




语义分割介绍
概念
语义分割(semantic segmentation):语义分割将图片中的每个像素分配到对应的类别中。
实例分割(Instance segmentation):也叫同时检测并分割,实例分割不仅需要对每个像素进行分类,还要区分不同的目标实例。
例如,在下例中,第一张为原图,第二张为语义分割后图片,第三张为实例分割后图片,对于语义分割只需要找到区分每个像素属于的类别,而对于实例分割相同类别的物体也要进行区分。

常见数据集格式
Pascal VOC
Pascal VOC2012数据集详解视频: https://b23.tv/F1kSCK
Pascal VOC2012官网地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
官方发表关于介绍数据集的文章 《The PASCALVisual Object Classes Challenge: A Retrospective》http://host.robots.ox.ac.uk/pascal/VOC/pubs/everingham15.pdf
下图为Pascal VOC数据集的语义分割后的图片。注意,在语义分割中对应的标注图像(.png)用PIL的Image.open()函数读取时,默认是P模式,即一个单通道的图像。在背景处的像素值为0,目标边缘处用的像素值为255(训练时一般会忽略像素值为255的区域),目标区域内根据目标的类别索引信息进行填充,例如人对应的目标索引是15,所以目标区域的像素值用15填充。
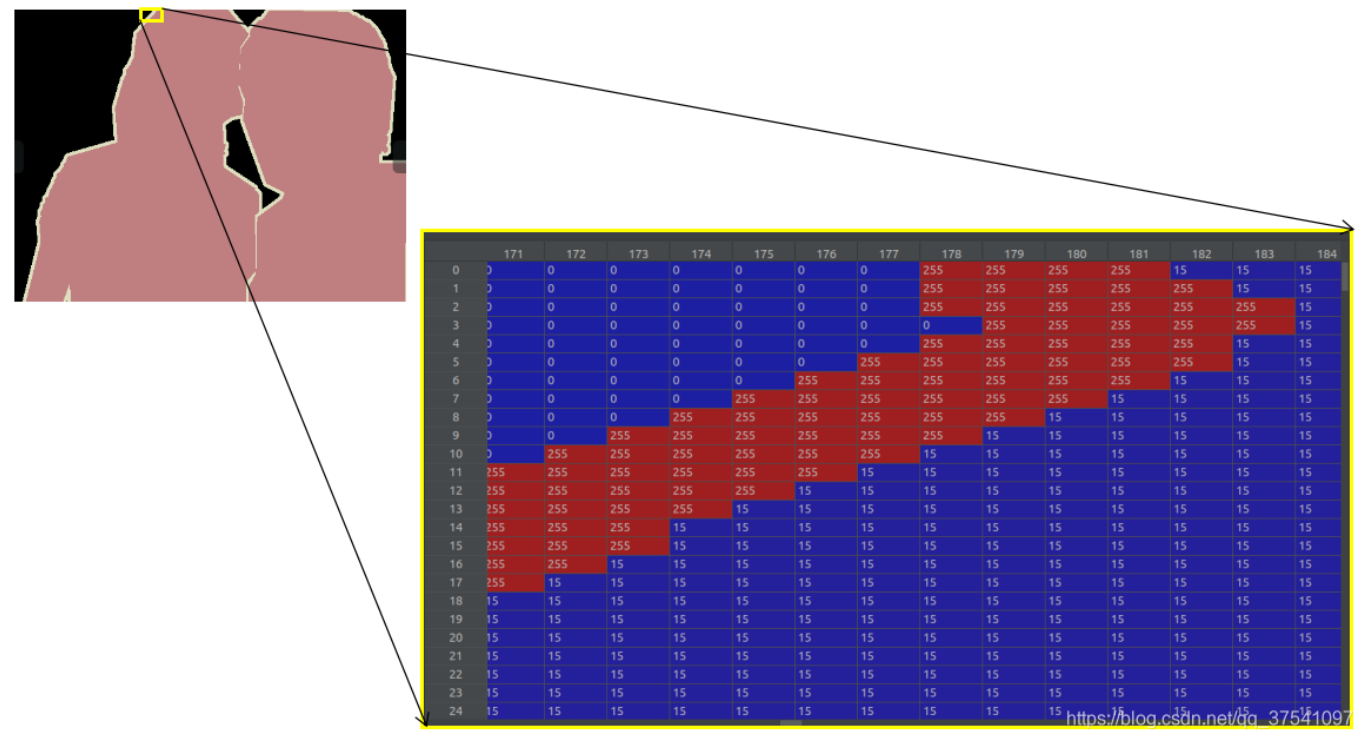
具体数据集使用参考博客:PASCAL VOC2012数据集介绍_pascal voc 2012-CSDN博客
MS COCO
MS COCO数据集中对图片中每个目标都记录的是多边形坐标,将其绘制后就可以得到右下角的图片。

具体数据使用参考博客:MS COCO数据集介绍以及pycocotools简单使用_coco数据集最多一张图有多少个instance-CSDN博客
评价指标
评价指标主要有以下三个:
- Pixel Accuracy(Global Acc,像素准确率 ):$ \frac{\sum_{i} n_{ii}}{\sum_{i} t_{i}} $
- mean Accuracy(平局准确率):$ \frac{1}{n_{cls}} \cdot \sum_{i} \frac{n_{ii}}{t_{i}} $
- mean IoU(平均交并币,核心指标):$ \frac{\frac{1}{n_{cls}} \cdot \sum n_{ii}}{\sum_{i} t_{i} + \sum_{j} n_{ji} - n_{ii}} $
$ n_{ij}: < f o n t s t y l e = " c o l o r : r g b ( 28 , 31 , 35 ) ; " > 类别 < / f o n t > <font style="color:rgb(28, 31, 35);"> 类别 </font> <fontstyle="color:rgb(28,31,35);">类别</font> i < f o n t s t y l e = " c o l o r : r g b ( 28 , 31 , 35 ) ; " > 被预测成类别 < / f o n t > <font style="color:rgb(28, 31, 35);"> 被预测成类别 </font> <fontstyle="color:rgb(28,31,35);">被预测成类别</font> j $ 的像素个数
$ n_{\text{cls}}: $ 目标类别个数(包含背景)
$ t_i = \sum_j n_{ij}: < f o n t s t y l e = " c o l o r : r g b ( 28 , 31 , 35 ) ; " > 目标类别 < / f o n t > <font style="color:rgb(28, 31, 35);"> 目标类别 </font> <fontstyle="color:rgb(28,31,35);">目标类别</font> i $ 的总像素个数(真实标签)
这里使用混淆矩阵来解释上面的指标, 这里介绍对于类别0的判断,在真实标签中类比0有16个,而在预测标签中有两个类别1被误认类别0。
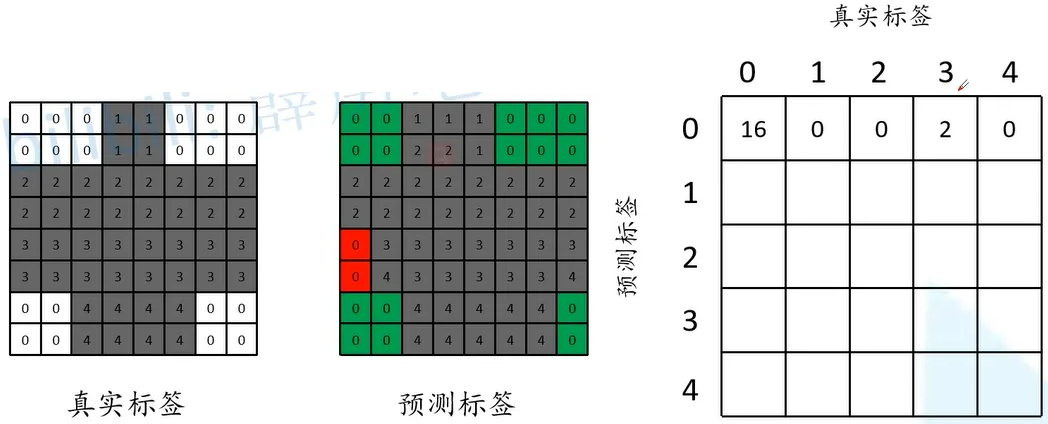
以此类推就可以得到整个混淆举证的值。
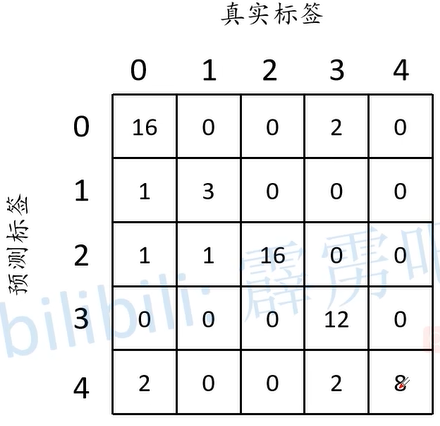
此时,在三个参数的计算如下:
对于Pixel Accuracy(Global Acccuacy):$ \frac{\sum_{i} n_{ii}}{\sum_{i} t_{i}} = \frac{16 + 3 + 16 + 12 + 8}{64} \approx 0.859 $,分子就为预测正确的数量之和,即混淆矩阵的对角线和,分母就为混淆举证中所有的元素之和。而对于每个类别的准确率如下,
其分子为混淆矩阵中真实标签为对应类别的数总和,分母为混淆举证中预测标签为对应矩阵的数总和。
$ \begin{array}{ccccc} \text{cls0\_acc} & \text{cls1\_acc} & \text{cls2\_acc} & \text{cls3\_acc} & \text{cls4\_acc} \\ \dfrac{16}{20} & \dfrac{3}{4} & \dfrac{16}{16} & \dfrac{12}{16} & \dfrac{8}{8} \\ \end{array} $
对于mean IoU:$ \frac{\frac{1}{n_{cls}} \cdot \sum n_{ii}}{\sum_{i} t_{i} + \sum_{j} n_{ji} - n_{ii}} ,解读以下, ∗ ∗ 分子为所有预测正确数总和 / 类别数量 ∗ ∗ ,分母为真实对应类别的数总和 + 预测对应类别的数总和(例如将类别 ,解读以下,**分子为所有预测正确数总和 / 类别数量**,分母为真实对应类别的数总和 + 预测对应类别的数总和(例如将类别 ,解读以下,∗∗分子为所有预测正确数总和/类别数量∗∗,分母为真实对应类别的数总和+预测对应类别的数总和(例如将类别 j 预测成 预测成 预测成 i d 的数量总和,其中 d的数量总和,其中 d的数量总和,其中 j 可以等于 可以等于 可以等于 i ) + 预测正确的数量(本身是类别 ) + 预测正确的数量(本身是类别 )+预测正确的数量(本身是类别 i 预测结果也是类别 预测结果也是类别 预测结果也是类别 i $),所有类别的IoU结果如下:
