









作者:Arpan Gujarati
会议:USENIX
发表年份:2020.11.4
引用量:132
作者提出了一种模型服务架构Clockwork,该架构可以预测DNN的执行时间,进一步减少时延。
作者介绍

Arpan Gujarati是印第安人,哥伦比亚大学助理教授,研究方向涵盖实时系统、分布式系统、可靠性分析、调度问题等。这篇论文出自他作为博士后第一年写的文章,创新点很新,算是一个比较先驱的东西了。膜拜膜拜☺☺☺
背景介绍
随着机器学习(ML)的不断发展,模型推理也变得越来越多。用户对于一个推理请求会有不同的需求(包括低时延、高吞吐量、低成本)。目前至少有100家公司正为加速机器学习推理而设计芯片。
然而,对于高性能模型服务,软件瓶颈继续阻碍着硬件加速器的高效使用。举个栗子,现在有一个有着明确截止时间的请求(超过时间就没有用了)需要服务,这时系统应该寻求限制请求的延迟,甚至提供SLOs以持续实现低尾延迟。实现一个低时延系统的常用解决办法是:通过提供超额资源,减少潜在的等待资源的时间。但是,超额资源的提供是以效益和利用率为代价的。
目前的系统基本上都假定组成系统组件具有不可预测的延迟性能。而且,容忍这种可变性的技术进一步将不可预测性级联到其它系统组件并将尾延迟传播到更高层。尽管一部分性能易变的原因是由于外部因素,比如一个瞬时的负载变化,但执行时间易变其实源自服务内部的设计决策,从分支结构的缓存决策到其他进程,系统和管理程序中都有体现。然后,我们应该如何克服内部不可预测性?
贡献
作者提出了一种用于可预测模型服务的分布式系统:Clockwork。首先作者发现DNN推理有着基本明确的数学操作序列并且该序列在GPU上的运行时间可以被预测。为了利用这个发现,在设计Clockwork时会尽可能保证可预见性,即将选择限制在顶层进行最关键的执行。与其他系统不同的是,如果Clockwork认为请求一定可以满足延迟SLO,那它会仅执行一个推断请求。这篇文章的主要贡献在于:
- 作者证明可预测性是DNN推断的基本特征,并因此构建了一个可预测模型服务系统。
- 作者提出了一种系统设计方法----consolidating choice以在大型系统中保留可预测的响应能力。
- 作者实现了Clockwork,该系统自底向上地移除DNN推断中的尾延迟。
- 作者做了一个评估实验,展示了该系统支持数千个模型同时在一块GPU上并且基本移除尾延迟,甚至同时满足时延SLOs。在复杂情况下,Clockwork实现了理想的吞吐量。
证明DNN推断执行可预测
作者发现DNN执行表现出可忽略的延迟变异性(latency variability)。一个直观且可以被证实的事是DNN推断没有涉及到条件分支(但输入可能不同啊)。该事实可以推广到其他加速器,例如TPU,或者适当CPU。
理论上
从概念上讲,DNN推断是一个完全确定性的执行。每个DNN推断请求都要有固定格式的输入格式;在实际过程中,它是一个静态大小的比特数组。worker将网络上接收到的这个输入存储到主存中。为了在GPU上执行,输入需要通过PCIe总线copy一份到GPU内存中。理论上,DNN代码会将这些操作一次性地应用于输入张量,将其转换成输出。DNN代码缺少条件分支,输入选择(例如批处理大小,RNN序列长度)都是被提前指定好了的。输出也是一个静态大小的比特数组,并且它又通过PCIe总线从GPU内存copy回主存。
实验验证
Setup:
ResNet50v2 with TVM 0.7
NVIDIA Tesla v100 GPU
11 million inferences in isolation
using random inputs and batch size
实验结果

