







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
可视化库不采用pyecharts,来点新东西。
使用matplotlib可视化库,利用这个底层库来进行可视化展示。
/ 01 / 网页分析
01 歌单索引页
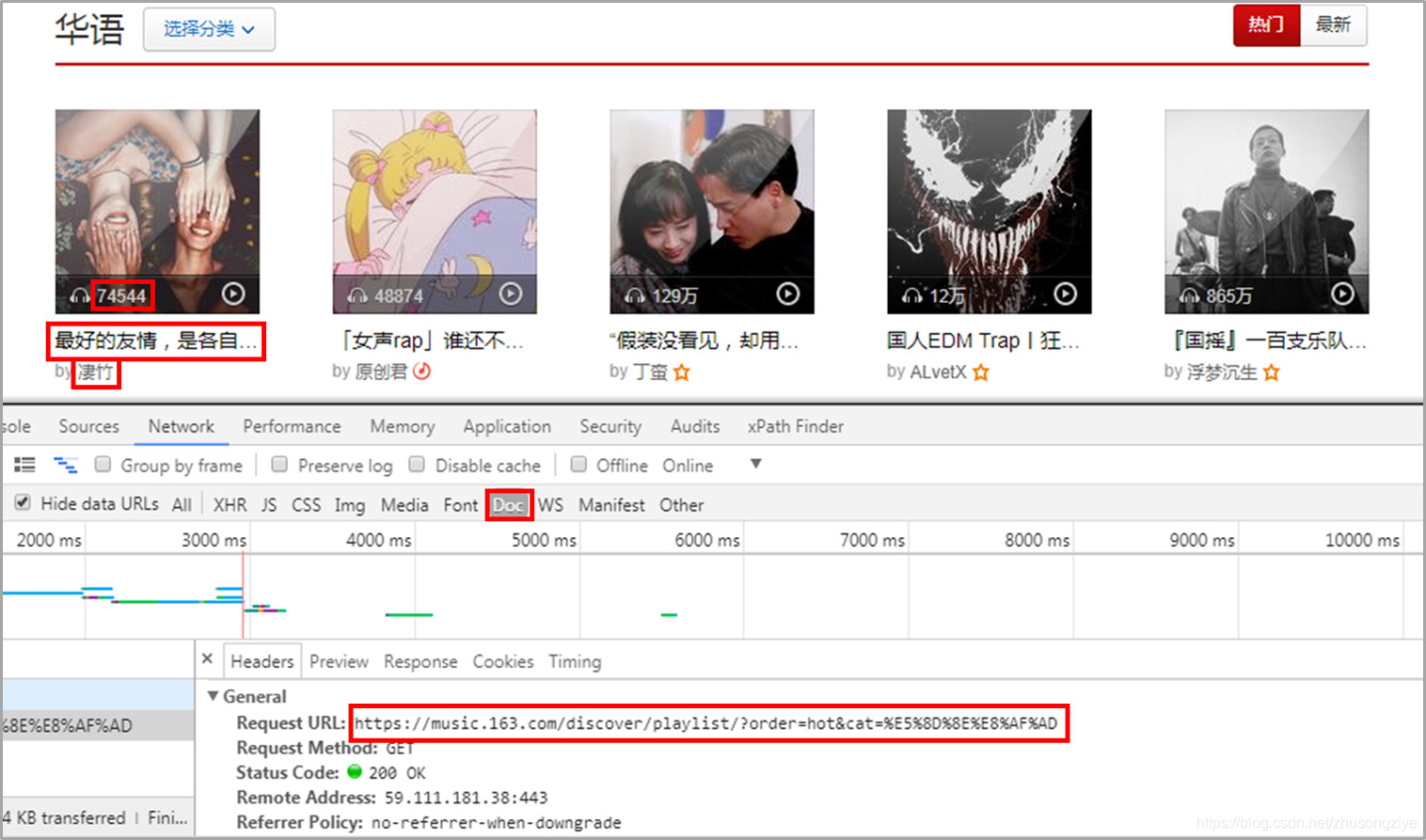
选取华语热门歌单页面。
获取歌单播放量,名称,及作者,还有歌单详情页链接。
本次一共获取了1302张华语歌单。
02 歌单详情页
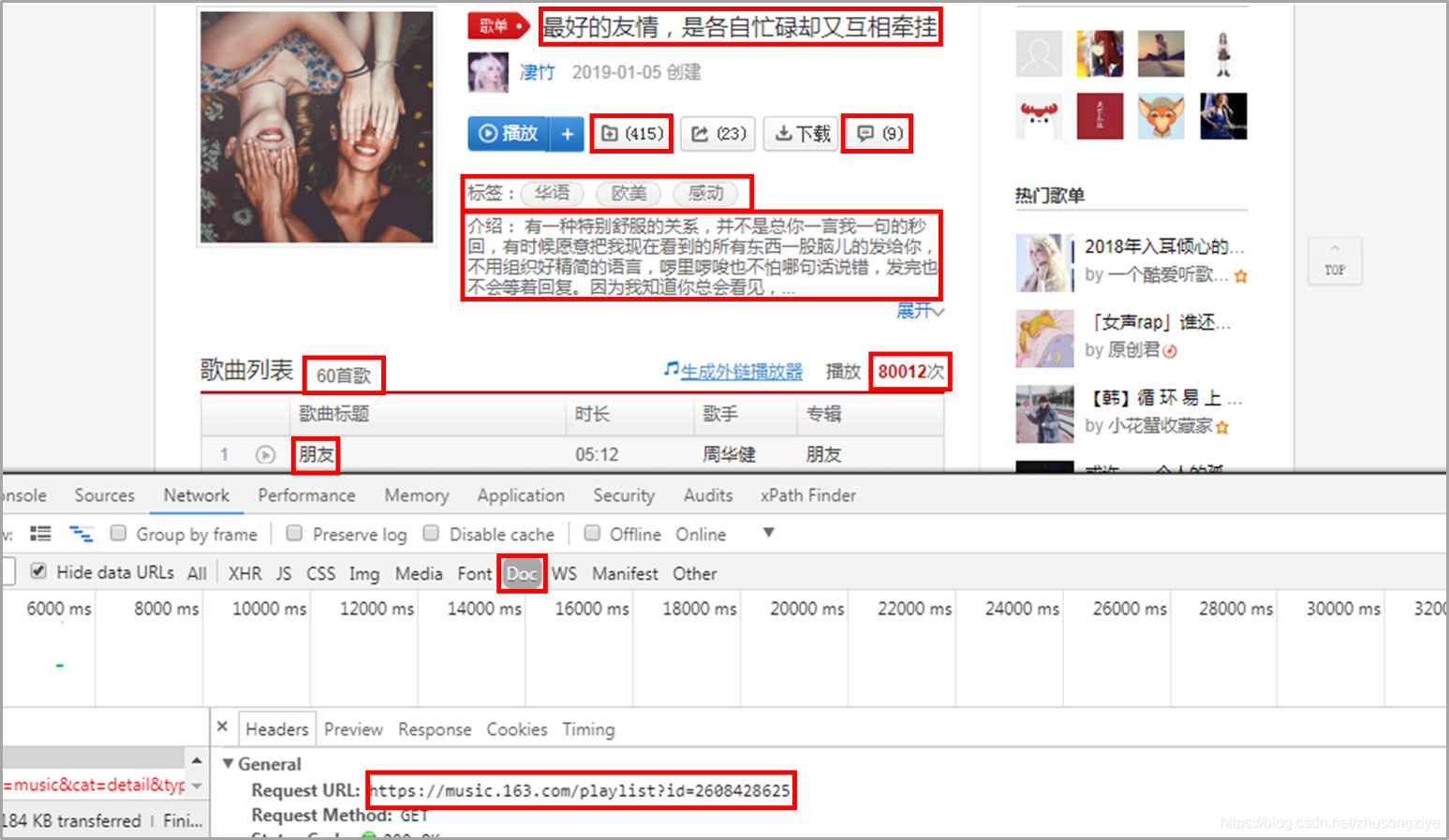
获取歌单详情页信息,信息比较多。
有歌单名,收藏量,评论数,标签,介绍,歌曲总数,播放量,收录的歌名。
这里歌曲的时长、歌手、专辑信息在网页的iframe中。
需要用selenium去获取信息,鉴于耗时过长,小F选择放弃…
有兴趣的小伙伴,可以试一下哈…
/ 02 / 数据获取
01 歌单索引页
from bs4 import BeautifulSoup
import requests
import time
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36’
}
for i in range(0, 1330, 35):
print(i)
time.sleep(2)
url = ‘https://music.163.com/discover/playlist/?cat=欧美&order=hot&limit=35&offset=’ + str(i)
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, ‘html.parser’)
