







目录
二、设置和安装Langchain-Chatchat及相关依赖
三、Xinference框架部署与大模型 & embidding模型加载
6.2 修改默认监听地址以允许远程访问(官方提供,我没用到)
前言
Home · chatchat-space/Langchain-Chatchat Wiki (github.com)
langchain-chatchat-0.3.0新版本相比于之前2.几的版本复杂些,部署的时候和启动方式都有一系列的改变,也遇到一些坑和解决办法,接下来就和我一步一步进行搭建。
一、本次基于AutoDl服务器实现部署
1.1 配置AutoDL环境
注册好autodl账户之后,开始在上面租服务器,地区我租的重庆A区的,GPU我选择的是RTX4090,基础镜像选择的是Pytorch-2.3.0-python-3.12(ubuntu22.04)- cuda版本12.1。

1.2 了解AutoDl学术加速的使用
在该项目中我并没有使用到,我是自己有挂一个VPN。有需要的话可以使用以下官方提供的方法进行文件的下载。
学术加速,提高在国外网站(github等学术网站)拉取文件的速度:
source /etc/network_turbo取消学术加速:
unset http_proxy && unset https_proxy
1.3 基于AutoDL的虚拟环境激活
对于一个全新的机子来说新建完虚拟环境无法做到直接激活,重新加载你的shell配置
输入以下指令:
source ~/.bashrcconda init二、设置和安装Langchain-Chatchat及相关依赖
1.打开终端从github上将新版本的项目拉取下来,指令如下
git clone https://github.com/chatchat-space/Langchain-Chatchat.git2.新建一个虚拟环境
conda create -n glm4_text python==3.11
3.对于一个全新的机子来说新建完虚拟环境无法做到直接激活,重新加载你的shell配置
输入以下指令:
source ~/.bashrcconda init4.关闭原来的终端,开启一个新终端开始激活新建好的环境
conda activate glm4_text5.安装 Langchain-Chatchat,从 0.3.0 版本起,Langchain-Chatchat 提供以 Python 库形式的安装方式,具体安装请执行:(请不要着急使用该命令,看下一条命令)
pip install langchain-chatchat -U -i https://pypi.tuna.tsinghua.edu.cn/simple6.因模型部署框架 Xinference 接入 Langchain-Chatchat 时需要额外安装对应的 Python 依赖库,因此如需搭配 Xinference 框架使用时,建议使用如下指令进行安装:(因为我使用的就是Xinference框架)
pip install langchain-chatchat[xinference] -U -i https://pypi.tuna.tsinghua.edu.cn/simple三、Xinference框架部署与大模型 & embidding模型加载
注:从 0.3.0 版本起,Langchain-Chatchat 不再根据用户输入的本地模型路径直接进行模型加载,涉及到的模型种类包括 LLM、Embedding、Reranker 及后续会提供支持的多模态模型等,均改为支持市面常见的各大模型推理框架接入,如 Xinference、Ollama、LocalAI、FastChat、One API 等。因此,请确认在启动 Langchain-Chatchat 项目前,首先进行模型推理框架的运行,并加载所需使用的模型。然后再正式启动 Langchain-Chatchat。
1.新开终端再次新建一个虚拟环境
conda create -n llm_tl python==3.11
2.开始激活新建好的环境
conda activate llm_tl
3.Xinference 在 Linux, Windows, MacOS 上都可以通过
pip来安装。如果需要使用 Xinference 进行模型推理,可以根据不同的模型指定不同的引擎。(我下载Xinference的时候是直接使用“pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple”进行安装,使用这一步骤安装成功后4-8步骤即可无需操作,直接跳转到9)
这一步骤请记得不要使用AutoDL中的无卡模式开机!不然会遇到进程杀死的错误!
