






结果:src=“test.jpg”
因为匹配到第一个"就结束了一次匹配。不会继续向后匹配。因为他懒惰嘛。
>
> * `.`表示除`\n`之外的任意字符
> * `*`表示匹配0-无穷
> * `+`表示匹配1-无穷
>
>
>
### 五、尾页判断
接下来我们要判断当前页是否为最后一页,否则我们就不能判断什么时候结束了,我找到了源码中‘尾页’的标签,发现是下面的结构:
所以我们可以用下面的正则表达式来匹配,如果匹配成功就说明当前页不是最后一页,否则当前页就是最后一页。
### 六、编程实现
下面是摘自的Python2版完整的代码实现:
#!usr/bin/python
-*- coding: utf-8 -*-
‘’’
Created on 2016年2月13日
@author: ***
使用python爬取csdn个人博客的访问量,主要用来练手
‘’’
import urllib2
import re
#当前的博客列表页号
page_num = 1
#不是最后列表的一页
notLast = 1
account = str(raw_input(‘输入csdn的登录账号:’))
while notLast:
#首页地址
baseUrl = ‘http://blog.csdn.net/’+account
#连接页号,组成爬取的页面网址
myUrl = baseUrl+‘/article/list/’+str(page_num)
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)’
headers = {‘User-Agent’:user_agent}
#构造请求
req = urllib2.Request(myUrl,headers=headers)
#访问页面
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
#在页面中查找是否存在‘尾页’这一个标签来判断是否为最后一页
notLast = re.findall(‘尾页’,myPage,re.S)
print ‘---------------第%d页-------------’ % (page_num,)
#利用正则表达式来获取博客的标题
title = re.findall(‘(.*?)’,myPage,re.S)
titleList=[]
for items in title:
titleList.append(str(items).lstrip().rstrip())
#利用正则表达式获取博客的访问量
view = re.findall(‘<span class=“link_view”.*?>阅读((.*?))’,myPage,re.S)
viewList=[]
for items in view:
viewList.append(str(items).lstrip().rstrip())
#将结果输出
for n in range(len(titleList)):
print ‘访问量:%s 标题:%s’ % (viewList[n].zfill(4),titleList[n])
#页号加1
page_num = page_num + 1
由于自己现在的IDE为Python3,且自己在学习Python3。故在此基础上实现Python2项目的升级改造,并在改造过程中发现版本之间的差异性。以下为Python3版本下的爬虫代码。
#!usr/bin/python
-*- coding: utf-8 -*-
‘’’
Created on 2017年3月19日
@author: SUN HuaQiang
目的:使用python爬取csdn个人博客的访问量,主要用来练手Python爬虫
收获:1.了解Python爬虫的基本过程
2.在Python2的基础上实现Python3,通过对比发现版本之间的差异
‘’’
import urllib.request
import urllib
import re
#当前的博客列表页号
page_num = 1
#初始化最后列表的页码
notLast = 1
account = str(input(‘请输入csdn的登录账号:’))
while notLast:
#首页地址
baseUrl = ‘http://blog.csdn.net/’ + account
#连接页号,组成爬取的页面网址
myUrl = baseUrl+‘/article/list/’ + str(page_num)
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = ‘Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)’
headers = {‘User-Agent’:user_agent}
#构造请求
req = urllib.request.Request(myUrl,headers=headers)
#访问页面
myResponse = urllib.request.urlopen(req)
#python3中urllib.read返回的是bytes对象,不是string,得把它转换成string对象,用bytes.decode方法
myPage = myResponse.read().decode()
#在页面中查找是否存在‘尾页’这一个标签来判断是否为最后一页
notLast = re.findall(‘尾页’, myPage, re.S)
print (‘-----------第%d页--------------’ % (page_num,))
#利用正则表达式来获取博客的标题
title = re.findall(‘(.*?)’,myPage,re.S)
titleList=[]
for items in title:
titleList.append(str(items).lstrip().rstrip())
#利用正则表达式获取博客的访问量
view = re.findall(‘<span class=“link_view”.*?>阅读((.*?))’,myPage,re.S)
viewList=[]
for items in view:
viewList.append(str(items).lstrip().rstrip())
#将结果输出
for n in range(len(titleList)):
print (‘访问量:%s 标题:%s’ % (viewList[n].zfill(4),titleList[n]))
#页号加1
page_num = page_num + 1
下面是部分结果:
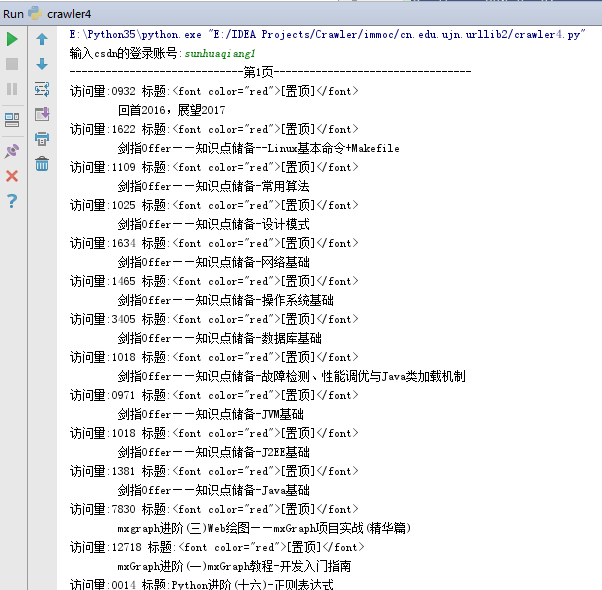
瑕疵:通过爬虫结果可以发现,在CSDN中,对于设置为指定的文章,爬取结果存在一定的问题,还包含部分css代码。
改善:通过更改获取博文标题的正则表达式,即可解决此问题。


