







现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
“approved”:false,
“assistAwardInfo”:{
“avatar”:“”,
“celebrityId”:0,
“celebrityName”:“”,
“rank”:0,
“title”:“”
},
“authInfo”:“”,
“cityName”:“贵阳”,
“content”:“必须十分,借钱都要看的一部电影。”,
“filmView”:false,
“id”:1045570589,
“isMajor”:false,
“juryLevel”:0,
“majorType”:0,
“movieId”:1208282,
“nick”:“nick”,
“nickName”:“nickName”,
“oppose”:0,
“pro”:false,
“reply”:0,
“score”:5,
“spoiler”:0,
“startTime”:“2018-11-22 23:52:58”,
“supportComment”:true,
“supportLike”:true,
“sureViewed”:1,
“tagList”:{
“fixed”:[
{
“id”:1,
“name”:“好评”
},
{
“id”:4,
“name”:“购票”
}
]
},
“time”:“2018-11-22 23:52”,
“userId”:1871534544,
“userLevel”:2,
“videoDuration”:0,
“vipInfo”:“”,
“vipType”:0
}
]
}
如此多的数据,我们感兴趣的只有以下这几个字段:
nickName, cityName, content, startTime, score
接下来,进行我们比较重要的数据处理,从拿到的 JSON 数据中解析出需要的字段:
def parseInfo(data):
data = json.loads(html)[‘cmts’]
for item in data:
yield{
‘date’:item[‘startTime’],
‘nickname’:item[‘nickName’],
‘city’:item[‘cityName’],
‘rate’:item[‘score’],
‘conment’:item[‘content’]
}
拿到数据后,我们就可以开始数据分析了。但是为了避免频繁地去猫眼请求数据,需要将数据存储起来,在这里,笔者使用的是 SQLite3,放到数据库中,更加方便后续的处理。存储数据的代码如下:
def saveCommentInfo(moveId, nikename, comment, rate, city, start_time)
conn = sqlite3.connect(‘unknow_name.db’)
conn.text_factory=str
cursor = conn.cursor()
ins=“insert into comments values (?,?,?,?,?,?)”
v = (moveId, nikename, comment, rate, city, start_time)
cursor.execute(ins,v)
cursor.close()
conn.commit()
conn.close()
因为前文我们是使用数据库来进行数据存储的,因此可以直接使用 SQL 来查询自己想要的结果,比如评论前五的城市都有哪些:
