







再看蚁群算法(待更新)
(比较枯燥)
前言
本文将从两篇参考文献的角度去了解蚁群算法的发展与变化,原理部分不会深入讨论了,分别为2005年的Ant colony optimization: Introduction and recent trends(中科院二区)和2023年的Modified adaptive ant colony optimization algorithm and its application for solving path planning of mobile robot(中科院一区)
基础部分请看:智能优化算法之蚁群算法_csdn 蚁群算法-CSDN博客
参考文献
[1] Blum C. [J]. Physics of Life reviews, 2005, 2(4): 353-373.
[2] Wu L, Huang X, Cui J, et al. Modified adaptive ant colony optimization algorithm and its application for solving path planning of mobile robot[J]. Expert Systems with Applications, 2023, 215: 119410.
免责声明
由于本人并不是智能优化算法方向,只是由于数模而有所了解,故可能理解有误。
正文
文献1(2005)
摘要(Introduction)
Ant colony optimization is a technique for optimization that was introduced in the early 1990’s. The inspiring source of ant colony optimization is the foraging behavior of real ant colonies. This behavior is exploited in artificial ant colonies for the search of approximate solutions to discrete optimization problems, to continuous optimization problems, and to important problems in telecommunications, such as routing and load balancing. First, we deal with the biological inspiration of ant colony optimization algorithms. We show how this biological inspiration can be transfered into an algorithm for discrete optimization. Then, we outline ant colony optimization in more general terms in the context of discrete optimization, and present some of the nowadays best performing ant colony optimization variants. After summarizing some important theoretical results, we demonstrate how ant colony optimization can be applied to continuous optimization problems. Finally, we provide examples of an interesting recent research direction: The hybridization with more classical techniques from artificial intelligence and operations research.
别怕,有翻译
蚁群优化是20世纪90年代初提出的一种优化技术。蚁群优化的灵感来源是真实蚁群的觅食行为。这种行为在人工蚁群中被用来搜索离散优化问题的近似解,连续优化问题,以及电信中的重要问题,如路由和负载平衡。首先,我们处理蚁群优化算法的生物学启示。我们展示了如何将这种生物学灵感转化为离散优化算法。然后,我们在离散优化的背景下概述了蚁群优化的更一般的术语,并提出了一些目前表现最好的蚁群优化变体。在总结了一些重要的理论结果之后,我们展示了蚁群优化如何应用于连续优化问题。最后,我们提供了最近一个有趣的研究方向的例子:与人工智能和运筹学中更经典的技术的杂交。
个人理解
所以蚁群算法就是为了解决优化问题,我们知道机器学习里面有许多优化方法,比如梯度下降就是最为经典的一种,而且具有很好的数学性质,也有许多衍生方法,那我们为什么还要用智能优化算法呢?智能优化看起来也是调参游戏,不稳定是其难以克服的问题。如果对优化有所了解的话,我们知道优化实际上就是寻找帕累托前沿的过程,在真实世界里很难说什么是最好的,沿着帕累托前沿的结果可能都是有价值的,当然这也不是一定要用智能优化算法的理由。本人理解的理由是,所有的优化问题都存在一个目标函数,比如机器学习最常用的交叉熵损失函数,为了将其值收敛至最小,提高模型的准确率提出了Adam等经典优化方法,然而不是所有的目标函数都具有很好的数学性质(还有 NP难问题),甚至多目标优化是现实中最常见的情况,无法求导更是家常便饭,而智能优化并不是从数学推导的角度去逼近最优的目标函数值,他与牛顿法等优化方法完全不同,他从生物学的角度去逼近最优解(还存在其他非生物原理的优化算法),避免了求导等数学操作,当然稳定性也更差,毕竟还会存在基因突变(遗传算法等),好的基因并不一定能产生好的后代,但是不得不承认这个方向是有价值的,所以智能优化算法也有研究价值了。
补充
“帕累托最优边界”(Pareto Frontier)或称为"帕累托前沿",来源于经济学中的帕累托效率或帕累托最优(Pareto Efficiency 或 Pareto Optimality)的概念,是指在一个分配系统中,没有可能通过重新分配使某个个体更好而不使任何其他个体变得更坏的状态。简而言之,这是一种“最优”的状态,其中任何个体的利益增加都将以另一个个体的损失为代价。
在多目标优化问题中,帕累托前沿是一个区域或一组点,代表了在考虑两个或更多目标时可能的最优解的集合。在这个边界上的每一点,一个目标不能够被进一步改善而不牺牲另一个目标。换句话说,它代表了在多个目标之间取得的最佳平衡点。
