






本次学习的相关资料:
【教程】
https://datawhalechina.github.io/easy-rl/
https://linklearner.com/learn/summary/11
https://github.com/datawhalechina/joyrl-book
【学习者手册】
https://mp.weixin.qq.com/s/pwWg0w1DL2C1i_Hs3SZedg
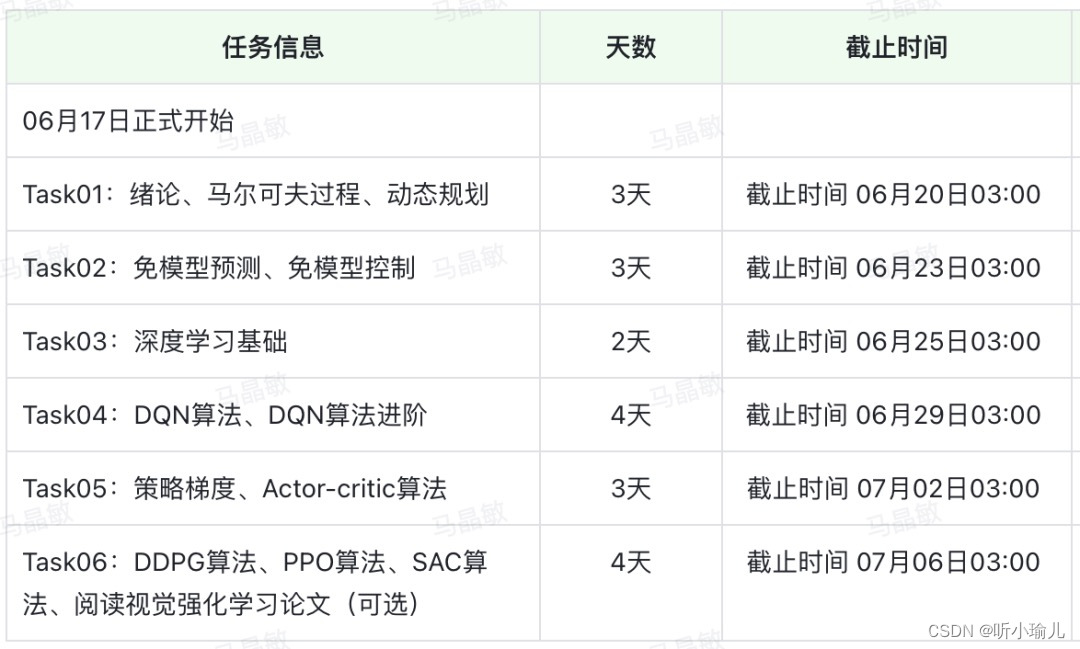
原文目录链接:
通俗理解笔记:
免模型预测和免模型控制
免模型预测和免模型控制是强化学习中的两个概念,它们涉及到在不知道环境具体模型的情况下,如何进行决策和行动。我们可以用一个非常简单的比喻来解释这两个概念,以便让小学生也能理解。
想象一下,你是一个探险家,你要在一个未知的地形中找到宝藏。你有一张地图,但是地图上没有标记宝藏的位置,你只能通过探索来找到它。
-
免模型预测: 免模型预测就像是你没有地图,但是你可以四处走动来探索地形。每当你到达一个新的地方,你会观察周围的环境特征,比如是否有河流、山脉或特殊的树木,然后根据这些信息来猜测宝藏可能的位置。你可能会记住某些地方给你带来了好的结果(比如找到了一些金币),而其他地方则没有。通过不断地探索和记录你的发现,你会逐渐建立起一个心理地图,这个地图会帮助你预测哪里可能藏有宝藏。你不需要知道整个地形的具体样子,只需要通过实际探索来不断更新你对宝藏位置的猜测。
-
免模型控制: 免模型控制就像是你不仅没有地图,而且你还有一只魔法灯笼,它可以告诉你往哪个方向走会离宝藏更近。但是,灯笼不会直接告诉你宝藏的位置,它只会给你一个提示,比如“向左走”或“向前走”。你根据这些提示来选择你的行动,这样你就可以在没有地图的情况下找到宝藏。
魔法灯笼在这里是一个比喻,用来代表强化学习中的策略。在免模型控制中,策略决定了智能体(探险家)在给定状态下应该采取的行动。这个策略可能是基于你之前的经验,也可能是基于一些简单的规则。
总结一下,免模型预测是关于如何在没有地图的情况下通过探索来猜测宝藏的位置,而免模型控制是关于如何在没有地图的情况下,根据一些提示来选择行动,以便找到宝藏。这两种方法都允许我们在不完全了解环境的情况下,通过实际经验和反馈来做出决策和行动。
蒙特卡洛策略评估
想象一下,你有一盒彩色糖果,你想知道这盒糖果平均来看是什么味道的。你不想一个一个尝,因为你可能有很多糖果,这会花很长时间。所以,你决定做这样一件事:
-
随机尝糖果:你闭上眼睛,每次从盒子里随机拿一个糖果尝一下。你可能尝到酸的,也可能尝到甜的。
-
记录感觉:每次尝了糖果后,你都会记下来这个糖果是酸的、甜的还是其他味道,并且给它一个分数,比如甜的给5分,酸的给1分。
-
尝很多次:你重复这个过程很多很多次,可能是几十次,也可能是几百次。
-
计算平均分:最后,你把所有尝糖果的分数加起来,然后除以你尝糖果的总次数。这个结果就是一个平均分,它告诉你这盒糖果平均来看是什么味道的。
这个方法就像蒙特卡洛策略评估。你通过随机尝试(尝糖果),然后记录结果(味道和分数),最后计算平均值来评估(糖果的味道)。这样,你就可以了解这盒糖果的整体味道,而不需要尝完每一个糖果。
在这个例子中,糖果就像是游戏中的不同情况,尝糖果的过程就像是玩游戏的过程,而记录和计算分数就是评估你的策略到底好不好。通过这种方法,我们可以不用知道每一个糖果的具体味道(不用知道游戏的每一个细节),也能大概了解整盒糖果的味道(评估策略的效果)。
动态规划方法、蒙特卡洛方法以及时序差分方法
在无法获取马尔可夫决策过程的模型情况下,我们可以通过蒙特卡洛方法和时序差分方法来估计某个给定策略的价值。 通俗解释动态规划方法、蒙特卡洛方法以及时序差分方法的自举和采样 。
想象一下,你是一个探险家,你的任务是找到一条从家到学校的最短路线。但是,你不知道每条路需要多长时间,你需要找到一种方法来估计这些时间。
-