SELECT city, count(*) rate_count FROM comments GROUP BY city ORDER BY rate_count DESC LIMIT 5
结果如下:
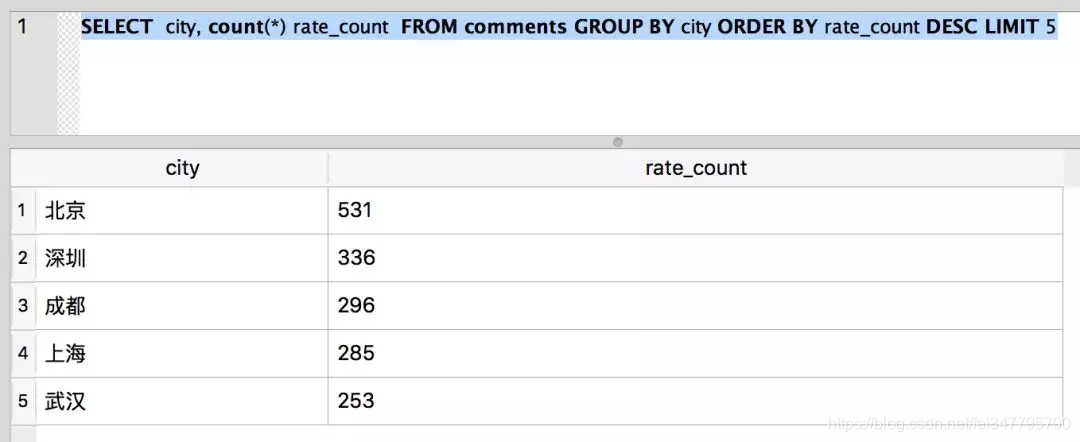
从上面的数据, 我们可以看出来,来自北京的评论数最多。
不仅如此,还可以使用更多的 SQL 语句来查询想要的结果。比如每个评分的人数、所占的比例等。如笔者有兴趣,可以尝试着去查询一下数据,就是如此地简单。
而为了更好地展示数据,我们使用 Pyecharts 这个库来进行数据可视化展示。
根据从猫眼拿到的数据,按照地理位置,直接使用 Pyecharts 来在中国地图上展示数据:
data = pd.read_csv(f,sep=‘{’,header=None,encoding=‘utf-8’,names=[‘date’,‘nickname’,‘city’,‘rate’,‘comment’])
city = data.groupby([‘city’])
city_com = city[‘rate’].agg([‘mean’,‘count’])
city_com.reset_index(inplace=True)
data_map = [(city_com[‘city’][i],city_com[‘count’][i]) for i in range(0,city_com.shape[0])]
geo = Geo(“GEO 地理位置分析”,title_pos = “center”,width = 1200,height = 800)
while True:
try:
attr,val = geo.cast(data_map)
geo.add(“”,attr,val,visual_range=[0,300],visual_text_color=“#fff”,
symbol_size=10, is_visualmap=True,maptype=‘china’)
except ValueError as e:
e = e.message.split("No coordinate is specified for ")[1]
data_map = filter(lambda item: item[0] != e, data_map)
else :
break
geo.render(‘geo_city_location.html’)
注:使用 Pyecharts 提供的数据地图中,有一些猫眼数据中的城市找不到对应的从标,所以在代码中,GEO
添加出错的城市,我们将其直接删除,过滤掉了不少的数据。
使用 Python,就是如此简单地生成了如下地图:
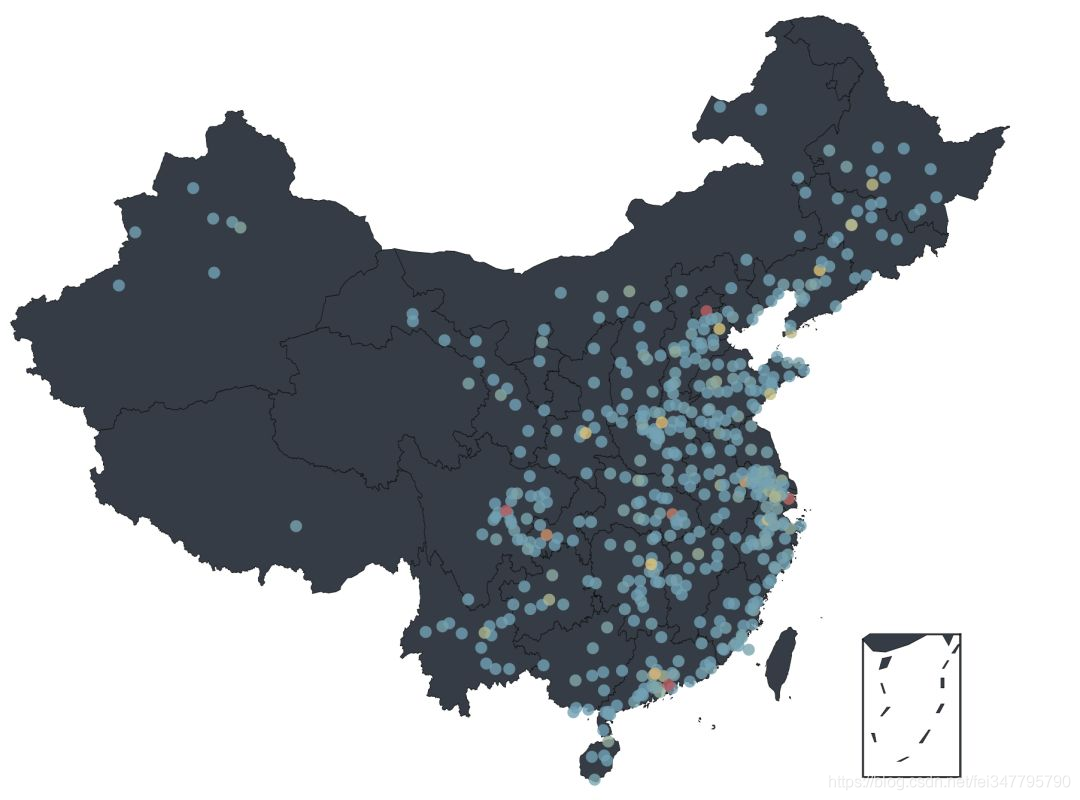
从可视化数据中可以看出,既看电影又评论的人群主要分布在中国东部,又以北京、上海、成都、深圳最多。虽然能从图上看出来很多数据,但还是不够直观,如果想看到每个省/市的分布情况,我们还需要进一步处理数据。
而在从猫眼中拿到的数据中,城市包含数据中具备县城的数据,所以需要将拿到的数据做一次转换,将所有的县城转换到对应省市里去,然后再将同一个省市的评论数量相加,得到最后的结果。
data = pd.read_csv(f,sep=‘{’,header=None,encoding=‘utf-8’,names=[‘date’,‘nickname’,‘city’,‘rate’,‘comment’])
city = data.groupby([‘city’])
