







目录
1.引例:两个练习题
2.定义基本的存储结构
#pragma once
namespace CloseHash
{
template<class K,class V>
struct HashData
{
pair<K, V> _kv;
};
template<class K,class V>
class HashTable
{
private:
HashData* _table;
size_t _size;
size_t _capacity; //用于增容
};
}后者直接用vector存储
#pragma once
#include<vector>
#include<iostream>
using namespace std;
namespace CloseHash
{
template<class K,class V>
struct HashData
{
pair<K, V> _kv;
};
template<class K,class V>
class HashTable
{
public://待写
private:
//HashData* _table;
//size_t _size;
//size_t _capacity; //用于增容
vector<HashData> _table;
size_t _n;//存储的有效数据的个数
};
}3.Insert()
如何判断一个位置是空还是满?若删除其中一个值,用空值去标识,下一次找后面冲突的值找不到了。前一个冲突的值被删了,导致不连续了,找到空就结束了。

提供一个状态标识即可
namespace CloseHash
{
enum State//状态
{
EMPTY,
EXITS,
DELTE,
};
template<class K,class V>
struct HashData
{
pair<K, V> _kv;
State _state = EMPTY;//默认状态给空
};
template<class K,class V>
class HashTable
{
public://待写函数
private:
//HashData* _table;
//size_t _size;
//size_t _capacity; //用于增容
vector<HashData> _table;
size_t _n;//存储的有效数据的个数
};
} bool Insert(const pair<K, V>& kv)
{
HashData<K, V>* ret = Find(kv, first);
if (ret)
{
return false;
}
//判断是否满
//计算负载因子,大于0.7就增容
//if (_n*10 / _table.size() > 7)
if (_tabale.size() == 0)
{
_table.resize(10);
}
else if ((double)_n / (double)_table.size() > 0.7)
{
//方法一,不足之处在于要重复写插入逻辑
//vector<HashData>newtable;
//newtable.resize(_table.size*2); 新表增容,增到旧表的二倍
//for (auto& e : _table)
//{
// if (e._table == EXITS)
// {
// //重新计算放到newtable中去
// //跟下面插入逻辑类似
// }
//}
//_table.swap(newtable);
