









 本文介绍了基于Python的招聘网站信息爬虫系统,利用Python爬取智联招聘网数据,通过MySQL存储并进行数据清洗、分析,实现可视化展示,提升数据挖掘效率。系统包括用户登录、数据爬取、数据管理等功能,旨在优化招聘数据分析过程。
本文介绍了基于Python的招聘网站信息爬虫系统,利用Python爬取智联招聘网数据,通过MySQL存储并进行数据清洗、分析,实现可视化展示,提升数据挖掘效率。系统包括用户登录、数据爬取、数据管理等功能,旨在优化招聘数据分析过程。
收藏关注不迷路
前言
随着社会经济的快速发展,人们的生活水平得到了显著提高,但随之而来的社会问题也越来越多。其中最为显著的就是就业问题。为此,招聘信息的展示也变得越来越为重要。但是在大量的招聘信息中,人们在提取自己最想要的信息时变得不那么容易,对于应聘者也是如此。本系统通过对网络爬虫的分析,研究智联招聘网站数据,尝试使用Python技术进行开发,将智联招聘网招聘信息尽可能的爬取出来,并对结果进行检测判断,最后可视化分析出来,为用户提供精确的查询结果。基于Python的招聘网站信息爬取与数据分析系统旨在提高数据挖掘的效率,便于科学的管理和分析招聘数据。
本文先分析基于Python的招聘网站信息爬取与数据分析系统的背景和意义;对常见的爬虫原理,获取策略,信息提取等技术进行分析;本系统使用python进行开发,MySQL数据库进行搭建,实现了招聘的数据爬取;对数据库的查询结果进行检测并可视化分析,对系统的前台界面进行管理,分析爬取的结果,并对招聘数据结果进行大屏显示;最后通过测试实现了数据爬取,存储过滤和数据可视化分析,以及系统管理等功能。
[关键词] 爬虫,python,大数据,关键字,招聘数据
一、项目介绍
