






【AAAI2023】Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
该论文得创新点主要有三个,第一个(架构如下图1)是解决Transformer计算复杂度太大的问题,将注意力的计算改在了H和W维度上,第一步相似性计算的是HxH,叫做 height-axis attention,第二步相似性计算的是 WxW,叫做 width-axis attention。第二个是改进了FFN(图2),使用双门控机制增加表示能力。第三个(图3)就是增加了计算层与层之间关系的交叉注意力机制。

图1

图2

图3
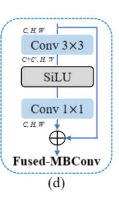
【NeurIPS2022】ShuffleMixer: An Efficient ConvNet for Image Super-Resolution
设计了通道分组模块,将其中的一组特征沿通道维度打乱,然后两个组shuffle,以便更好的特征提取。

提供了一个新的FFN结构
【ARXIV2212】A Close Look at Spatial Modeling: From Attention to Convolution
论文中提出了两个新奇的问题:注意力中的Query与注意力图无关、发现了只有几个patch发挥作用。因此改写了注意力计算机制并且和卷积结合。
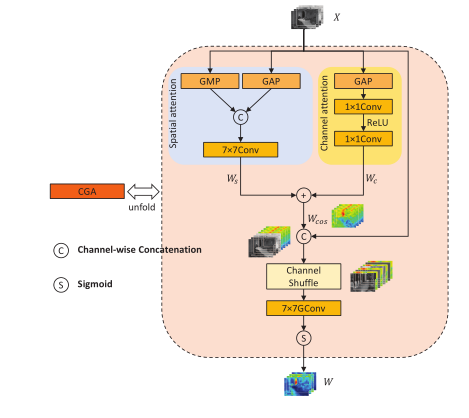
【ARXIV2301】DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
使用DEConv将精心设计的先验集成到普通卷积层中,并且设计了content-guided attention模块,以从粗到细的方式获得输入特征的每个通道的专属SIM(spatial importance map),同时充分混合信道注意力权重和空间注意力权重,以保证信息交互。

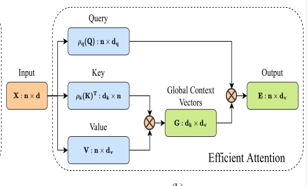
【ARXIV2212】DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
论文主要解决的问题是VIT应用在高分辨率上复杂度太高,因此串联高效注意力和通道注意力,并且设计了类U-Net结构,提出交叉注意力(SCCA),为网络提供多尺度信息。

高效注意力:论文 Efficient attention 中 利用常规自注意力产生冗余上下文矩阵提出了一种计算自注意力过程的有效方法 ,既当应用 ρq 和 ρk 时,模块会产生等效的点积注意力输出,它们是 softmax 归一化函数。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