想法是好的,但是直接利用正则实现标题获取时遇到了困难,暂时并未实现理想结果。
遂改变思路,将利用正则获取后的字符串再进行二次正则,即替换操作,语句如下:
for items in title:
titleList.append(re.sub(‘.*?’, ‘’, str(items).lstrip().rstrip()))
更改后的结果如下。并同时为每篇博文进行了编号。
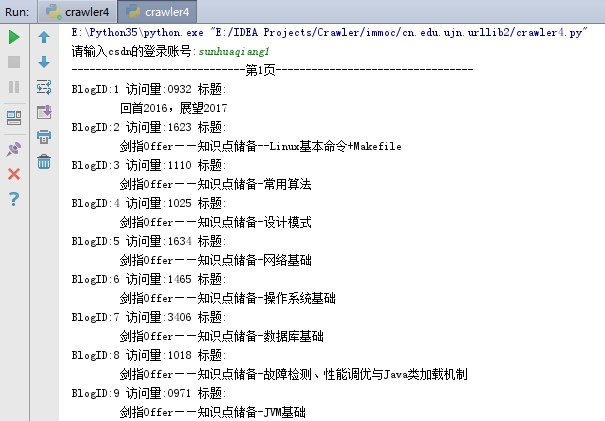
同时,自己还希望获取到的信息包括:访问总量、积分、等级、排名、粉丝、原创、转载、译文、评论等数据信息。
以上信息在网页源码中如下所示。
- 访问:459285次
- 积分:9214
- 等级:
 积分:9214
积分:9214 - 排名:第1639名
- 原创:425篇
- 转载:44篇
- 译文:2篇
- 评论:108条
则获取访问信息的正则表达式为:
#利用正则表达式获取博客信息
sumVisit = re.findall(‘
- 访问:(.*?)
- ’, myPage, re.S)
credit = re.findall(‘ - 积分:(.*?)
- ’, myPage, re.S)
rank = re.findall(‘ - 排名:(.*?)
- ’, myPage, re.S)
grade = re.findall(‘ - .*?
 .*?
.*? - ’, test3, re.S)
original = re.findall(‘ - 原创:(.*?)
- ’, myPage, re.S)
reprint = re.findall(‘ - 转载:(.*?)
- ’, myPage, re.S)
trans = re.findall(‘ - 译文:(.*?)
- ’, myPage, re.S)
comment = re.findall(‘ - 评论:(.*?)
- ’, myPage, re.S)
 根据网页源码,可得出其正则表达式为 ### 最后 不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~ 给大家准备的学习资料包括但不限于: Python 环境、pycharm编辑器/永久激活/翻译插件 python 零基础视频教程 Python 界面开发实战教程 Python 爬虫实战教程 Python 数据分析实战教程 python 游戏开发实战教程 Python 电子书100本 Python 学习路线规划  **网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。** **[需要这份系统化学习资料的朋友,可以戳这里无偿获取](https://bbs.csdn.net/topics/618317507)** **一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**














 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









