







随机森林(Random Forest):机器学习中的经典算法
引言
随机森林(Random Forest)是一种基于决策树的集成学习算法,由Leo Breiman和Adele Cutler于2001年提出。它通过构建多棵决策树并将它们的预测结果进行集成,显著提高了模型的准确性和鲁棒性。随机森林因其出色的性能、易于实现和解释性强的特点,成为机器学习领域中最经典和广泛应用的算法之一。本文将从随机森林的基本概念、数学原理、训练方法、评估指标、应用场景及其优缺点等方面进行详细探讨,并结合具体实例帮助读者深入理解这一算法。
一、什么是随机森林?
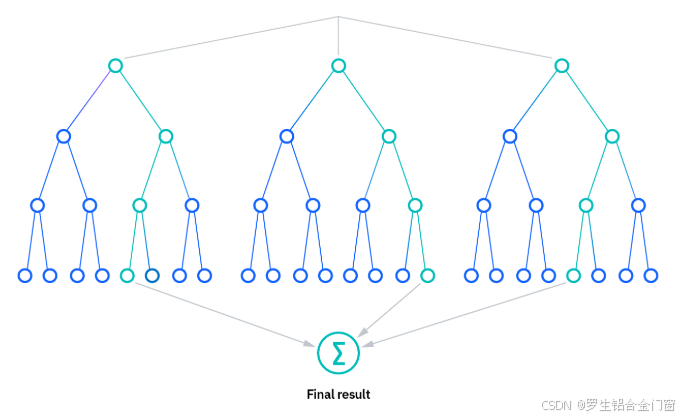
随机森林是一种集成学习方法,其核心思想是通过构建多棵决策树并将它们的预测结果进行集成(如投票或平均),从而得到最终的预测结果。随机森林的名称来源于两个方面:
- 随机性:在构建每棵决策树时,随机森林引入了两种随机性:一是从训练数据中随机抽取样本(Bootstrap采样),二是从特征集中随机选择部分特征进行节点分裂。
- 森林:随机森林由多棵决策树组成,这些树共同构成一个“森林”。
随机森林算法有三个主要超参数,需要在训练前设置。这些参数包括节点大小、树的数量和特征采样的数量。由此,随机森林分类器可用于解决回归或分类问题。随机森林算法由决策树集合组成,集合中的每棵树都由从训练集中抽取的数据样本组成,并进行替换,称为自举样本。在训练样本中,有三分之一被留作测试数据,即我们稍后会提到的 “袋外样本”(out-of-bag (oob) sample)。然后通过特征袋注入另一个随机性实例,为数据集增加更多的多样性,并降低决策树之间的相关性。根据问题的类型,预测的确定方式也会有所不同。对于回归任务,将对单个决策树进行平均,而对于分类任务,将通过多数票(即最常见的分类变量)得出预测类别。最后,将 oob 样本用于交叉验证,最终确定预测结果。
二、随机森林的数学原理
随机森林的数学原理可以从以下几个方面进行阐述:
1. 决策树的基本原理
决策树是一种树形结构模型,通过递归地将数据集划分为若干子集,每个子集对应树的一个节点。决策树的构建过程包括特征选择、节点分裂和剪枝:
- 特征选择:选择最优特征进行节点分裂,常用的指标包括信息增益(Information Gain)、基尼指数(Gini Index)等。
- 节点分裂:根据选定特征的值将数据集划分为多个子集。
- 剪枝:通过剪枝策略避免过拟合。
信息增益
信息增益用于衡量选择某个特征进行分裂后,数据集的不确定性减少的程度。其计算公式为:
Information Gain
=
H
(
D
)
−
∑
v
∈
Values
(
A
)
∣
D
v
∣
∣
D
∣
H
(
D
v
)
\text { Information Gain }=H(D)-\sum_{v \in \operatorname{Values}(A)} \frac{\left|D_{v}\right|}{|D|} H\left(D_{v}\right)
Information Gain =H(D)−v∈Values(A)∑∣D∣∣Dv∣H(Dv)
其中,
H
(
D
)
H(D)
H(D) 是数据集
D
D
D 的熵,Dv是根据特征
A
A
A 的取值 v 划分的子集。
基尼指数
基尼指数用于衡量数据集的不纯度,其计算公式为:
Gini Index
=
1
−
∑
i
=
1
k
p
i
2
\text { Gini Index }=1-\sum_{i=1}^{k} p_{i}^{2}
Gini Index =1−i=1∑kpi2
其中,
p
i
p_i
pi 是数据集中第
i
i
i类样本的比例。
2. 随机森林的随机性
随机森林通过引入随机性来增强模型的多样性,具体包括:
- Bootstrap采样:从训练集中随机抽取样本(有放回抽样),用于构建每棵决策树。这种采样方式使得每棵树的训练数据略有不同。
- 特征随机选择:在每棵树的节点分裂时,随机选择部分特征(而非全部特征)进行分裂。通常选择特征的数量为总特征数的平方根(用于分类问题)或总特征数的三分之一(用于回归问题)。
3. 集成学习
随机森林通过集成多棵决策树的结果来提高模型的性能。对于分类问题,随机森林采用多数投票法(Majority Voting)确定最终预测结果;对于回归问题,随机森林采用平均法(Averaging)确定最终预测结果。
多数投票法
对于分类问题,随机森林的最终预测结果为:
y
^
=
mode
{
T
1
(
x
)
,
T
2
(
x
)
,
…
,
T
n
(
x
)
}
\hat{y}=\operatorname{mode}\left\{T_{1}(x), T_{2}(x), \ldots, T_{n}(x)\right\}
y^=mode{T1(x),T2(x),…,Tn(x)}
其中,
T
i
(
x
)
T_i (x)
Ti(x) 是第 i 棵树的预测结果,mode表示取众数。
平均法
对于回归问题,随机森林的最终预测结果为:
y
^
=
1
n
∑
i
=
1
n
T
i
(
x
)
\hat{y}=\frac{1}{n} \sum_{i=1}^{n} T_{i}(x)
