






本次学习的相关资料:
【教程】
GitHub - datawhalechina/joyrl-book
【学习者手册】
https://mp.weixin.qq.com/s/pwWg0w1DL2C1i_Hs3SZedg
DQN算法
让我们用一个简单的例子来解释DQN算法:假设你是一个在迷宫中寻找宝藏的探险家。迷宫中有多个房间,每个房间都可以通往其他房间,但有些房间是死路。你的目标是找到存放宝藏的房间。
在DQN算法中,每个房间可以被视为一个“状态”,你的移动方向(向上、向下、向左、向右)可以被视为“动作”。你的目标是找到一系列动作,这些动作能带你到达藏有宝藏的房间。
一开始,你不知道哪个房间有宝藏,也不知道应该走哪条路。所以,你随机选择一个方向移动。当你进入一个新房间时,你会得到一个奖励。如果这个房间是藏有宝藏的房间,你会得到一个很大的奖励;如果这个房间是死路,你可能会得到一个负的奖励;如果这个房间只是普通的房间,你可能不会得到任何奖励或有很小的奖励。
在这个过程中,你会逐渐学习到每个状态(房间)和每个动作(移动方向)的“价值”(Q值)。价值高的动作意味着它们更有可能带你到达宝藏房间。通过不断的尝试和学习,你最终能够找到一条通往宝藏的路径。
在DQN算法中,神经网络会帮助你预测每个状态和动作的价值(Q值)。随着你不断探索迷宫,神经网络会通过观察你的经历(状态、动作、奖励和下一个状态)来不断更新和改进它的预测。这就是DQN算法的基本工作原理。

算法的训练过程分为交互采样和模型更新两个步骤,这两个步骤其实我们在深度学习基础那章讲强化学习与深度学习的关系的时候就已经给出示例了。其中交互采样的目的就是与环境交互并产生样本,模型更新则是利用得到的样本来更新相关的网络参数,更新方式涉及每个强化学习算法的核心。

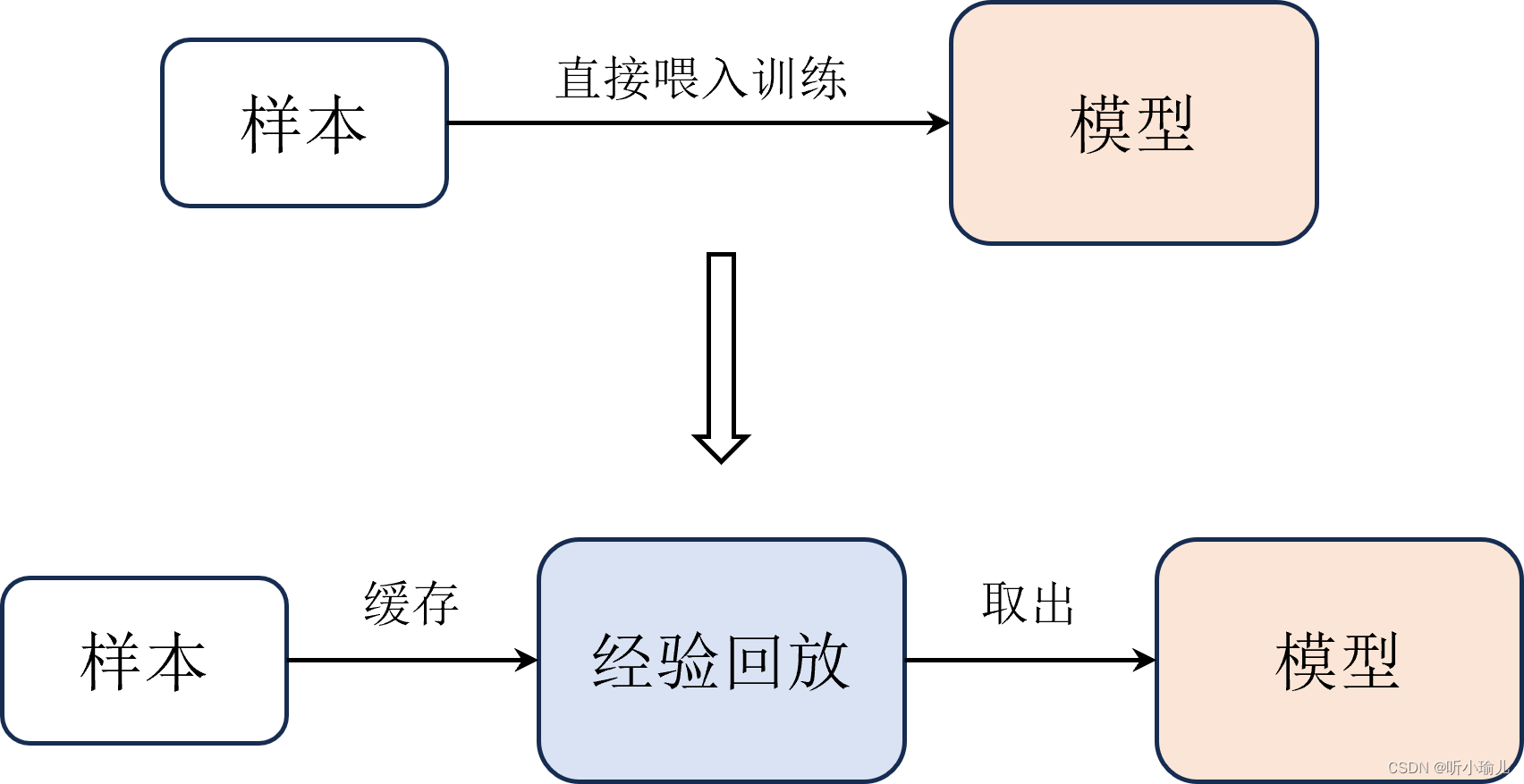
经验回放
- 什么是经验回放?
