







背景:
传统的两个分离模型(检测模型、外观嵌入模型)效率低
现有的实时多目标本质属于实时关联
分离模型:
目标检测:只解决了位置定位
跟踪任务:外观嵌入模型提供每个目标的身份信息
引言:
检测与re-ID任务共享同一组低级特征
定义:
采用单个网络来同时输出检测结果和检测到的框的相应外观嵌入
对比:
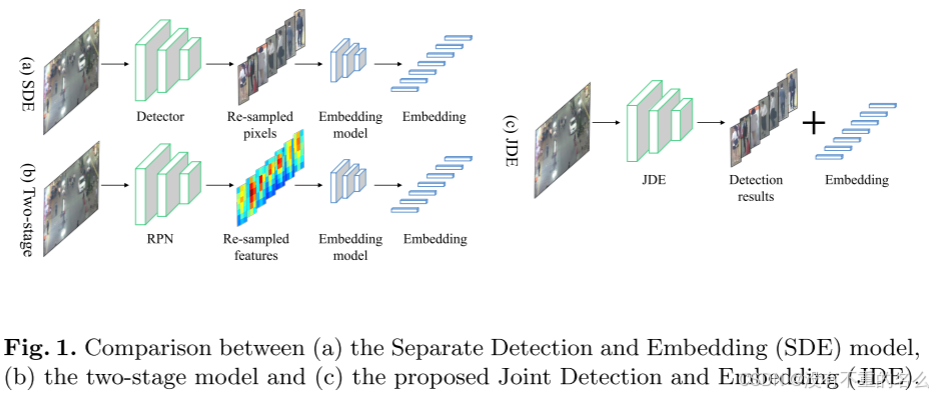
SDE 模型
步骤:首先使用检测器来检测目标,然后将检测到的目标传递给嵌入模型进行外观特征的提取。
特点:重复计算特征,导致计算效率低;在目标数量较多时,整体推理时间是两个步骤的和。
Two-stage 模型
类似于 Faster R-CNN 的两阶段检测方法
步骤:第一阶段是区域提议网络(RPN),用于生成候选框;第二阶段将候选框传递给嵌入模型进行外观特征提取。
特点:两阶段的设计,速度慢,无法达到实时处理的要求。
JDE 模型
目标检测和外观嵌入是在一个单一的网络中同时进行的,在一次前向传递中同时输出检测结果和相应的外观嵌入。
特点:提高计算效率,避免重复计算,保持较高的跟踪准确性,接近实时的处理速度
关键:
创新点:
联合学习框架:JDE是一个单次检测框架,用于联合检测和嵌入学习
实时性能:能够在接近实时的速度下运行,
准确性:追求实时性能的同时其跟踪准确性与单独检测和嵌入学习(SDE)相当
简化的数据关联:JDE提出了一个简单快速的关联方法
重点:
效率与准确性的平衡:在保持高准确性的同时提高MOT系统的运行效率
网络架构:采用FPN作为基础架构,有助于在不同尺度上捕捉目标特征。
多任务学习:JDE将检测、框回归和嵌入学习建模为一个多任务学习问题,并使用任务依赖的不确定性来动态加权不同的损失。
JDE:
目标:
在一次前向传递中同时输出目标的位置和外观嵌入
假设:
训练集:
:图像帧,
:目标的边界框标注(k个目标),
y:身份标签(目标的),
JDE输出:
:预测边界框,
:外观嵌入,
,D为嵌入维度
满足条件:
①预测的边界框应该尽可能接近真实的边界框
②相同身份的id在不同时间保持一致,不同身份的保持不同;同一身份目标在不同时间的外观嵌入d小于不同身份目标之间的d,d可以代表欧几里得距离或余弦距离
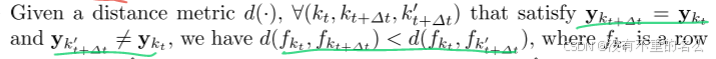
架构概览:

FPN:
FPN通过自底向上和自顶向下两个路径来构建特征金字塔。自底向上路径逐渐降低空间分辨率,增加通道数,捕获图像的语义信息;自顶向下路径逐渐增加空间分辨率,减少通道数,保留更多的位置信息。分别采用、
、
的上/下采样率,通过跳跃连接进行特征融合。
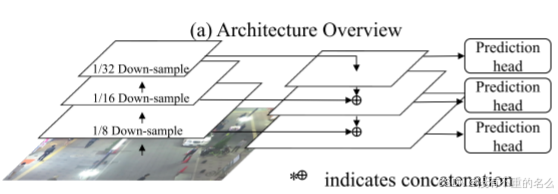
FPN在每个尺度的特征图上添加预测头,用于输出该尺度的目标检测结果。
预测头:
每个预测头输出(6A+D)*H*W
类别得分:2A*H*W
四个边界框回归坐标:4A*H*W
D维嵌入向量:D*H*W
检测任务:
检测头与RPN的区别:
①锚框设置1:3的纵横比
②当IOU>0.5时,设置为前景
损失函数:
:分类损失,使用交叉熵损失函数
:边界框回归损失,使用smooth-L1损失
外观嵌入任务:
三元组损失:
:锚框实例
:相对于
的正样本
:相对于
的负样本
三元组损失:
缺点:训练不稳定,收敛慢
平滑上界:
换一种表达形式就类似于交叉熵损失:
作用:
①采用可学习的类权重
②所有负类都参与到损失计算
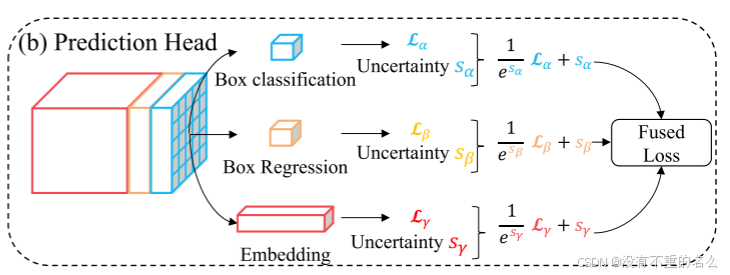
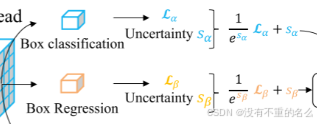
自动损失平衡:
总损失函数:
:第i个预测头的第j个任务的损失权重
:第i个预测头的第j个任务的损失
M:预测头的数量
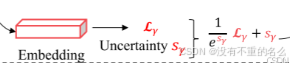
采用不确定性的损失权重自动学习方案:
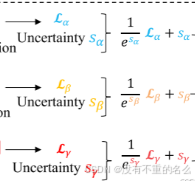
:第i个预测头数量的第j个人物的不确定性,
越大,
越小,不确定性较高的任务会有较小的损失权重
在线关联:
Tracklet Pool(轨迹片段池):维护一个轨迹片段池,包含所有可能与观测结果相关联的参考轨迹片段。
Motion Affinity Matrix (运动亲和矩阵):对于每一帧新输入的图像,计算所有观测结果与轨迹片段池中的轨迹片段之间的成对运动亲和度矩阵
,使用马氏距离计算,考虑观测之间的运动一致性。
Appearance Affinity Matrix (外观亲和矩阵):同时计算外观亲和矩阵
,衡量观测结果与轨迹片段在外观上的相似度,使用余弦相似度来计算,考虑观测之间的视觉相似性。
Linear Assignment Problem(线性分配问题):使用匈牙利算法解决线性分配问题,以找到观测结果与轨迹片段之间的最佳匹配。
Cost Matrix (成本矩阵) :成本矩阵
由外观亲和度和运动亲和度的加权和构成即:
其中是一个权重参数,用于平衡外观和运动亲和度。
Kalman Filter(卡尔曼滤波器):使用卡尔曼滤波器更新其运动状态
Appearance State Update(外观状态更新):更新匹配轨迹片段的外观状态 ,使用公式 :
其中是一个权重参数,用于平衡历史外观信息和当前观测的外观信息。
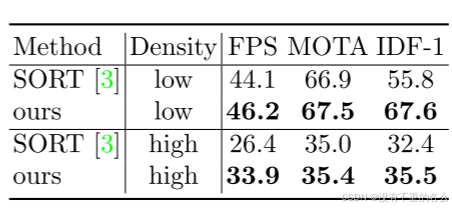
采用的关联算法非常优秀
实验(Experiments):
构建了一个大规模训练集,并使用了多个公开数据集进行评估
使用DarkNet-53作为骨干网络,采用随即旋转、随机缩放和颜色抖动
输入分辨率为1088*608
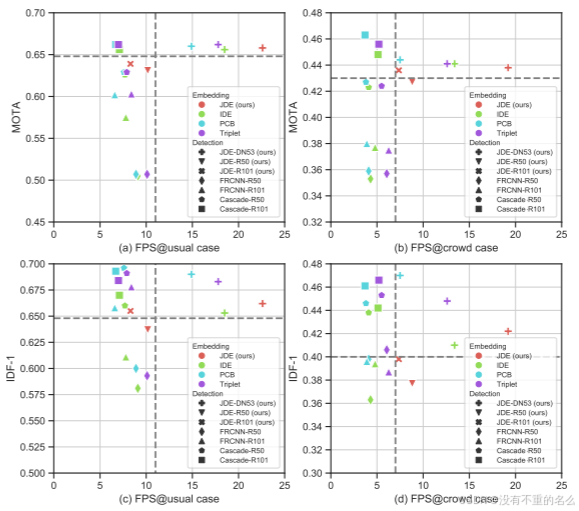
展示了JDE在不同数据集上的性能,并与现有的SDE方法和最先进的MOT系统进行了比较
结论(Conclusion):
这篇论文在MOT领域提供了一个新视角,通过联合学习框架JDE,实现了接近实时的多目标跟踪性能,同时保持了较高的跟踪准确性。这对于需要实时处理视频流的应用场景,如自动驾驶和智能视频监控,具有重要意义。
论文总结了JDE的主要贡献,并指出了未来工作的方向,包括进一步探索时间-准确性权衡问题。

















 1898
1898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