y^=n1i=1∑nTi(x)
其中,
T
i
(
x
)
T_i (x)
Ti(x) 是第 i 棵树的预测结果。
4. 泛化误差与多样性
随机森林的泛化误差(Generalization Error)取决于每棵树的性能以及树与树之间的多样性。通过引入随机性,随机森林能够有效降低模型的方差(Variance),从而提高泛化能力。
三、如何训练随机森林模型
训练随机森林模型的过程可以分为以下几个步骤:
1. 数据准备
- 数据清洗:处理缺失值、异常值等问题。
- 特征工程:对特征进行编码、标准化等处理。
- 划分数据集:将数据集划分为训练集和测试集。
2. 模型参数设置
随机森林的主要参数包括:
- 树的数量(n_estimators):森林中决策树的数量。
- 最大特征数(max_features):每棵树节点分裂时考虑的最大特征数。
- 最大深度(max_depth):每棵树的最大深度。
- 最小样本分裂(min_samples_split):节点分裂所需的最小样本数。
- 最小样本叶子(min_samples_leaf):叶子节点所需的最小样本数。
3. 训练过程
- Bootstrap采样:从训练集中随机抽取样本,用于构建每棵决策树。
- 构建决策树:根据随机选择的特征和样本,递归地构建每棵决策树。
- 集成结果:将所有决策树的预测结果进行集成(投票或平均)。
4. 模型调优
通过交叉验证(Cross-Validation)和网格搜索(Grid Search)等方法,优化随机森林的参数,以提高模型的性能。
5.代码块
分类任务:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import warnings
warnings.filterwarnings('ignore')
# Corrected URL for the dataset
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic_data = pd.read_csv(url)
# Drop rows with missing 'Survived' values
titanic_data = titanic_data.dropna(subset=['Survived'])
# Features and target variable
X = titanic_data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']]
y = titanic_data['Survived']
# Encode 'Sex' column
X.loc[:, 'Sex'] = X['Sex'].map({'female': 0, 'male': 1})
# Fill missing 'Age' values with the median
X.loc[:, 'Age'].fillna(X['Age'].median(), inplace=True)
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize RandomForestClassifier
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# Fit the classifier to the training data
rf_classifier.fit(X_train, y_train)
# Make predictions
y_pred = rf_classifier.predict(X_test)
# Calculate accuracy and classification report
accuracy = accuracy_score(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred)
# Print the results
print(f"Accuracy: {accuracy:.2f}")
print("\nClassification Report:\n", classification_rep)
# Sample prediction
sample = X_test.iloc[0:1] # Keep as DataFrame to match model input format
prediction = rf_classifier.predict(sample)
# Retrieve and display the sample
sample_dict = sample.iloc[0].to_dict()
print(f"\nSample Passenger: {sample_dict}")
print(f"Predicted Survival: {'Survived' if prediction[0] == 1 else 'Did Not Survive'}")
回归任务:
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
