







一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
counts = df[“zipcode”].value_counts().tolist()
loop over each of the unique zip codes and their corresponding
count
for (zipcode, count) in zip(zipcodes, counts):
the zip code counts for our housing dataset is extremely
unbalanced (some only having 1 or 2 houses per zip code)
so let’s sanitize our data by removing any houses with less
than 25 houses per zip code
if count < 25:
idxs = df[df[“zipcode”] == zipcode].index
df.drop(idxs, inplace=True)
return the data frame
return df
在剩下的几行中,我们:
-
确定唯一的邮政编码集,然后计算每个唯一邮政编码的数据点数。
-
过滤掉计数低的邮政编码。 对于某些邮政编码,我们只有一两个数据点,这使得获得准确的房价估算即使并非不可能,也极具挑战性。
-
将数据返回给调用函数。
现在让我们创建用于预处理数据的 process_house_attributes 函数:
def process_house_attributes(df, train, test):
initialize the column names of the continuous data
continuous = [“bedrooms”, “bathrooms”, “area”]
performin min-max scaling each continuous feature column to
the range [0, 1]
cs = MinMaxScaler()
trainContinuous = cs.fit_transform(train[continuous])
testContinuous = cs.transform(test[continuous])
我们定义函数。 process_house_attributes 函数接受三个参数:
-
df :pandas 生成的我们的数据框(前面的函数帮助我们从数据框中删除一些记录)
-
train :我们针对房价数据集的训练数据
-
test :我们的测试数据。
然后,我们定义了连续数据的列,包括卧室、浴室和房屋大小。
我们将采用这些值并使用 sklearn-learn 的 MinMaxScaler 将连续特征缩放到范围 [0, 1]。 现在我们需要预处理我们的分类特征,即邮政编码:
one-hot encode the zip code categorical data (by definition of
one-hot encoing, all output features are now in the range [0, 1])
zipBinarizer = LabelBinarizer().fit(df[“zipcode”])
trainCategorical = zipBinarizer.transform(train[“zipcode”])
testCategorical = zipBinarizer.transform(test[“zipcode”])
construct our training and testing data points by concatenating
the categorical features with the continuous features
trainX = np.hstack([trainCategorical, trainContinuous])
testX = np.hstack([testCategorical, testContinuous])
return the concatenated training and testing data
return (trainX, testX)
首先,我们将对邮政编码进行one-hot编码。
然后,我们将使用 NumPy 的 hstack 函数将分类特征与连续特征连接起来,将生成的训练和测试集作为元组返回。 请记住,现在我们的分类特征和连续特征都在 [0, 1] 范围内。
===================================================================
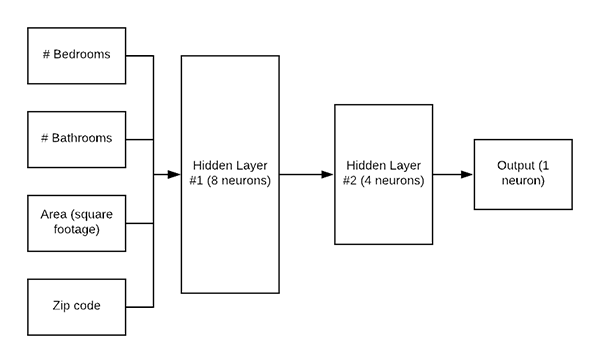
图 5:我们的 Keras 回归架构。 网络的输入是一个数据点,包括家庭的#卧室、#浴室、面积/平方英尺和邮政编码。 网络的输出是具有线性激活函数的单个神经元。 线性激活允许神经元输出房屋的预测价格。
在我们训练 Keras 网络进行回归之前,我们首先需要定义架构本身。 今天我们将使用一个简单的多层感知器 (MLP),如图 5 所示。 打开models.py文件并插入以下代码:
import the necessary packages
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Activation
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Input
from tensorflow.keras.models import Model
def create_mlp(dim, regress=False):
define our MLP network
model = Sequential()
model.add(Dense(8, input_dim=dim, activation=“relu”))
model.add(Dense(4, activation=“relu”))
check to see if the regression node should be added
if regress:
model.add(Dense(1, activation=“linear”))
return our model
return model
首先,我们将从 Keras 导入所有必要的模块。通过编写一个名为 create_mlp 的函数来定义 MLP 架构。 该函数接受两个参数: dim : 定义我们的输入维度 regress : 一个布尔值,定义是否应该添加我们的回归神经元 我们将继续使用dim-8-4架构开始构建我们的MLP。 如果我们正在执行回归,我们会添加一个 Dense 层,其中包含一个具有线性激活函数的神经元。 通常我们使用基于 ReLU 的激活,但由于我们正在执行回归,我们需要一个线性激活。 最后,返回模型。
=======================================================================
现在是时候把所有的部分放在一起了!