HashTable<K, v>newHT;
newHT._table.resize(_table.size() * 2);
for (auto& e : _table)
{
if (e._state == EXITS)
{
newHT.Insert(e._kv);
}
}
_table.swap(newHT._table);
}
size_t start = kv.first % _table.size();//不能%_table.capacity()
size_t index = start;
//探测后面的位置 -- 线性探测或二次探测
size_t i = 1;
while (_table[index]._state == EXITS)
{
index += start + i;//此处的线性探测想改成二次探测将i改为i*i即可
index %= _table.size();
++i;
}
_table[index]._kv = kv;
_table[index]._state = EXITS;
++_n;
return true;
}
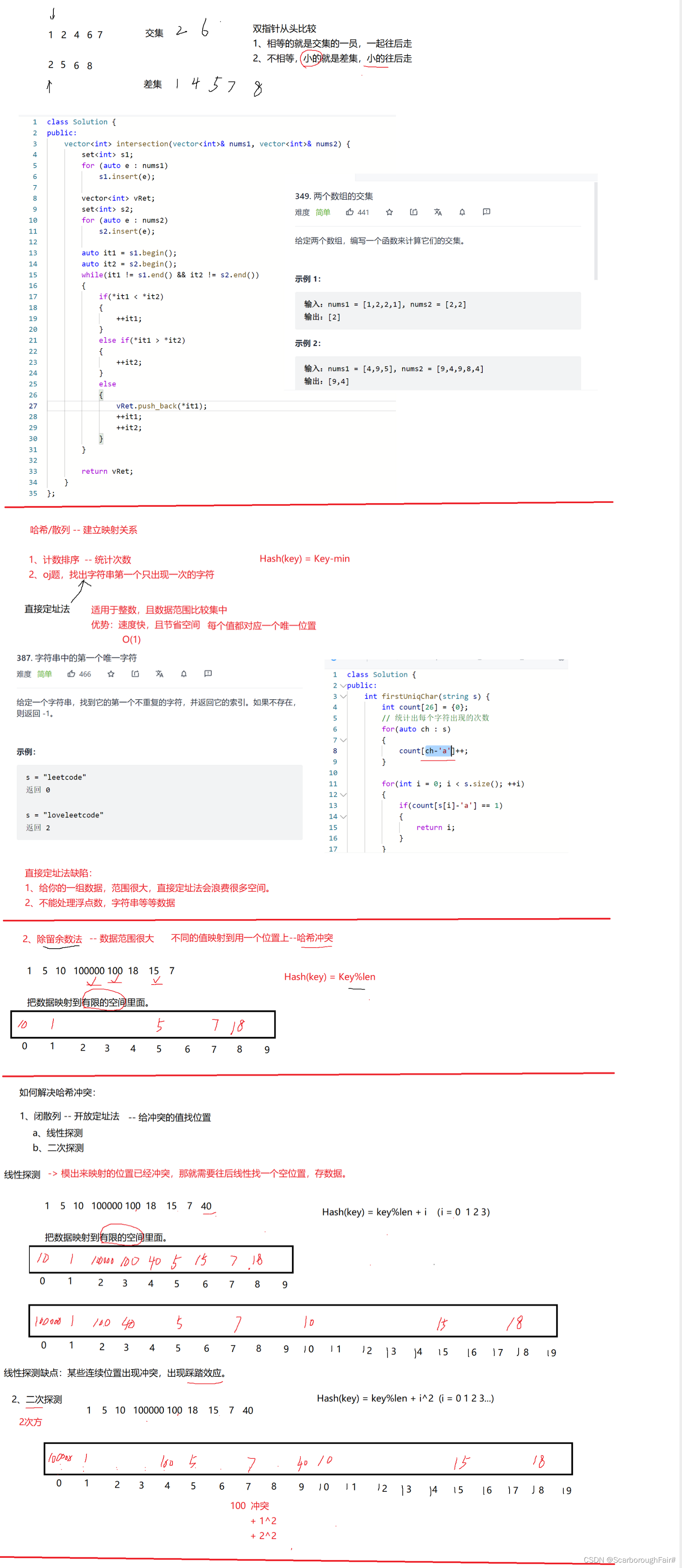
HashData<K, V>* Find(const K& key)
{
//排除0的情况
if (_table.size() == 0)
{
return nullptr;
}
size_t start = key % _table.size();
size_t index = start;
size_t i = 1;
while (_table[index]._state != EMPTY)
{
if (_table[index]._state == EXITS//避免已经删除的元素仍可被寻找的情况
&& _table[index]._kv.first == key)
{
return &_table[index];
}
inded = start + i;
index %= _table.size();
++i;
}
return nullptr;
}4.Erase()
bool Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret == nullptr)
{
return false;
}
else
{
ret->_state = DELETE;
return true;
}
}5.string为参数的情况
若出现下面测试代码的情况,如何更改?
void TestHashTable2()
{
string a[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "橘子", "苹果" };
HashTable<string, int> ht;
for (auto str : a)//string作k的情况
{
auto ret = ht.Find(str);
if (ret)
{
ret->_kv.second++;
}
else
{
ht.Insert(make_pair(str, 1));
}
}
}所有要取模的地方添加仿函数,该仿函数的功能就是将数据转换成整型。
struct IniHashFunc
{
int operator()(int i)
{
return i;
}
};
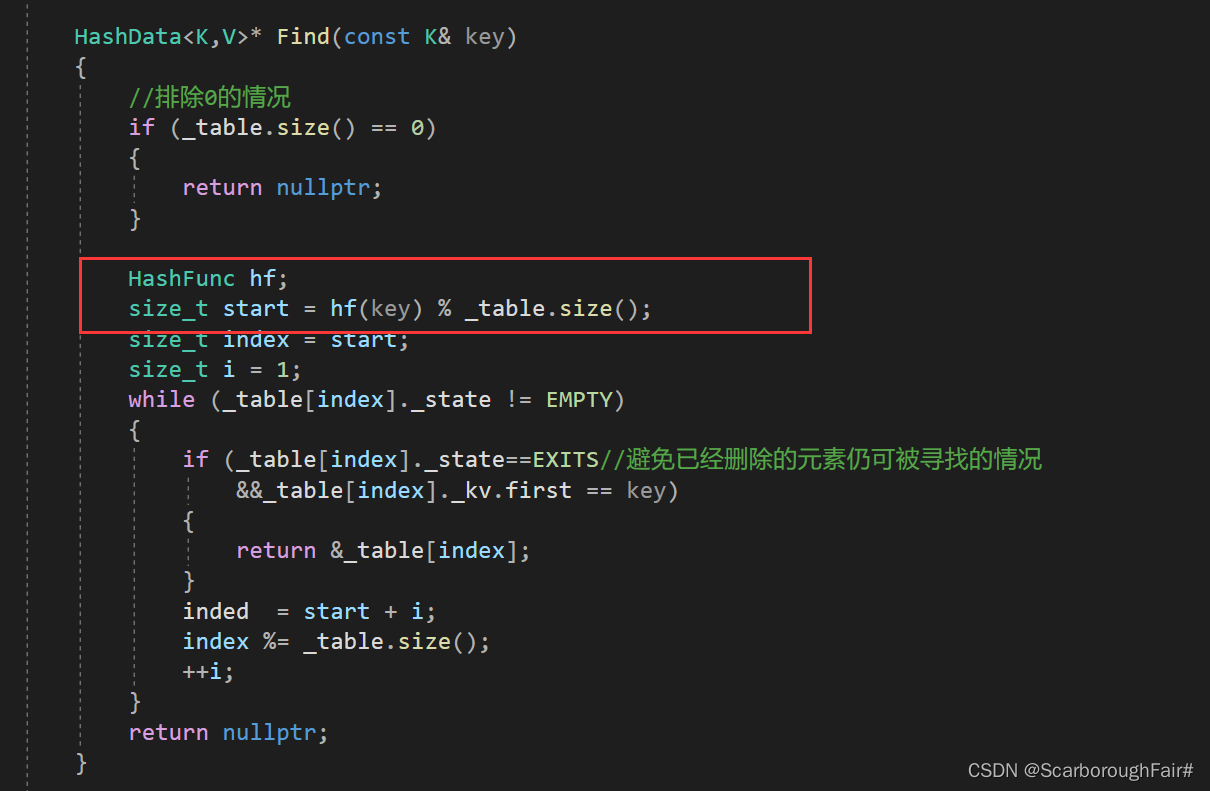