$ \begin{array}{ccccc} \text{cls0_iou} & \text{cls1_iou} & \text{cls2_iou} & \text{cls3_iou} & \text{cls4_iou} \ \dfrac{16}{20 + 18 - 16} & \dfrac{3}{4 + 4 - 3} & \dfrac{16}{16 + 18 - 16} & \dfrac{12}{16 + 12 - 12} & \dfrac{8}{8 + 12 - 8} \ \end{array}
$
这里挑类别0的IoU进行解释,分子为16,即真实标签为类别0,预测也为类别0。 分母第一个数,即预测为类别0的总个数20,第二个数为预测结果为类别0的总个数18,第三个数为真实标签为类别0,预测也为类别0,总数量为16。
语义分割标注工具
Labelme
网址:https://github.com/wkentaro/labelme
参考博客:Labelme分割标注软件使用_labelme2voc.py-CSDN博客
EISeg
网址:https://github.com/PaddlePaddle/PaddleSeg
参考博客:EISeg分割标注软件使用_eiseg使用-CSDN博客
转置卷积
内容介绍
转置卷积(transposed convolution),其通常用于上采样(upsampling)。转置卷积需要注意的两个点,转置卷积不是卷积的逆运算、转置卷积也是卷积。
转置卷积运算主要步骤如下:
- 在输入特征图元素间填充$ s - 1 $行、列的0元素
- 在输入特征图周围填空 $ k - p - 1 $行、列的0元素
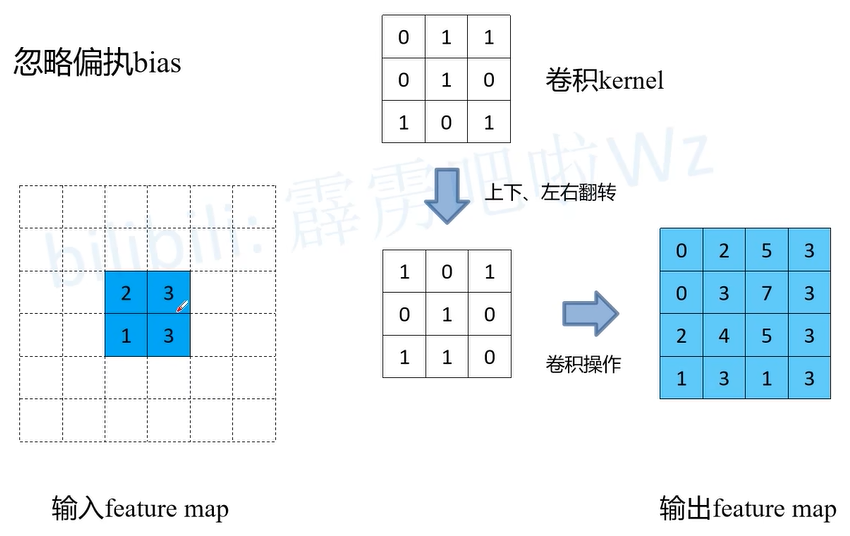
- 将卷积核参数上下、左右翻转
- 做正常的卷积核运算(填充0,步距1,始终为1)
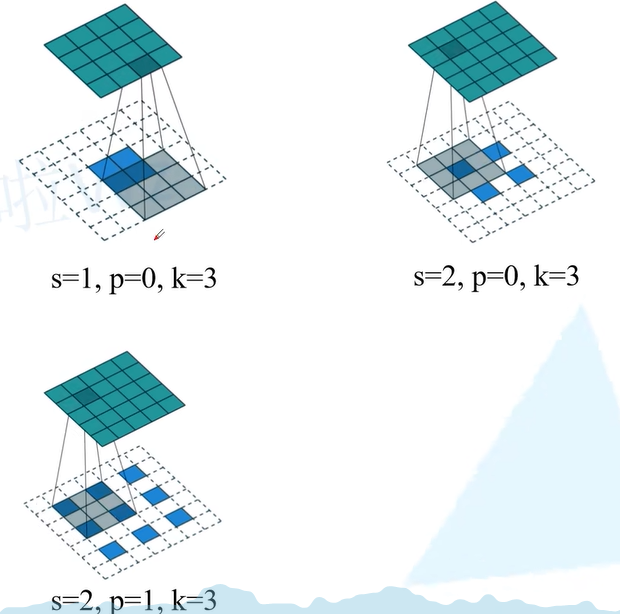
下图中可以看到步骤1,对特征图元素间填充,例如s = 2,p = 0, k = 3, 元素间填充2 - 1 = 1行和列的0元素。步骤2对元素周围填充,例如s = 1,p = 0, k = 3, 特征图周围填充3 - 0 - 1 = 2的行和列元素。
最终可以得到,特征图的高和宽的计算公式。
$ H_{out} = (H_{in} - 1) \times \text{stride}[0] - 2 \times \text{padding}[0] + \text{kernel_size}[0] < f o n t s t y l e = " c o l o r : r g b ( 28 , 31 , 35 ) ; " > < / f o n t > <font style="color:rgb(28, 31, 35);"></font> <fontstyle="color:rgb(28,31,35);"></font> W_{out} = (W_{in} - 1) \times \text{stride}[1] - 2 \times \text{padding}[1] + \text{kernel_size}[1] $
对于步骤3、4,进行如下计算,最终得到输出的结果特征图。
下面介绍Pytorch中转置卷积的参数:
in_channels和out_channels分别为输入输出的通道数
kernel_size为转置卷积的卷积核大小,stride为步幅,padding为扩充
output_padding为在输出特征图每个维度的一侧添加的额外尺寸,默认为0
groups为从输入通道到输出通道的分组连接数,默认为1
bias为是否添加偏置值,默认为Ture
dilation为卷积核元素之间的间距,也称为扩张率,默认为1

其根据上述参数可以得到最终特征图的高宽计算公式为:
$ \begin{align*} H_{out} &= (H_{in} - 1) \times \text{stride}[0] - 2 \times \text{padding}[0] + \text{dilation}[0] \times (\text{kernel_size}[0] - 1) + \text{output_padding}[0] + 1 \ W_{out} &= (W_{in} - 1) \times \text{stride}[1] - 2 \times \text{padding}[1] + \text{dilation}[1] \times (\text{kernel_size}[1] - 1) + \text{output_padding}[1] + 1 \end{align*} $
参考论文
A guide to convolution arithmetic for deep.pdf
**空洞(膨胀)**卷积
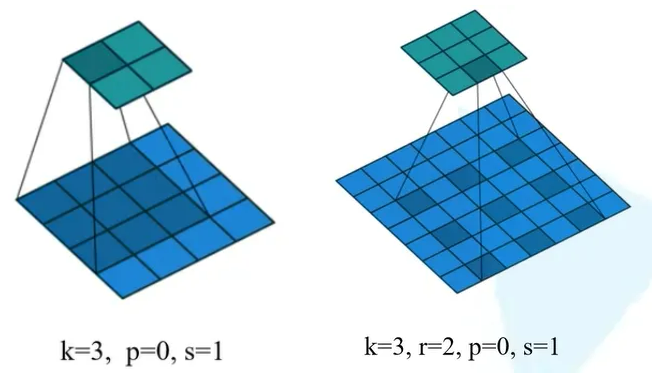
膨胀卷积(Dilated convolution)或者空洞卷积(Atrous convolution),在卷积运算中让卷积核在计算时相隔r个单位像素,当r=1时就为原始的卷积。
膨胀卷积的主要作用就是,增大感受野 并同时 保持原输入特征图W、H,下面的膨胀卷积特征图缩小是因为没有设置好padding值。
但是使用膨胀卷积可能会出现gridding effect影响,导致卷积运算跳过某个像素,丢失一部分信息。这里使用三层卷积层来举例这种现象。
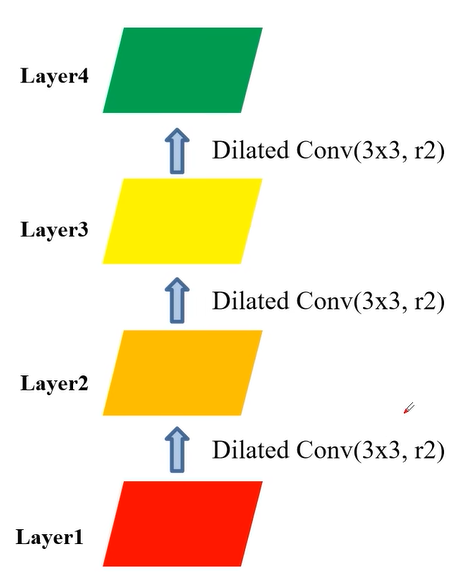
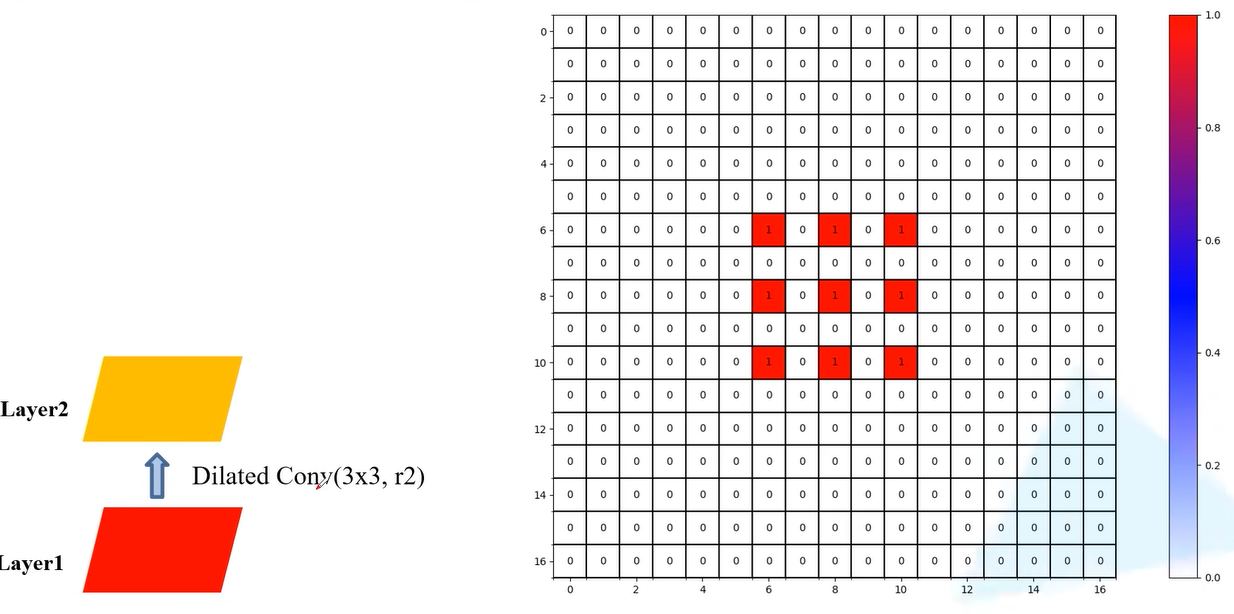
首先,第一步卷积后,Layer2会使用Layer1上9个像素。
然后,第二步卷积后, Layer3会使用Layer2上25个像素。
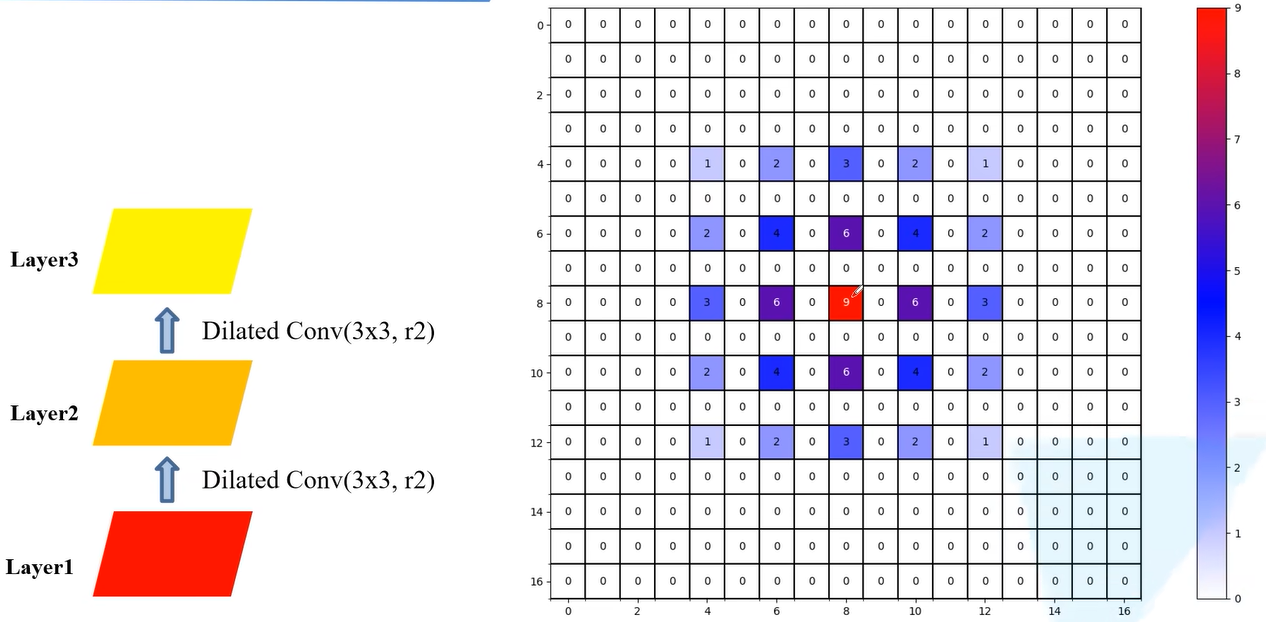
最后,第三步卷积后, Layer4会使用Layer3上36个像素。