# Load the California housing dataset
california_housing = fetch_california_housing()
california_data = pd.DataFrame(california_housing.data, columns=california_housing.feature_names)
california_data['MEDV'] = california_housing.target
# Features and target variable
X = california_data.drop('MEDV', axis=1)
y = california_data['MEDV']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize the RandomForestRegressor
rf_regressor = RandomForestRegressor(n_estimators=100, random_state=42)
# Train the regressor
rf_regressor.fit(X_train, y_train)
# Make predictions
y_pred = rf_regressor.predict(X_test)
# Calculate metrics
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# Sample Prediction
single_data = X_test.iloc[0].values.reshape(1, -1)
predicted_value = rf_regressor.predict(single_data)
print(f"Predicted Value: {predicted_value[0]:.2f}")
print(f"Actual Value: {y_test.iloc[0]:.2f}")
# Print results
print(f"Mean Squared Error: {mse:.2f}")
print(f"R-squared Score: {r2:.2f}")
四、随机森林的评估指标
随机森林的性能可以通过以下指标进行评估:
1. 分类问题
- 准确率(Accuracy):预测正确的样本占总样本的比例。
- 精确率(Precision):预测为正类的样本中实际为正类的比例。
- 召回率(Recall):实际为正类的样本中被正确预测为正类的比例。
- F1分数(F1 Score):精确率和召回率的调和平均数。
- ROC-AUC:ROC曲线下的面积,用于评估分类器的整体性能。
2. 回归问题
- 均方误差(MSE):预测值与真实值之间差异的平方的平均值。
- 均方根误差(RMSE):MSE的平方根。
- 平均绝对误差(MAE):预测值与真实值之间差异的绝对值的平均值。
- R²(决定系数):模型解释的方差占总方差的比例。
五、随机森林的应用场景
随机森林因其强大的性能和广泛的适用性,被应用于多个领域:
1. 分类问题
- 医学诊断:如疾病预测、患者分类等。
- 金融风控:如信用评分、欺诈检测等。
- 图像分类:如手写数字识别、物体检测等。
2. 回归问题
- 房价预测:根据房屋特征预测房价。
- 销量预测:根据历史数据预测产品销量。
- 股票预测:根据市场数据预测股票价格。
3. 特征选择
随机森林可以计算特征的重要性(Feature Importance),从而帮助选择对模型预测最有用的特征。
六、随机森林的优缺点
1. 优点
- 高准确性:通过集成多棵决策树,随机森林能够显著提高模型的准确性。
- 鲁棒性强:对噪声数据和缺失值不敏感。
- 易于并行化:每棵树的构建过程相互独立,适合并行计算。
- 可解释性强:可以通过特征重要性评估特征对模型的贡献。
2. 缺点
- 计算复杂度高:当树的数量较多时,训练和预测的计算成本较高。
- 内存消耗大:需要存储多棵决策树,内存消耗较大。
- 对高维稀疏数据效果较差:在处理高维稀疏数据时,随机森林的性能可能不如其他算法(如支持向量机)。
结论
随机森林作为一种经典的机器学习算法,凭借其高准确性、鲁棒性和易于实现的特点,在多个领域得到了广泛应用。尽管随机森林在某些场景下存在计算复杂度高和内存消耗大的问题,但其整体性能仍然优于许多其他算法。未来,随着计算能力的提升和算法的优化,随机森林将继续在机器学习领域发挥重要作用。
参考文献
- Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.
- Scikit-learn Documentation: Random Forest. https://scikitlearn.org/stable/modules/ensemble.html#random-forests

















 1275
1275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