特别的,将字符串转换成整型的仿函数仍存在问题。采用字符串哈希算法的思路改正即可 各种字符串Hash函数 - clq - 博客园

以此类推,K为不同类型元素的情况写对应的仿函数即可
思考:
一个类型去作map/set的Key有什么要求? 能支持比较大小
一个类型去作unordered_map/unordered_set的Key有什么要求? 能支持转换成整型+相等比较
6.添加类模板
可以转化成整型的数据采用下面模板,返回值为int
template<class K>
struct Hash
{
size_t operator()(const K& key)
{
return key;
}
};当K是string时不会走原生的模板,采用特化单独创建一个模板
template<>
struct Hash<string>
{
//字符串转成对应的整型,整型才能取模算映射位置
//期望->字符串不同,转出的整型值尽量不同
size_t operator()(const string& s)
{
//return s[0]; 存在int insert类似首字母相同的情况
//存在abcd,bcad或abbb.abca的情况(ascii码和相同的情况)
size_t value = 0;
for (auto ch : s)
{
value += ch;
value *= 131;//采用BKDRHash算法的思想 乘以131
}
return value;
}
};使用类模板后不同的数据类型会调用不同类型的仿函数
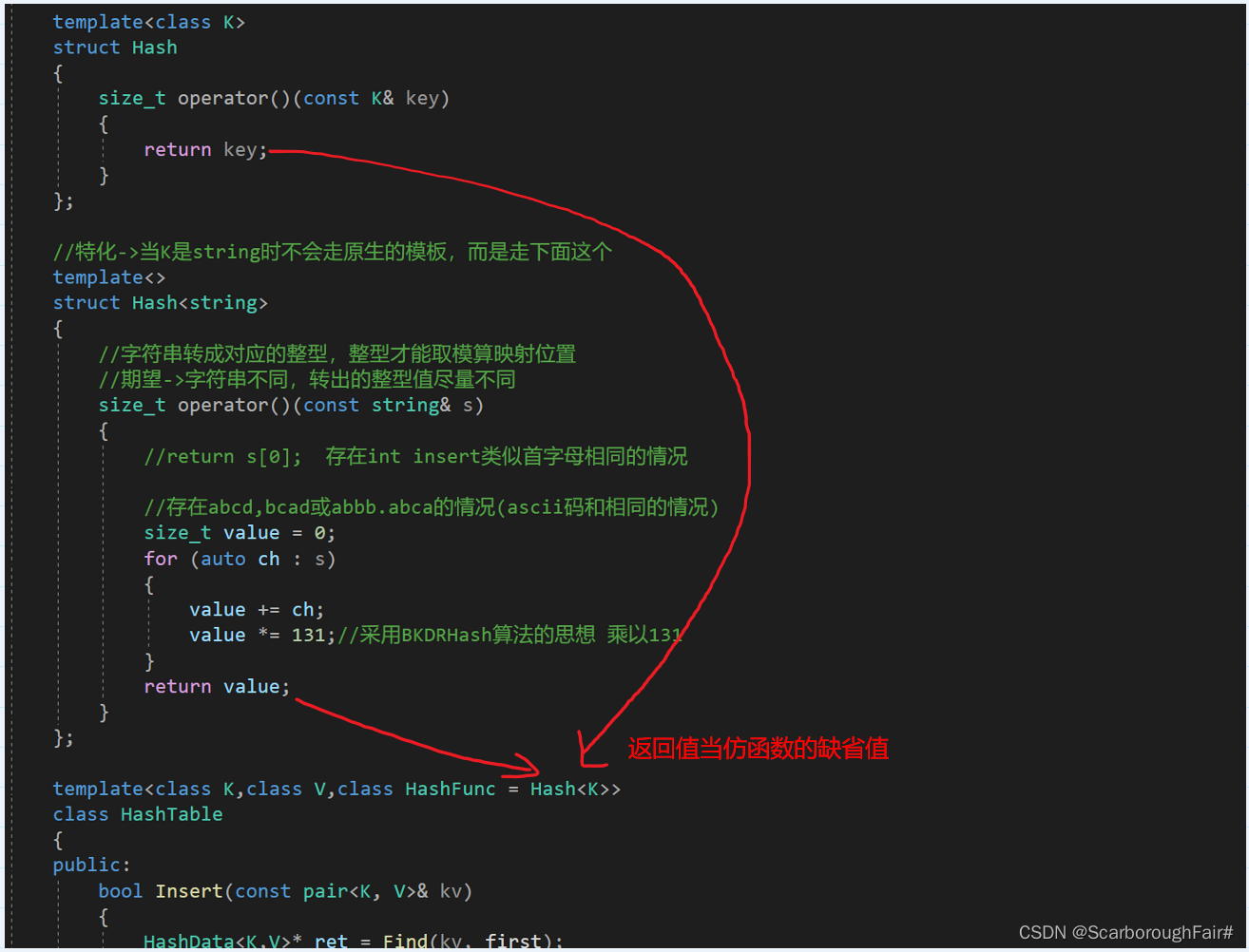
此时可以省略仿函数,参数自动使用隐式类型转换

7.整体代码
#pragma once
#include <vector>
#include <iostream>
using namespace std;
namespace CloseHash
{
enum State
{
EMPTY,
EXITS,
DELETE,
};
template<class K, class V>
struct HashData
{
pair<K, V> _kv;
State _state = EMPTY; // 状态
};
template<class K>
struct Hash
{
size_t operator()(const K& key)
{
return key;
}
};
// 特化
template<>
struct Hash<string>
{
// "int" "insert"
// 字符串转成对应一个整形值,因为整形才能取模算映射位置
// 期望->字符串不同,转出的整形值尽量不同
// "abcd" "bcad"
// "abbb" "abca"
size_t operator()(const string& s)
{
// BKDR Hash
size_t value = 0;
for (auto ch : s)
{
value += ch;
value *= 131;
}
return value;
}
};
template<class K, class V, class HashFunc = Hash<K>>
class HashTable
{
public:
bool Insert(const pair<K, V>& kv)
{
HashData<K,V>* ret = Find(kv.first);
if (ret)
{
return false;
}
// 负载因子大于0.7,就增容
//if (_n*10 / _table.size() > 7)