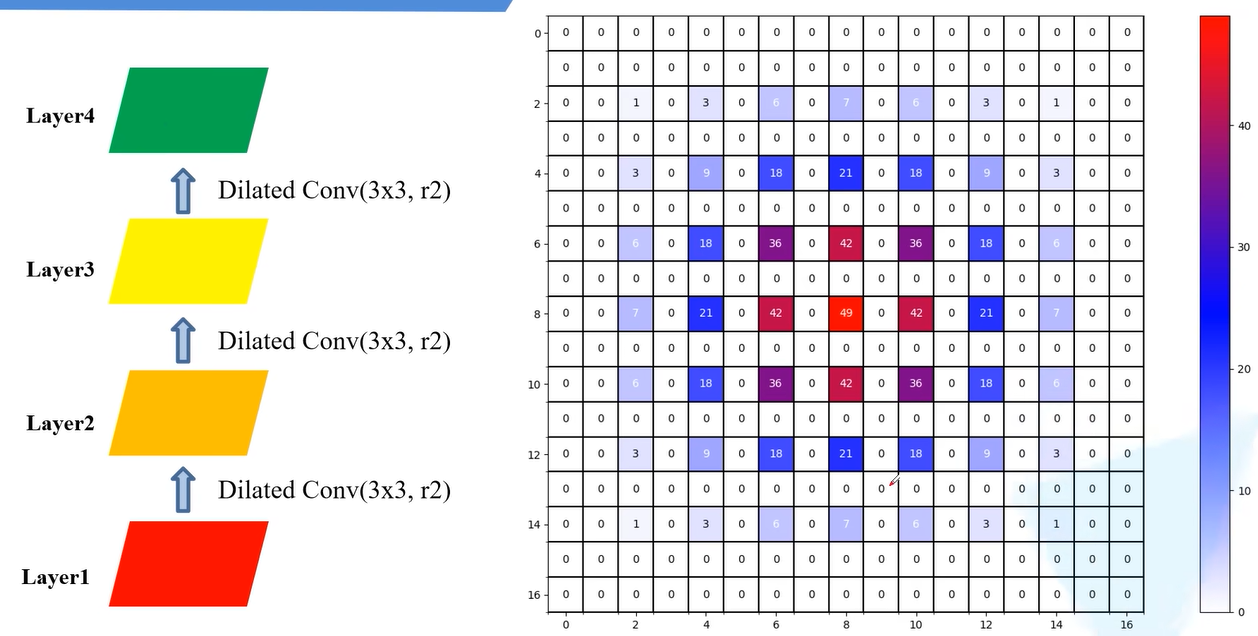
可以看出,上述的利用原图的像素每个非零元素都是有一定间隙的,并不连续。没有利用到所有的像素值,这样可能会丢失一部分的信息。
但是遵循一定的$ r $设置就可以避免这种现象,同时利用相同大小的像素。
例如,在下面$ r $的设置中,参数相同的情况下获得了和上面相同大小的像素值,且利用像素点也紧凑。
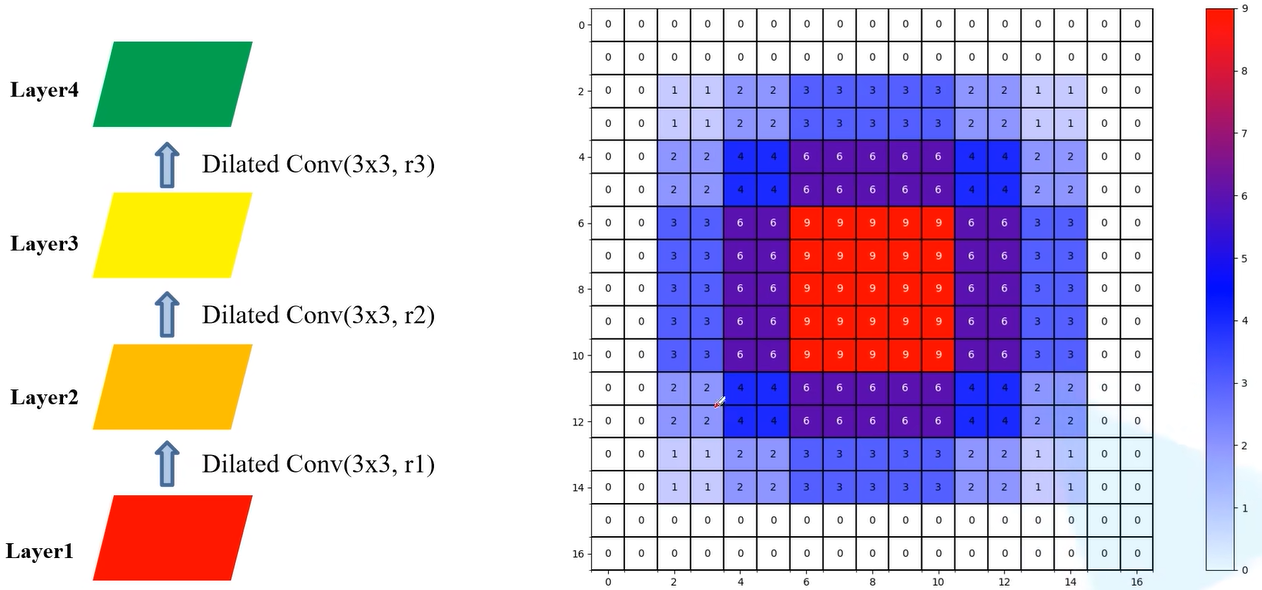
遵循条件1: $ M_2 层的 r 要小于 层的r要小于 层的r要小于 K ,同时遵循 ,同时遵循 ,同时遵循 M_i=max[M_{i+1}-2r_i,M_{i+1}-2(M_{i+1}-r_i),r_i] $。

遵循条件2:建议将膨胀卷积设置成锯齿状。

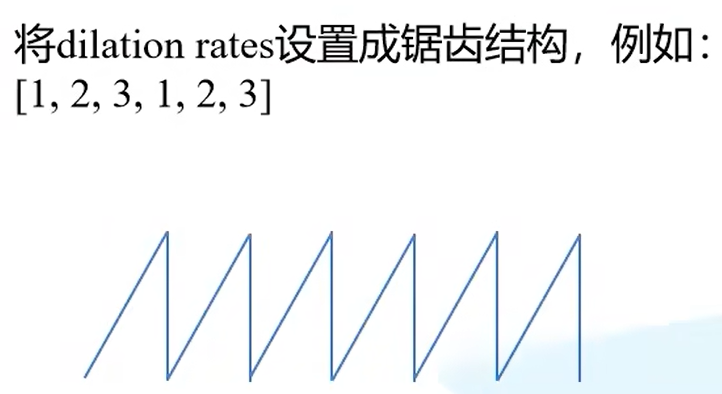
遵循条件3:公约数不能大于1

参考论文
Understanding Convolution for Semantic Segmentation.pdf
FCN
FCN(Fully Convolutional Networks for Semantic Segmentation),全卷积网络是首个端对端的针对像素级预测的全卷积网络。在FCN中使用**VGG16**作为Backbone,保留了VGG16的卷积层和池化层,并把最后的全连接层全部改成卷积层,用来作为图像的像素级预测。
虽然使用卷积层代替全连接层,但是其最终的参数并没有改变,通过增加通道数来使得参数数量在替换后不变。
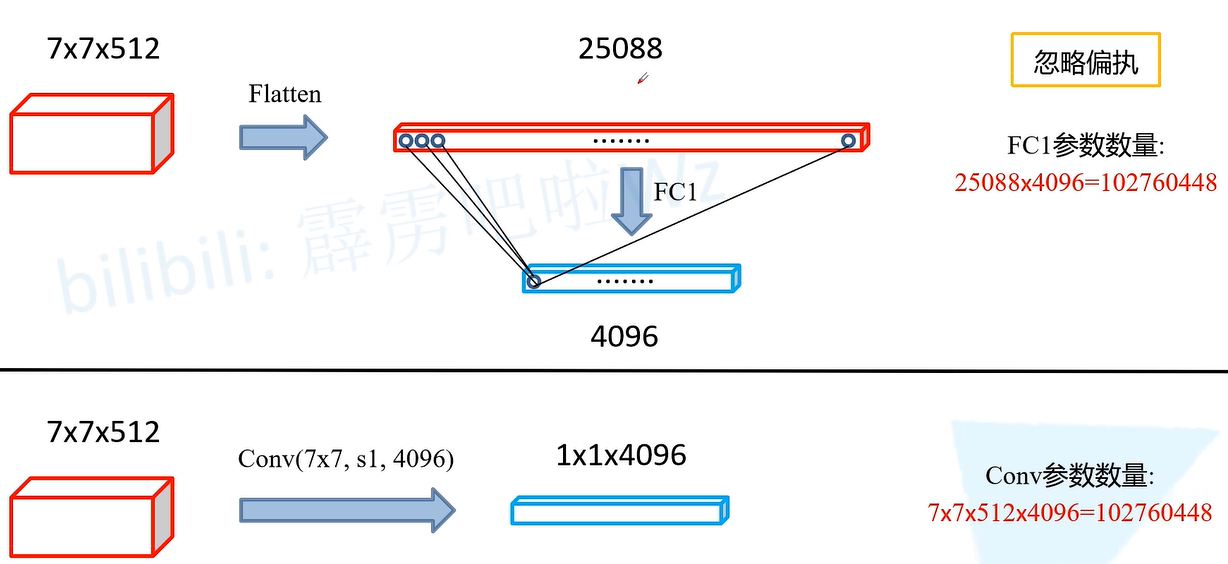
FCN的类别在论文中,主要分为FCN-32S、FCN-16S、FCN-8S,其中FCN-8S的性能最好,当然参数也更多。以为对各个FCN的详细介绍:
FCN-32S
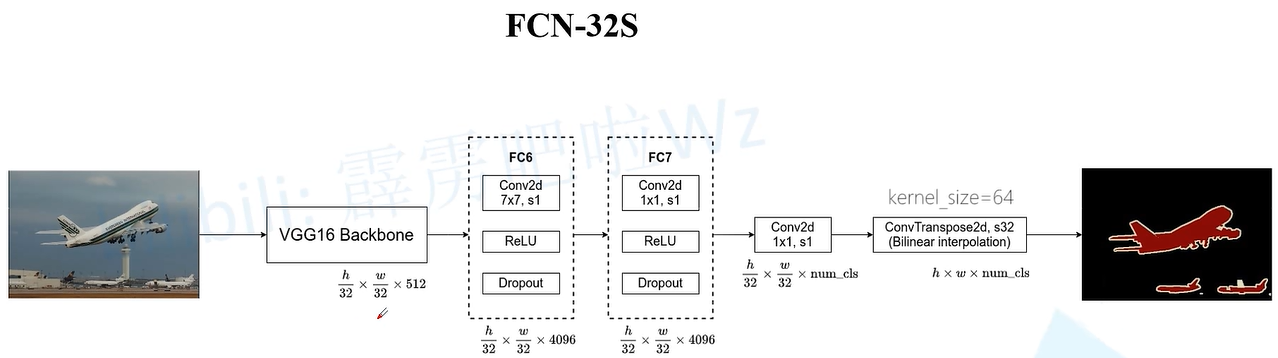
代码实现:
class FCN32s(nn.Module):
"""There are some difference from original fcn"""
def __init__(self, nclass, backbone='vgg16', aux=False, pretrained_base=True,
norm_layer=nn.BatchNorm2d, **kwargs):
super(FCN32s, self).__init__()
self.aux = aux # 是否需要辅助损失分支
if backbone == 'vgg16': # 获取VGG16骨干网络(全连接层之前的)
self.pretrained = vgg16(pretrained=pretrained_base).features
else: # 若不为VGG16 则报错
raise RuntimeError('unknown backbone: {}'.format(backbone))
self.head = _FCNHead(512, nclass, norm_layer) # 中间处理过程
if aux:
self.auxlayer = _FCNHead(512, nclass, norm_layer)
self.__setattr__('exclusive', ['head', 'auxlayer'] if aux else ['head'])
def forward(self, x):
size = x.size()[2:] # 获取高和宽
pool5 = self.pretrained(x) # 进行VGG16骨干网络训练
outputs = []
out = self.head(pool5) # 将经过VGG16 高和宽下采样32倍进行中间处理 即_FCNHead
# 进行双线性插值 将图片尺寸恢复至原来的大小
out = F.interpolate(out, size, mode='bilinear', align_corners=True)
outputs.append(out)
if self.aux:
auxout = self.auxlayer(pool5)
auxout = F.interpolate(auxout, size, mode='bilinear', align_corners=True)
outputs.append(auxout)
return tuple(outputs) # 返回结果元组
# 用来代替图片中的 FC6和FC7以及后面的通道数改变 工程代码
class _FCNHead(nn.Module):
def __init__(self, in_channels, channels, norm_layer=nn.BatchNorm2d, **kwargs):
super(_FCNHead, self).__init__()
inter_channels = in_channels // 4
self.block = nn.Sequential(
nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels), # 批量归一化
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Conv2d(inter_channels, channels, 1) # 通道数转化为类别数
)
def forward(self, x):
return self.block(x)
FCN-16S
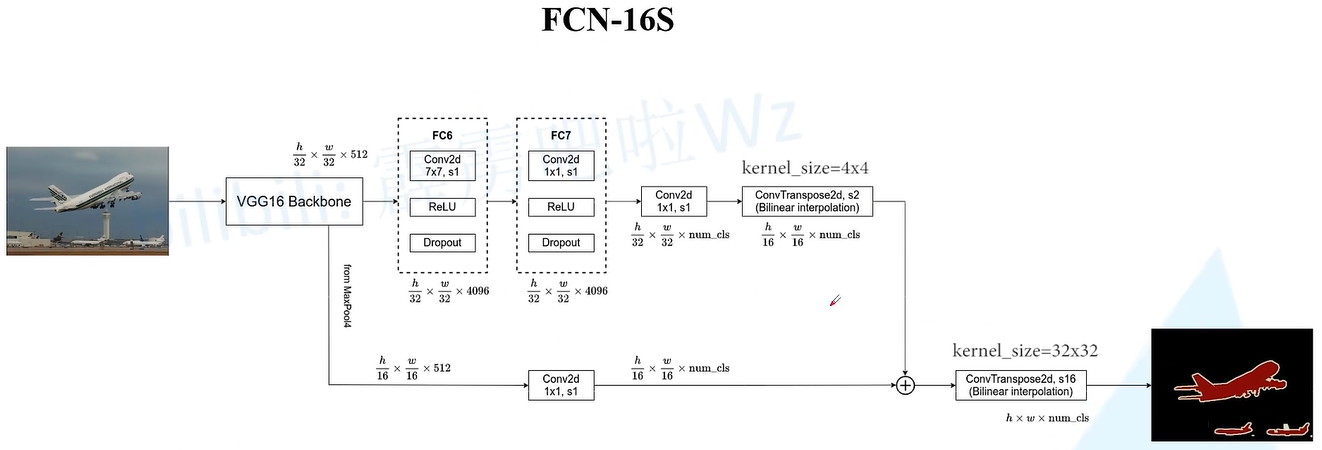
其中工程实现和论文中是实现不同,其是先将经过vgg->_FCNHead得到的score_fr(h/32, w/32,nclass)进行线性插值得到upscore2(h/16, w/16, nclass)与经过pool4(h/16, w/16, nclass)相加,最后再进行线性插值得到最终结果out(h,w,nclass)。
代码实现:
class FCN16s(nn.Module):
def __init__(self, nclass, backbone='vgg16', aux=False, pretrained_base=True, norm_layer=nn.BatchNorm2d, **kwargs):
