屏幕刷新率
......
CommandWriter mWriter;
CommandReader mReader;//mWriter用于SurfaceFlinger向HWC service发送指令, mReader用于从HWC service侧获取信息
}Error Composer::presentDisplay(Display display, int* outPresentFence)
{
......
mWriter.presentDisplay();
......
}到这里 SurfaceFlinger侧的处理主流程走完了,我们先来总结一下当应用的buffer提交到SurfaceFlinger后SurfaceFlinger所经历的主要流程, 如下图所示,首先binder线程会通过BufferQueue机制把应用上帧的Slot状态改为QUEUED, 然后把这个Slot放入mQueue队列(请回忆5.3节知识), 然后通过onFrameAvailable回调通知到BufferQueueLayer, 在处理函数里会请求下一次的vsync-sf信号,在vsync-sf信号到来后,SurfaceFlinger主线程要执行两次onMessageReceived, 第一次要检查所有的layer看是否有上帧, 如果有Layer上帧就调用它的latchBuffer把它的buffer acquireBuffer走。并发送一个消息到主消息队列,让UI线程再次走进onMessageReceived, 第二次走进来时,主要执行present方法,在这些方法里会和HWC service沟通,调用它的跨进程接口通知它去做图层的合成。
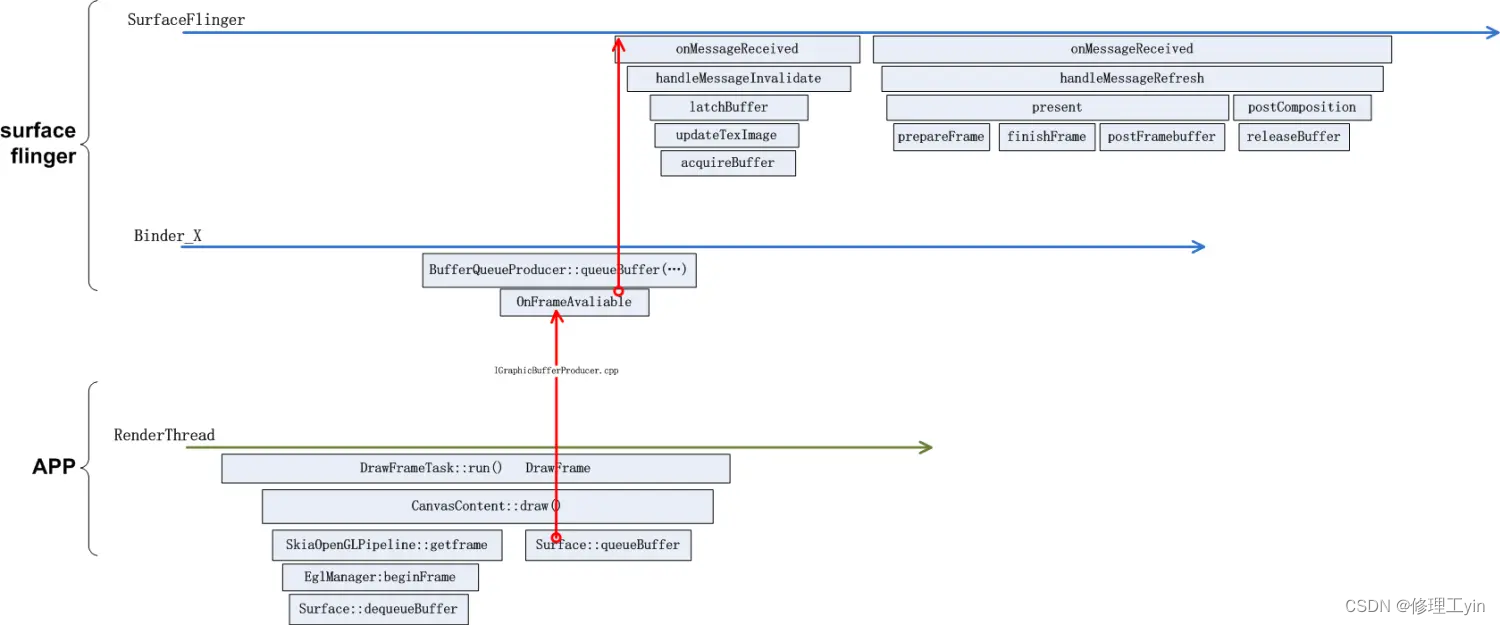
之后就进入HWC Service的处理流程,这部分的处理流程和芯片厂商HAL层实现紧密相关,限于某些因素不便于介绍。本章应用更新画面的代码流程就介绍到这里。
7.4. 本章小结
本章我们沿着代码逻辑学习了应用是如何申请到画布、使用android的View系统如何绘图、绘图完成后如何提交buffer以及buffer提交以及Surfaceflinger如何处理。但本章所述的逻辑均是指通过android的View系统绘图的过程,也可以称其为hwui绘图流程,从上面代码流程可以知道,hwui的绘图流程是被vsync信号触发的,开始于vsync信号到达UI线程调用performTraversals函数, hwui的画面更新是被vsync信号驱动的。
在android系统中也有提供不依赖vsync信号的自主上帧接口,比如app可以使用SurfaceView这个特殊的View来申请一个独立于Activity之外的画布。接下来我们通过一些helloworld示例来看下这些接口如何使用。
8. 应用是如何绘图的
目前很多游戏类应用都是借由SurfaceView申请到画布,然后自主上帧,并不依赖Vsync信号, 所以本章通过几个helloworld示例来看下应用侧是如何绘图和上帧的。
由于java层很多接口是对C层接口的JNI封装,这里我们只看一些C层接口的用法。下面的示例代码为缩减篇幅把一些异常处理部分的代码去除了,只保留了重要的部分,如果读者需要执行示例代码,可以自行加入一些异常处理部分。
8.1. 无图形库支持下的绘图
下面的示例中演示的是如何使用C层接口向SurfaceFlinger申请一块画布,然后不使用任何图形库,直接修改画布上的像素值,最后提交给SurfaceFlinger显示。
int main()
{
sp<ProcessState> proc(ProcessState::self());
ProcessState::self()->startThreadPool();//在应用和SurfaceFlinger沟通过程中要使用到binder, 所以这里要先初始化binder线程池
sp<SurfaceComposerClient> client = new SurfaceComposerClient();//SurfaceComposerClient是SurfaceFlinger在应用侧的代表, SurfaceFlinger的接口通过它来提供
client->initCheck();
//先通过createSurface接口来申请一块画布,参数里包含对画布起的名字,大小,位深信息
sp<SurfaceControl> surfaceControl = client->createSurface(String8("Console Surface"),800, 600, PIXEL_FORMAT_RGBA_8888);
SurfaceComposerClient::Transaction t;
t.setLayer(surfaceControl, 0x40000000).apply();