if (_table.size() == 0)
{
_table.resize(10);
}
else if ((double)_n / (double)_table.size() > 0.7)
{
//vector<HashData> newtable;
// newtable.resize(_table.size*2);
//for (auto& e : _table)
//{
// if (e._state == EXITS)
// {
// // 重新计算放到newtable
// // ...跟下面插入逻辑类似
// }
//}
//_table.swap(newtable);
HashTable<K, V, HashFunc> newHT;
newHT._table.resize(_table.size() * 2);
for (auto& e : _table)
{
if (e._state == EXITS)
{
newHT.Insert(e._kv);
}
}
_table.swap(newHT._table);
}
HashFunc hf;
size_t start = hf(kv.first) % _table.size();
size_t index = start;
// 探测后面的位置 -- 线性探测 or 二次探测
size_t i = 1;
while (_table[index]._state == EXITS)
{
index = start + i;
index %= _table.size();
++i;
}
_table[index]._kv = kv;
_table[index]._state = EXITS;
++_n;
return true;
}
HashData<K,V>* Find(const K& key)
{
if (_table.size() == 0)
{
return nullptr;
}
HashFunc hf;
size_t start = hf(key) % _table.size();
size_t index = start;
size_t i = 1;
while (_table[index]._state != EMPTY)
{
if (_table[index]._state == EXITS
&& _table[index]._kv.first == key)
{
return &_table[index];
}
index = start + i;
index %= _table.size();
++i;
}
return nullptr;
}
bool Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret == nullptr)
{
return false;
}
else
{
ret->_state = DELETE;
return true;
}
}
private:
/* HashData* _table;
size_t _size;
size_t _capacity;*/
vector<HashData<K, V>> _table;
size_t _n = 0; // 存储有效数据的个数
};
void TestHashTable1()
{
int a[] = { 1, 5, 10, 100000, 100, 18, 15, 7, 40};
HashTable<int, int> ht;
