









图形化管理工具
访问地址:http://服务器IP:9101/
DEFAULT_USERNAME:默认账号admin
DEFAULT_PASSWORD:默认密码admin
Git 地址:https://github.com/dushixiang/kafka-# map/blob/master/README-zh_CN.md
docker run -d --name kafka-map
–network app-kafka
-p 9101:8080
-v /opt/kafka-map/data:/usr/local/kafka-map/data
-e DEFAULT_USERNAME=admin
-e DEFAULT_PASSWORD=admin
–restart always dushixiang/kafka-map:latest
##

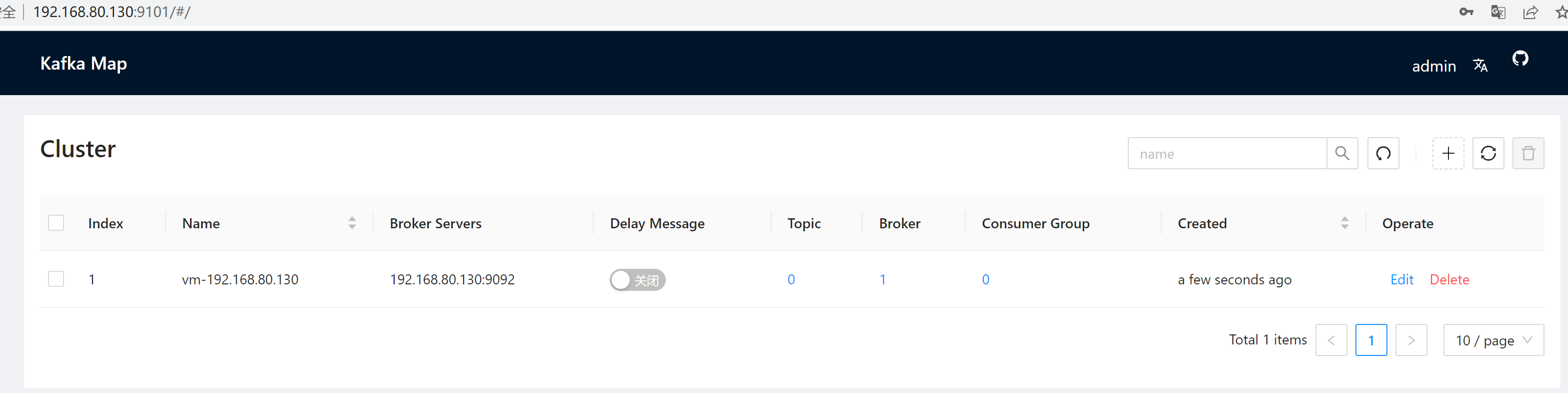
## 四、验证是否部署成功
1、查看zookeeper中有关kafka的配置
docker exec -it zookeeper-server /bin/bash
cd /bin
sh zkCli.sh -server 127.0.0.1:2181
[zk: 127.0.0.1:2181(CONNECTED) 7] ls /
[zookeeper, kafka]
[zk: 127.0.0.1:2181(CONNECTED) 8] ls /kafka
[cluster, controller, controller_epoch, brokers, admin, isr_change_notification, consumers, config]
[zk: 127.0.0.1:2181(CONNECTED) 9]
2、进入kafka容器查看
[root@blog]
d
o
c
k
e
r
e
x
e
c
−
i
t
z
o
o
k
e
e
p
e
r
−
s
e
r
v
e
r
b
a
s
h
[
r
o
o
t
@
b
l
o
g
]
docker exec -it zookeeper-server bash [root@blog]
dockerexec−itzookeeper−serverbash[root@blog] ps -ef
PID USER TIME COMMAND
1 root 0:08 /usr/lib/jvm/java-1.8-openjdk/jre/bin/java -Xmx1G -Xms1G -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -XX:MaxIn
502 root 0:00 /bin/sh
506 root 0:00 ps -ef
创建主题
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic mytest
查看主题
kafka-topics.sh --list --bootstrap-server localhost:9092
发送消息
kafka-console-producer.sh --broker-list localhost:9092 --topic mytest
接收消息
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic mytest --from-beginning
 