//通过getSurface接口获取到Surface对象
sp<Surface> surface = surfaceControl->getSurface();
ANativeWindow_Buffer buffer;
//通过Surface的lock方法调用到dequeueBuffer,获取到一个BufferQueue可用的Slot
status_t err = surface->lock(&buffer, NULL);// &clipRegin
void* addr = buffer.bits;
ssize_t len = buffer.stride * 4 * buffer.height;
memset(addr, 255, len);//这里绘图,由于我们没有使用任何图形库,所以这里把内存填成255, 画一个纯色画面
surface->unlockAndPost();//这里会调用到queueBuffer,把我们绘制好的画面提交给SurfaceFlinger
printf("sleep...\n");
usleep(5 * 1000 * 1000);
surface.clear();
surfaceControl.clear();
printf("complete. CTRL+C to finish.\n");
IPCThreadState::self()->joinThreadPool();
return 0;
}在上面的示例中,几个关建点是,第一步,先创建出一个SurfaceComposerClient,它是我们和Surfaceflinger沟通的桥梁,第二步,通过SurfaceComposerClient的createLayer接口创建一个SurfaceControl,这是我们控制Surface的一个工具,第三步,从SurfaceControl的getSurface接口来获取Surface对象,这是我们操作BufferQueue的接口。
有了Surface对象,我们可以通过Surface的lock方法来dequeueBuffer, 再通过unlockAndPost接口来queueBuffer, 循环执行,我们就可以对画布进行连续绘制和提交数据了,屏幕上动态的画面就出来了。
所以对于SurfaceFlinger或者说对于Display系统底层所提供的接口主要就是这三个SurfaceComposerClient, SurfaceControl和Surface. 这里我们不妨称其为Display系统接口三大件。
8.2. 有图形库支持下的绘图
在上节示例中,我们并没有去绘画复杂的图案,只是使用内存填充的方式画了一个纯色画面,在本节中我们将尝试使用图形库在给定的画布上画一些复杂的图案,比如画一张图片上去。
在上节的讨论中我们知道要画画面出来,要拿到Display的三大件(SurfaceComposerClient, SurfaceControl和Surface),接下来拿到画布后我们使用skia库来画一张图片到屏幕上。
using namespace android;
//先写一个函数把图片转成一个bitmap
static status_t initBitmap(SkBitmap* bitmap, const char* fileName) {
if (fileName == NULL) {
return NO_INIT;
}
sk_sp<SkData> data = SkData::MakeFromFileName(fileName);
sk_sp<SkImage> image = SkImage::MakeFromEncoded(data);
bool result = image->asLegacyBitmap(bitmap, SkImage::kRO_LegacyBitmapMode);
if(!result ){
printf("decode picture fail!");
return NO_INIT;
}
return NO_ERROR;
}
int main()
{
sp<ProcessState> proc(ProcessState::self());
ProcessState::self()->startThreadPool();//和上一示例一样要开启binder线程池
// create a client to surfaceflinger
sp<SurfaceComposerClient> client = new SurfaceComposerClient();//三大件第一件
client->initCheck();
sp<SurfaceControl> surfaceControl = client->createSurface(String8("Consoleplayer Surface"),800, 600, PIXEL_FORMAT_RGBA_8888);//三大件第二件