super(FCN16s, self).__init__()
self.aux = aux
if backbone == 'vgg16': # 获取VGG16骨干网络(全连接层之前的)
self.pretrained = vgg16(pretrained=pretrained_base).features
else:
raise RuntimeError('unknown backbone: {}'.format(backbone))
self.pool4 = nn.Sequential(*self.pretrained[:24]) # 16倍下采样率 pool5前面的VGG
self.pool5 = nn.Sequential(*self.pretrained[24:]) # 32倍下采样率
self.head = _FCNHead(512, nclass, norm_layer)
self.score_pool4 = nn.Conv2d(512, nclass, 1) # 下面经过pool4得到的结果
if aux:
self.auxlayer = _FCNHead(512, nclass, norm_layer)
self.__setattr__('exclusive', ['head', 'score_pool4', 'auxlayer'] if aux else ['head', 'score_pool4'])
def forward(self, x):
pool4 = self.pool4(x) # 得到 h / 32, w / 32, 512
pool5 = self.pool5(pool4) # 得到 h / 16, w / 16, 512
outputs = []
# score_fr = vgg -> _FCNHead
score_fr = self.head(pool5) # 得到 h / 32, w / 32, nclass
score_pool4 = self.score_pool4(pool4) # 得到 h / 16, w / 16, nclass
# 将socre_fr 进行线性插值得到 shape:[h / 16, w / 16, nclass]
upscore2 = F.interpolate(score_fr, score_pool4.size()[2:], mode='bilinear', align_corners=True)
fuse_pool4 = upscore2 + score_pool4 # 相加经过pool5和pool4的结果
# 最终再进行线性插值得到 shape[h, w, nclass]
out = F.interpolate(fuse_pool4, x.size()[2:], mode='bilinear', align_corners=True)
outputs.append(out)
if self.aux: # 辅助损失分支
auxout = self.auxlayer(pool5)
auxout = F.interpolate(auxout, x.size()[2:], mode='bilinear', align_corners=True)
outputs.append(auxout)
return tuple(outputs) # 返回结果元组
FCN-8S
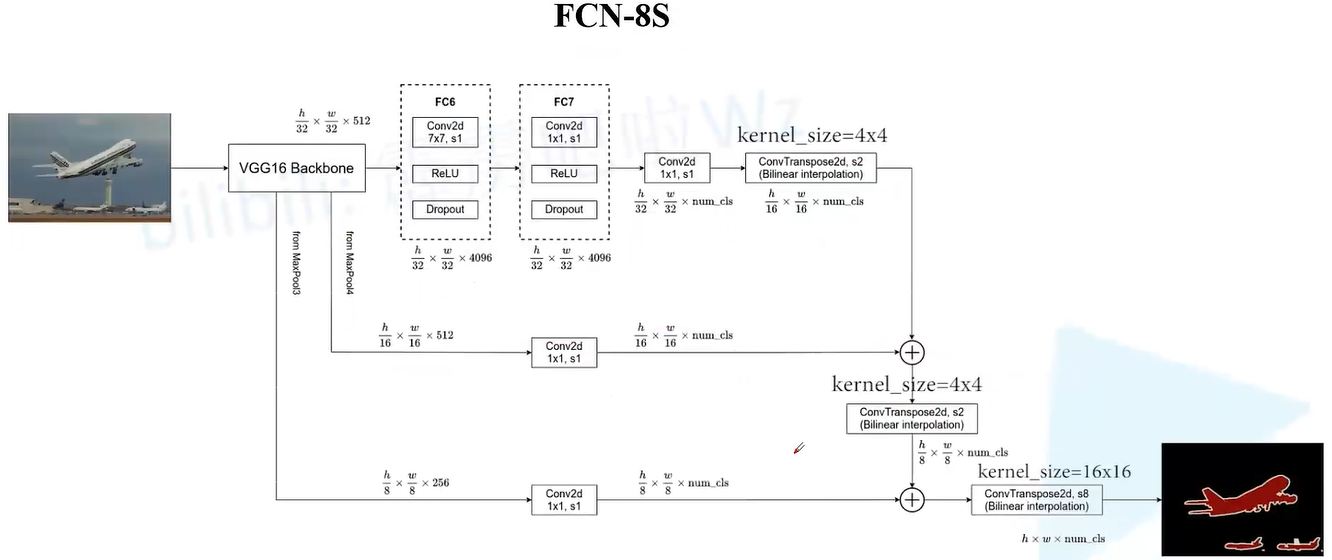
代码实现:
class FCN8s(nn.Module):
def __init__(self, nclass, backbone='vgg16', aux=False, pretrained_base=True, norm_layer=nn.BatchNorm2d, **kwargs):
super(FCN8s, self).__init__()
self.aux = aux
if backbone == 'vgg16':
self.pretrained = vgg16(pretrained=pretrained_base).features
else:
raise RuntimeError('unknown backbone: {}'.format(backbone))
self.pool3 = nn.Sequential(*self.pretrained[:17]) # pool4之前的VGG 8倍下采样率
self.pool4 = nn.Sequential(*self.pretrained[17:24]) # pool4 16倍下采样率
self.pool5 = nn.Sequential(*self.pretrained[24:]) # pool5 32倍下采样率
self.head = _FCNHead(512, nclass, norm_layer) # 将通道数改为nclass
self.score_pool3 = nn.Conv2d(256, nclass, 1) # pool3输出后将通道数改为nclass
self.score_pool4 = nn.Conv2d(512, nclass, 1) # pool4输出后将通道数改为nclass
if aux:
self.auxlayer = _FCNHead(512, nclass, norm_layer)
self.__setattr__('exclusive',
['head', 'score_pool3', 'score_pool4', 'auxlayer'] if aux else ['head', 'score_pool3',
'score_pool4'])
def forward(self, x):
pool3 = self.pool3(x)
pool4 = self.pool4(pool3)
pool5 = self.pool5(pool4)
outputs = []
score_fr = self.head(pool5) # 得到 h / 32, w / 32, nclass
score_pool4 = self.score_pool4(pool4) # 得到 h / 16, w / 16, nclass
score_pool3 = self.score_pool3(pool3) # 得到 h / 8, w / 8, nclass
