






目录
介绍:
简称ES
Elasticsearch 是一个基于 Lucene 的 搜索服务器 。它提供了一个分布式多用户能力的 全文搜索引擎 ,基于RESTful web接口。Elasticsearch 是用 Java 语言开发的,并作为 Apache 许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch 用于 云计算 中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在 Java 、 .NET ( C# )、 PHP 、 Python 、 Apache Groovy 、 Ruby 和许多其他 语言中都是可用的。根据DB-Engines 的排名显示,Elasticsearch 是最受欢迎的企业搜索引擎, Apache Solr ,也是基于 Lucene
场合:
电商平台 eg:京东、淘宝
重要性:
1.实现高并发和多词条的海量搜索,查询效率高
2.分布式的实时文件存储,每个字段都被索引并可被搜索
3.实时分析的分布式搜索引擎

倒排索引 ---【ES独有】
先理解正向索引
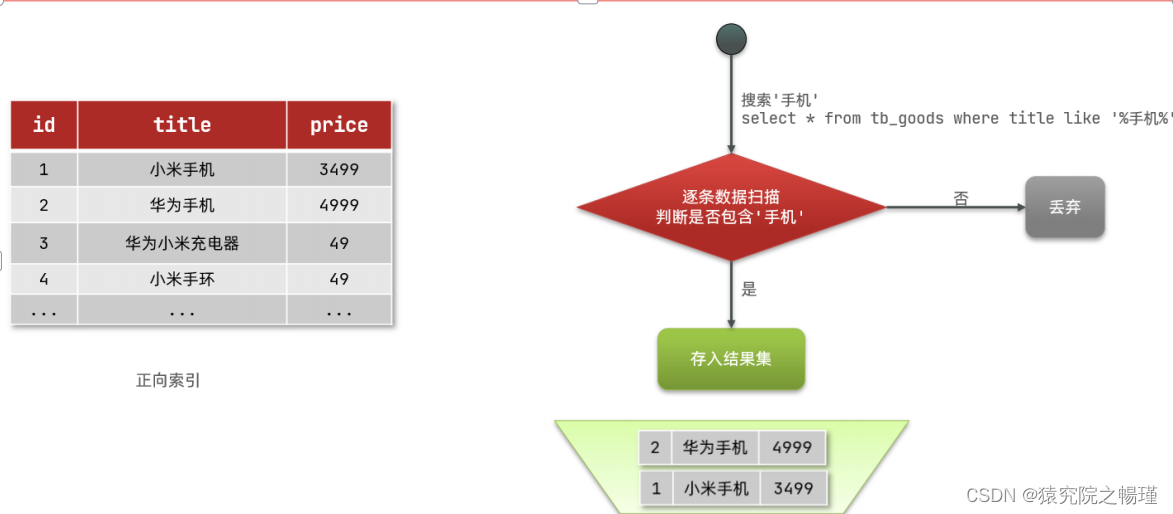
分析 :
1.根据id查询,根据索引,查询效率高;
2.若根据title作模糊查询,只能逐行扫描数据【即全表查询】:
1)用户搜索数据,条件是
title
符合
"%
手机
%"
2)逐行获取数据,比如
id
为
1
的数据
3)判断数据中的
title
是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤
1
倒排索引:
知识点:
文档(Document):用来搜索的数据,其中每一条数据就是一个文档【数据库的每一行】。
可以是数据库中的一条商品数据,一个订单信息。
文档数据会被序列化为json格式后存储在elasticsearch中
词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语 就是词条.ad
执行流程:
- 将每一个文档的数据利用算法分词,得到一个个词条 创建表,
- 每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引

搜索流程:
如下(以搜索"华为手机"为例):【只检索有效数据】
1)用户输入条件
"
华为手机
"
进行搜索。
2)对用户输入内容
分词
,得到词条:
华为
、
手机
。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档
id
:
1
、
2
、
3
。
4
)拿着文档
id
到正向索引中查找具体文档。
总结:
正向索引
是最传统的,根据
id
索引的方式。
但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,
是
根据文档找词条的过程
。
优点:
可以给多个字段创建索引
根据索引字段搜索、排序速度非常快
缺点:
非索引字段,只能全表查
倒排索引
则相反,是先找到用户要搜索的词条,
根据词条到索引库中得到保护词条的文档的
id
,然后根据
id获取文档【即数据信息】。
是
根据词条找文档的过程
。
优点:
根据词条搜索、模糊查询,速度非常快,但是需要维护倒排索引库【进行】
缺点:
只能给词条创建索引,而不是字段
无法根据字段作排序
与MySql的概念对比