举一个例子来说明这个概念,考虑一个简单的经济模型,其中有两种产品需要被生产,并且有固定数量的资源。在这种情况下,帕累托前沿将描述在不同生产比例下,这两种产品之间的最大可能生产量。在这个边界上,资源被用于一种产品的额外单位生产将会减少另一种产品的产量,因为可用资源是固定的。因此,这个边界显示了在两种产品之间实现的最佳平衡或权衡,没有浪费,所有资源都得到了充分利用。
Introduction
我摘取了蚁群算法的介绍,及对本文内容的介绍,可看可不看
Ant colony optimization (ACO) [36] is one of the most recent techniques for approximate optimization. The inspiring source of ACO algorithms are real ant colonies. More specifically, ACO is inspired by the ants’ foraging behavior.
At the core of this behavior is the indirect communication between the ants by means of chemical pheromone trails, which enables them to find short paths between their nest and food sources. This characteristic of real ant colonies is exploited in ACO algorithms in order to solve, for example, discrete optimization problems.3 Depending on the point of view, ACO algorithms may belong to different classes of approximate algorithms. Seen from the artificial intelligence (AI) perspective, ACO algorithms are one of the most successful strands of swarm intelligence [16,17]. The goal of swarm intelligence is the design of intelligent multi-agent systems by taking inspiration from the collective behavior of social insects such as ants, termites, bees, wasps, and other animal societies such as flocks of birds or fish schools. Examples of “swarm intelligent” algorithms other than ACO are those for clustering and data mining inspired by ants’ cemetery building behavior [55,63], those for dynamic task allocation inspired by the behavior of wasp colonies [22], and particle swarm optimization [58].
Seen from the operations research (OR) perspective, ACO algorithms belong to the class of metaheuristics [13, 47,56]. The term metaheuristic, first introduced in [46], derives from the composition of two Greek words. Heuristic derives from the verb heuriskein (τυρισ κτιν) which means “to find”, while the suffix meta means “beyond, in an upper level”. Before this term was widely adopted, metaheuristics were often called modern heuristics[81]. In addition to ACO, other algorithms such as evolutionary computation, iterated local search, simulated annealing, and tabu search, are often regarded as metaheuristics. For books and surveys on metaheuristics see [13,47,56,81].
This review is organized as follows. In Section 2 we outline the origins of ACO algorithms. In particular, we present the foraging behavior of real ant colonies and show how this behavior can be transfered into a technical algorithm for discrete optimization. In Section 3 we provide a description of the ACO metaheuristic in more general terms, outline some of the most successful ACO variants nowadays, and list some representative examples of ACO applications.
In Section 4, we discuss some important theoretical results. In Section 5, how ACO algorithms can be adapted to continuous optimization. Finally, Section 6 will give examples of a recent successful strand of ACO research, namely the hybridization of ACO algorithms with more classical AI and OR methods. In Section 7 we offer conclusions and an outlook to the future.