动态规划方法: 动态规划就像是你有一个魔法地图,它可以告诉你从任何地方到学校的最快路线。你只需要看看地图,就能知道最好的路。但是,如果地图很大或者有很多路,这可能需要一些时间来计算。
-
蒙特卡洛方法: 蒙特卡洛方法就像是你决定亲自尝试每条路,并且记录下每次走的时间。你尝试很多次,然后计算平均时间。这种方法需要你实际去走很多次,但是你不需要知道每条路的具体情况,只需要通过尝试来找到最短的时间。
-
时序差分方法: 时序差分方法就像是你在走一条路的时候,每到达一个新路标,你就看看地图,然后估计从那个新路标到学校的最快路线。你不需要等到最后到达学校才知道时间,你可以在路上不断地更新你的估计。这种方法结合了动态规划和蒙特卡洛的方法,你既实际走路,又看地图来更新你的估计。
自举(Bootstrapping): 自举就像是你每次到达一个新路标时,你不仅仅看地图,还问问你的朋友他们走这条路需要多长时间。然后你把他们的答案和你自己的经验结合起来,来更新你对这条路的估计。这样,你就可以用一部分信息来帮助估计另一部分信息。
采样(Sampling): 采样就像是你每次选择一条路走的时候,你只是随机选择,而不是根据地图或者朋友的经验。你通过实际走很多次不同的路来得到一个对每条路所需时间的整体估计。
所以,这三种方法都是用来估计从家到学校的最短时间,但是它们使用的方法不同。动态规划使用地图,蒙特卡洛方法通过实际走路来尝试,时序差分方法结合了实际走路和看地图。自举和采样是这些方法中用来帮助估计的一些额外技巧。
免模型控制中的同策略和异策略
理解免模型控制中的同策略和异策略方法,我们可以用一个小故事来比喻:
想象一下,你是一个探险家,你的目标是找到一片隐藏的黄金城市。你在一个未知的热带雨林中探险,没有地图,只能依靠自己的经验和直觉来找到出路。
-
同策略(On-policy)方法,如 Sarsa: 在同策略方法中,你边探险边学习。你有一个小本子(Q 表格),记录着每次你采取某种行动(比如向前走、向左转)后得到的奖励(比如找到一片水果、遇到一只危险的动物)。每次你采取行动后,你都会更新你的小本子,记录下这次行动的结果。这样,你在探险的过程中,不断地学习哪些行动更可能带你找到黄金城市,哪些行动可能会让你陷入危险。你用这些信息来决定你的下一步行动,确保即使有时候不得不随机选择行动,也不会离黄金城市太远。
-
异策略(Off-policy)方法,如 Q 学习: 在异策略方法中,你有两个小本子。一个是你自己的探险日志(行为策略),记录着你实际采取的行动和结果。另一个是你的梦想日志(目标策略),记录着你认为最优的行动和结果。你实际探险时可能会尝试一些冒险的行动,以探索雨林的不同部分。但当你坐下来思考时,你会查看梦想日志,考虑如果每次都采取最好的行动,会发生什么。这样,你可以在实际探险时采取一些冒险的行动,但在学习时考虑的是最优的行动策略。你的梦想日志会告诉你,哪些行动最有可能带你找到黄金城市。
同策略方法就像是你边走边学,每次行动后都更新你的知识,以确保你的下一步行动不会太冒险。异策略方法就像是你边走边记录,同时还有一个梦想日志告诉你最优的行动策略,这样即使你实际探险时采取了一些冒险行动,你仍然可以学习到最好的路线。这两种方法都能帮助你在不知道具体环境模型的情况下,找到最佳的策略。
更新公式的比较: -Sarsa 的更新公式考虑了实际采取的行动和该行动的即时奖励,以及未来奖励的估计。它不直接选择最大值,而是根据当前策略采取的行动来更新价值估计。 -Q 学习的更新公式则更为激进,它总是选择最大值来更新价值估计,不考虑实际采取的行动。它基于行为策略收集的经验来优化目标策略,希望能够找到最佳的行动策略。
总结来说,同策略方法(如 Sarsa)是保守的,它通过实际探索来学习,同时确保安全。异策略方法(如 Q 学习)则更为激进,它利用行为策略的探索来优化目标策略,希望能够找到最佳的行动路线。
















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









