







print(df.describe())
由于CSV文件内的数据是字符串形式,先用正则表达式将字符串转化为列表,再取区间的均值
pattern = ‘\d+’
df[‘工作年限’] = df[‘工作经验’].str.findall(pattern)
avg_work_year = []
for i in df[‘工作年限’]:
如果工作经验为’不限’或’应届毕业生’,那么匹配值为空,工作年限为0
if len(i) == 0:
avg_work_year.append(0)
如果匹配值为一个数值,那么返回该数值
elif len(i) == 1:
avg_work_year.append(int(‘’.join(i)))
如果匹配值为一个区间,那么取平均值
else:
num_list = [int(j) for j in i]
avg_year = sum(num_list)/2
avg_work_year.append(avg_year)
df[‘经验’] = avg_work_year
将字符串转化为列表,再取区间的前25%,比较贴近现实
df[‘salary’] = df[‘工资’].str.findall(pattern)
avg_salary = []
for k in df[‘salary’]:
int_list = [int(n) for n in k]
avg_wage = int_list[0]+(int_list[1]-int_list[0])/4
avg_salary.append(avg_wage)
df[‘月工资’] = avg_salary
将清洗后的数据保存,以便检查
df.to_csv(‘draft.csv’, index = False)
我们将职位福利这一列的数据汇总,生成一个字符串,按照词频生成词云实现python可视化。以下是原图和词云的对比图,可见五险一金在职位福利里出现的频率最高,平台、福利、发展空间、弹性工作次之。

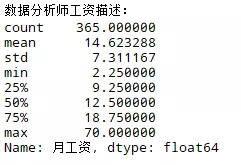
可知,数据分析师的均值在14.6K,中位数在12.5K,算是较有前途的职业。数据分析散布在各个行业,但在高级层面上涉及到数据挖掘和机器学习,在IT业有长足的发展。
我们再来看工资的分布,这对于求职来讲是重要的参考:

工资在10-15K的职位最多,在15-20K的职位其次。个人愚见,10-15K的职位以建模为主,20K以上的职位以数据挖掘、大数据架构为主。
我们再来看职位在各区的分布:

数据分析职位有62.9%在南
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5200
5200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