蚁群优化(Ant colony optimization, ACO)[36]是一种最新的近似优化技术。蚁群算法的灵感来源是真实的蚁群。更具体地说,蚁群算法的灵感来自蚂蚁的觅食行为。
这种行为的核心是蚂蚁之间通过化学信息素轨迹的间接交流,这使它们能够找到巢穴和食物来源之间的短路径。蚁群算法利用真实蚁群的这一特性来解决离散优化问题根据不同的观点,蚁群算法可能属于不同类别的近似算法。从人工智能(AI)的角度来看,蚁群算法是群体智能最成功的分支之一[16,17]。群体智能的目标是通过从群居昆虫(如蚂蚁、白蚁、蜜蜂、黄蜂和其他动物社会(如鸟群或鱼群)的集体行为中获得灵感,设计智能多代理系统。除蚁群算法外,“群智能”算法的例子是用于聚类的算法以及受蚂蚁建墓地行为启发的数据挖掘[55,63]、受蜂群行为启发的动态任务分配[22]和粒子群优化[58]。
从运筹学的角度来看,蚁群算法属于元启发式算法[13,47,56]。“元启发式”一词在[46]中首次提出,源于两个希腊词的组合。Heuristic源自动词heuriskein (τυ σ κτιν),意为“发现”,后缀meta意为“超越,在更高的水平上”。在这个术语被广泛采用之前,元启发式通常被称为现代启发式[81]。除蚁群算法外,进化计算、迭代局部搜索、模拟退火和禁忌搜索等算法也常被视为元启发式算法。关于元启发式的书籍和调查见[13,47,56,81]。
这篇综述的组织如下。在第2节中,我们概述了蚁群算法的起源。特别是,我们展示了真实蚁群的觅食行为,并展示了如何将这种行为转移到离散优化的技术算法中。在第3节中,我们以更一般的术语描述了蚁群算法的元启发式,概述了当今一些最成功的蚁群算法变体,并列出了蚁群算法应用的一些代表性示例。
在第四节中,我们讨论了一些重要的理论结果。在第5节中,蚁群算法如何适应持续优化。最后,第6节将给出最近成功的蚁群算法研究的例子,即蚁群算法与更经典的AI和OR方法的杂交。在第7节中,我们给出了结论和对未来的展望。
蚁群优化的起源(The origins of ant colony optimization)
我只摘取我觉得有点用的内容
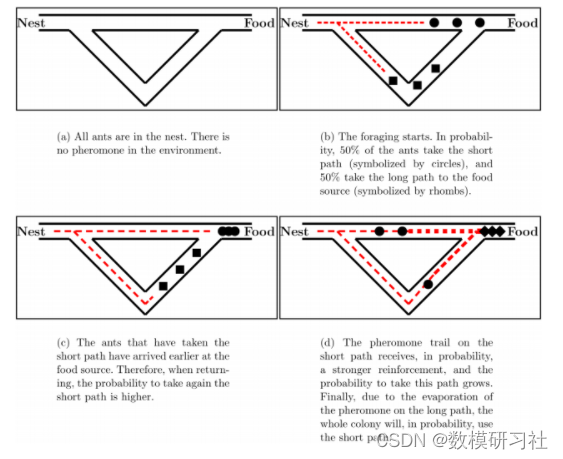
蚁群最短寻径能力的实验研究。在蚁巢和唯一的食物来源之间有两条不同长度的路径。在这四张图中,信息素轨迹用虚线表示,虚线的粗细表示轨迹的强度。
真实情况与算法的区别:
The main differences between the behavior of the real ants and the behavior of the artificial ants in our model are as follows: (1) While real ants move in their environment in an asynchronous way, the artificial ants are synchronized, i.e., at each iteration of the simulated system, each of the artificial ants moves from the nest to the food source and follows the same path back.
(2) While real ants leave pheromone on the ground whenever they move, artificial ants only deposit artificial pheromone on their way back to the nest.
(3) The foraging behavior of real ants is based on an implicit evaluation of a solution (i.e., a path from the nest to the food source). By implicit solution evaluation we mean the fact that shorter paths will be completed earlier than longer ones, and therefore they will receive pheromone reinforcement more quickly. In contrast, the artificial ants evaluate a solution with respect to some quality measure which is used to determine the strength of the pheromone reinforcement that the ants perform during their return trip to the nest.