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple运行上述指令时有可能会遇到以下错误:(我就遇到了以下错误)
ERROR: Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based projects
找了好多方法,后面发现查阅当前虚拟机的 g++ --version,如果高于10的话就需要降级到10。降级后重新运行即可成功!在创建的虚拟环境中更新需如下指令:
conda config --add channels conda-forge
conda install gxx_linux-64=10
pip install "xinference[all]" -i https://pypi.tuna.tsinghua.edu.cn/simple
(以上代码如果因为做了绿色标记复制有问题的话,可以找一个文本框粘贴后在进行复制。)
4.PyTorch(transformers) 引擎支持几乎有所的最新模型,这是 Pytorch 模型默认使用的引擎:
pip install "xinference[transformers]" -i https://pypi.tuna.tsinghua.edu.cn/simple5.安装 xinference 和 vLLM:
pip install "xinference[vllm]"6.Xinference 通过
llama-cpp-python支持gguf和ggml格式的模型。建议根据当前使用的硬件手动安装依赖,从而获得最佳的加速效果。初始步骤:
pip install xinference -i https://pypi.tuna.tsinghua.edu.cn/simple7.安装英伟达显卡:
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python -i https://pypi.tuna.tsinghua.edu.cn/simple8.SGLang 具有基于 RadixAttention 的高性能推理运行时。它通过在多个调用之间自动重用KV缓存,显著加速了复杂 LLM 程序的执行。它还支持其他常见推理技术,如连续批处理和张量并行处理。
pip install 'xinference[sglang]' -i https://pypi.tuna.tsinghua.edu.cn/simple9.本地运行Xinference,让我们以一个经典的大语言模型 glm4-9b-chat 来展示如何在本地用 Xinference 运行大模型,我这里自定义了一个存储日志文件和大模型,embidding模型的路径,如果不自定义一个路径将会下载到默认的一个路径下,这样很容易将我们的系统盘给撑爆,以魔塔社区下载模型为例。
XINFERENCE_HOME=/root/autodl-tmp/xinference XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997 10.新建一个终端依次输入如下代码:
(下载embidding模型,官方地址如下bge-large-zh-v1.5 — Xinference这里我选择的是bge-large-zh-v1.5)
xinference launch --model-name bge-large-zh-v1.5 --model-type embeddingxinference launch --model-engine vllm --model-name glm4-chat --size-in-billions 9 --model-format pytorch --quantization none11.以使用
--model-uid或者-u参数指定模型的 UID,如果没有指定,Xinference 会随机生成一个 ID,下面的命令就是手动指定了 ID 为glm4-chat :
xinference list
12.大模型下载好之后,让我们开始启动项目!
四、启动项目
1.切换成我们最开始新建的虚拟环境,在启动项目之前确保首先进行模型推理框架的运行,并加载所需使用的模型,查看与修改 Langchain-Chatchat 配置
(可以直接跳转到步骤7.)
chatchat-config --help这时会得到返回:
Usage: chatchat-config [OPTIONS] COMMAND [ARGS]...
指令` chatchat-config` 工作空间配置
Options:
--help Show this message and exit.