for (auto e : a)
{
ht.Insert(make_pair(e, e));
}
auto ret = ht.Find(100);
if (ret)
{
cout << "找到了"<<endl;
}
else
{
cout << "没有找到了" << endl;
}
ht.Erase(100);
ret = ht.Find(100);
if (ret)
{
cout << "找到了" << endl;
}
else
{
cout << "没有找到了" << endl;
}
}
struct stringHashFunc
{
// "int" "insert"
// 字符串转成对应一个整形值,因为整形才能取模算映射位置
// 期望->字符串不同,转出的整形值尽量不同
// "abcd" "bcad"
// "abbb" "abca"
size_t operator()(const string& s)
{
// BKDR Hash
size_t value = 0;
for (auto ch : s)
{
value += ch;
value *= 131;
}
return value;
}
};
void TestHashTable2()
{
string a[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "橘子", "苹果" };
HashTable<string, int> ht;
for (auto str : a)
{
auto ret = ht.Find(str);
if (ret)
{
ret->_kv.second++;
}
else
{
ht.Insert(make_pair(str, 1));
}
}
}
struct Student
{
// ...
};
struct StudentHashFunc
{
size_t operator()(const Student& kv)
{
// 如果是结构体
// 1、比如说结构体中有一个整形,基本是唯一值 - 学号
// 2、比如说结构体中有一个字符串,基本是唯一值 - 身份证号
// 3、如果没有一项是唯一值,可以考虑多项组合
size_t value = 0;
// ...
return value;
}
};
void TestHashTable3()
{
string a[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "橘子", "苹果" };
// 任意类型都可以做key,跟上一个把这个类型对象转换成整形的仿函数即可
HashTable<Student, int, StudentHashFunc> ht;
}
void TestStringHashFunc()
{
stringHashFunc hf;
cout << hf("insert")<<endl;
cout << hf("int") << endl<<endl;
cout << hf("abcd") << endl;
cout << hf("bacd") << endl << endl;
cout << hf("abbb") << endl;
cout << hf("abca") << endl << endl;
}
}















 5580
5580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