在我们的模型中,真实蚂蚁的行为与人工蚂蚁的行为的主要区别在于:
(1)真实蚂蚁在其环境中以异步方式移动,而人工蚂蚁是同步的,即在模拟系统的每次迭代中,每只人工蚂蚁都从巢穴移动到食物源并遵循相同的路径返回。
(2)真正的蚂蚁每次移动都会在地面上留下信息素,而人工蚂蚁只会在返回巢穴的路上留下人工信息素。
(3)真实蚂蚁的觅食行为是基于对解决方案的隐式评估(即从巢穴到食物源的路径)。通过隐式解评估,我们指的是较短的路径将比较长的路径更早完成,因此它们将更快地获得信息素强化。相比之下,人工蚂蚁根据一些质量指标来评估解决方案,这些指标用于确定蚂蚁在返回巢穴时执行的信息素强化强度。
蚁群元启发式的工作原理:

一般来说,蚁群算法试图通过迭代以下两个步骤来解决优化问题:•使用信息素模型构建候选解,即解空间上的参数化概率分布;•候选解决方案被用来修改信息素值的方式,被认为是偏向未来的抽样向高质量的解决方案。
信息素更新旨在将搜索集中在搜索空间中包含高质量解决方案的区域。
其中,基于解质量的解分量增强是蚁群算法的重要组成部分。它隐含地假设好的解决方案由好的解决方案组件组成。了解哪些组件有助于形成好的解决方案,有助于将它们组合成更好的解决方案
蚁群优化元启发式算法(The ant colony optimization metaheuristic)
接下来就是论文中的算法伪代码(其实那篇博客都讲的差不多了,这样看估计也很难看明白,都是机翻):
蚁群算法是一种迭代算法,其运行时间由算法1的主while循环控制。在每次迭代中,三个算法组件AntBasedSolutionConstruction()、PheromoneUpdate()和DaemonActions()——聚集在ScheduleActivities构造中——必须被调度。ScheduleActivities构造没有指定如何安排和同步这三个活动。这取决于算法设计者。
AntBasedSolutionConstruction()(参见算法2):人工蚂蚁可以被视为概率构造启发式,它将解决方案组装为解决方案组件的序列。解分量的有限集C = {c1,…,cn}由所考虑的离散优化问题导出。例如,在将AS应用于TSP的情况下(参见前一节),TSP图的每个边都被认为是一个解决方案组件。
每个解决方案构造都以空序列s =∁∂开始。然后,在每个构建步骤上,从集合N (s)中添加一个可行解分量,扩展当前序列s。
6 N (s)的规格取决于溶液的构建机制。在将AS应用于TSP的示例中(参见前一节),解构造机制将可遍历边的集合限制为连接蚂蚁当前节点和未访问节点的边。从N (s)中选择一个解决方案组件(参见算法2中的函数ChooseFrom(N (s)))是在每个构建步骤中根据信息素模型概率执行的。在大多数蚁群算法中,各自的概率(也称为转移概率)定义如下:
其中η是一个可选的加权函数,也就是说,有时根据当前序列,在每个构造步骤为每个可行解分量cj∈N (s)分配一个启发式值η(cj)。由加权函数给出的值通常称为启发式信息。此外,指数α和β是正参数,其值决定信息素信息与启发式信息的关系。在前面章节的TSP示例中,我们选择不使用任何加权函数η,并将α设置为1。值得注意的是,通过在算法2中实现函数ChooseFrom(N (s)),从而确定地选择使Eq.(7)最大化的解分量(即c←argmax{η(ci) | ci∈N (s)}),我们获得了一个确定性贪婪算法。
PheromoneUpdate():不同的蚁群算法变体主要不同于它们所应用的信息素值的更新。在下面,我们概述了一个一般的信息素更新规则,以提供基本的想法。信息素更新规则由两部分组成。首先,进行信息素蒸发,均匀地降低所有信息素值。从实际的角度来看,需要信息素蒸发来避免算法过快地收敛到次优区域。它实现了一种有用的遗忘形式,有利于探索搜索空间中的新领域。其次,使用来自当前和/或早期迭代的一个或多个解决方案增加作为这些解决方案一部分的解决方案组件的信息素踪迹参数的值:
DaemonActions():守护进程动作可用于实现单个蚂蚁无法执行的集中操作。例如,将局部搜索方法应用于构造的解决方案,或者收集全局信息,以确定是否有用,从非局部的角度放置额外的信息素以偏差搜索过程。作为一个实际的例子,守护进程可能决定将额外的信息素沉积到属于目前找到的最佳解决方案的解决方案组件上。




然后就是改进(当然也很老了),个人理解大部分创新都不会改变蚁群的迭代机制,即流程不会发生多大变化,优化的都是参数更新机制等,针对某些问题进行优化,比如指数平滑机制等。。。。当然不排除大佬可以搞出很牛逼的东西

然后就是算法的应用领域,毕竟是综述文章
理论结果(Theoretical results)
The first theoretical problem considered was the one concerning convergence. The question is: will a given ACO algorithm find an optimal solution when given enough resources? This is an interesting question, because ACO algorithms are stochastic search procedures in which the pheromone update could prevent them from ever reaching an optimum. Two different types of convergence were considered: convergence in value and convergence in solution.
