







接下来只需要用到的python的两个库:
-
requests
-
json
-
BeautifulSoup
requests库就是用来进行网络请求的,说白了就是模拟浏览器来获取资源。
由于我们采集的是api接口,它的格式为json,所以要用到json库来解析。BeautifulSoup是用来解析html文档的,可以很方便的帮我们获取指定div的内容。
下面开始编写我们爬虫:
第一步先导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
接着我们定义一个获取指定页码内数据的方法:
def get_page(page):
url_temp = ‘http://temp.163.com/special/00804KVA/cm_guonei_0{}.js’
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样子就得到每个页码对应的内容列表:
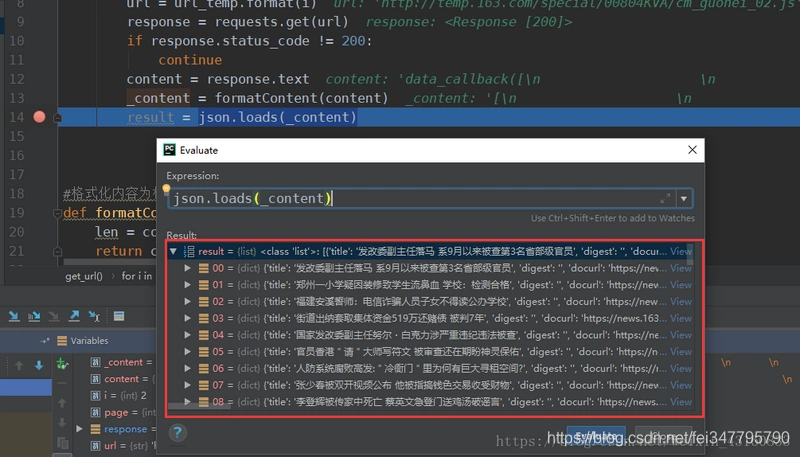
之后通过分析数据可知下图圈出来的则是需要抓取的标题、发布时间以及新闻内容页面。
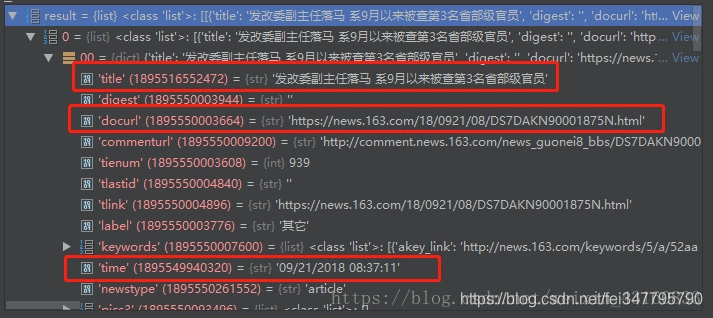
既然现在已经获取到了内容页的url,那么接下来开始抓取新闻正文。
在抓取正文之前要先分析一下正文的html页面,找到正文、作者、来源在html文档中的位置。
我们看到文章来源在文档中的位置为:id = "ne_article_source" 的 a 标签。
作者位置为:class = "ep-editor" 的 span 标签。
正文位置为:class = "post_text" 的 div 标签。
下面试采集这三个内容的代码:
def get_content(url):
source = ‘’
author = ‘’
body = ‘’
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 4058
4058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