Commands:
basic 基础配置
kb 知识库配置
model 模型配置
server 服务配置2.可根据上述配置命令选择需要查看或修改的配置类型,以
基础配置为例,想要进行基础配置查看或修改时可以输入以下命令获取帮助信息:
chatchat-config basic --help这时会得到返回信息:
Usage: chatchat-config basic [OPTIONS]
基础配置
Options:
--verbose [true|false] 是否开启详细日志
--data TEXT 初始化数据存放路径,注意:目录会清空重建
--format TEXT 日志格式
--clear 清除配置
--show 显示配置
--help Show this message and exit.3.使用 chatchat-config 查看对应配置参数以
基础配置为例,可根据上述命令帮助内容确认,需要查看基础配置的配置参数,可直接输入:
chatchat-config basic --show在未进行配置项修改时,可得到默认配置内容如下:
{
"log_verbose": false,
"CHATCHAT_ROOT": "/root/anaconda3/envs/chatchat/lib/python3.11/site-packages/chatchat",
"DATA_PATH": "/root/anaconda3/envs/chatchat/lib/python3.11/site-packages/chatchat/data",
"IMG_DIR": "/root/anaconda3/envs/chatchat/lib/python3.11/site-packages/chatchat/img",
"NLTK_DATA_PATH": "/root/anaconda3/envs/chatchat/lib/python3.11/site-packages/chatchat/data/nltk_data",
"LOG_FORMAT": "%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s",
"LOG_PATH": "/root/anaconda3/envs/chatchat/lib/python3.11/site-packages/chatchat/data/logs",
"MEDIA_PATH": "/root/anaconda3/envs/chatchat/lib/python3.11/site-packages/chatchat/data/media",
"BASE_TEMP_DIR": "/root/anaconda3/envs/chatchat/lib/python3.11/site-packages/chatchat/data/temp",
"class_name": "ConfigBasic"
}4.使用 chatchat-config 修改对应配置参数,以修改
模型配置中默认llm模型为例,可以执行以下命令行查看配置项名称:
chatchat-config model --help这时会得到
Usage: chatchat-config model [OPTIONS]
模型配置
Options:
--default_llm_model TEXT 默认llm模型
--default_embedding_model TEXT 默认embedding模型
--agent_model TEXT agent模型
--history_len INTEGER 历史长度
--max_tokens INTEGER 最大tokens
--temperature FLOAT 温度
--support_agent_models TEXT 支持的agent模型
--set_model_platforms TEXT 模型平台配置 as a JSON string.
--set_tool_config TEXT 工具配置项 as a JSON string.
--clear 清除配置
--show 显示配置
--help Show this message and exit.5.可首先查看当前
模型配置的配置项:
chatchat-config model --show这时会得到:
{
"DEFAULT_LLM_MODEL": "glm4-chat",
"DEFAULT_EMBEDDING_MODEL": "bge-large-zh-v1.5",
"Agent_MODEL": null,
"HISTORY_LEN": 3,
"MAX_TOKENS": null,
"TEMPERATURE": 0.7,
...
"class_name": "ConfigModel"
}6.需要修改
默认llm模型为qwen2-instruct时,可执行:
chatchat-config model --default_llm_model qwen2-instruct7.初始化知识库(不初始化官方提供的知识库也没问题,后面直接在UI界面中操作自己的本地知识库就好!),可以直接跳转到步骤11.启动项目。
chatchat-kb -r8.初始化知识库最常见的报错信息是
Traceback (most recent call last):
File "/Users/hkk/Amap/ai/Langchain-Chatchat/myenv/lib/python3.8/site-packages/chatchat/init_database.py", line 156, in main
folder2db(kb_names=args.kb_name, mode="recreate_vs", embed_model=args.embed_model)
File "/Users/hkk/Amap/ai/Langchain-Chatchat/myenv/lib/python3.8/site-packages/chatchat/server/knowledge_base/migrate.py", line 130, in folder2db
kb.create_kb()
File "/Users/hkk/Amap/ai/Langchain-Chatchat/myenv/lib/python3.8/site-packages/chatchat/server/knowledge_base/kb_service/base.py", line 80, in create_kb
self.do_create_kb()
File "/Users/hkk/Amap/ai/Langchain-Chatchat/myenv/lib/python3.8/site-packages/chatchat/server/knowledge_base/kb_service/faiss_kb_service.py", line 51, in do_create_kb
self.load_vector_store()
File "/Users/hkk/Amap/ai/Langchain-Chatchat/myenv/lib/python3.8/site-packages/chatchat/server/knowledge_base/kb_service/faiss_kb_service.py", line 28, in load_vector_store
return kb_faiss_pool.load_vector_store(kb_name=self.kb_name,
File "/Users/hkk/Amap/ai/Langchain-Chatchat/myenv/lib/python3.8/site-packages/chatchat/server/knowledge_base/kb_cache/faiss_cache.py", line 132, in load_vector_store
raise RuntimeError(f"向量库 {kb_name} 加载失败。")
RuntimeError: 向量库 samples 加载失败。9.遇到类似加载向量库失败的报错,缺少一个faiss这个包,这个时候需要再安装一个faiss的包
pip install faiss-cpu==1.7.4pip install rank_bm25 -i https://mirrors.aliyun.com/pypi/simple10.出现以下日志即为成功:
----------------------------------------------------------------------------------------------------
知识库名称 :samples
知识库类型 :faiss
向量模型: :bge-large-zh-v1.5
知识库路径 :/root/anaconda3/envs/chatchat/lib/python3.11/site-packages/chatchat/data/knowledge_base/samples
文件总数量 :45
入库文件数 :45
知识条目数 :1390
用时 :0:19:31.113864
----------------------------------------------------------------------------------------------------
总计用时 :0:19:31.159014
(glm4_text)root@autodl-container-488144a6d4-859a933e:~/Langchain-Chatchat#
11.启动项目
chatchat -a12.出现以下界面即为启动成功:


13.常规万能对话与本地知识库对话测试
常规万能对话测试:效果挺不错的。

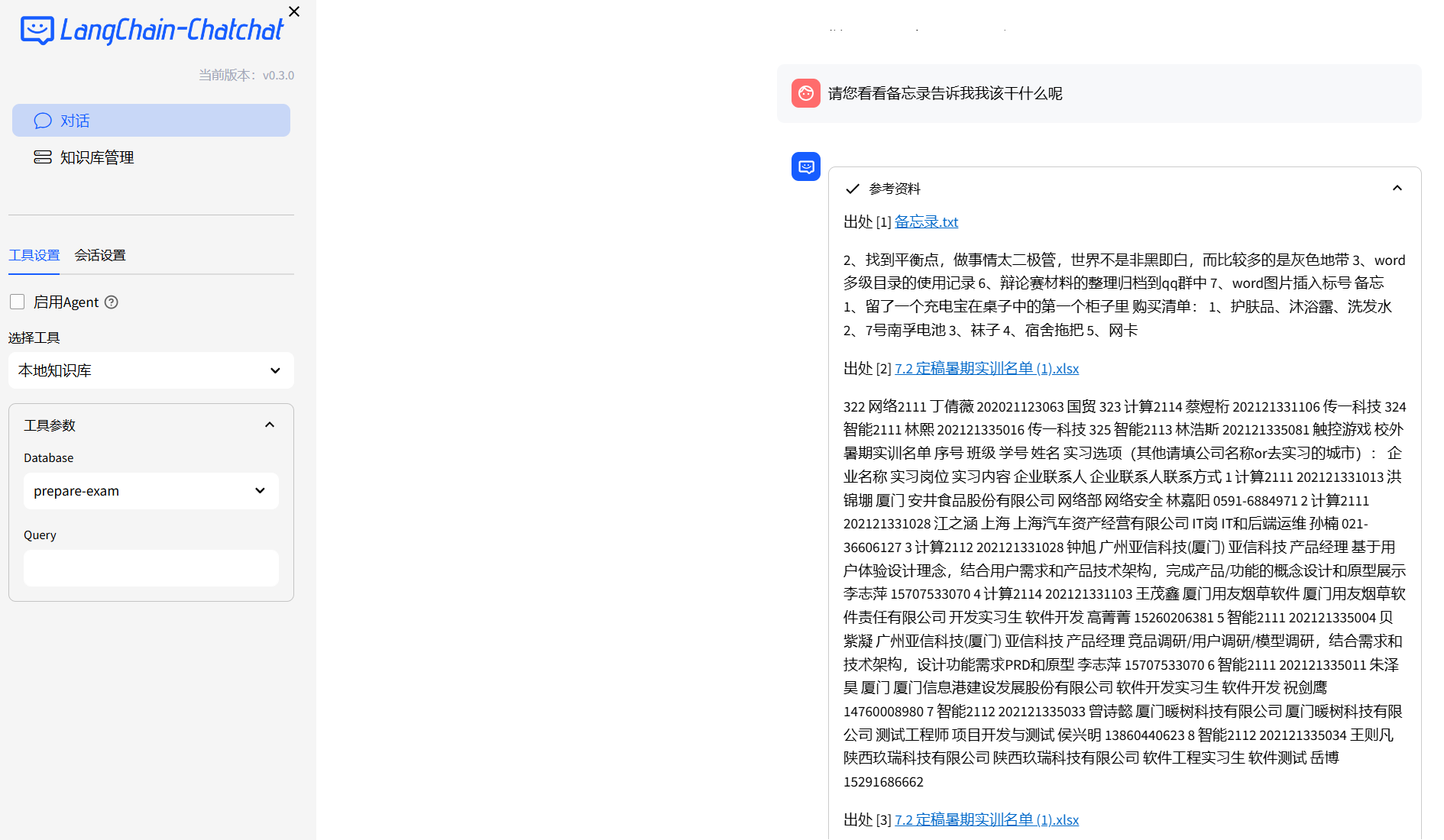
基于本地知识库进行对话测试: 效果也不错!