SurfaceComposerClient::Transaction t;
t.setLayer(surfaceControl, 0x40000000).apply();
sp<Surface> surface = surfaceControl->getSurface();//三大件第三件
sp<IGraphicBufferProducer> graphicBufferProducer = surface->getIGraphicBufferProducer();
ANativeWindow_Buffer buffer;
status_t err = surface->lock(&buffer, NULL);//调用dequeueBuffer把buffer拿来
SkBitmap* bitmapDevice = new SkBitmap;
SkIRect* updateRect = new SkIRect;
SkBitmap* bitmap = new SkBitmap;
initBitmap(bitmap, "/sdcard/picture.png");//从文件读一个bitmap出来
printf("decode picture done.\n");
ssize_t bpr = buffer.stride * bytesPerPixel(buffer.format);
SkColorType config = convertPixelFormat(buffer.format);
bitmapDevice->setInfo(SkImageInfo::Make(buffer.width, buffer.height, config, kPremul_SkAlphaType), bpr);
//上面我们创建了另一个SkBitmap对象bitmapDevice
if (buffer.width > 0 && buffer.height > 0) {
bitmapDevice->setPixels(buffer.bits);//这里把帧缓冲区buffer的地址设给了bitmapDevice,这时和bitmapDevice画东西就是在向帧缓冲区buffer画东西
} else {
bitmapDevice->setPixels(NULL);
}
//SkRegion region;
printf("to create canvas..\n");
SkCanvas* nativeCanvas = new SkCanvas(*bitmapDevice);
SkRect sr;
sr.set(*updateRect);
nativeCanvas->clipRect(sr);
SkPaint paint;
nativeCanvas->clear(SK_ColorBLACK);
const SkRect dst = SkRect::MakeXYWH(0,0,800, 600);
paint.setAlpha(255);
const SkIRect src1 = SkIRect::MakeXYWH(0, 0, bitmap->width(), bitmap->height());
printf("draw ....\n");
nativeCanvas->drawBitmapRect((*bitmap), src1, dst, &paint);//调用SkCanvas的drawBitmapRect把图片画到bitmapDevice,也就是画到了从Surface申请到的帧缓冲区buffer中
surface->unlockAndPost();//调用queueBuffer把buffer提交给SurfaceFlinger显示
printf("sleep...\n");
usleep(10 * 1000 * 1000);
surface.clear();
surfaceControl.clear();
printf("test complete. CTRL+C to finish.\n");
IPCThreadState::self()->joinThreadPool();
return 0;
}在上面的示例中获取到帧缓冲区buffer的方式和上一个例子是一样的,不同点 是我们把申请到的buffer的地址空间给到了skia库,然后我们通过skia提供的操作接口把一张图片画到了帧缓冲区buffer中,由此可以看出我们想使用图形库来操作帧缓冲区的关键是要把帧缓冲区buffer的地址对接到图形库提供的接口上。
在android平台上,我们通常不会直接使用CPU去绘图,通常是调用opengl或其他图形库去指挥GPU去做这些绘图的事情,那么又是如何使用opengl库来完成绘图的呢?