# 获取包含歌单详情页网址的标签
ids = soup.select(‘.dec a’)
# 获取包含歌单索引页信息的标签
lis = soup.select(‘#m-pl-container li’)
print(len(lis))
for j in range(len(lis)):
# 获取歌单详情页地址
url = ids[j][‘href’]
# 获取歌单标题
title = ids[j][‘title’]
# 获取歌单播放量
play = lis[j].select(‘.nb’)[0].get_text()
# 获取歌单贡献者名字
user = lis[j].select(‘p’)[1].select(‘a’)[0].get_text()
# 输出歌单索引页信息
print(url, title, play, user)
# 将信息写入CSV文件中
with open(‘playlist.csv’, ‘a+’, encoding=‘utf-8-sig’) as f:
f.write(url + ‘,’ + title + ‘,’ + play + ‘,’ + user + ‘\n’)
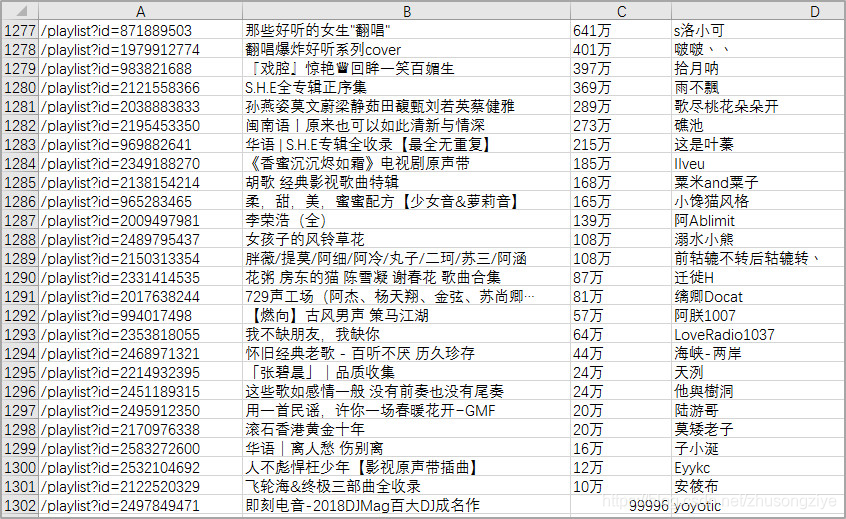
获取歌单索引页信息如下,共1302张华语歌单。
02 歌单详情页
from bs4 import BeautifulSoup
import pandas as pd
import requests
import time
df = pd.read_csv(‘playlist.csv’, header=None, error_bad_lines=False, names=[‘url’, ‘title’, ‘play’, ‘user’])
headers = {