city_com = city[‘rate’].agg([‘mean’,‘count’])
city_com.reset_index(inplace=True)
fo = open(“citys.json”,‘r’)
citys_info = fo.readlines()
citysJson = json.loads(str(citys_info[0]))
data_map_all = [(getRealName(city_com[‘city’][i], citysJson),city_com[‘count’][i]) for i in range(0,city_com.shape[0])]
data_map_list = {}
for item in data_map_all:
if data_map_list.has_key(item[0]):
value = data_map_list[item[0]]
value += item[1]
data_map_list[item[0]] = value
else:
data_map_list[item[0]] = item[1]
data_map = [(realKeys(key), data_map_list[key] ) for key in data_map_list.keys()]
def getRealName(name, jsonObj):
for item in jsonObj:
if item.startswith(name) :
return jsonObj[item]
return name
def realKeys(name):
return name.replace(u"省", “”).replace(u"市", “”)
.replace(u"回族自治区", “”).replace(u"维吾尔自治区", “”)
.replace(u"壮族自治区", “”).replace(u"自治区", “”)
经过上面的数据处理,使用 Pyecharts 提供的 map 来生成一个按省/市来展示的地图:
def generateMap(data_map):
map = Map(“城市评论数”, width= 1200, height = 800, title_pos=“center”)
while True:
try:
attr,val = geo.cast(data_map)
map.add(“”,attr,val,visual_range=[0,800],
visual_text_color=“#fff”,symbol_size=5,
is_visualmap=True,maptype=‘china’,
is_map_symbol_show=False,is_label_show=True,is_roam=False,
)
except ValueError as e:
e = e.message.split("No coordinate is specified for ")[1]
data_map = filter(lambda item: item[0] != e, data_map)
else :
break
map.render(‘city_rate_count.html’)
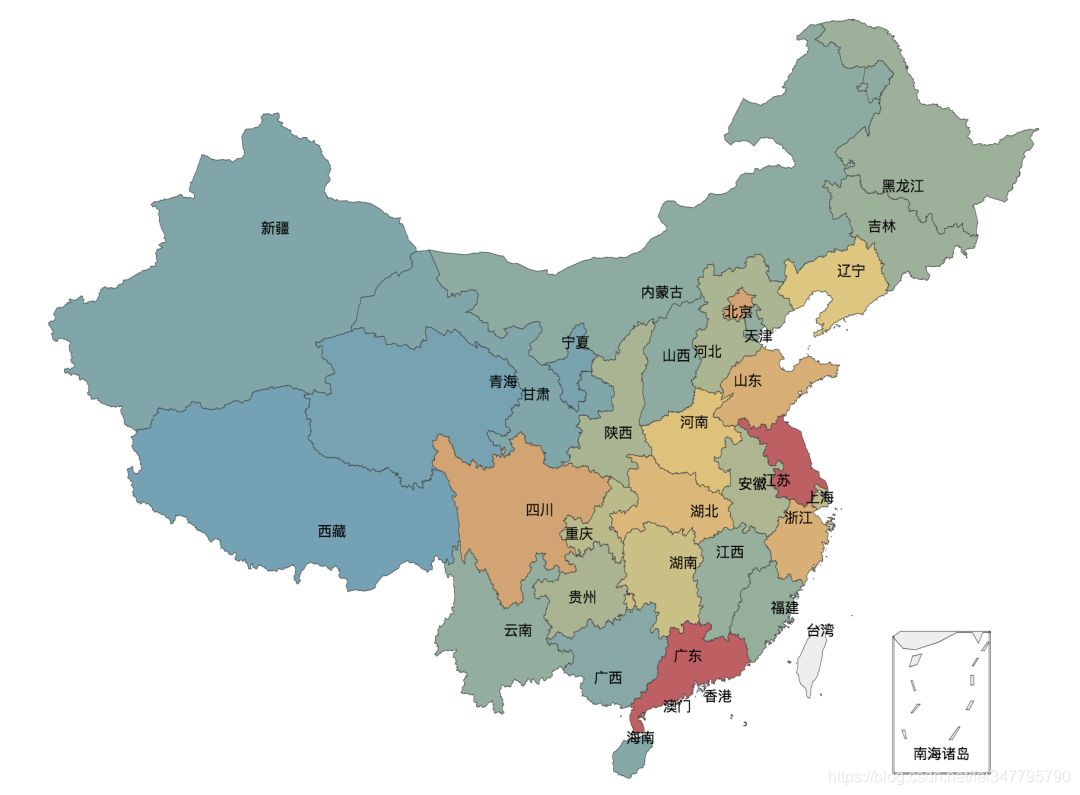
当然,我们还可以来可视化一下每一个评分的人数,这个地方采用柱状图来显示:
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