8.3. 使用OpenGL&EGL的绘图
由上面第二个例子可知,要想使用一个图形库来向帧缓冲区buffer绘图的关建是要把对应的buffer给到图形库, 我们知道opengl是一套设备无关的api接口,它和平台是无关的,所以和Surface接口的任务是由EGL库来完成的,帧缓冲区buffer要和EGL库对接。
在hwui绘图中是以如下结构对接的:
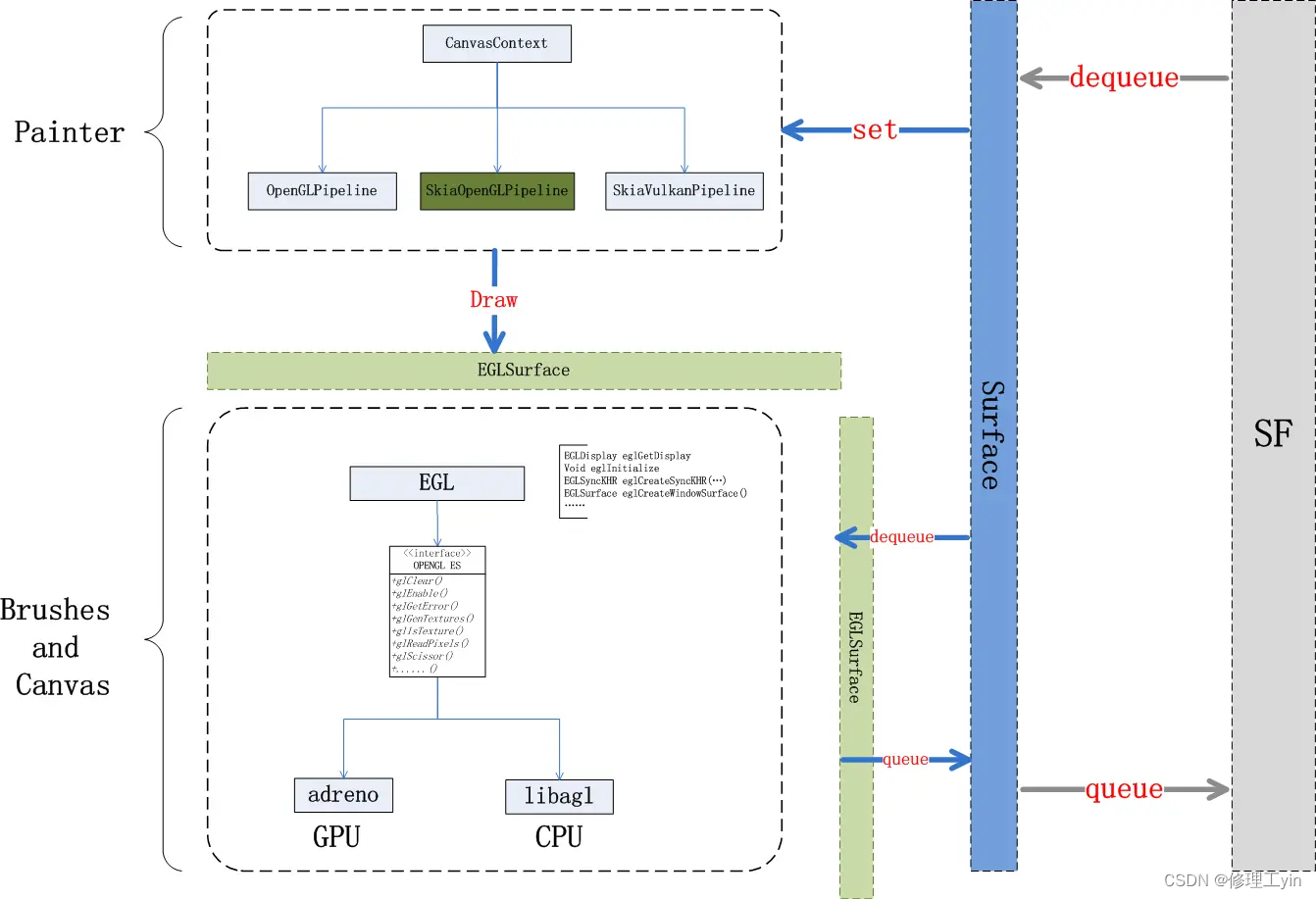
首先EGL库会提供一个EGLSurface的对象,这个对象是对三大件中的Surface的一个封装,它本身与帧提交相关部分提供了两个接口:dequeue/queue,分别对应Surface的dequeueBuffer和queueBuffer.