实验表明,在单独运行推断时,推断的执行时间是可以预测的,没有明显的延迟变异性,99.99%的时延都在中位数时延的0.03%范围内。同时运行多个实例可以使吞吐量增加,但也会导致时延的增加。延迟不确定性的增加意味着推理任务的完成时间不再固定,可能有较大波动,这可能对某些应用程序的响应时间造成影响。
可预测性能
通过原则性响应设计,我们进一步发现了造成或者扩大性能可变的一些因素。主要的是,任何水平现代系统栈的组件都能导致可变的请求时延,无论是否处于应用层,是否在操作系统中,甚至是否在硬件里。网络影响和负载浮动又添加了两个导致分布式系统不可预测性的源头。
整体会比各部分之和要大
整体系统性能可变主要取决于系统怎样由组成组件组装的。我们可以通过下列几种方式处理单个软件可变时延:
- 忽略这个问题。这会导致这种可变性传播到后一个请求或者渗出到别的系统组件中。即便对吞吐量或者平均时延进行优化也无法修正尾时延。因此忽略可变性是不可行的。
- 通过最高延时的方法移除可变性。这会导致系统资源利用率降低,尤其是当最坏情况时延远高于平均值时。
- 通过扩展资源的方式最小化时延。当然,这也会导致利用率降低。例如,一些网络系统会提交同样的工作给多个workers并行处理,当收到一个响应时就取消其他的工作。
- 在检测到不寻常的延迟时,我们通过反馈机制调制环境,以降低对未来请求的影响。这种“尽力而努力”的方法通常是反应性的,旨在长期影响,例如暂时添加更多的资源,节流请求或平衡负载。(这也是我想到的)
Consolidating choice
我们采取了一种完全不同的策略:设计一个自低向上的可预测系统。策略是尽可能限制较低层的选择以及可能性----这是基于我们的观察:当执行一个基本可预测任务时,性能可变发生只可能因为系统较低层自己选择如何执行它的任务。系统层次栈如图所示:
- 硬件层次:当一个GPU通过多个CIDA核去并行处理时,GPU能够选择如何分配资源,包括内核之间的执行单元和内存带宽。GPU会依据网络状态和未经记录、专有的策略。
- 系统层次:当我们创建一个多线程时,OS 可以基于内部调度策略和状态选择哪一条线程执行任务。