# 先将 pool5经过线性插值和pool4结果相加
upscore2 = F.interpolate(score_fr, score_pool4.size()[2:], mode='bilinear', align_corners=True)
fuse_pool4 = upscore2 + score_pool4 # 得到 h / 16, w / 16, nclass
# 再将中间的值经过线性插值与pool3结果相加
upscore_pool4 = F.interpolate(fuse_pool4, score_pool3.size()[2:], mode='bilinear', align_corners=True)
fuse_pool3 = upscore_pool4 + score_pool3 # 得到 h / 8, w / 8, nclass
# 最终得到 h, w, nclass
out = F.interpolate(fuse_pool3, x.size()[2:], mode='bilinear', align_corners=True)
outputs.append(out)
if self.aux:
auxout = self.auxlayer(pool5)
auxout = F.interpolate(auxout, x.size()[2:], mode='bilinear', align_corners=True)
outputs.append(auxout)
return tuple(outputs) # 返回结果元组
参考论文
ENet
概述
ENet(Efficient Neural Network)是专门为实时语义分割任务设计的深度神经网络框架,与SegNet相比其在尺寸和推理时间都有显著优势。其核心结构为大编码器和小解码器的组合,基于观点:解码器的主要作用是对编码器的输出进行上采样并进行微调细节,使得参数大幅度减少,仅为0.7MB,降低了网络使用的硬件要求。
模型结构
在网络模型中核心模块如下,其中图(a)为初始输入数据的**initialize,而图(b)则为网络组成的主要部分Bottleneck**。
InitialBlock中分别对输入数据进行$ 3 \times 3 $大小,stride为2的卷积和Maxpooling操作后,在进行Concat合并,并对合并结果执行bn操作,即对Concat后结果图片通道数增加3。
Bottleneck主要由三部分构成:$ 1 \times 1 ∗ ∗ < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ! i m p o r t a n t ; " > 投影卷积、主卷积层、 < / f o n t > ∗ ∗ **<font style="color:rgb(0, 0, 0) !important;">投影卷积、主卷积层、</font>** ∗∗<fontstyle="color:rgb(0,0,0)!important;">投影卷积、主卷积层、</font>∗∗ 1 \times 1 $拓展卷积。
- $ 1 \times 1 $投影卷积:主要用于减少通道数量
- 主卷积层:核心模块,可以使用标准卷积、空洞卷积或者非对称卷积。对于标准卷积和空洞卷积使用$ 3 \times 3 < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ! i m p o r t a n t ; " > 卷积核大小进行,对于非对称卷积通常使用 < / f o n t > <font style="color:rgb(0, 0, 0) !important;">卷积核大小进行,对于非对称卷积通常使用</font> <fontstyle="color:rgb(0,0,0)!important;">卷积核大小进行,对于非对称卷积通常使用</font> 1 \times 5 < f o n t s t y l e = " c o l o r : r g b ( 0 , 0 , 0 ) ! i m p o r t a n t ; " > 和 < / f o n t > <font style="color:rgb(0, 0, 0) !important;">和</font> <fontstyle="color:rgb(0,0,0)!important;">和</font> 5 \times 1 $的序列。
对于正则化,在Bottleneck2.0之前$ p = 0.01 ,之后 ,之后 ,之后 p = 0.1 $(论文中说明)。
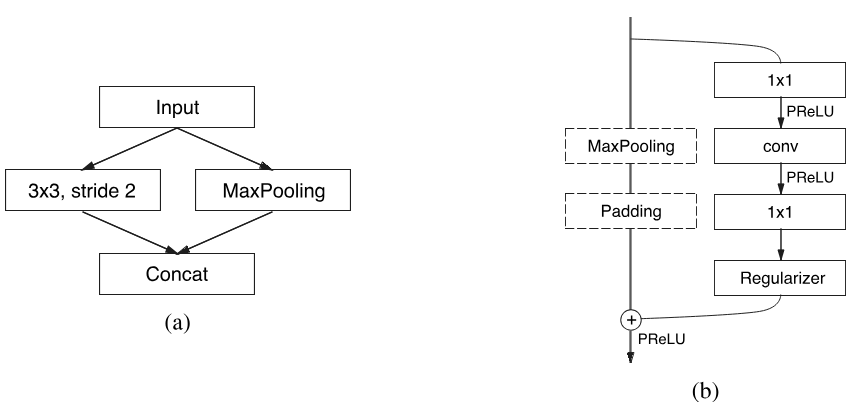
除此之外,网络中每个卷积之后都会使用** normal_layer(批量归一化)和PReLU(激活函数)**。
具体网络结构:
在具体的网络结构中,首先通过Bottleneck,然后进入5个stag的Bottleneck。
其中前3个stage的Bottleneck作为编码器,其中前2个的首个Bottleneck进行下采样操作,后面的Bottleneck进行空洞卷积和非对称卷积交替执行,,
最后2个stage的Bottleneck作为解码器,用于对编码器的图片进行上采样并微调。最终通过一个转置卷积得到最终结果图片。

PReLU激活
PReLU(Parametric Rectified Linear Unit),就是带参数的ReLU激活函数,
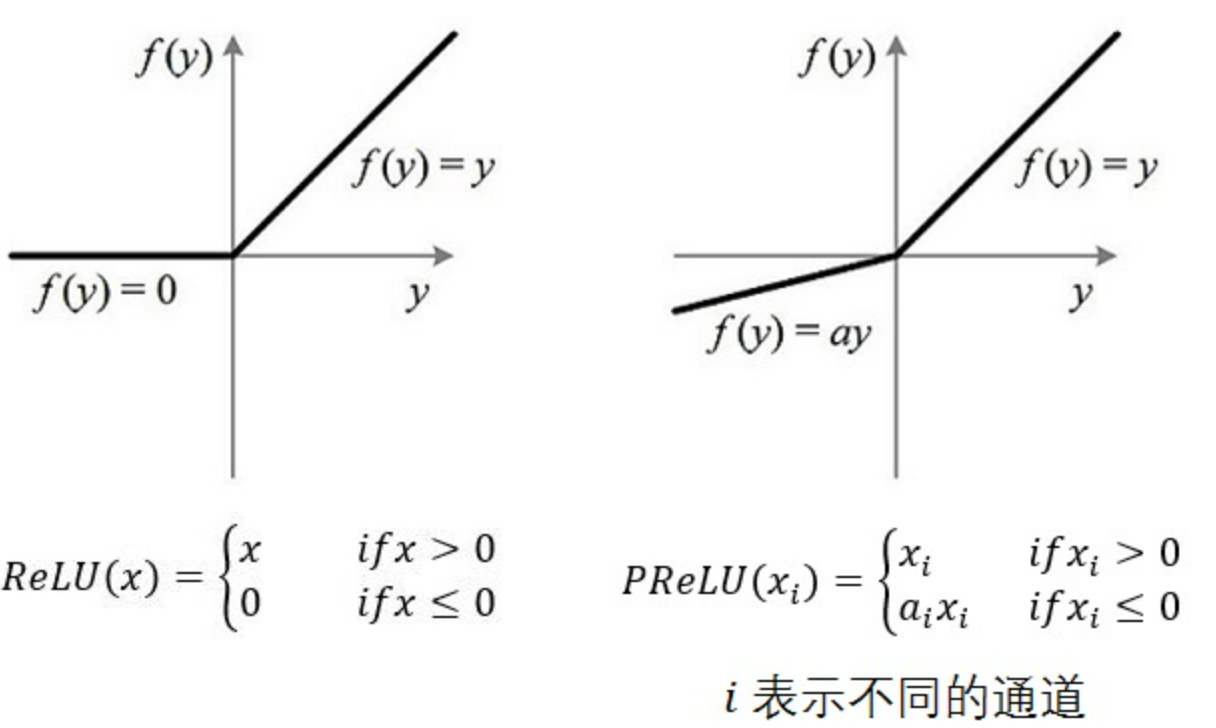
# num_parameters 为可学习参数 a 的数量
# 例如: num_parameter = 1, 所有通道共用一个 a 参数
# num_parameter = c(c为通道数),每个通道都有独立的 a 参数
# init 为 a 参数的初始值 通常保持默认值即可
torch.nn.PReLU(num_parameters=1, init=0.25)
下表为几种ReLU激活函数的对比:
| 激活函数 | 数学表达式 | 可学习参数 | 特点 |
|---|---|---|---|
| ReLU | $ (max(0, x)) $ | 无 | 简单高效,可能导致神经元死亡 |