Convergence in value concerns the probability of the algorithm generating an optimal solution at least once. On the contrary, convergence in solution concerns the evaluation of the probability that the algorithm reaches a state which keeps generating the same optimal solution. The first convergence proofs concerning an algorithm called graph-based ant system (GBAS) were presented by Gutjahr in [53,54]. A second strand of work on convergence focused on a class of ACO algorithms that are among the best-performing in practice, namely, algorithms that apply a positive lower bound τmin to all pheromone values. The lower bound prevents that the probability to generate any solution becomes zero. This class of algorithms includes ACO variants such as ACS and MMAS. Dorigo and Stützle, first in [90] and later in [36], presented a proof for the convergence in value, as well as a proof for the convergence in solution, for algorithms from this class.
Recently, researchers have been dealing with the relation of ACO algorithms to other methods for learning and optimization. One example is the work presented in [6] that relates ACO to the fields of optimal control and reinforcement learning. A more prominent example is the work that aimed at finding similarities between ACO algorithms and other probabilistic learning algorithms such as stochastic gradient ascent (SGA), and the cross-entropy (CE) method.
Zlochin et al [96] proposed a unifying framework called model-based search (MBS) for this type of algorithms.Meuleau and Dorigo have shown in [72] that the pheromone update as outlined in the proof-of-concept application to the TSP [34,35] is very similar to a stochastic gradient ascent in the space of pheromone values. Based on this observation, the authors developed an SGA-based type of ACO algorithm whose pheromone update describes a stochastic gradient ascent. This algorithm can be shown to converge to a local optimum with probability 1. In practice, this SGA-based pheromone update has not been much studied so far. The first implementation of SGA-based ACO algorithms was proposed in [8] where it was shown that SGA-based pheromone updates avoid certain types of search bias.