- 应用层次:当分布式应用程序的工作人员进程各自管理自己的缓存时,workers 就可以选择缓存的内容以及缓存多长时间,这导致不可预测的命中率和延迟。类似的,当worker进程实现自己的线程池和排队策略时,它们可以选择哪个请求先执行哪个请求后执行,这会导致不可预测的排队时间。
作者的策略是在较高层巩固选择:一旦高层根据内部状态实现较低层的选择,它迫使较低层遵循可能执行的狭窄路径,导致结果层的性能几乎可以预测。通过对资源利用率和所有请求的预期执行时间进行监控,高层可以有效预测低层的性能和结果。然而,该策略的缺点是需要更紧密的组件耦合和更少模块化的架构。
有缺点的预测
通过合并选择,我们可以将不完全可预测性的因素整合在系统的上层,从而实现可预测的执行。实际系统中存在一些不可预测的组成部分,例如管理CPU缓存或工作负载的变化,即使在整合选择之后仍然存在。然而,通过集中处理这些选择,我们的主要目标是使可预测的执行成为常见情况。这样一来,我们就不需要实现最佳努力机制来容忍偶尔出现的、罕见的不可预测性实例;相反,我们可以将不可预测性直接视为错误。
系统设计
为了递归地限制较低层的选择,我们设计了一种新的架构,其中最关键的选择执行是在顶层做出的。这种框架称为Clockwork,有一个集中的控制器和可预测性能的workers。
整体概览
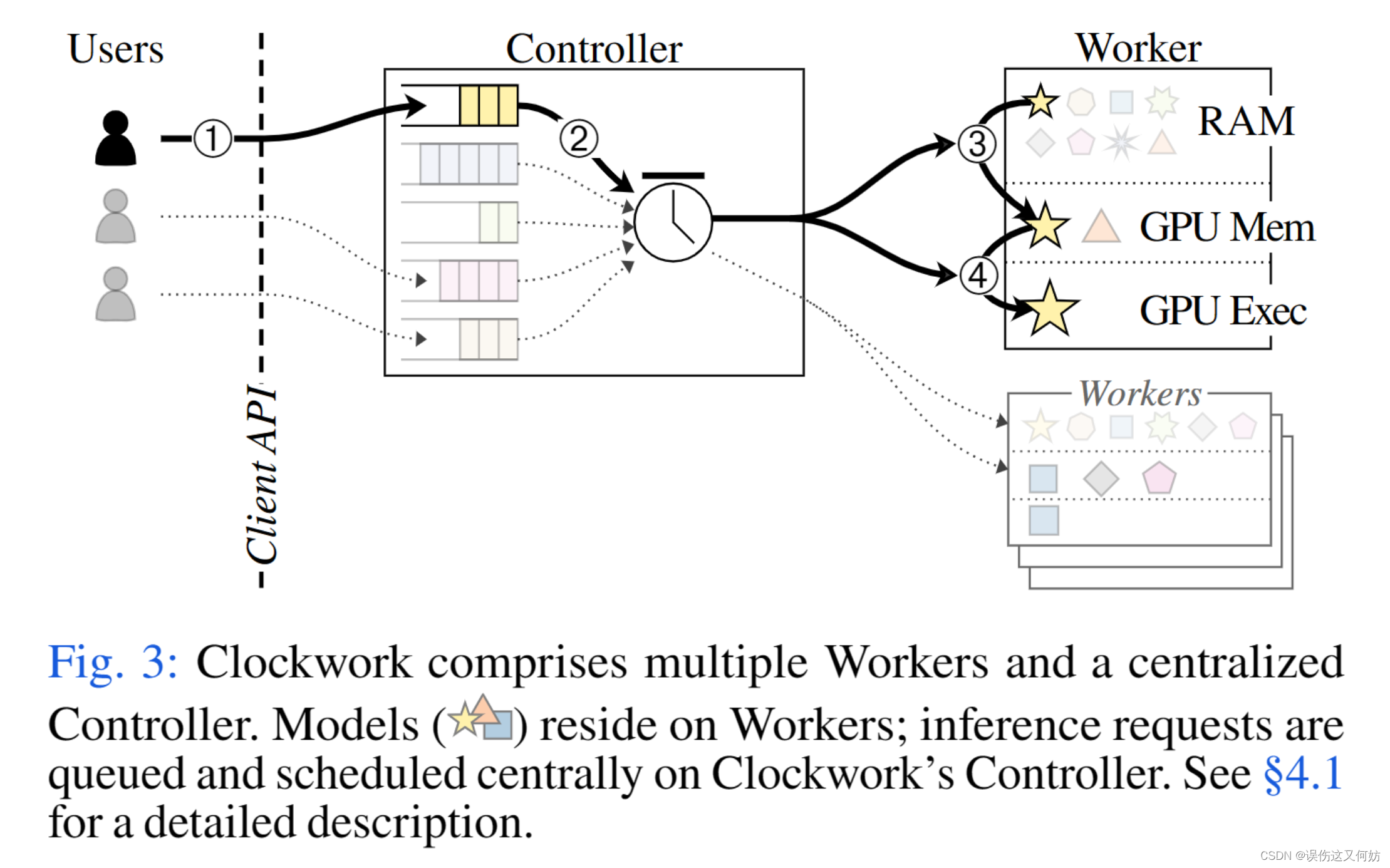
架构
图三是Clockwork的整体架构。用户提出推断请求,请求会在Clockwork的控制器处排队。每个worker都有一个已加载到RAM中的DNN模型集合,worker会对1个或者多个GPU进行独占控制。集中调度器会对系统状态有一个全面了解,包括所有的workers,和在处理每个请求时所作的选择。为了执行一个请求,调度器直接决定什么时候加载模型到gpu内存,什么时候在gpu处理。在任何时候,调度器都会做出准确、高质量的决策(cache, schedule, load balance)。
例证
为了解释Clockwork架构组件的更多细节,包括分配给控制器的选择,思考下面几种情况。
只有一个请求时

