







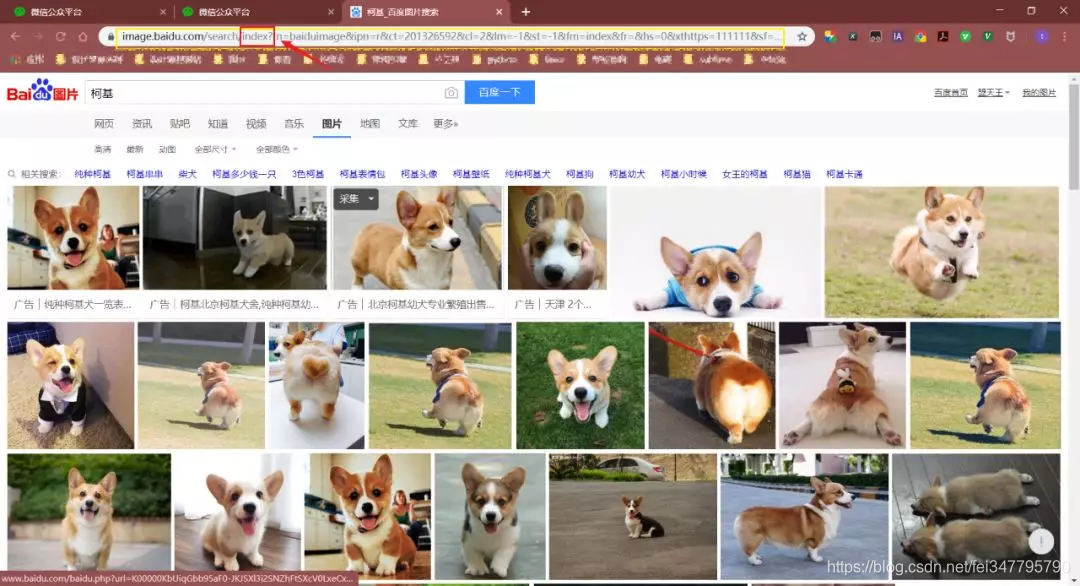
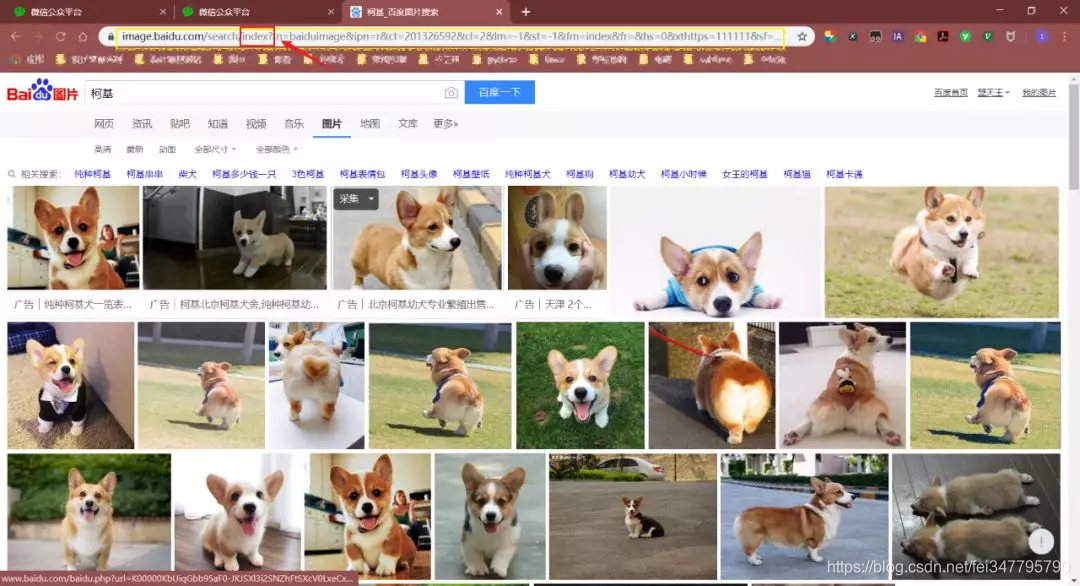
 本文介绍了使用Python爬虫批量下载百度图片的方法。首先,通过分析百度图片的URL发现pn参数控制页数,每页最多60张图片。然后,利用正则表达式匹配网页源代码中的objURL,获取原始图片链接,并将其保存到本地。通过get_parse_page函数获取指定页数的图片链接,再调用save_to_txt函数创建文件夹并下载图片。
本文介绍了使用Python爬虫批量下载百度图片的方法。首先,通过分析百度图片的URL发现pn参数控制页数,每页最多60张图片。然后,利用正则表达式匹配网页源代码中的objURL,获取原始图片链接,并将其保存到本地。通过get_parse_page函数获取指定页数的图片链接,再调用save_to_txt函数创建文件夹并下载图片。
本文介绍了使用Python爬虫批量下载百度图片的方法。首先,通过分析百度图片的URL发现pn参数控制页数,每页最多60张图片。然后,利用正则表达式匹配网页源代码中的objURL,获取原始图片链接,并将其保存到本地。通过get_parse_page函数获取指定页数的图片链接,再调用save_to_txt函数创建文件夹并下载图片。
本文介绍了使用Python爬虫批量下载百度图片的方法。首先,通过分析百度图片的URL发现pn参数控制页数,每页最多60张图片。然后,利用正则表达式匹配网页源代码中的objURL,获取原始图片链接,并将其保存到本地。通过get_parse_page函数获取指定页数的图片链接,再调用save_to_txt函数创建文件夹并下载图片。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















10-24
 498
498
498
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