| Leaky ReLU | $ (max(0.01x, x)) $ | 固定斜率 | 缓解死亡问题,斜率不可学习 |
| PReLU | $ (max(\alpha x, x)) $ | $ (\alpha) $ | 自适应学习斜率,计算高效 |
| ELU/SELU | 指数形式表达式 | 有 | 平滑激活,但计算成本较高 |
代码实现
class InitialBlock(nn.Module):
"""ENet initial block"""
def __init__(self, out_channels, norm_layer=nn.BatchNorm2d, **kwargs):
super(InitialBlock, self).__init__() # k s p
self.conv = nn.Conv2d(3, out_channels, 3, 2, 1, bias=False) # 3x3 卷积
self.maxpool = nn.MaxPool2d(2, 2) # 最大池化
self.bn = norm_layer(out_channels + 3) # bn 增加通道数
self.act = nn.PReLU()
def forward(self, x):
x_conv = self.conv(x)
x_pool = self.maxpool(x)
x = torch.cat([x_conv, x_pool], dim=1) # 合并
x = self.bn(x) # bn操作
x = self.act(x)
return x
class Bottleneck(nn.Module):
"""Bottlenecks include regular, asymmetric, downsampling, dilated"""
def __init__(self, in_channels, inter_channels, out_channels, dilation=1, asymmetric=False,
downsampling=False, norm_layer=nn.BatchNorm2d, **kwargs):
super(Bottleneck, self).__init__()
self.downsamping = downsampling
if downsampling: # 下采样
self.maxpool = nn.MaxPool2d(2, 2, return_indices=True) # 最大池化
self.conv_down = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
norm_layer(out_channels)
)
# 第一部分: 1x1投影卷积 减小通道数目
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, inter_channels, 1, bias=False),
norm_layer(inter_channels),
nn.PReLU()
)
# 第二部分:主卷积层(核心模块) 可以是标准卷积、空洞卷积或者完全卷积
if downsampling: # 如果下采样 => 标准卷积
self.conv2 = nn.Sequential(
nn.Conv2d(inter_channels, inter_channels, 2, stride=2, bias=False),
norm_layer(inter_channels),
nn.PReLU()
)
else:
if asymmetric: # 不进行下采样 使用不对称卷积
self.conv2 = nn.Sequential( # 这里采样非对称卷积
nn.Conv2d(inter_channels, inter_channels, (5, 1), padding=(2, 0), bias=False),
nn.Conv2d(inter_channels, inter_channels, (1, 5), padding=(0, 2), bias=False),
norm_layer(inter_channels),
nn.PReLU()
)
else: # 不进行下采样 步使用不对称卷积 => 空洞卷积
self.conv2 = nn.Sequential( # 空洞卷积
nn.Conv2d(inter_channels, inter_channels, 3, dilation=dilation, padding=dilation, bias=False),
norm_layer(inter_channels),
nn.PReLU()
)
# 第三部分:1 x 1拓展卷积 用于将通道数拓展回原来的大小
self.conv3 = nn.Sequential(
nn.Conv2d(inter_channels, out_channels, 1, bias=False),
norm_layer(out_channels),
nn.Dropout2d(0.1)
)
self.act = nn.PReLU()
def forward(self, x):
identity = x
if self.downsamping: # 下采样
identity, max_indices = self.maxpool(identity) # 保存池化索引
identity = self.conv_down(identity)
out = self.conv1(x) # 1x1投影卷积
out = self.conv2(out) # 核心卷积:标准、空洞或者非对称
out = self.conv3(out) # 1x1拓展卷积
# 直接加上原始输入 和 经过三层卷积后结果的和 进行激活函数
out = self.act(out + identity)
if self.downsamping:
return out, max_indices # 返回结果 和 池化索引
else:
return out
UpsamplingBottleneck
- 设计思想:通过 1×1 卷积降维→3×3 卷积提取特征→1×1 卷积升维,减少参数量和计算量。
- 优势:在保持模型性能的同时,大幅提升计算效率。
前向传播过程:
- 主路径:x → 1×1 卷积(调整通道) → 反池化(恢复尺寸) → out_up。