## 五、SpringBoot整合Kafka
### 1、导入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
### 2、修改配置
spring:
kafka:
bootstrap-servers: 192.168.58.130:9092 #部署linux的kafka的ip地址和端口号
producer:
# 发生错误后,消息重发的次数。
retries: 1
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
**本次测试**:linux地址:192.168.58.130
**spring.kafka.bootstrap-servers=**192.168.58.130:9092
**advertised.listeners=**192.168.58.130:9092
### 3、生产者
import com.alibaba.fastjson.JSON;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
/**
-
事件的生产者
*/
@Slf4j
@Component
public class KafkaProducer {@Autowired
public KafkaTemplate kafkaTemplate;/** 主题 /
public static final String TOPIC_TEST = “Test”;
/* 消费者组 */
public static final String TOPIC_GROUP = “test-consumer-group”;public void send(Object obj){
String obj2String = JSON.toJSONString(obj);
log.info(“准备发送消息为:{}”,obj2String);//发送消息 ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_TEST, obj); //回调 future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() { @Override public void onFailure(Throwable ex) { //发送失败的处理 log.info(TOPIC_TEST + " - 生产者 发送消息失败:" + ex.getMessage()); } @Override public void onSuccess(SendResult<String, Object> result) { //成功的处理 log.info(TOPIC_TEST + " - 生产者 发送消息成功:" + result.toString()); } });}
}
### 4、消费者
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;
import java.util.Optional;
/**
-
事件消费者
*/
@Component
public class KafkaConsumer {
private Logger logger = LoggerFactory.getLogger(org.apache.kafka.clients.consumer.KafkaConsumer.class);@KafkaListener(topics = KafkaProducer.TOPIC_TEST,groupId = KafkaProducer.TOPIC_GROUP)
public void topicTest(ConsumerRecord<?,?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic){
Optional<?> message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
logger.info(“topic_test 消费了: Topic:” + topic + “,Message:” + msg);
ack.acknowledge();
}
}
}
### 5、测试发送消息
@Test
void kafkaTest(){
kafkaProducer.send(“Hello Kafka”);
}
### 6、测试收到消息

## 六、拦截器
### 1、生产者拦截器
#### 1.1、生产者拦截器代码
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
-
@author idcos
-
@date 2023/11/9 11:13
*/
@Slf4j
public class CustomProducerInterceptor implements ProducerInterceptor<String,String> {
@Override
public ProducerRecord onSend(ProducerRecord producerRecord) {
log.info(“发送前处理———发送消息:”+producerRecord.toString());
return producerRecord;
}@Override
public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {
// 在收到消息的确认或异常时执行逻辑
if (e == null) {
log.info(“消息成功发送”);
} else {
log.error(“消息成功失败”);
}
}@Override
public void close() {
log.info(“执行一些资源清理操作”);
}@Override
public void configure(Map<String, ?> map) {}
}
#### 1.2、生产者yml配置
spring:
kafka:
bootstrap-servers: IP:9092,IP:9092,IP:9092
producer:
properties:
interceptor.classes: com.kafkaserver3.interceptor.CustomProducerInterceptor
#### 1.3、测试
发送消息hello,主题TOPIC1,key为test

### 2、消费者拦截器
#### 2.1、消费者拦截器代码
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.Map;
/**
-
@author idcos
-
@date 2023/11/9 11:25
*/
@Slf4j
public class CustomConsumerInterceptor implements ConsumerInterceptor<String,String> {
@Override
public ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> consumerRecords) {
log.info(“消费前处理———发送消息:”+consumerRecords.toString());
return consumerRecords;
}@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> map) {
// 在消费者提交偏移量之后的逻辑
log.info(“在消费者提交偏移量之后的逻辑”+map.toString());
}@Override
public void close() {
// 在拦截器关闭时的逻辑
System.out.println(“在拦截器关闭时”);
}@Override
public void configure(Map<String, ?> map) {
// 在拦截器配置时的逻辑
System.out.println(“在拦截器配置时”);
}
}
#### 2.2、消费者yml配置
spring:
kafka:
bootstrap-servers: IP:9092,IP:9092,IP:9092
consumer:
properties:
interceptor.classes: com.kafkaserver3.interceptor.CustomConsumerInterceptor
#### 2.3、测试
发送消息hello,主题TOPIC1,key为test

参考文档:
### 最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
### 资料预览
给大家整理的视频资料:

给大家整理的电子书资料:

**如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!**
omConsumerInterceptor
2.3、测试
发送消息hello,主题TOPIC1,key为test

参考文档:
最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:
[外链图片转存中…(img-fDX8ZoJM-1718876942513)]
给大家整理的电子书资料:
[外链图片转存中…(img-YdzvHKLG-1718876942514)]
如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!















 559
559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