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36’
}
for i in df[‘url’]:
time.sleep(2)
url = ‘https://music.163.com’ + i
response = requests.get(url=url, headers=headers)
html = response.text
soup = BeautifulSoup(html, ‘html.parser’)
# 获取歌单标题
title = soup.select(‘h2’)[0].get_text().replace(‘,’, ‘,’)
# 获取标签
tags = []
tags_message = soup.select(‘.u-tag i’)
for p in tags_message:
tags.append(p.get_text())
# 对标签进行格式化
if len(tags) > 1:
tag = ‘-’.join(tags)
else:
tag = tags[0]
# 获取歌单介绍
if soup.select(‘#album-desc-more’):
text = soup.select(‘#album-desc-more’)[0].get_text().replace(‘\n’, ‘’).replace(‘,’, ‘,’)
else:
text = ‘无’
# 获取歌单收藏量
collection = soup.select(‘#content-operation i’)[1].get_text().replace(‘(’, ‘’).replace(‘)’, ‘’)
# 歌单播放量
play = soup.select(‘.s-fc6’)[0].get_text()
# 歌单内歌曲数
songs = soup.select(‘#playlist-track-count’)[0].get_text()
# 歌单评论数
comments = soup.select(‘#cnt_comment_count’)[0].get_text()
# 输出歌单详情页信息
print(title, tag, text, collection, play, songs, comments)
# 将详情页信息写入CSV文件中
with open(‘music_message.csv’, ‘a+’, encoding=‘utf-8-sig’) as f:
f.write(title + ‘,’ + tag + ‘,’ + text + ‘,’ + collection + ‘,’ + play + ‘,’ + songs + ‘,’ + comments + ‘\n’)
# 获取歌单内歌曲名称
li = soup.select(‘.f-hide li a’)
for j in li:
with open(‘music_name.csv’, ‘a+’, encoding=‘utf-8-sig’) as f:
f.write(j.get_text() + ‘\n’)
获取的1302张华语歌单的详情。
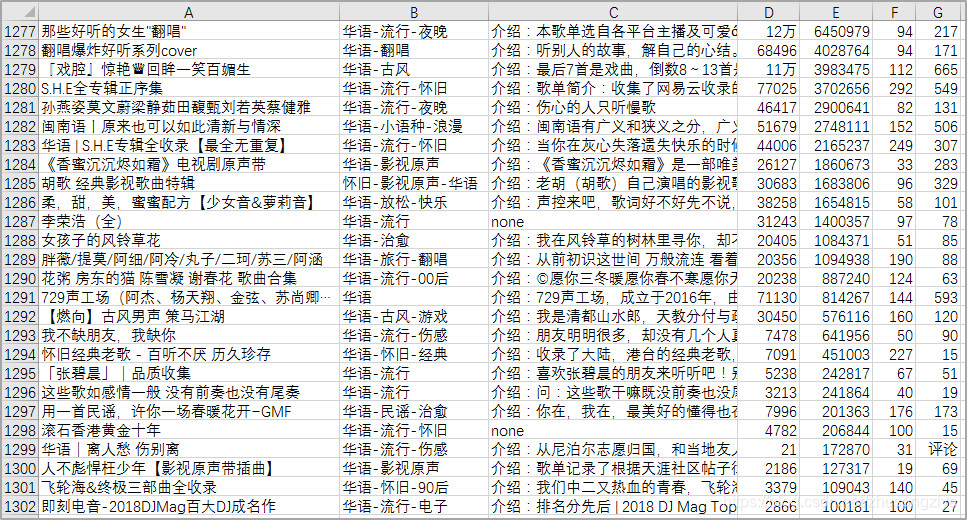
1302张歌单里的121118首歌。
/ 03 / 数据可视化
可视化代码已上传GitHub,点击左下角阅读原文即可访问!!!
01 歌曲出现次数 TOP10
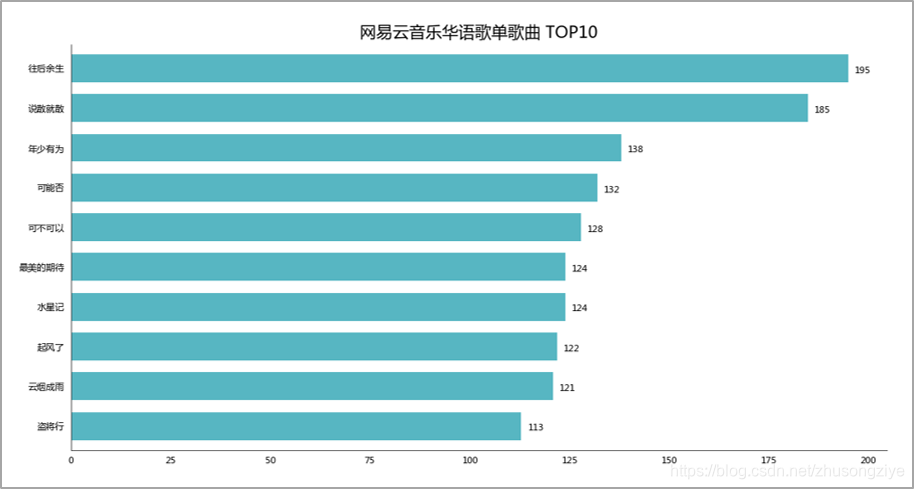
榜上的十首歌,除了「水星记」,小F听得次数都不少。
那么你又是如何的呢?