打开 mlp_regression.py 文件并插入以下代码:
import the necessary packages
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
from pyimagesearch import datasets
from pyimagesearch import models
import numpy as np
import argparse
import locale
import os
construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument(“-d”, “–dataset”, type=str, required=True,
help=“path to input dataset of house images”)
args = vars(ap.parse_args())
我们首先导入必要的包、模块和库。
我们的脚本只需要一个命令行参数 --dataset。 当您在终端中运行训练脚本时,您需要提供 --dataset 开关和数据集的实际路径。
让我们加载房屋数据集属性并构建我们的训练和测试分割:
construct the path to the input .txt file that contains information
on each house in the dataset and then load the dataset
print(“[INFO] loading house attributes…”)
inputPath = os.path.sep.join([args[“dataset”], “HousesInfo.txt”])
df = datasets.load_house_attributes(inputPath)
construct a training and testing split with 75% of the data used
for training and the remaining 25% for evaluation
print(“[INFO] constructing training/testing split…”)
(train, test) = train_test_split(df, test_size=0.25, random_state=42)
使用我们方便的 load_house_attributes 函数,并通过将 inputPath 传递给数据集本身,我们的数据被加载到内存中。
训练集和测试集按照4:1切分。 让我们扩展我们的房价数据:
find the largest house price in the training set and use it to
scale our house prices to the range [0, 1] (this will lead to
better training and convergence)
maxPrice = train[“price”].max()
trainY = train[“price”] / maxPrice
testY = test[“price”] / maxPrice
如评论中所述,将我们的房价缩放到 [0, 1] 范围将使我们的模型更容易训练和收敛。 将输出目标缩放到 [0, 1] 将减少我们的输出预测范围(相对于 [0, maxPrice ]),不仅使我们的网络训练更容易、更快,而且使我们的模型能够获得更好的结果。 因此,我们获取训练集中的最高价格,并相应地扩展我们的训练和测试数据。 现在让我们处理房屋属性:
process the house attributes data by performing min-max scaling
on continuous features, one-hot encoding on categorical features,
and then finally concatenating them together
print(“[INFO] processing data…”)
(trainX, testX) = datasets.process_house_attributes(df, train, test)
从 datasets.py 脚本中回忆 process_house_attributes 函数:
-
预处理我们的分类和连续特征。
-
通过最小-最大缩放将我们的连续特征缩放到范围 [0, 1]。
-
One-hot 编码我们的分类特征。
-
连接分类特征和连续特征以形成最终特征向量。
现在让我们继续训练MLP模型:
create our MLP and then compile the model using mean absolute
percentage error as our loss, implying that we seek to minimize
the absolute percentage difference between our price predictions
and the actual prices
model = models.create_mlp(trainX.shape[1], regress=True)
opt = Adam(lr=1e-3, decay=1e-3 / 200)
model.compile(loss=“mean_absolute_percentage_error”, optimizer=opt)
train the model
print(“[INFO] training model…”)
model.fit(x=trainX, y=trainY,
validation_data=(testX, testY),
epochs=200, batch_size=8)
我们的模型用 Adam 优化器初始化,然后compile。 请注意,我们使用平均绝对百分比误差作为我们的损失函数,这表明我们寻求最小化预测价格和实际价格之间的平均百分比差异。
训练。
训练完成后,我们可以评估我们的模型并总结我们的结果:
make predictions on the testing data
print(“[INFO] predicting house prices…”)
preds = model.predict(testX)
compute the difference between the predicted house prices and the
actual house prices, then compute the percentage difference and
the absolute percentage difference
diff = preds.flatten() - testY
percentDiff = (diff / testY) * 100
absPercentDiff = np.abs(percentDiff)
compute the mean and standard deviation of the absolute percentage
difference
mean = np.mean(absPercentDiff)
std = np.std(absPercentDiff)
finally, show some statistics on our model
locale.setlocale(locale.LC_ALL, “en_US.UTF-8”)
print(“[INFO] avg. house price: {}, std house price: {}”.format(
locale.currency(df[“price”].mean(), grouping=True),
locale.currency(df[“price”].std(), grouping=True)))
print(“[INFO] mean: {:.2f}%, std: {:.2f}%”.format(mean, std))
第 57 行指示 Keras 对我们的测试集进行预测。
使用预测,我们计算:
-
预测房价与实际房价之间的差异。
-
百分比差异。
-
绝对百分比差异。
-
计算绝对百分比差异的均值和标准差。
-
结果打印。
使用 Keras 进行回归并没有那么难,对吧? 让我们训练模型并分析结果!
