







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
(二)http常见请求参数
url:请求url地址
headers:请求头
**data:发送编码为表单形式的数据
params:查询字符串**
host:请求web服务器的域名地址
User-Agent:HTTP客户端运行的浏览器类型的详细信息。通过该头部信息,web服务器可以判断到当前HTTP请求的客户端浏览器类别。
Accept:指定客户端能够接收的内容类型,内容类型中的先后次序表示客户端接收的先后次序。
Accept-Encoding:指定客户端浏览器可以支持的web服务器返回内容压缩编码类型。
Accept-Language:指定HTTP客户端浏览器用来展示返回信息所优先选择的语言
Connection:表示是否需要持久连接。如果web服务器端看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),表示连接持久有效,是不会断开的
cookie:HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。
Refer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面
四、request请求模块的方法使用
==================
举例说明:爬取我个人网站的数据
import requests #导入request模块
url = “http://42.192.212.170/” #指定url为我个人的网站
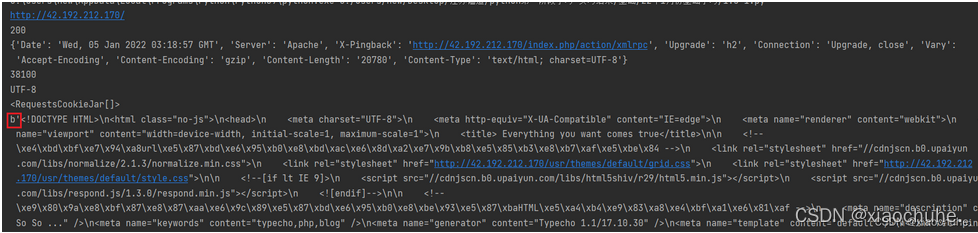
r = requests.get(url) #基于request模块给我个人url网站发送请求
print (r.url) #获取响应包地址
print (r.status_code) #获取响应包的状态码
print (r.headers) #获取响应包的头部信息
print (len(r.text)) #获取以文本形式下响应包的长度
print (r.encoding) #获取网页编码方式
print (r.cookies) #获取响应包的cookie值
print (r.content) #以字节形式返回响应体,会自动解码成gzip和deflate压缩
输出结果:
当然也可以用下面几种请求方法:
1.requests.post(“http://httpbin.org/post”) # POST请求
2.requests.put(“http://httpbin.org/put”) # PUT请求
3.requests.delete(“http://httpbin.org/delete”) # DELETE请求
4.requests.head(“http://httpbin.org/get”) # HEAD请求
5.requests.options(“http://httpbin.org/get” ) # OPTIONS请求
requests响应参数说明:
r.encoding #获取当前的编码
r.encoding = ‘utf-8’ #设置编码
r.text #以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字符编码进行解码。
r.content #以字节形式(二进制)返回。字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩。
r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回
r.status_code #响应状态码
五,params和payload参数使用说明
=======================
举例说明:
import requests #导入request模块
r1 = requests.get(“http://42.192.212.170/”,params={‘s’:‘1’} ) #params字符串传参变量s为1
print (r1.url)
payload1 = {‘s’:‘1’} #设置payload参变量s为1
r2 = requests.get(“http://42.192.212.170/”,params=payload1) #将params设为payload1
最后
Python崛起并且风靡,因为优点多、应用领域广、被大牛们认可。学习 Python 门槛很低,但它的晋级路线很多,通过它你能进入机器学习、数据挖掘、大数据,CS等更加高级的领域。Python可以做网络应用,可以做科学计算,数据分析,可以做网络爬虫,可以做机器学习、自然语言处理、可以写游戏、可以做桌面应用…Python可以做的很多,你需要学好基础,再选择明确的方向。这里给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
👉Python所有方向的学习路线👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

👉Python必备开发工具👈
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

👉Python全套学习视频👈
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

👉实战案例👈
学python就与学数学一样,是不能只看书不做题的,直接看步骤和答案会让人误以为自己全都掌握了,但是碰到生题的时候还是会一筹莫展。
因此在学习python的过程中一定要记得多动手写代码,教程只需要看一两遍即可。

👉大厂面试真题👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-wXVfn78B-1713176613405)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 619
619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