点开参考资料,显示信息如下。

五、再次启动项目
前言:当我们关掉服务器之后,再次开机的时候,这时候我们需要在启动项目前先将xinference上的大模型和embidding模型启动起来,再次启动项目,否则项目启动起来会报错。
新建第一个终端
conda activate llm_tlXINFERENCE_HOME=/root/autodl-tmp/xinference XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 9997 新建第二个终端
conda activate llm_tl
xinference launch --model-name bge-large-zh-v1.5 --model-type embedding
xinference launch --model-engine vllm --model-name glm4-chat --size-in-billions 9 --model-format pytorch --quantization none新建第三个终端
conda activate glm4_textchatchat -a六、注意事项
6.1 使用AutoDL代理工具访问虚拟机中的服务(强推)
由于 chatchat-config server 配置默认监听地址
DEFAULT_BIND_HOST为 127.0.0.1, 所以无法通过其他 ip 进行访问。那我们在虚拟机中配置这个项目的话,该如何通过本机访问这个网址呢?
答:在AutoDL中官方是有提供一个工具(ssh隧道映射工具)可以让我们高效解决这个问题,在该工具中输入需要监听的虚拟机账号信息以及代理端口后,点击开始代理。代理完成后直接点击网址即可成功访问该网址!

6.2 修改默认监听地址以允许远程访问(官方提供,我没用到)
由于 chatchat-config server 配置默认监听地址 DEFAULT_BIND_HOST 为 127.0.0.1, 所以无法通过其他 ip 进行访问。
如需修改请参考以下方式:
shell chatchat-config server --show这时会得到
{
"HTTPX_DEFAULT_TIMEOUT": 300.0,
"OPEN_CROSS_DOMAIN": true,
"DEFAULT_BIND_HOST": "127.0.0.1",
"WEBUI_SERVER_PORT": 8501,
"API_SERVER_PORT": 7861,
"WEBUI_SERVER": {
"host": "127.0.0.1",
"port": 8501
},
"API_SERVER": {
"host": "127.0.0.1",
"port": 7861
},
"class_name": "ConfigServer"
}
如需通过机器ip 进行访问(如 Linux 系统), 需要将监听地址修改为 0.0.0.0。
chatchat-config server --default_bind_host=0.0.0.0
这时会得到
{
"HTTPX_DEFAULT_TIMEOUT": 300.0,
"OPEN_CROSS_DOMAIN": true,
"DEFAULT_BIND_HOST": "0.0.0.0",
"WEBUI_SERVER_PORT": 8501,
"API_SERVER_PORT": 7861,
"WEBUI_SERVER": {
"host": "0.0.0.0",
"port": 8501
},
"API_SERVER": {
"host": "0.0.0.0",
"port": 7861
},
"class_name": "ConfigServer"
}七、参考文章
langchain-chatchat-0.3.0小白保姆部署指南_langchain-chatchat 0.3-CSDN博客




















 1987
1987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