While convergence proofs can provide insight into the working of an algorithm, they are usually not very useful to the practitioner that wants to implement efficient algorithms. This is because, generally, either infinite time or infinite space are required for an optimization algorithm to converge to an optimal solution (or to the optimal solution value). The existing convergence proofs for particular ACO algorithms are no exception. As more relevant for practical applications might be considered the research efforts that were aimed at a better understanding of the behavior of ACO algorithms. Of particular interest is hereby the understanding of negative search bias that might cause the failure of an ACO algorithm. For example, when applied to the job shop scheduling problem, the average quality of the solutions produced by some ACO algorithms decreases over time. This is clearly undesirable, because instead of successively finding better solutions, the algorithm finds successively worse solutions over time. As one of the principal causes for this search bias were identified situations in which some solution components on average receive update from more solutions than solution components they compete with [12]. Merkle and Middendorf [69,70] were the first to study the behavior of a simple ACO algorithm by analyzing the dynamics of its model, which is obtained by applying the expected pheromone update. Their work deals with the application of ACO to idealized permutation problems. When applied to constrained problems such as permutation problems, the solution construction process of ACO algorithms consists of a sequence of local decisions in which later decisions depend on earlier decisions. Therefore, the later decisions of the construction process are inherently biased by the earlier ones. The work of Merkle and Middendorf shows that this leads to a bias which they call selection bias. Furthermore, the competition between the ants was identified as the main driving force of the algorithm.
第一个考虑的理论问题是关于收敛的问题。问题是:给定的蚁群算法在给定足够的资源时能否找到最优解?这是一个有趣的问题,因为蚁群算法是随机搜索过程,信息素的更新可能会阻止它们达到最优。考虑了两种不同类型的收敛:值收敛和解收敛。
值的收敛性涉及算法至少产生一次最优解的概率。相反,解的收敛性关注的是算法达到不断产生相同最优解的状态的概率的评估。Gutjahr在[53,54]中首次提出了基于图的蚂蚁系统(GBAS)算法的收敛性证明。关于收敛的第二部分工作集中在一类在实践中表现最好的蚁群算法上,即对所有信息素值应用正下界τmin的算法。下界防止生成任何解的概率变为零。这类算法包括ACS和MMAS等蚁群算法的变体。Dorigo和st tzle首先在[90]和后来在[36]中对这类算法给出了值收敛性的证明,以及解收敛性的证明。
近年来,研究人员一直在研究蚁群算法与其他学习和优化方法的关系。其中一个例子是[6]中提出的将蚁群算法与最优控制和强化学习领域联系起来的工作。一个更突出的例子是旨在发现蚁群算法与其他概率学习算法(如随机梯度上升(SGA)和交叉熵(CE)方法)之间的相似性的工作。
Zlochin等人[96]为这类算法提出了一种称为基于模型的搜索(MBS)的统一框架。Meuleau和Dorigo在[72]中表明,信息素更新概述了概念验证应用对TSP的影响[34,35]非常类似于信息素值空间的随机梯度上升。基于这一观察,作者开发了一种基于sga的蚁群算法,其信息素更新描述了随机梯度上升。该算法收敛到局部最优的概率为1。实际上,到目前为止,这种基于sga的信息素更新还没有得到很多研究。基于sga的蚁群算法的第一个实现是在[8]中提出的,其中表明基于sga的信息素更新避免了某些类型的搜索偏差。
虽然收敛证明可以提供对算法工作的深入了解,但对于想要实现高效算法的实践者来说,它们通常不是很有用。这是因为,通常需要无限的时间或无限的空间才能使优化算法收敛到最优解(或最优解值)。已有的特定蚁群算法的收敛性证明也不例外。由于与实际应用更相关,可以考虑旨在更好地理解蚁群算法行为的研究工作。特别感兴趣的是对可能导致蚁群算法失败的负搜索偏差的理解。例如,当应用于作业车间调度问题时,一些蚁群算法产生的解决方案的平均质量随着时间的推移而降低。这显然是不可取的,因为随着时间的推移,算法不是不断地找到更好的解决方案,而是不断地找到更糟糕的解决方案。造成这种搜索偏差的主要原因之一是,某些解决方案组件平均从比与其竞争的解决方案组件更多的解决方案中获得更新[12]。Merkle和Middendorf[69,70]首先通过分析其模型的动力学来研究简单蚁群算法的行为,该模型是通过应用预期信息素更新获得的。他们的工作涉及蚁群算法在理想置换问题中的应用。当应用于排列问题等约束问题时,蚁群算法的解构造过程由一系列局部决策组成,其中后期决策依赖于早期决策。因此,建设过程的后期决策本身就会受到早期决策的影响。梅克尔和米登多夫的研究表明,这导致了一种他们称之为选择偏见的偏见。进一步,确定了蚂蚁之间的竞争是算法的主要驱动力。
将蚁群算法应用于持续优化(Applying ACO to continuous optimization)
Many practical optimization problems can be formulated as continuous optimization problems. These problems are characterized by the fact that the decision variables have continuous domains, in contrast to the discrete domains of the variables in discrete optimization. While ACO algorithms were originally introduced to solve discrete problems, their adaptation to solve continuous optimization problems enjoys an increasing attention. Early applications of ant-based algorithms to continuous optimization include algorithms such as Continuous ACO (CACO) [5], the API algorithm [75], and Continuous Interacting Ant Colony (CIAC) [37]. However, all these approaches are conceptually quite different from ACO for discrete problems. The latest approach, which was proposed by Socha in [86], is closest to the spirit of ACO for discrete problems. In the following we shortly outline this algorithm. For the sake of simplicity, we assume the continuous domains of the decision variables Xi, i = 1,…,n, to be unconstrained.
