






机器学习(西瓜书),第3章,线性模型
一、线性回归
此部分直接回顾高等数学最小二乘法,先是定义损失函数(均方误差),为了使其最小,将损失函数对两个变量和
分别求偏导,偏导都为0的地方是最小值(必要条件),严格来说还要对二阶偏导的Hessian矩阵判断正定。

多维空间原理相似,仅均方误差变为,直观理解就是向量内积的形式,而向量内积类似于到原点的欧几里得距离的平方,便隐含了“距离”的概念。
,则
为距离的平方
参考调用sklearn代码
#导入包
import numpy as np #
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决符号显示问题
#创建数据
x = np.array([1, 2, 3, 4, 5]).reshape(-1, 1) # 自变量数据
y = np.array([1, 4, 8, 10, 11]).reshape(-1, 1) # 因变量数据
#构建线性模型
model = LinearRegression() # 创建一个回归分析对象
model.fit(x.reshape(-1, 1), y.reshape(-1, 1)) # 对x和y进行拟合
#获取系数和截距
print('系数:', model.coef_[0],'截距:', model.intercept_)
# 可视化
plt.scatter(x, y, color='blue', label='实际数据')
plt.plot(x, model.predict(x), color='red', label='线性回归模型')
plt.title('线性回归示例')
plt.xlabel('自变量')
plt.ylabel('因变量')
plt.legend()
plt.show()效果图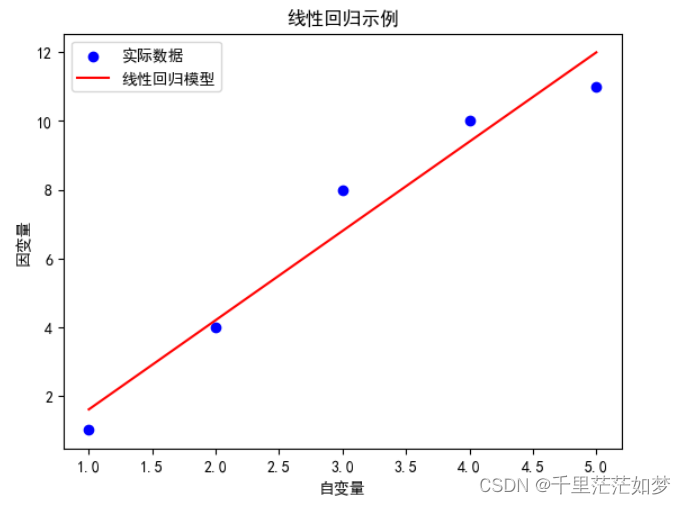
二、对数几率回归
将乘法问题转化为加法问题,大大降低了计算的复杂度,其核心就为数理统计中的,利用已知数据结果,反推最具有可能(极大似然)导致这些样本结果出现的模型参数值
中提到牛顿法,推荐看这个可视化过程的b站视频【【机器学习】动画讲解牛顿法】https://www.bilibili.com/video/BV17u4y1Q7wB/
三、多问题学习
最经典的拆分策略有三种. "一对一" (One vs. One ,简称 OvO) ,"一对 其余" (One vs. Rest ,简称 OvR) 和"多对多" (Many vs. Many,简称 MvM).
多分类中的编码属实是一个有趣的想法,将多问题变为多个01位的二分类问题
四、不平衡问题
欠采样:丢弃了很多多出的例子,代表性算法 EasyEnsemble [Liu et 此, 2009] 则是利用集成学习机制,将反倒划分为若干个 集合供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来 看却不会丢失重要信息.
过采样:SMOTE [Chawla et al., 2002] 通过对训练集里的正例进行插值来产生额外的正例
阈值移动:即讲预测阈值设定在原有的比例上,比如正例(数值1)80个,反例(数值0)20个,只有预测值映射在[0,1],只有预测值大于0.8,才认为是正例。而不是简单的用0.5作为分类阈值















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









