







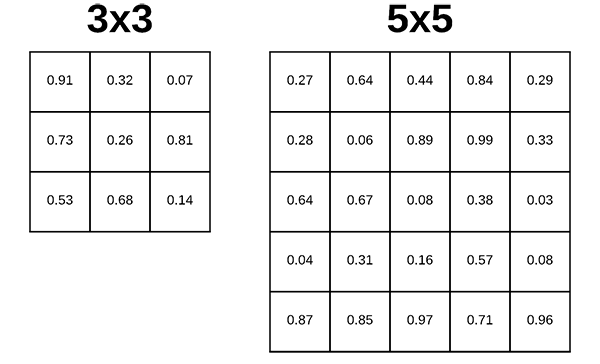
图2: 深度学习 Conv2D 参数,决定了内核的维度。常见的尺寸包括 1×1、3×3、5×5 和 *7×7,*这些尺寸可以以"或"tuples"的身份传递。 filter_size:(1, 1)、(3, 3)、(5, 5)、(7, 7)
您需要提供给 Keras Conv2D 类的第二个必需参数是 kernel_size ,它是一个 2 元组,指定了 2D 卷积窗口的宽度和高度。 kernel_size 也必须是奇数。 kernel_size 的典型值包括: (1, 1) , (3, 3) , (5, 5) , (7, 7) 。 很少看到大于 7×7 的内核大小。
那么,你什么时候使用每个?
如果您的输入图像大于 128×128,您可以选择使用大于 3 的内核大小来这样做的好处:
(1) 学习更大的空间过滤器
(2)帮助减小体积大小。
其他网络,例如 VGGNet,在整个网络中专门使用 (3, 3) 过滤器。 更高级的架构如 Inception、ResNet 和 SqueezeNet 设计了整个微架构,它们是网络内部的“模块”,可以学习不同尺度(即 1×1、3×3 和 5×5)的局部特征,然后结合输出。 在下面的 Inception 模块中可以看到一个很好的例子:
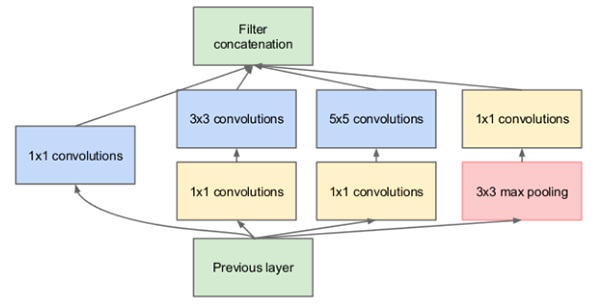
图3: Inception/GoogLeNet CNN 架构在网络内部使用“微架构”模块,学习不同尺度(filter_size)的局部特征,然后组合输出。
ResNet 架构中的 Residual 模块使用 1×1 和 3×3 过滤器作为一种降维形式,这有助于保持网络中的参数数量较少(或在给定网络深度的情况下尽可能少) ):
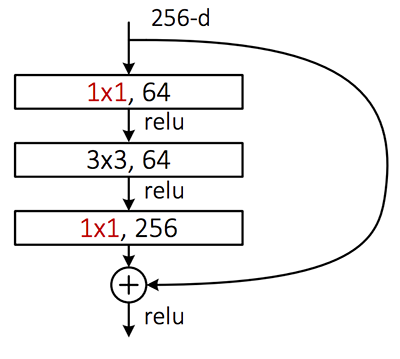
图4: ResNet“残差模块”使用 1×1 和 3×3 过滤器进行降维。 这有助于用更少的参数使整个网络更小。
那么,您应该如何选择 filter_size ? 首先,检查你的输入图像——它是否大于 128×128? 如果是这样,请考虑使用 5×5 或 7×7 内核来学习更大的特征,然后快速减少空间维度——然后开始使用 3×3 内核:
model.add(Conv2D(32, (7, 7), activation=“relu”))
…
model.add(Conv2D(32, (3, 3), activation=“relu”))
如果您的图像小于 128×128,您可能需要考虑坚持使用小点的 1×1 和 3×3 过滤器。
==================================================================
strides 参数是一个 2 元组整数,指定沿输入体积的 x 和 y 轴的卷积“步长”。
strides 值默认为 (1, 1) ,这意味着:
-
给定的卷积滤波器应用于输入体积的当前位置
-
过滤器向右移动 1 个像素,然后过滤器再次应用于输入体积
-
这个过程一直执行,直到我们到达体积的最右侧边界,我们将过滤器向下移动一个像素,然后从最左侧重新开始
通常,您会将 strides 参数保留为默认 (1, 1) 值; 但是,您可以偶尔将其增加到 (2, 2) 以帮助减小输出体积的大小(因为滤波器的步长较大)。 通常,您会看到 2×2 步幅作为最大池化的替代:
