







我们需要解决以下两个问题:
给出二叉树的前序遍历和中序遍历,构建二叉树
给出二叉树的中序遍历和后序遍历,构建二叉树
可行性分析:
中序遍历的访问顺序是"左子树->根节点->右子树"
所以说给出前序或者后序遍历顺序,我们可以找到其对应的节点在中序遍历的位置从而可以得到它的左子树和右子树(左子树在该节点在中序遍历对应点的位置的左边,右子树位于对应位置的右边)
下面思考一个问题:给出前序遍历和后序遍历序列,能否推断出二叉树?
答案是否定的,因为缺少了中序序列我们无从推断一个节点的左右子树的顺序,很容易可以举出反例
给定前序遍历顺序:1,2,3
后序遍历序列:3,2,1
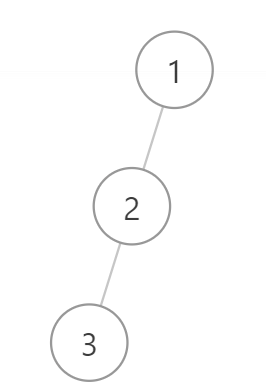

这两颗二叉树的前序遍历和后序遍历都是相同的,但是我们确很轻松的可以举出多种满足的二叉树(你甚至可以举出更多,…很多很多的例子)
思路
下面我们以从前序和中序遍历推断二叉树为例看看如何实现
105. 从前序与中序遍历序列构造二叉树
我们再次回到前序遍历和中序遍历的访问顺序这一问题。
一个元素首先肯定是先出现在前序遍历中再出现在中序遍历中,但是中序遍历的一个节点可以确定它的两颗子树的顺序:
- 该节点的左子树的中序遍历的序列位于该节点原中序遍历序列的左边,
- 右子树的中序遍历序列位于该节点原中序遍历序列的右边。(因为中序序列的顺序是先左子树再到当前节点再到右子树)
那么它的左右子树的前序序列的范围我们能否推断呢?
首先我们可以计算出该节点的左子树的节点个数,于是为了在前序序列中得以保证访问到左子树的所有节点,我们可以先忽略它在序列中的顺序,得出一个范围,由于在前序序列中都被先访问到,所以左子树的前序序列的终点是到当前的根节点加上左子树的节点个数。
同理为了得到它右子树的前序序列的范围,我们需要从该节点在前序序列中的位置后开始寻找,其终点不变。
实现
其实这个问题最难的就在于代码部分,通过手写画图我们是可以推断出比较少的节点的二叉树的,但是要在计算机上解决这个问题,我们需要不断拆解子问题,递归调用函数来实现。
我们的函数应该包括这几个参数
- 前序遍历的起点 l 1 l1 l1
- 前序遍历的终点 r 1 r1 r1
- 中序遍历的起点 l 2 l2 l2
- 中序遍历的终点 r 2 r2 r2
但我们始终使用前序遍历的第一个点作为根节点的
- 找到当前节点(根节点,这里是在先序遍历的第一个元素上)对应在中序遍历序列中的位置
- 建立一个节点将其存储
- 计算该节点的左子树的节点数量
左节点数量 = 中序序列中头节点对应位置 − 中序序列起始位置 左节点数量=中序序列中头节点对应位置-中序序列起始位置 左节点数量=中序序列中头节点对应位置−中序序列起始位置 - 创建左子树,更新序列起始位置
- 创建右子树(在下面这种写法中顺序可以对调)
- 返回根节点
106. 从中序与后序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:
输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
提示:
1 <= preorder.length <= 3000
inorder.length == preorder.length
-3000 <= preorder[i], inorder[i] <= 3000
preorder 和 inorder 均 无重复 元素
inorder 均出现在 preorder
preorder 保证 为二叉树的前序遍历序列
inorder 保证 为二叉树的中序遍历序列
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
unordered_map<int,int> ump;
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder)
{
for (int i=0;i<inorder.size();i++)
{
ump[inorder[i]]=i; //建立哈希表加速查找过程
}
return build(0,inorder.size()-1,0,inorder.size()-1,preorder,inorder);//调用递归函数
}
TreeNode *build(int l1,int r1,int l2,int r2,vector<int> &preorder,vector<int> &inorder)
{
if (r2<l2)
return nullptr;
int pos=ump[preorder[l1]];
int len=pos-l2; //计算左节点个数
TreeNode *cur=new TreeNode(preorder[l1]);
cur->left=build(l1+1,l1+len,l2,pos-1,preorder,inorder);
cur->right=build(l1+len+1,l2,pos+1,r2,preorder,inorder);
return cur;
}
};
我们还可以通过先创建左子树的方法来减少递归函数需要的信息,思路就是我们用一个全局变量来表示创建的根节点,始终是从前序遍历按照从左到右的顺序来创建的,每次创建全局变量加一,这样只需记录中序遍历的区间范围就可以了,能减少一定的时间和空间。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
unordered_map<int,int> ump;
int idx=0;
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder)
{
for (int i=0;i<inorder.size();i++)
{
ump[inorder[i]]=i;
}
return build(0,inorder.size()-1,preorder,inorder);
}
TreeNode *build(int l,int r,vector<int> &preorder,vector<int> &inorder)
{
if (r<l)
return nullptr;
int pos=ump[preorder[idx]];
TreeNode *cur=new TreeNode(preorder[idx]);
idx++;
cur->left=build(l,pos-1,preorder,inorder);
cur->right=build(pos+1,r,preorder,inorder);
return cur;
}
};
练习
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
思路与从前序和中序推断类似,我们只需要找清楚中序和后序序列中节点元素的出现的先后顺序然后进行递归调用。根据后序遍历先访问左子树然后右子树最后根节点,我们以后续遍历中最右边的一个元素作为节点去寻找在中序遍历中的位置,然后类似的,后序遍历中的左子树也要比右子树更早的出现我们可以通过左子树节点个数确定后序遍历的范围,进行递归调用。
如果要省去函数中后序遍历的范围用全局变量替代的话,我们必须要先建右子树,因为将后序遍历翻转后可以看到右子树中的元素是先出现的。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
int n=inorder.size();
return build(0,n-1,0,n-1,inorder,postorder);
}
TreeNode *build(int l1,int r1,int l2,int r2,vector<int> &inorder,vector<int> &postorder)
{
if (r1<l1)
return nullptr;
int pos=0,root=postorder[r2];
for (int i=l1;i<=r1;i++)
{
if (inorder[i]==root)
{
pos=i;
break;
}
}
int len=pos-l1;
TreeNode *cur=new TreeNode(inorder[pos]);
cur->left=build(l1,pos-1,l2,l2+len-1,inorder,postorder);
cur->right=build(pos+1,r1,l2+len,r2-1,inorder,postorder);
return cur;
}
};
总结
解决这个问题的关键就是要搞清楚三种遍历方式中元素的出现顺序,这样我们才能确定需要在函数中传递的参数的范围从而正确的写出递归函数。同时我们应该认识到,无论是哪种遍历方式,左子树中的元素总是比右子树中的元素更早的出现的!而中序遍历可以确定一个节点的左右子树!














 49
49











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