经验回放是一种机器学习技术,主要用于强化学习中。它允许代理(即AI)在环境中执行操作,然后将这些操作及其结果存储在记忆库中。这些经验可以被重复使用,以便代理从过去的行动中学习,并改进其未来的决策。
- 经验回放的工作原理是什么?
经验回放的工作原理如下:
- 代理在环境中执行一个动作。
- 环境对动作做出响应,产生一个新的状态和一个奖励或惩罚。
- 这个经历(动作、环境响应、新状态、奖励/惩罚)被存储在一个记忆库中。
- 之后,代理可以从记忆库中随机选择一些经历进行回放。
- 在回放过程中,代理会模拟执行相同的动作,但这一次它会收到虚拟的奖励或惩罚,而不是实际的奖励或惩罚。
- 通过这样的回放过程,代理可以多次学习同样的经验,从而加深对哪些行为是有效的以及如何改进的理解。
- 为什么经验回放对于强化学习很重要?
经验回放对于强化学习很重要,因为它允许代理在不直接与环境交互的情况下反复学习。在实际环境中,每次尝试新的动作都可能需要花费时间和资源,而且可能会受到不可预测的因素影响。通过经验回放,代理可以在短时间内多次模拟同一动作,从而更高效地学习和优化策略。此外,经验回放还可以帮助解决样本效率低的问题,因为代理可以从少量的原始数据中学习到更多的知识。
- 经验回放在哪些场景中特别有用?
经验回放在以下场景中特别有用:
- 当环境变化时,经验回放可以帮助代理快速适应新的环境。
- 在多智能体系统中,经验回放可以用来协调多个代理之间的行为。
- 在复杂的任务中,如游戏开发或机器人控制,经验回放可以帮助代理发现和利用潜在的模式和策略。
- 总结一下经验回放的重要性:
经验回放在强化学习中扮演着至关重要的角色。它不仅提高了学习的效率,使代理能够从有限的数据中提取更多的信息,还增强了代理在面对复杂环境和动态变化时的适应能力。通过这种方法,代理可以不断积累和应用知识,最终实现更为复杂和高级的任务目标。
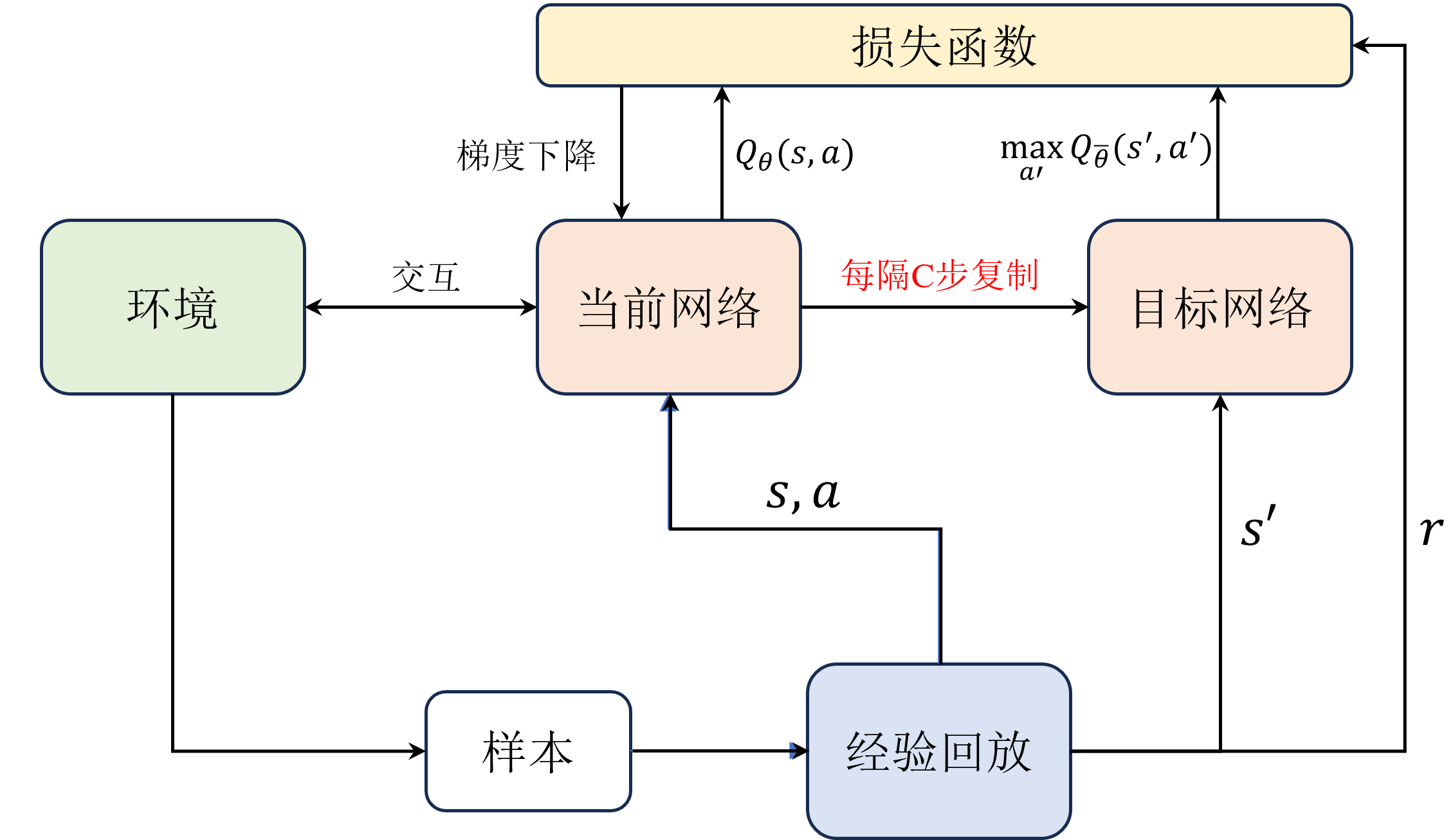
目标网络
目标网络的作用:在深度学习框架中,目标网络通常用于模仿或替代原始的网络结构,以便进行评估、优化或其他相关操作。具体来说,目标网络有以下几个主要作用:
- 评估网络性能:通过将当前网络的输出与目标网络的期望输出进行比较,可以评估网络的学习效果和性能。这种方法常用于梯度下降算法中的损失函数计算,帮助调整网络参数以最小化误差。
- 优化网络结构:在某些情况下,目标网络可能被用作优化网络结构的参考。例如,在迁移学习中,目标网络可以代表源域数据分布,而当前网络需要与之对齐,从而实现跨域适应。
- 辅助训练过程:目标网络还可以用于辅助训练过程,如提供正则ization(正则化)约束,防止网络过拟合。或者在分布式训练环境中,目标网络可以帮助协调各个节点的更新,确保全局一致性。
- 模拟真实环境:在仿真或测试环境中,目标网络可以模拟实际应用场景,为当前网络提供接近真实世界的输入和输出条件,检验其在现实情况下的表现。
- 对抗攻击防御:在对抗机器学习攻击的场景中,目标网络可以被用来检测和抵御 adversarial examples(对抗样本),提高模型的鲁棒性和安全性。
- 其他用途:除了上述主要作用外,目标网络还可以用于生成对抗样本、执行元学习任务等。