下面我们通过一个示例来看下它在C层是如何使用和与三大件对接的:
using namespace android;
int main()
{
sp<ProcessState> proc(ProcessState::self());
ProcessState::self()->startThreadPool();//同样地开启binder线程池
// create a client to surfaceflinger
sp<SurfaceComposerClient> client = new SurfaceComposerClient();//三大件第一件
client->initCheck();
sp<SurfaceControl> surfaceControl = client->createSurface(String8("Consoleplayer Surface"),800, 600, PIXEL_FORMAT_RGBA_8888);//三大件第二件
SurfaceComposerClient::Transaction t;
t.setLayer(surfaceControl, 0x40000000).apply();
sp<Surface> surface = surfaceControl->getSurface();//三大件第三件
// initialize opengl and egl
const EGLint attribs[] = {
EGL_RED_SIZE, 8,
EGL_GREEN_SIZE, 8,
EGL_BLUE_SIZE, 8,
EGL_DEPTH_SIZE, 0,
EGL_NONE
};
//开始初始化EGL库
EGLint w, h;
EGLSurface eglSurface;
EGLint numConfigs;
EGLConfig config;
EGLContext context;
EGLDisplay display = eglGetDisplay(EGL_DEFAULT_DISPLAY);
eglInitialize(display, 0, 0);
eglChooseConfig(display, attribs, &config, 1, &numConfigs);
eglSurface = eglCreateWindowSurface(display, config, surface.get(), NULL);//创建eglSurface(对Surface的一个封装)
context = eglCreateContext(display, config, NULL, NULL);
eglQuerySurface(display, eglSurface, EGL_WIDTH, &w);
eglQuerySurface(display, eglSurface, EGL_HEIGHT, &h);
if (eglMakeCurrent(display, eglSurface, eglSurface, context) == EGL_FALSE)//会调用dequeue以获取帧缓冲区buffer
return NO_INIT;
glShadeModel(GL_FLAT);
glDisable(GL_DITHER);
glDisable(GL_SCISSOR_TEST);
//draw red
glClearColor(255,0,0,1);//这里用opengl库来一个纯红色的画面
glClear(GL_COLOR_BUFFER_BIT);
eglSwapBuffers(display, eglSurface);//这里会调用到Surface的queueBuffer方法,提交画好的帧缓冲区数据
printf("sleep...\n");
usleep(10 * 1000 * 1000);
surface.clear();
surfaceControl.clear();
printf("test complete. CTRL+C to finish.\n");
IPCThreadState::self()->joinThreadPool();
return 0;
}在上面的例子中我们看到了opengl&egl库对帧缓冲区buffer的使用方式,首先和8.1的示例中一样从三大件中获取的帧缓冲区操作接口,只是这里我们不再直接使用该接口,而是把Surface对象给到EGL库,由EGL库去使用它,我们使用opengl 的api来间接操作帧缓冲区buffer,这些操作包括申请新的BufferQueue slot和提交绘制好的BufferQueue slot.
8.4 本章小结
本章我们通过三个示例程序了解了下display部分给应用层设计的接口,了解到了通过三大件可以拿到帧缓冲区buffer, 之后应用如何作画就是应用层的事情了,应用可以选择不使用图形库,也可以选择图形库让cpu来作画,也可以使用像opengl&egl这样的库来指挥GPU来作画。
9. 应用画面更新总结
通过以上章节的了解,APP的画面要显示到屏幕上大致上要经过如下图所示系统组件的处理:

首先App向SurfaceFlinger申请画布(通过dequeueBuffer接口),SurfaceFlinger内部有一个BufferQueue的管理实体,它会分配一个GraphicBuffer给到APP, App拿到buffer后调用图形库向这块buffer内绘画。
APP绘画完成后使用向SurfaceFlinger提交绘制完成的buffer(通过queueBuffer接口), 当然这时候的绘制完成只是说在CPU侧绘制完成,此时GPU可能还在该buffer上作画,所以这时向SurfaceFlinger提交数据的同时还会带上一个acquireFence,使用接下来使用该buffer的人能知道什么时候buffer使用完毕了。
SurfaceFlinger收到应用提交的帧缓冲区buffer后是在下一个vsync-sf信号来时做处理,首先遍历所有的Layer, 找到哪些Layer有上帧, 通过acquireBuffer把Buffer拿出来,通知给HWC Service去参与合成, 最后调用HWC Service的presentDisplay接口来告知HWC Service SurfaceFlinger的工作已完成。
HWC Service收到合成任务后开始合成数据,在SurfaceFlinger调用presetDisplay时会去调用DRM接口DRMAtomicReq::Commit通知kernel可以向DDIC发送数据了.
如果有TE信号来提示已进入消隐区,这时DRM驱动会马上开始通过DSI总线向DDIC传输数据,与此同时Panel的Disp Scan也在进行中,传输完成后这帧画面就完整地显示到了屏幕上。
至此,一帧画面的更新过程就完成了,我们这里讲了这么久的一个复杂的过程,其实在高刷手机上一秒钟要重复做100多次!

















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