=====================================================================

图 6: Keras 回归模型采用四个数值输入,产生一个数值输出:房屋的预测值。
打开一个终端并提供以下命令(确保 --dataset 命令行参数指向您下载房价数据集的位置):
$ python mlp_regression.py --dataset Houses-dataset/Houses\ Dataset/
[INFO] loading house attributes…
[INFO] constructing training/testing split…
[INFO] processing data…
[INFO] training model…
Epoch 1/200
34/34 [==============================] - 0s 4ms/step - loss: 73.0898 - val_loss: 63.0478
Epoch 2/200
34/34 [==============================] - 0s 2ms/step - loss: 58.0629 - val_loss: 56.4558
Epoch 3/200
34/34 [==============================] - 0s 1ms/step - loss: 51.0134 - val_loss: 50.1950
Epoch 4/200
34/34 [==============================] - 0s 1ms/step - loss: 47.3431 - val_loss: 47.6673
Epoch 5/200
34/34 [==============================] - 0s 1ms/step - loss: 45.5581 - val_loss: 44.9802
Epoch 6/200
34/34 [==============================] - 0s 1ms/step - loss: 42.4403 - val_loss: 41.0660
Epoch 7/200
34/34 [==============================] - 0s 1ms/step - loss: 39.5451 - val_loss: 34.4310
Epoch 8/200
34/34 [==============================] - 0s 2ms/step - loss: 34.5027 - val_loss: 27.2138
Epoch 9/200
34/34 [==============================] - 0s 2ms/step - loss: 28.4326 - val_loss: 25.1955
Epoch 10/200
34/34 [==============================] - 0s 2ms/step - loss: 28.3634 - val_loss: 25.7194
…
Epoch 195/200
34/34 [==============================] - 0s 2ms/step - loss: 20.3496 - val_loss: 22.2558
Epoch 196/200
34/34 [==============================] - 0s 2ms/step - loss: 20.4404 - val_loss: 22.3071
Epoch 197/200
34/34 [==============================] - 0s 2ms/step - loss: 20.0506 - val_loss: 21.8648
Epoch 198/200
34/34 [==============================] - 0s 2ms/step - loss: 20.6169 - val_loss: 21.5130
Epoch 199/200
34/34 [==============================] - 0s 2ms/step - loss: 19.9067 - val_loss: 21.5018
Epoch 200/200
34/34 [==============================] - 0s 2ms/step - loss: 19.9570 - val_loss: 22.7063
[INFO] predicting house prices…
[INFO] avg. house price: $533,388.27, std house price: $493,403.08
[INFO] mean: 22.71%, std: 18.26%
从我们的输出中可以看出,我们最初的平均绝对百分比误差高达 73%,然后迅速下降到 30% 以下。
当我们完成训练时,我们可以看到我们的网络开始有点过拟合了。 我们的训练损失低至~20%; 然而,我们的验证损失约为 23%。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1514
1514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