定义智能体
class Agent:
def __init__(self):
# 定义当前网络
self.policy_net = MLP(state_dim,action_dim).to(device)
# 定义目标网络
self.target_net = MLP(state_dim,action_dim).to(device)
# 将当前网络参数复制到目标网络中
self.target_net.load_state_dict(self.policy_net.state_dict())
# 定义优化器
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=learning_rate)
# 经验回放
self.memory = ReplayBuffer(buffer_size)
self.sample_count = 0 # 记录采样步数
def sample_action(self,state):
''' 采样动作,主要用于训练
'''
self.sample_count += 1
# epsilon 随着采样步数衰减
self.epsilon = self.epsilon_end + (self.epsilon_start - self.epsilon_end) * math.exp(-1. * self.sample_count / self.epsilon_decay)
if random.random() > self.epsilon:
with torch.no_grad(): # 不使用梯度
state = torch.tensor(np.array(state), device=self.device, dtype=torch.float32).unsqueeze(dim=0)
q_values = self.policy_net(state)
action = q_values.max(1)[1].item() # choose action corresponding to the maximum q value
else:
action = random.randrange(self.action_dim)
def predict_action(self,state):
''' 预测动作,主要用于测试
'''
with torch.no_grad():
state = torch.tensor(np.array(state), device=self.device, dtype=torch.float32).unsqueeze(dim=0)
q_values = self.policy_net(state)
action = q_values.max(1)[1].item() # choose action corresponding to the maximum q value
return action
def update(self):
pass
















 1671
1671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