- 卷积分支:x → 1×1 卷积(降维) → 转置卷积(上采样) → 1×1 卷积(升维) → out_ext。
- 合并:out_up + out_ext → PReLU 激活 → 输出结果。
class UpsamplingBottleneck(nn.Module):
"""upsampling Block"""
# 实现将特征图回复到原始图像尺寸
def __init__(self, in_channels, inter_channels, out_channels, norm_layer=nn.BatchNorm2d, **kwargs):
super(UpsamplingBottleneck, self).__init__()
self.conv = nn.Sequential( # 1x1卷积 调整通道数
nn.Conv2d(in_channels, out_channels, 1, bias=False),
norm_layer(out_channels)
)
self.upsampling = nn.MaxUnpool2d(2) # 反池化
self.block = nn.Sequential(
# 调整通道 降维
nn.Conv2d(in_channels, inter_channels, 1, bias=False),
norm_layer(inter_channels),
nn.PReLU(),
# 转置卷积 上采样
nn.ConvTranspose2d(inter_channels, inter_channels, 2, 2, bias=False),
norm_layer(inter_channels),
nn.PReLU(),
# 调整通道 升维
nn.Conv2d(inter_channels, out_channels, 1, bias=False),
norm_layer(out_channels),
nn.Dropout2d(0.1)
)
self.act = nn.PReLU()
def forward(self, x, max_indices):
out_up = self.conv(x)
# max_indices 能让反池化操作 “记住” 并精确还原高激活值的位置
out_up = self.upsampling(out_up, max_indices)
out_ext = self.block(x)
out = self.act(out_up + out_ext) # 残差连接 + 激活
return out
class ENet(nn.Module):
"""Efficient Neural Network"""
def __init__(self, nclass, backbone='', aux=False, gpu=False, pretrained_base=None, **kwargs):
super(ENet, self).__init__()
self.initial = InitialBlock(13, **kwargs) # 得到通道数16
# 编码器:前三阶段组成编码器 用于通过连续的卷积和池化操作提取图像特征
# stage1: 除第一个Bottleneck 后面核心卷积都为 标准卷积
self.bottleneck1_0 = Bottleneck(16, 16, 64, downsampling=True, **kwargs)
self.bottleneck1_1 = Bottleneck(64, 16, 64, **kwargs)
self.bottleneck1_2 = Bottleneck(64, 16, 64, **kwargs)
self.bottleneck1_3 = Bottleneck(64, 16, 64, **kwargs)
self.bottleneck1_4 = Bottleneck(64, 16, 64, **kwargs)
# stage2: 除第一个Bottleneck 后面执行两次 标准卷积->空洞卷积->非对称卷积->空洞卷积
self.bottleneck2_0 = Bottleneck(64, 32, 128, downsampling=True, **kwargs)
self.bottleneck2_1 = Bottleneck(128, 32, 128, **kwargs)
self.bottleneck2_2 = Bottleneck(128, 32, 128, dilation=2, **kwargs)
self.bottleneck2_3 = Bottleneck(128, 32, 128, asymmetric=True, **kwargs)
self.bottleneck2_4 = Bottleneck(128, 32, 128, dilation=4, **kwargs)
self.bottleneck2_5 = Bottleneck(128, 32, 128, **kwargs)
self.bottleneck2_6 = Bottleneck(128, 32, 128, dilation=8, **kwargs)
self.bottleneck2_7 = Bottleneck(128, 32, 128, asymmetric=True, **kwargs)
self.bottleneck2_8 = Bottleneck(128, 32, 128, dilation=16, **kwargs)
# stage3: 执行两次 标准卷积->空洞卷积->非对称卷积->空洞卷积
self.bottleneck3_1 = Bottleneck(128, 32, 128, **kwargs)
self.bottleneck3_2 = Bottleneck(128, 32, 128, dilation=2, **kwargs)
self.bottleneck3_3 = Bottleneck(128, 32, 128, asymmetric=True, **kwargs)
self.bottleneck3_4 = Bottleneck(128, 32, 128, dilation=4, **kwargs)
self.bottleneck3_5 = Bottleneck(128, 32, 128, **kwargs)