在技术上,本文利用Python技术进行数据爬取,这种简洁快速,类库丰富的编程语言可以轻松的实现爬虫方法。先分析目标网站的网页信息,然后进行数据处理,完成抓取后进行数据存储,最后完成数据的可视化呈现。数据存储使用的是MySQL数据库,这种数据库轻巧而功能强大,可以有效的满足系统的开发。
在业务上,本系统利用用户无法在海量的智联招聘网中查找到有效的招聘数据,因此设计了本系统对招聘数据进行存储,然后整理招聘数据,并通过可视化的方式展现出来。在后台也可以对这些招聘数据进行整理,为用户提供更加精确的招聘数据信息。。
二、开发环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
开发软件:PyCharm/vs code
前端框架:vue.js
————————————————
三、功能介绍
3.2.1爬虫功能需求分析
在目前计算机信息化快速发展过程中,招聘和求职逐渐转移到网络中来,本题目来源于求职招聘系统研发项目的子项目,该项目主要完成一个招聘数据系统的设计和开发,该系统用于收集当前地方招聘数据,然后通过爬取、清理、存储、统计招聘数据,并进行招聘数据,是现代化招聘管理不可缺少的部分,为热门岗位的推荐提供便捷的模式。本文旨在对智联招聘网上的招聘信息、岗位信息进行爬取,收集各种类型的招聘数据信息。然后对招聘数据的内容进行分析,整理招聘数据信息。本系统首先分析智联招聘网站的网站结构,查看网站网页的排版,然后读取其包含的招聘信息。具体分为以下几个步骤,指定智联招聘网url,爬取网页信息,获取特定的智联招聘网url存入队列中,提取招聘数据的信息,将信息存入数据库,然后对岗位和薪资等进行分析,得出招聘数据的可视化视图。
图3-1所示数据清洗和加工用例。
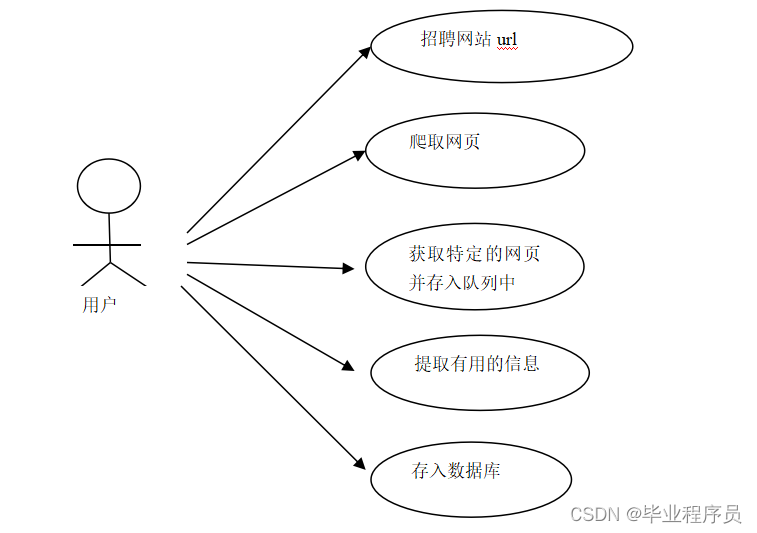
图3-1 数据清洗和加工用例
