






原博:憨批的语义分割重制版9——Pytorch 搭建自己的DeeplabV3+语义分割平台-CSDN博客
github:https://github.com/bubbliiiing/deeplabv3-plus-pytorch
最近在使用Bubbliiing的deeplabv3+模型对自己的数据集进行训练时,使用博主提供的json_to_dataset.py对labelme标注的数据进行转换后,训练完的模型在预测结果时没有拉框的情况,原博的评论区下也有很多同学有这种情况,具体如下:
json_to_dataset.py代码:
import base64
import json
import os
import os.path as osp
import numpy as np
import PIL.Image
from labelme import utils
if __name__ == '__main__':
# jpg原图路径
jpgs_path = "datasets/JPEGImages"
# 标签图片输出路径
pngs_path = "datasets/SegmentationClass"
classes = ["_background_", "xxx"]
# json文件路径
count = os.listdir(r".\xml")
for i in range(0, len(count)):
path = os.path.join(r".\xml", count[i])
if os.path.isfile(path) and path.endswith('json'):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
PIL.Image.fromarray(img).save(osp.join(jpgs_path, count[i].split(".")[0]+'.jpg'))
new = np.zeros([np.shape(img)[0],np.shape(img)[1]])
for name in label_names:
index_json = label_names.index(name)
index_all = classes.index(name)
new = new + index_all*(np.array(lbl) == index_json)
utils.lblsave(osp.join(pngs_path, count[i].split(".")[0]+'.png'), new)
print('Saved ' + count[i].split(".")[0] + '.jpg and ' + count[i].split(".")[0] + '.png')
训练时的损失值也很不科学:
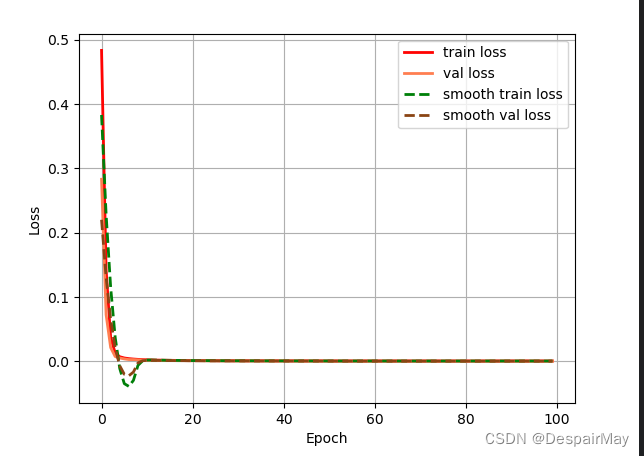
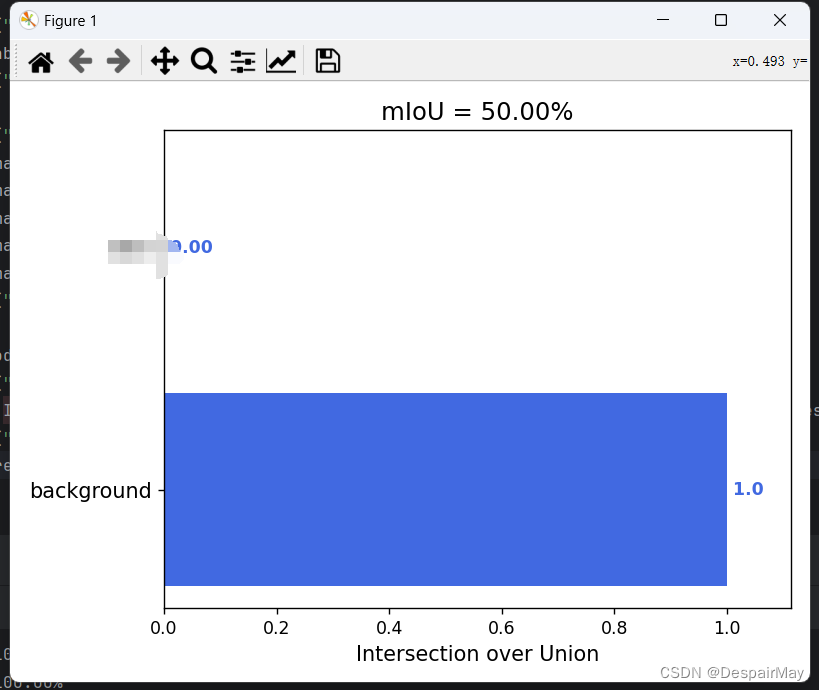
又计算了miou值,好嘛(你看看你给孩子学了什么!):
解决办法:
首先怀疑VOC标注图片的像素值的问题,非博主所说的目标区域像素值为1,背景区域像素值为0,用代码遍历统计voc标注图片的所有像素值:
from PIL import Image
import numpy as np
# 图像路径
image = Image.open(r'path.png')
# 转换为NumPy数组
image_array = np.array(image)
# 统计每个像素值的数量
unique, counts = np.unique(image_array, return_counts=True)
# 打印结果
pixel_counts = dict(zip(unique, counts))
for pixel_value, count in pixel_counts.items():
print(f'像素值 {pixel_value}: {count} 个')
运行结果发现:
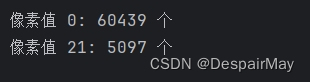
嘿!您猜怎么着?,使用博主提供的json_to_datasets.py代码转完之后的像素值会因为不明原因异常,需要手动修改一下,添加代码:
# 令所有非0像素值点为1
image_array[image_array != 0] = 1
#这里要根据自己实际标注的标签数量来确定像素值,我的标签只有一个所以目标区域为1,背景为0再统计一下试试:

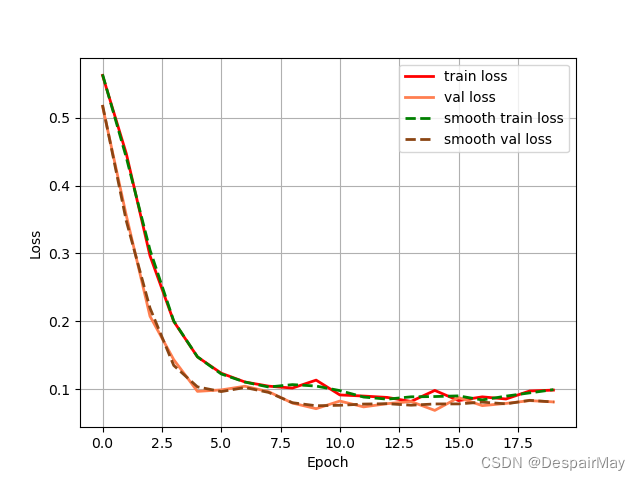
批量将png图片的像素值全部修改完成之后再重新进行训练,训练过程就正常多了,预测结果也可以正常拉框显示区域了(预测结果就不放了):
损失值:

mIoU:
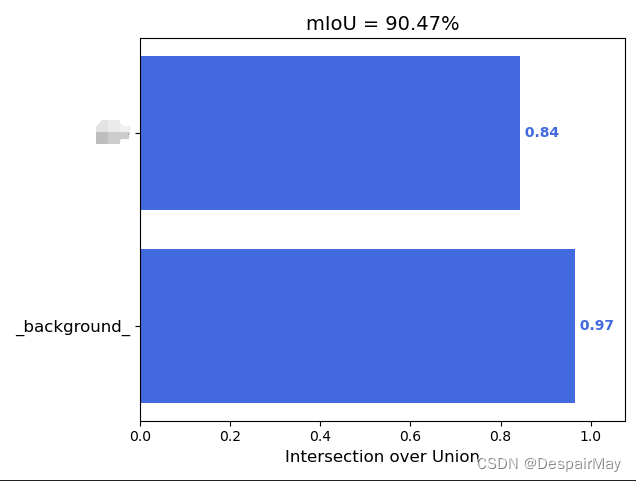
又可以愉快的炼丹了
总结
可能是环境配置和库版本不一的问题或是其他玄学问题,运行博主提供的json_to_datasets.py会导致原本应该像素值为1的点会乱掉(
所以就像原博主说的,请仔细检查一下自己的数据集的格式和像素值的问题!
其他问题请参考原博主的帖子神经网络学习小记录-番外篇——常见问题汇总_loading weights into state dict... killed-CSDN博客















 1990
1990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









