







背景:
MobileNet v3是Google在2019年提出的轻量级卷积神经网络结构,旨在提高在移动设备上的速度和准确性,广泛的用于轻量级网络。
为满足移动设备上对高效、准确、低功耗深度学习模型的需求,并在保持计算成本适中的情况下增强模型的性能
网络亮点:
更新了block(bneck:针对MobileNet v2的倒残差结构做了简单的改动)
使用了NAS(Neural Architecture Search)搜索参数技术
重新设计耗时层结构
对比MobileNet v2:
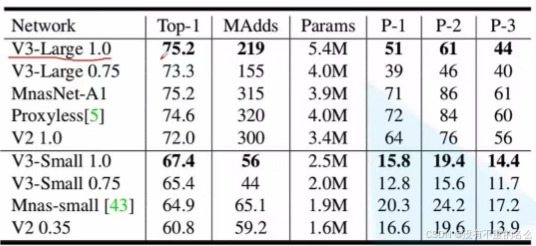
更准确,更高效
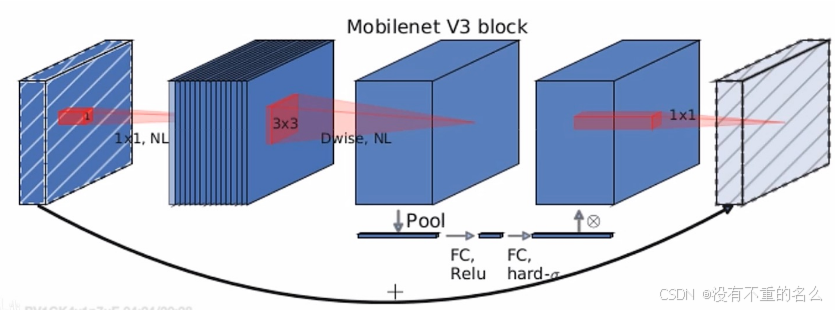
Block:
更新:
加入了SE模块(注意力机制)
更新了激活函数
MobileNet v2:
结构图:
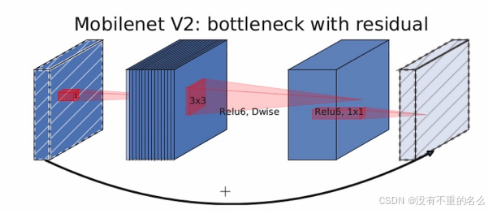
过程:
1.通过1*1卷积层进行升维处理,在卷积层后跟有BN、ReLU6激活函数
2.经过3*3的DW卷积,在卷积后跟有BN、ReLU6激活函数
3.使用1*1卷积层降维,只跟了一个BN层,并没有连接ReLU6激活函数
4.shortcut捷径分支,在输入特征矩阵与输出特征矩阵相同的维度上进行相加,当stride == 1且input_c == output_c才有shortcut连接
MobileNet v3:
结构图:
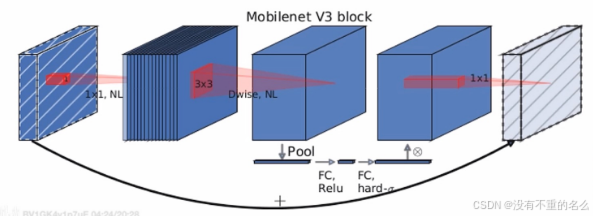
SE(Squeeze-and-Excitation)模块:
①针对得到的特征矩阵的每一个channel做池化处理,特征矩阵的channel数和得到的一维向量元素数一致
②一维向量通过两个全连接层得到输出向量:
第一个全连接层:全连接层的节点个数等于特征矩阵channel的(原论文中提及)
第二个全连接层:全连接层的节点个数与特征矩阵的channel保持一致
③输出向量是对输入的特征矩阵的每一个channel分析出一个权重关系,认为比较重要的channel赋予较大的权重,认为不重要的channel维度赋予比较小的权重
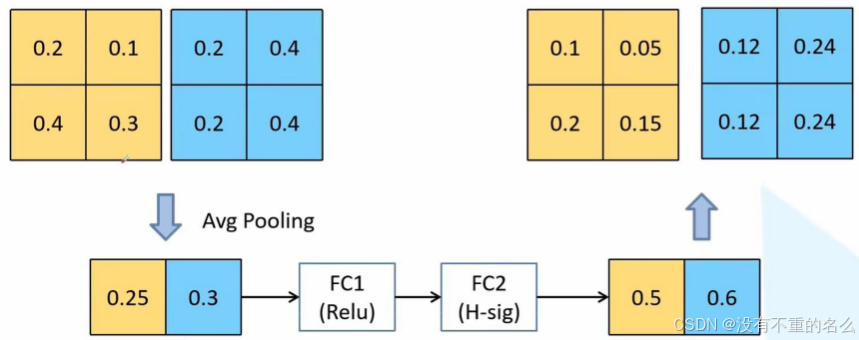