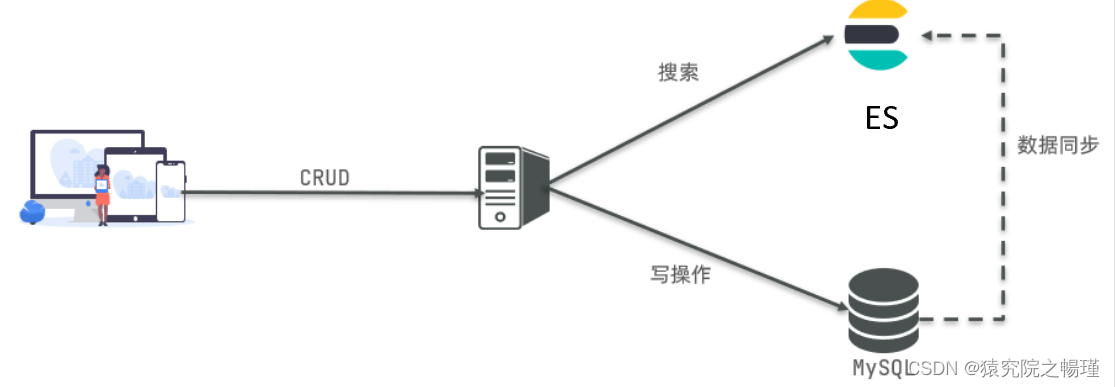
应用
在企业中,往往是两者结合使用
对安全性要求较高的写操作,使用mysql实现
对查询性能要求较高的搜索需求,使用elasticsearch实现
两者再基于某种方式,实现数据的同步,保证一致性
Windows版环境安装
下载
https://www.elastic.co/cn/downloads/elasticsearch
安装与启动 【解压缩即安装】
运行
elasticsearch.bat
访问
localhost:9200
能看到
json
代表启动成功
IK分词器
作用:
1.创建倒排索引库时对文档分词
2.用户搜索是,对输入的内容分词
模式:
ik_smart
:智能切分,粗粒度
ik_max_word
:最细切分,细粒度
安装
下载路径:
https://github.com/medcl/elasticsearch-analysis-ik/releases
安装路径:
在ES
安装目录下找到
plugins目录
创建 I
k
文件夹
将IK
分词器解压缩在此目录
并重新运行
ES
即可
创建索引库
基本语法
请求方式:PUT
请求路径:/
索引库名,可以自定义
请求参数:mapping
映射
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
//……略
}
}
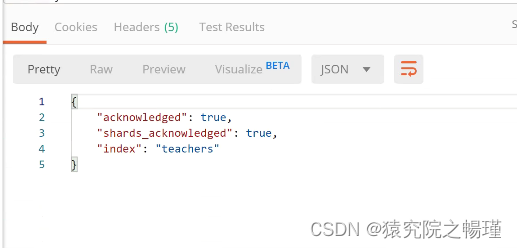
}使用PostMan检测:

理解:
【索引库就类似数据库表,mapping映射就类似表的结构】
mapping映射属性
type
:字段数据类型,常见的简单类型有:
字符串:text
(可分词的文本)、
keyword
(精确值,例如:品牌、国家、
ip
地址)
数值:long
、
integer
、
short
、
byte
、
double
、
float
、
布尔:boolean
日期:date
对象:object
index
:是否创建索引,默认为
true
analyzer
:使用哪种分词器
properties
:该字段的子字段
eg:
{
"age": 18,
"weight": 50,
"isMarried": false,
"info": "司念",
"email": "sinian501@163.com",
"score": [99.1,99.5,98.9],
"name": {
"firstName": "司",
"lastName": "念"
}
}查询索引库
请求方式:
GET
请求路径:
/
索引库名
请求参数:无
格式: GET /库名
修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),
就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改
mapping
。
虽然无法修改
mapping
中已有的字段,
但是却允许添加新的字段到
mapping
中,因为不会对倒排索引产生影响。
说明:
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer" }
}
}删除索引库
请求方式:DELETE
请求路径:
/
索引库名
请求参数:无















 7581
7581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