As outlined before, in ACO algorithms for discrete optimization problems solutions are constructed by sampling at each construction step a discrete probability distribution that is derived from the pheromone information. In a way, the pheromone information represents the stored search experience of the algorithm. In contrast, ACO for continuous optimization—in the literature denoted by ACOR—utilizes a continuous probability density function (PDF). This density function is produced, for each solution construction, from a population of solutions that the algorithm keeps at all times. The management of this population works as follows. Before the start of the algorithm, the population—whose cardinality k is a parameter of the algorithm—is filled with random solutions. This corresponds to the pheromone value initialization in ACO algorithms for discrete optimization problems. Then, at each iteration the set of generated solutions is added to the population and the same number of the worst solutions are removed from it. This action corresponds to the pheromone update in discrete ACO. The aim is to bias the search process towards the best solutions found during the search.
For constructing a solution, an ant chooses at each construction step i = 1,…,n, a value for decision variable Xi.
In other words, if the given optimization problem has n dimensions, an ant chooses in each of n construction steps a value for exactly one of the dimensions. In the following we explain the choice of a value for dimension i. For performing this choice an ant uses a Gaussian kernel, which is a weighted superposition of several Gaussian functions,
许多实际的优化问题都可以表述为连续优化问题。这些问题的特点是决策变量具有连续域,而不是离散优化中变量的离散域。蚁群算法最初是为了解决离散问题而引入的,但其对连续优化问题的适应性越来越受到关注。基于蚁群算法在连续优化中的早期应用包括连续蚁群算法(continuous ACO, CACO)[5]、API算法[75]和连续交互蚁群算法(continuous interaction Ant Colony, CIAC)[37]。然而,所有这些方法在概念上与离散问题的蚁群算法有很大的不同。Socha在[86]中提出的最新方法最接近离散问题的蚁群算法精神。在下文中,我们将简要概述该算法。为简单起见,我们假设决策变量Xi, i = 1,…的连续域。n,不受约束。
如前所述,在离散优化问题的蚁群算法中,通过在每个构建步骤中采样从信息素信息中导出的离散概率分布来构建解决方案。在某种程度上,信息素信息代表了算法存储的搜索经验。相比之下,用于连续优化的蚁群算法(在文献中用acor表示)使用连续概率密度函数(PDF)。对于每个解构造,这个密度函数是由算法始终保持的解的总体产生的。这一人口的管理工作如下。在算法开始之前,种群(其基数k是算法的一个参数)被随机解填充。这对应于离散优化问题的蚁群算法中的信息素值初始化。然后,在每次迭代中,将生成的解决方案集添加到总体中,并从中删除相同数量的最差解决方案。这个动作对应于离散蚁群算法中信息素的更新。其目的是使搜索过程偏向于在搜索过程中找到的最佳解决方案。
一个新的趋势:人工智能和OR技术的杂交(A new trend: Hybridization with AI and OR techniques)
Hybridization is nowadays recognized to be an essential aspect of high performing algorithms. Pure algorithms are almost always inferior to hybridizations. In fact, many of the current state-of-the-art ACO algorithms include components and ideas originating from other optimization techniques. The earliest type of hybridization was the incorporation of local search based methods such as local search, tabu search, or iterated local search, into ACO.