假设特征矩阵channel=2,先采用平均池化操作,对每一个channel求均值;由于有两个channel,则得到一个元素个数为2的向量;依次经过两个全连接层得到输出得到有两个元素的向量:FC1的节点个数为输入特征矩阵channel的,接一个ReLU激活函数;FC2的节点个数与输入特征矩阵channel维度一致,接一个hard-sigmoid激活函数;每个元素对应每一个矩阵的权重,与原矩阵相乘得到新的矩阵。
NL激活函数:
NL:非线性激活函数
由于每一个层使用的非线性激活函数不同,没有明确标出,统一用NL表示

1*1的降维卷积层没有使用激活函数,也可以说使用的是线性激活函数
NAS:
过程:
-
搜索空间:NAS 先设定好一个候选架构的搜索空间,包含多种选择,如卷积核大小、是否使用倒残差结构、激活函数类型(ReLU、H-Swish)、SE模块的应用等。
-
基于代理模型的强化学习:使用强化学习代理来评估不同架构组合的性能。通过构建代理模型,预测不同候选架构在移动设备上的计算效率和分类精度。不需要每次都完全训练每个候选网络,而是通过模拟得出合理结果。
-
效率优先:NAS 优化了 FLOPs(每秒浮点运算次数)和延迟指标,在兼顾精度和效率的前提下,生成的 MobileNetV3-Small 和 MobileNetV3-Large 两个版本。
-
多目标优化:平衡了多个目标,包括减少计算成本和提高模型准确性。
重新设计耗时层结构:
更新:
减少第一个卷积层的卷积核个数
精简Last Stage
减少卷积核个数:
从原来的32个卷积核减少为16个卷积核,但准确率未发生改变
在准确率相同的情况下,选择较少的卷积核
Efficient Last Stage:
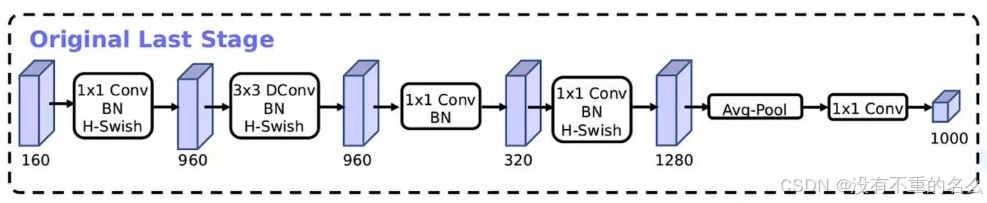
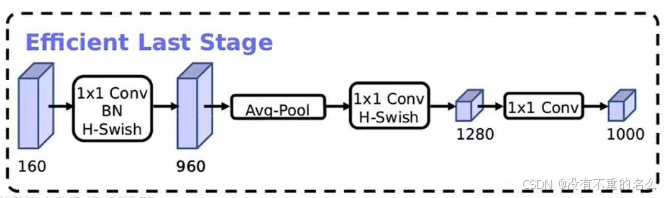
在准确率上基本没有任何变化,但节省了7ms的执行时间(占据了整个推理过程的11%的时间),对速度提升比较明显。
重新设计激活函数:
swish:
在MobileNet v2中常用ReLU6激活函数,而现在常用:
使用swish激活函数可以提高网络的准确率,但存在问题:
计算、求导复杂
对量化过程不友好
h-sigmoid:
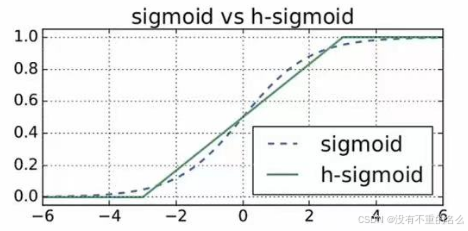
h-sigmoid函数与sigmoid函数相近,因此在很多场景使用h-sigmoid函数替代sigmoid激活函数
h-siwsh:
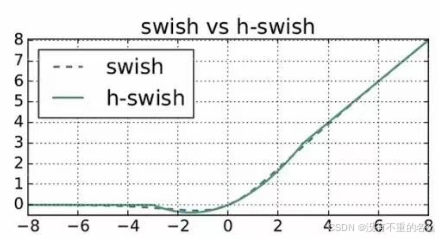
使用h-swish激活函数提到swish激活函数
作用:
将这些激活函数一一替换,对网络推理过程速度是有帮助的,对量化过程(精简数据结构)也很友好
MobileNet v3-Large的网络结构:
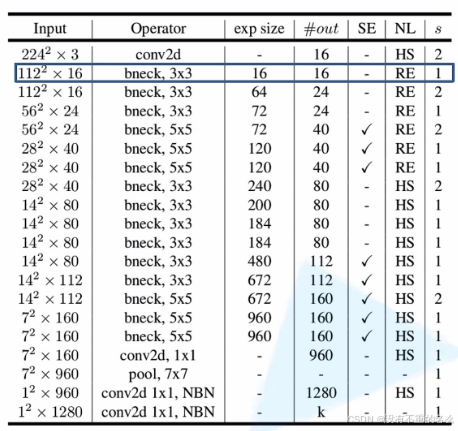
input:输入当前层特征矩阵的shape
operator:操作
out:输出特征矩阵的channel,降维之后的数值
NL:代表激活函数,HS代表h-swish激活函数,RE代表ReLU激活函数
s:DW卷积的步距stride
bneck:对应下图
后面的“”代表DW卷积的卷积核大小
exp size:代表第一个升维的卷积,要将这个维度升到多少
SE:代表是否使用注意力机制
NBN:当前卷积结构不使用BN结构
![]()
起到和全连接层作用相似,一般情况将特征矩阵通过池化层后接全连接层,而这里直接使用卷积结构
第一个bneck结构:
![]()
第一个bneck的exp size和输入特征矩阵的channel一样,第一个1*1卷积本来起到的是升维作用,而这里并没有升维。因此,在第一个bneck结构中并不包含1*1卷积结构,直接对特征矩阵进行DW,convolution处理;当前层也无SE处理,直接通过1*1卷积层输出。
shortcut:
与MobileNet v2相同,必须当stride == 1且input_c == output_c才有shortcut连接
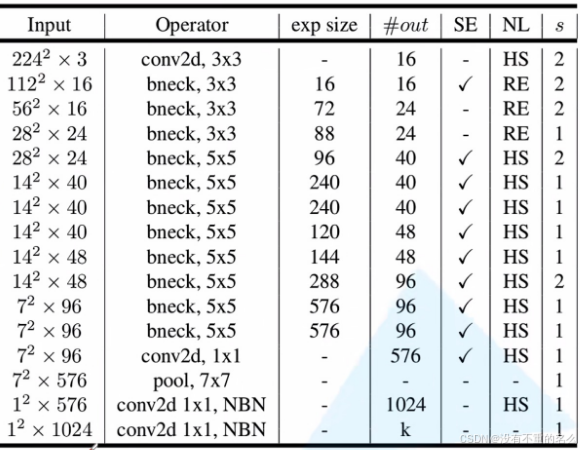
MobileNet v3-Small的网络结构:

















 2276
2276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