当一个请求
r
1
r_1
r1到来时,Controller会首先估计指定worker的LOAD,INFER时间,然后根据LOAD、INFER时间去得出请求完成时间,如果满足SLOs,就发送给worker先进行加载操作,然后执行。
当 r 1 r_1 r1加载时,请求 r 2 r_2 r2到来

当⭐正加载时,请求🔺模型的
r
2
r_2
r2到来。controller知道🔺已经加载到GPU内存中。此时控制器选择立刻INFER
r
2
r_2
r2,或者等待⭐加载完成后INFER
r
1
r_1
r1。由于worker处于空闲状态,因此立刻INFAR
r
2
r_2
r2。
两个模型相同的请求同时到达

workers一次只能运行一个LOAD和一个INFER。因此
r
1
r_1
r1执行只能等到INFER
r
2
r_2
r2执行完毕,与此同时,请求同一模型的⭐的
r
3
r_3
r3到达。这时控制器选择是单独INFER
r
1
r_1
r1 还是同时INFER
r
1
r
3
r_1 r_3
r1r3。由于批处理INFER仍然在
r
1
r_1
r1的deadline之前完成,因此选择批处理INFER。
在批处理过程中 r 4 r_4 r4到达
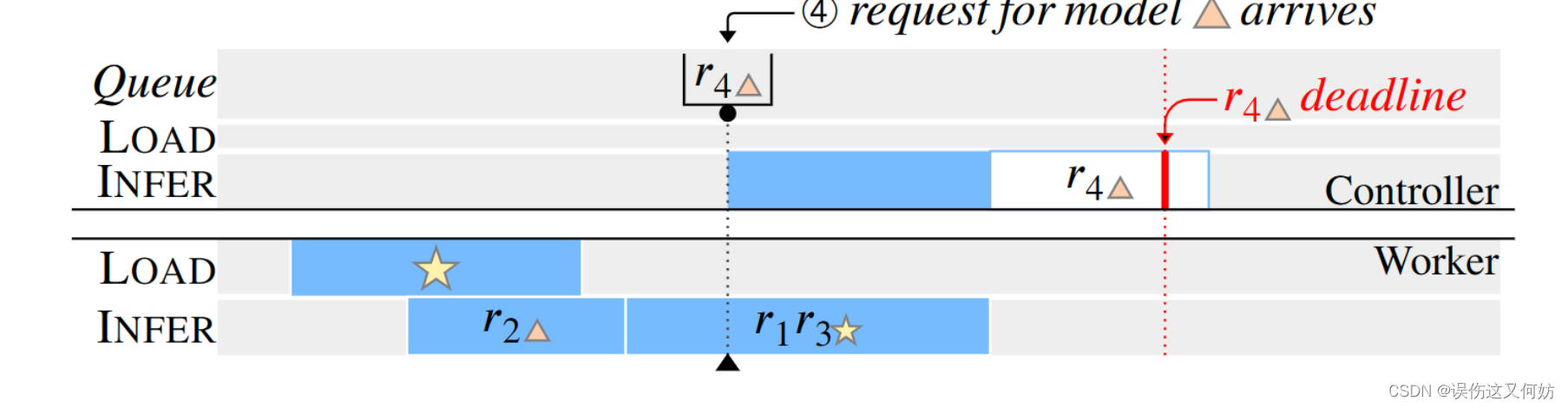
在这种情况下,控制器知道就算立刻执行
r
4
r_4
r4也不能在deadline之前响应。因此,控制器不会继续调度INFER动作并取消此次请求。
选择合并
Clockwork 合并选择采用了三种主要方式:
- worker状态的改变能够影响为了请求的性能。因此需要没有任何worker操作会对任何未来的操作产生影响。
- 确保可预测的组件要么将可能影响性能的调度决策委托给集中式控制器,要么否则使调度确定性。
- 当可预测组件无法按照指示执行时间表时,会将其视作一个error。worker不会尝试尽力而为的补救,避免级联错误预测。
Clockwork通过controller和wokers之间的行为命令抽象来强制Clockerwork中的三个属性,而不是传统的RPC调用,要么传递worker的状态,要么传达worker所要执行的任务。
可预测推断难点
为了合并选择,作者必须验证系统出现性能关键选择的位置。作者已经确定DNN推断本身具有确定性的性能。下一步,如何将这一结果拓展到整个已经成熟的inference system呢?
管理的内存和缓存是不可预估的
由于内存碎片和均摊性能的内部权衡,一些内存分配器会展现可变的时间。cache由于命中或不命中的原因也会导致性能可变。为了维持可预测性。















 2969
2969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