在小F的印象里,这些歌都曾在网易云音乐热歌榜的榜首出现过。
02 歌单贡献UP主 TOP10
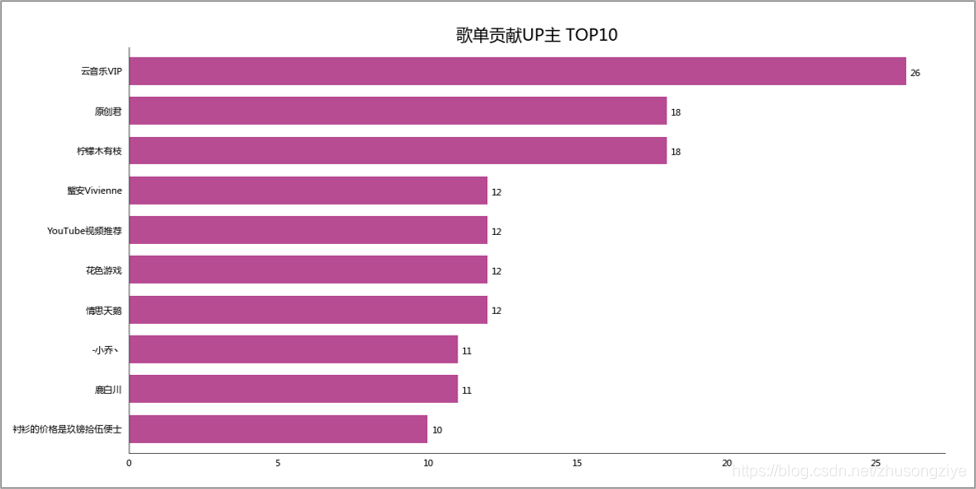
10大歌单贡献UP主,感谢这些辛勤的“搬运工”,给大家带来优质的歌单。
给广大懒人癌患者,亦或选择困难症患者,带来福利。
03 歌单播放量 TOP10

歌单播放量前十名单,第一名7000多万播放量。
其实matplotlib生成的图是挺清楚的,只不过一上传就变模糊了。
所以这里你可能会觉得图片质量不行…
其实并不是,为此小F做了相应的图表,具体见文末~
04 歌单收藏量 TOP10
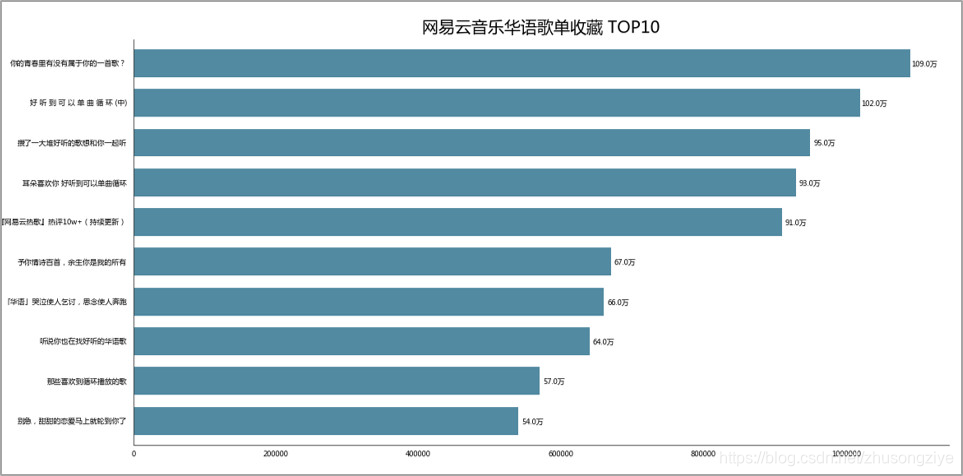
同样是好东西,收藏收藏!!!
有一些歌单和播放量TOP10里歌单有重复。
05 歌单评论数 TOP10
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