However, these hybridizations often reach their limits when either large-scale problem instances with huge search spaces or highly constrained problems for which it is difficult to find feasible solutions are concerned. Therefore, some researchers recently started investigating the incorporation of more classical AI and OR methods into ACO algorithms. One reason why ACO algorithms are especially suited for this type of hybridization is their constructive nature. Constructive methods can be considered from the viewpoint of tree search [45]. The solution construction mechanism of ACO algorithms maps the search space to a tree structure in which a path from the root node to a leaf corresponds to the process of constructing a solution (see Fig. 6). Examples for tree search methods from AI and OR are greedy algorithms [79], backtracking techniques [45], rollout and pilot techniques [3,38], beam search [78], or constraint programming (CP) [68].
杂交是目前公认的高性能算法的一个重要方面。纯算法几乎总是不如杂交算法。事实上,许多当前最先进的蚁群算法包含了源自其他优化技术的组件和思想。最早的杂交类型是将基于局部搜索的方法(如局部搜索、禁忌搜索或迭代局部搜索)结合到蚁群算法中。
然而,当涉及具有巨大搜索空间的大规模问题实例或难以找到可行解的高度约束问题时,这些杂交方法往往会达到极限。因此,一些研究人员最近开始研究将更经典的人工智能和OR方法结合到蚁群算法中。蚁群算法特别适合这种杂交的一个原因是它们的构造性质。可以从树搜索的角度考虑构造方法[45]。蚁群算法的解构建机制将搜索空间映射到树形结构,其中从根节点到叶节点的路径对应于构建解的过程(见图6)。AI和OR中树形搜索方法的示例有贪心算法[79]、回溯技术[45]、rollout和pilot技术[3,38]、束搜索[78]或约束规划(CP)[68]。
Conclusions
In this work we first gave a detailed description of the origins and the basics of ACO algorithms. Then we outlined the general framework of the ACO metaheuristic and presented some of the most successful ACO variants today.
After listing some representative applications of ACO, we summarized the existing theoretical results and outlined the latest developments concerning the adaptation of ACO algorithms to continuous optimization. Finally, we provided a survey on a very interesting recent research direction: The hybridization of ACO algorithms with more classical artificial intelligence and operations research methods. As examples we presented the hybridization with beam search and with constraint programming. The central idea behind these two approaches is the reduction of the search space that has to be explored by ACO. This can be especially useful when large scale problem instances are considered. Other hybridization examples are the application of ACO for solution refinement in multilevel frameworks, and the application of ACO to auxiliary search spaces. In the opinion of the author, this research direction offers many possibilities for valuable future research.
在这项工作中,我们首先给出了蚁群算法的起源和基础的详细描述。然后,我们概述了蚁群算法元启发式的一般框架,并介绍了当今一些最成功的蚁群算法变体。
在列举了蚁群算法的一些代表性应用之后,总结了已有的理论成果,并概述了蚁群算法适应连续优化的最新进展。最后,我们对最近一个非常有趣的研究方向进行了综述:蚁群算法与更经典的人工智能和运筹学方法的杂交。作为例子,我们给出了束搜索和约束规划的杂交。这两种方法背后的中心思想是减少蚁群算法必须探索的搜索空间。这在考虑大规模问题实例时尤其有用。其他的杂交例子是在多层框架中应用蚁群算法进行解精化,以及在辅助搜索空间中应用蚁群算法。笔者认为,这一研究方向为未来有价值的研究提供了许多可能性。

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