model.add(Conv2D(128, (3, 3), strides=(1, 1), activation=“relu”))
model.add(Conv2D(128, (3, 3), strides=(1, 1), activation=“relu”))
model.add(Conv2D(128, (3, 3), strides=(2, 2), activation=“relu”))
在这里我们可以看到前两个 Conv2D 层的步幅为 1×1。 最终的 Conv2D 层; 然而,它代替了最大池化层,而是通过跨步卷积减少了输出体积的空间维度。
2014 年,Springenber 等人。 发表了一篇题为 Striving for Simplicity: The All Convolutional Net 的论文,该论文证明在某些情况下用跨步卷积替换池化层可以提高准确性。
ResNet 是一种流行的 CNN,已经接受了这一发现——如果您查看 ResNet 实现的源代码(或自己实现它),您会看到 ResNet 响应跨步卷积而不是最大池化以减少两者之间的空间维度 残余模块。
==================================================================

图5: 应用于带有填充的图像的 3×3 内核。 Keras Conv2D 填充参数接受“valid”(无填充)或“same”(填充 + 保留空间维度)。 此动画贡献给 StackOverflow。
Keras Conv2D 类的填充参数可以采用以下两个值之一: valid 或 same 。 使用有效参数,输入体积不会被零填充,并且空间维度可以通过卷积的自然应用减少。 下面的例子自然会减少我们体积的空间维度:
model.add(Conv2D(32, (3, 3), padding=“valid”))
如果您想要保留体积的空间尺寸,以便输出体积大小与输入体积大小匹配,那么您需要为 padding 提供“same”的值:
model.add(Conv2D(32, (3, 3), padding=“same”))
虽然默认的 Keras Conv2D 值是有效的,但我通常会将其设置为网络中大多数层的相同值,
然后通过以下任一方式减少我的体积的空间维度:
最大池化
- 跨步卷积
我建议您也使用类似的方法来填充 Keras Conv2D 类。
=======================================================================
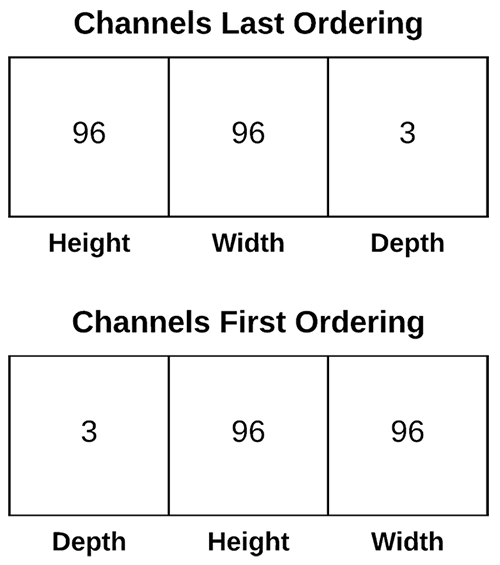
图 6: Keras 作为高级框架,支持多个深度学习后端。 因此,它包括对“channels last”和“channels last”通道排序的支持。
Conv2D 类中的数据格式值可以是 channels_last 或 channels_first : Keras 的 TensorFlow 后端使用最后排序的通道。 Theano 后端使用通道优先排序。
由于以下两个原因,您通常不必像 Keras 那样触及此值:
- 您很有可能使用 TensorFlow 后端到 Keras
- 如果没有,你可能已经更新了你的 ~/.keras/keras.json 配置文件来设置你的后
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