在本需求分析阶段,不需要关注如何爬取,只需要关注爬取什么样的信息,进行怎样的操作即可,所以先分析智联招聘网网站的数据,确定满足系统要求后,然后查看目标网站,将智联招聘网内的有关招聘数据进行提取,最后将信息存储到数据库。
3.2.2数据可视化功能需求分析
爬取完招聘数据后,需要对数据进行分析,根据评分和K-means聚类算法分析出招聘数据趋势,并可视化查询处理。本系统使用Python进行编程,通过HTML、JS等方法显示数据。具体包括:招聘数据数据展示、招聘数据分类、用户注册登录、用户管理和爬虫数据管理。其中可视化功能用例图如图3-2所示。
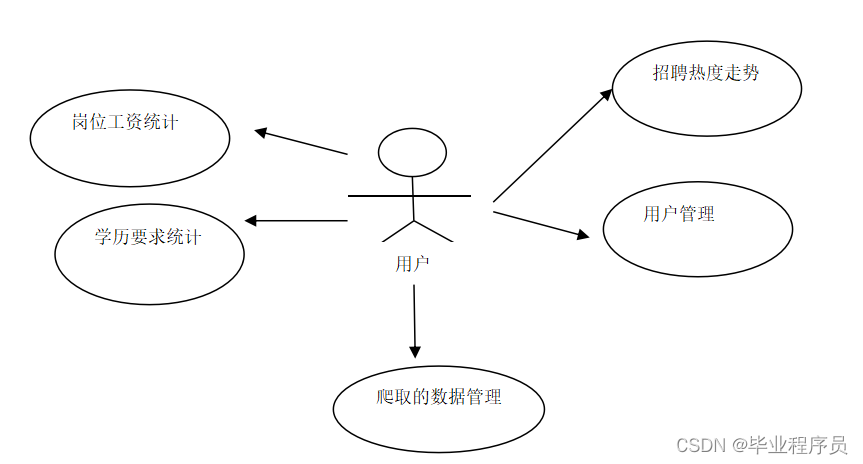
图3-2 数据分析展示用例
基于Python的招聘网站信息爬取与数据分析系统用户登录,先验证信息、成功启动系统后进行登录。登录验证成功后,获取到登录权限,跳转到系统首页。
进入到基于Python的招聘网站信息爬取与数据分析系统大屏界面,通过图形化显示出岗位工资统计、学历要求统计、工作年限统计、招聘热度统计、行业占比统计、招聘人数统计、福利待遇统计。如果查询失败,返回基于Python的招聘网站信息爬取与数据分析系统的错误页面。
四、核心代码
部分代码:
def users_login(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
if req_dict.get('role')!=None:
del req_dict['role']
datas = users.getbyparams(users, users, req_dict)
if not datas:
msg['code'] = password_error_code
msg['msg'] = mes.password_error_code
return JsonResponse(msg)
req_dict['id'] = datas[0].get('id')
