







数据库隔离级别及其解决的问题
数据库的隔离级别是事务处理中用于控制并发操作引发数据异常的核心机制。根据SQL标准,隔离级别分为 读未提交(READ UNCOMMITTED) 、 读已提交(READ COMMITTED) 、 可重复读(REPEATABLE READ) 和 可串行化(SERIALIZABLE) 四个级别。每个级别通过不同的锁机制或多版本并发控制(MVCC)策略,逐步消除脏读、不可重复读和幻读等数据异常问题。
1. 读未提交(READ UNCOMMITTED)
- 定义:最低的隔离级别,允许事务读取其他事务未提交的数据。
- 解决的问题:无。此级别不解决任何数据异常。
- 可能引发的异常:
- 脏读(Dirty Read) :读取到其他事务未提交的数据,若该事务回滚,则数据无效。
- 不可重复读(Non-repeatable Read) :同一事务中多次读取同一数据,结果因其他事务的修改而不同。
- 幻读(Phantom Read) :范围查询时,其他事务插入新数据,导致前后结果不一致。
- 应用场景:对数据一致性要求极低但追求高并发的场景(如实时日志记录)。
2. 读已提交(READ COMMITTED)
- 定义:事务只能读取其他事务已提交的数据,大多数数据库(如Oracle)的默认级别。
- 解决的问题:
- 脏读:通过只读取已提交数据来避免。
- 可能引发的异常:
- 不可重复读:同一事务中多次读取同一数据,可能因其他事务的提交而结果不同。
- 幻读:其他事务插入新数据导致范围查询结果变化。
- 实现机制:
- 行级锁(写锁):事务修改数据时加锁,阻止其他事务同时修改,但读取时不加锁。
- MVCC:为每个查询生成快照,仅读取已提交的数据版本。
- 应用场景:常见的OLTP系统,平衡一致性与性能。
3. 可重复读(REPEATABLE READ)
- 定义:保证同一事务内多次读取同一数据的结果一致,MySQL的默认级别。
- 解决的问题:
- 脏读和不可重复读:通过事务期间锁定读取的数据或使用MVCC快照。
- 可能引发的异常:
- 幻读:其他事务插入新数据可能导致范围查询结果变化。
- 实现机制:
- 锁机制:事务首次读取数据时加锁,直至事务结束(如共享锁)。
- MVCC:生成事务开始时的一致性快照,后续读取均基于此快照。
- 特殊说明:
- MySQL的InnoDB引擎通过 间隙锁(Gap Lock) 在可重复读级别下解决了幻读,但这是数据库实现的扩展,超出SQL标准定义。
- 应用场景:需保证事务内数据一致性的场景(如订单状态多次校验)。
4. 可串行化(SERIALIZABLE)
- 定义:最高隔离级别,事务完全串行执行,完全服从ACID原则。
- 解决的问题:
- 脏读、不可重复读和幻读:所有事务按顺序执行,无并发干扰。
- 实现机制:
- 严格锁:对涉及的所有数据加范围锁,阻止其他事务的读写操作。
- MVCC+串行化验证:通过时间戳或序列号强制事务串行提交。
- 缺点:严重降低并发性能,增加死锁风险。
- 应用场景:对数据一致性要求极高的场景(如金融交易)。
数据异常与隔离级别对照表
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 性能影响 |
|---|---|---|---|---|
| 读未提交 | ✓ | ✓ | ✓ | 最低 |
| 读已提交 | ✗ | ✓ | ✓ | 中等 |
| 可重复读 | ✗ | ✗ | ✓ | 较高 |
| 可串行化 | ✗ | ✗ | ✗ | 最高 |
实际数据库的默认设置
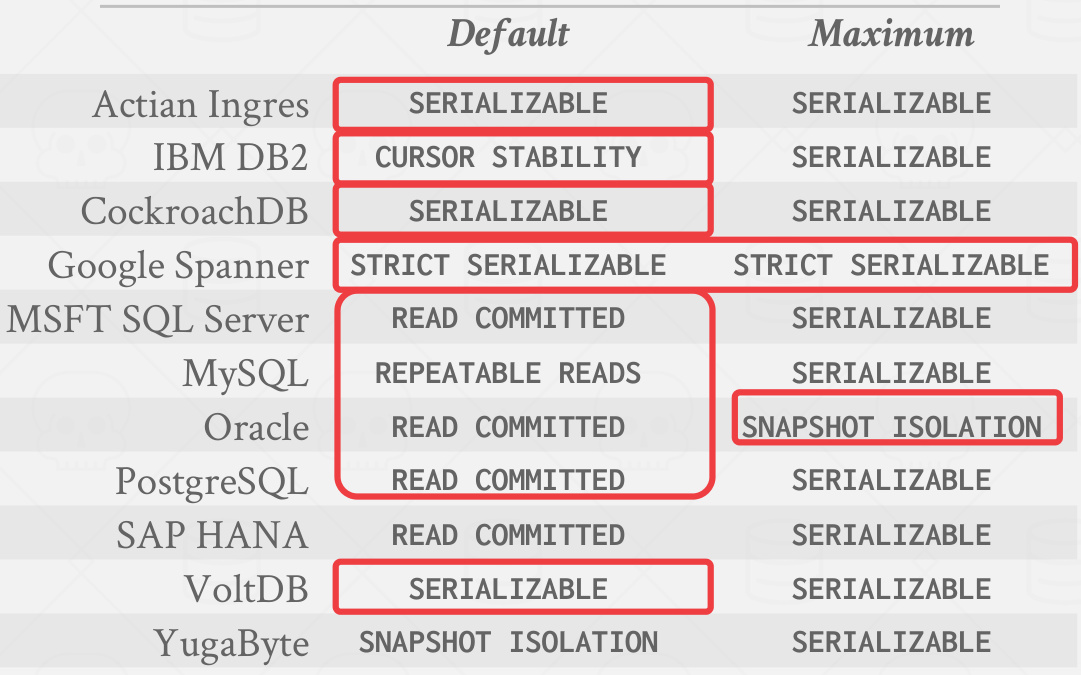
- MySQL(InnoDB) :默认可重复读,通过间隙锁避免幻读。
- Oracle:默认读已提交,支持可串行化和只读模式。
- PostgreSQL:默认读已提交,但通过SSI(可串行化快照隔离)实现高级别一致性。
选择隔离级别的权衡
- 低隔离级别(如读已提交) :适合高并发、弱一致性需求的场景(如社交平台)。
- 高隔离级别(如可串行化) :用于关键业务(如银行转账),需牺牲性能换取数据安全。
- 中间级别(如可重复读) :在一致性与性能间折中,适用于大多数业务系统。
总结
隔离级别的核心目标是在并发环境下平衡数据一致性与系统性能。开发者需根据业务需求选择合适级别:低级别提升吞吐量但需容忍异常,高级别保证数据正确性但限制并发。理解每种异常的表现及解决机制,是设计高可靠数据库系统的关键。


















 6232
6232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