return Auth.authenticate(Auth, users, req_dict)
def users_register(request):
if request.method in ["POST", "GET"]:
msg = {'code': normal_code, "msg": mes.normal_code}
req_dict = request.session.get("req_dict")
error = users.createbyreq(users, users, req_dict)
if error != None:
msg['code'] = crud_error_code
msg['msg'] = error
return JsonResponse(msg)
def users_session(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code,"msg":mes.normal_code, "data": {}}
req_dict = {"id": request.session.get('params').get("id")}
msg['data'] = users.getbyparams(users, users, req_dict)[0]
return JsonResponse(msg)
def users_logout(request):
if request.method in ["POST", "GET"]:
msg = {
"msg": "退出成功",
"code": 0
}
return JsonResponse(msg)
def users_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code,
"data": {"currPage": 1, "totalPage": 1, "total": 1, "pageSize": 10, "list": []}}
req_dict = request.session.get("req_dict")
tablename = request.session.get("tablename")
try:
__hasMessage__ = users.__hasMessage__
except:
__hasMessage__ = None
if __hasMessage__ and __hasMessage__ != "否":
if tablename != "users":
req_dict["userid"] = request.session.get("params").get("id")
if tablename == "users":
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = users.page(users, users, req_dict)
else:
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize'] = [],1,0,0,10
return JsonResponse(msg)
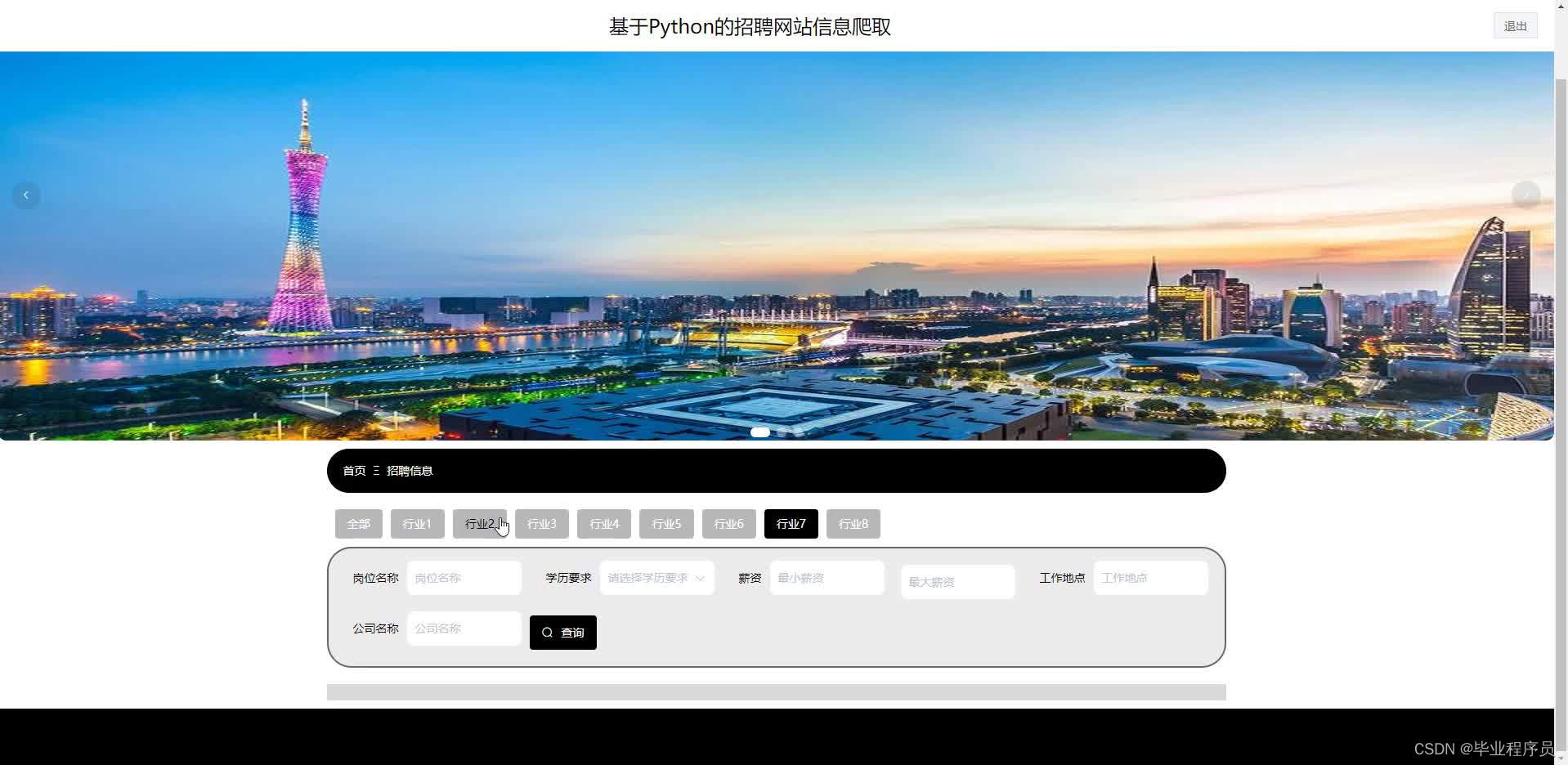
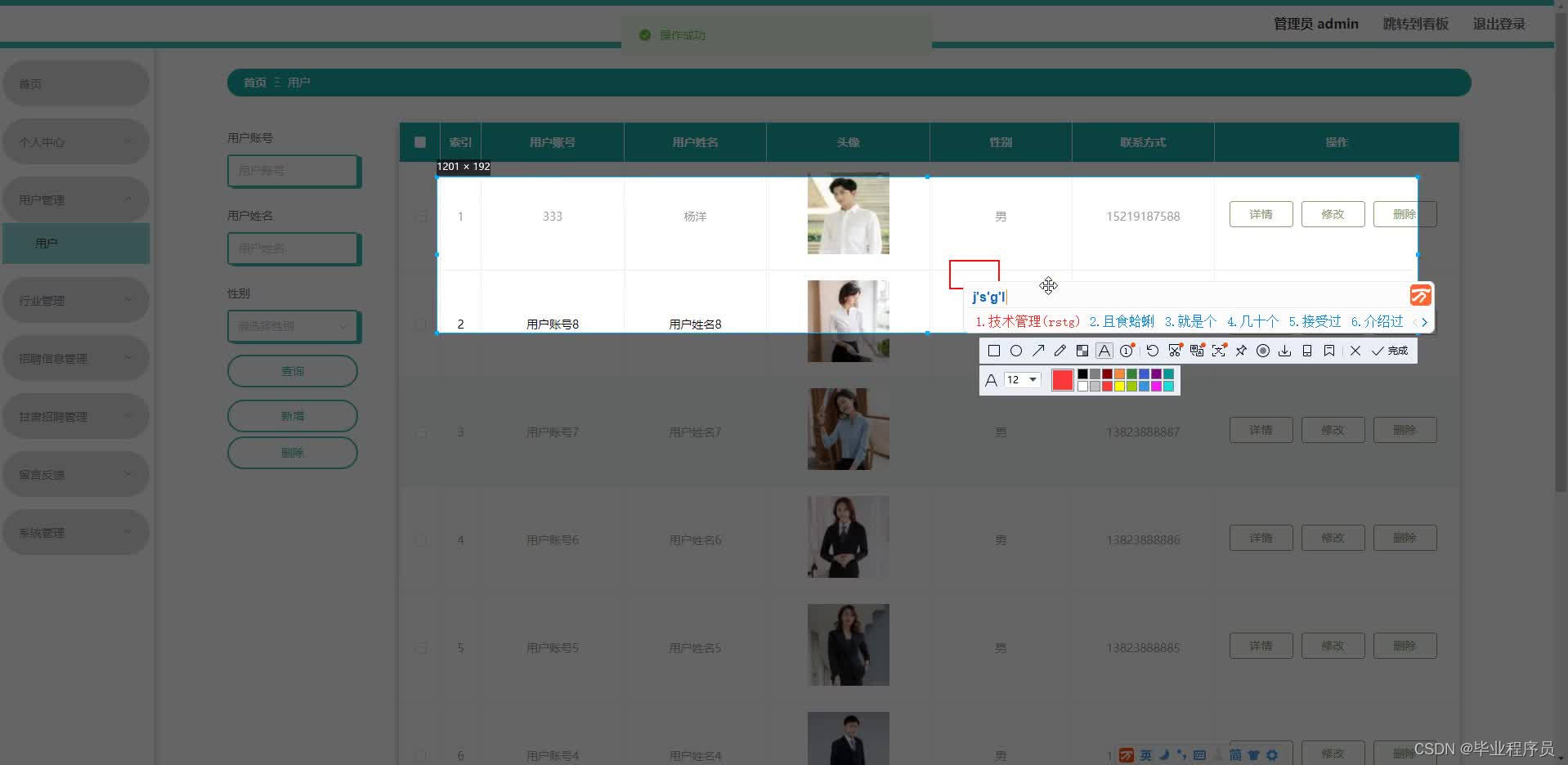
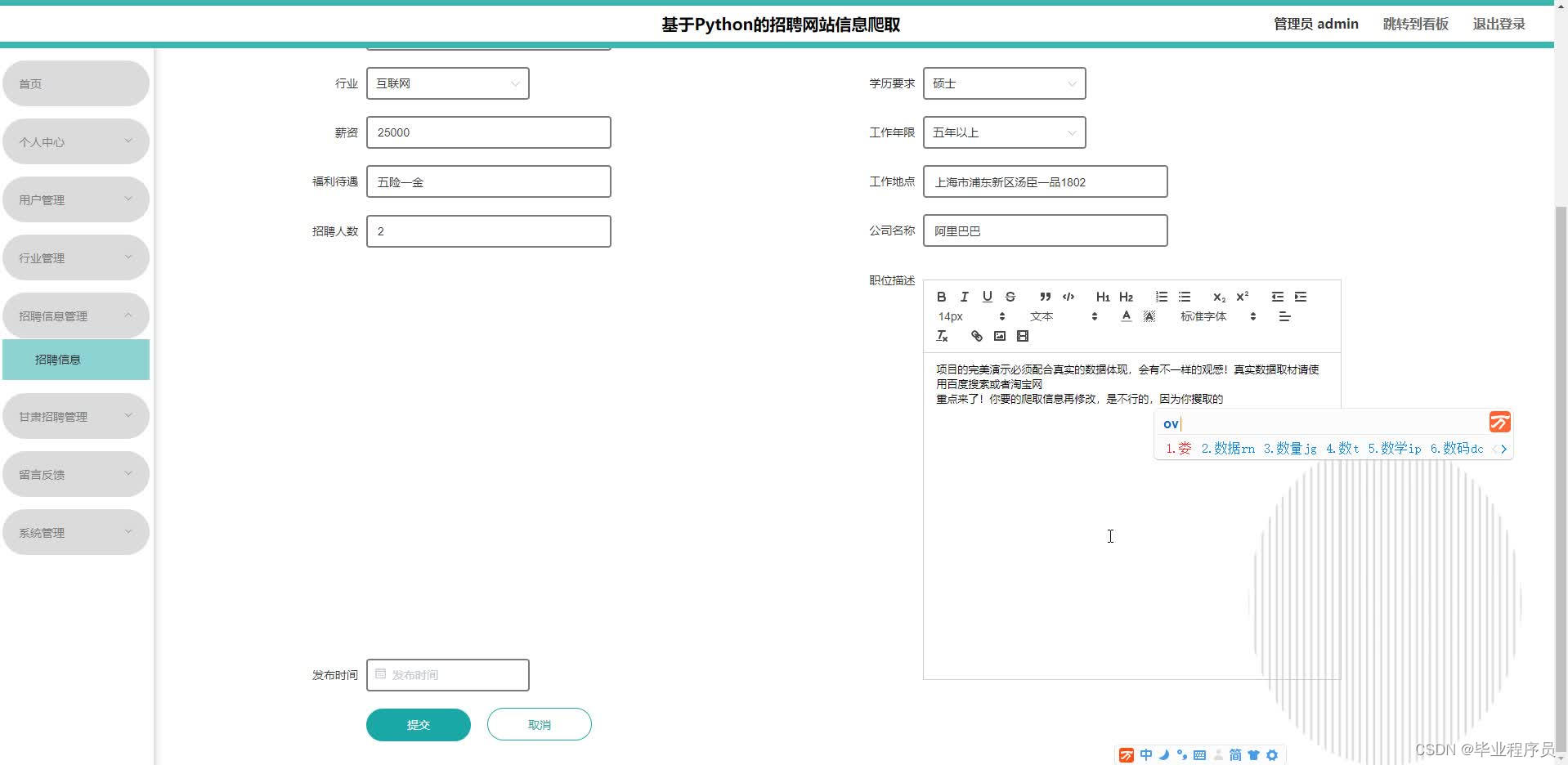
五、效果图






















 1987
1987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