self.bottleneck3_6 = Bottleneck(128, 32, 128, dilation=8, **kwargs)
self.bottleneck3_7 = Bottleneck(128, 32, 128, asymmetric=True, **kwargs)
self.bottleneck3_8 = Bottleneck(128, 32, 128, dilation=16, **kwargs)
# 解码器:后两个阶段组成解码器,使用上采样和空间卷积重建图像,并生成最终分割结果
# stage4: 上采样->标准卷积->标准卷积
self.bottleneck4_0 = UpsamplingBottleneck(128, 16, 64, **kwargs)
self.bottleneck4_1 = Bottleneck(64, 16, 64, **kwargs)
self.bottleneck4_2 = Bottleneck(64, 16, 64, **kwargs)
# stage5: 上采样->标准卷积
self.bottleneck5_0 = UpsamplingBottleneck(64, 4, 16, **kwargs)
self.bottleneck5_1 = Bottleneck(16, 4, 16, **kwargs)
# 转置卷积 上采样 放大图片两倍
self.fullconv = nn.ConvTranspose2d(16, nclass, 2, 2, bias=False)
self.__setattr__('exclusive', ['bottleneck1_0', 'bottleneck1_1', 'bottleneck1_2', 'bottleneck1_3',
'bottleneck1_4', 'bottleneck2_0', 'bottleneck2_1', 'bottleneck2_2',
'bottleneck2_3', 'bottleneck2_4', 'bottleneck2_5', 'bottleneck2_6',
'bottleneck2_7', 'bottleneck2_8', 'bottleneck3_1', 'bottleneck3_2',
'bottleneck3_3', 'bottleneck3_4', 'bottleneck3_5', 'bottleneck3_6',
'bottleneck3_7', 'bottleneck3_8', 'bottleneck4_0', 'bottleneck4_1',
'bottleneck4_2', 'bottleneck5_0', 'bottleneck5_1', 'fullconv'])
def forward(self, x):
# init
x = self.initial(x)
# stage 1
x, max_indices1 = self.bottleneck1_0(x)
x = self.bottleneck1_1(x)
x = self.bottleneck1_2(x)
x = self.bottleneck1_3(x)
x = self.bottleneck1_4(x)
# stage 2
x, max_indices2 = self.bottleneck2_0(x)
x = self.bottleneck2_1(x)
x = self.bottleneck2_2(x)
x = self.bottleneck2_3(x)
x = self.bottleneck2_4(x)
x = self.bottleneck2_5(x)
x = self.bottleneck2_6(x)
x = self.bottleneck2_7(x)
x = self.bottleneck2_8(x)
# stage 3
x = self.bottleneck3_1(x)
x = self.bottleneck3_2(x)
x = self.bottleneck3_3(x)
x = self.bottleneck3_4(x)
x = self.bottleneck3_6(x)
x = self.bottleneck3_7(x)
x = self.bottleneck3_8(x)
# stage 4
x = self.bottleneck4_0(x, max_indices2)
x = self.bottleneck4_1(x)
x = self.bottleneck4_2(x)
# stage 5
x = self.bottleneck5_0(x, max_indices1)
x = self.bottleneck5_1(x)
# out
x = self.fullconv(x)
return tuple([x])
参考论文
PSPNet
概述
PSPNet(Pyramid Scene Parsing Network)金字塔场景解析网络,源于收FCN的缺陷——没有利用全局先验信息,PSPNet利用设计的金字塔模块,使用设计的全局金字塔池化,综合利用上下文先验信息,利用局部和全局线索共同使得最终预测更加可靠。
模型结构
首先原始输入图片经过某个CNN模型得到特征图,如果使用辅助分支,最直接进行另外一个模型进行额外预测,这里代码使用_FCNHead。对于主分支来说,获得特征图之后,进行
池化 =>$ 1 \times 1 ∗ ∗ 卷积 = > 上采样 = > C o n c a t 合并 ∗ ∗ ,其中金字塔池化分为 4 个,得到 **卷积 =>上采样 => Concat合并**,其中金字塔池化分为4个,得到 ∗∗卷积=>上采样=>Concat合并∗∗,其中金字塔池化分为4个,得到 1 \times 1 特征图经过全局平均池化、其他 3 个分别经过 特征图经过全局平均池化、其他3个分别经过 特征图经过全局平均池化、其他3个分别经过 2 \times 2 、 、 、 3 \times 3 、 、 、 6 \times 6 大小平均池化得到对应特征图,此时就是金字塔池化层,然后进行 大小平均池化得到对应特征图,此时就是金字塔池化层,然后进行 大小平均池化得到对应特征图,此时就是金字塔池化层,然后进行 1 \times 1 $卷积将每个特征图的通道数减到in_channels / 4,然后经过上采样统一图片大小再合并,最后进行通道数量的变化得到最终结果图片(若有辅助分支,加上对应结果即可)。
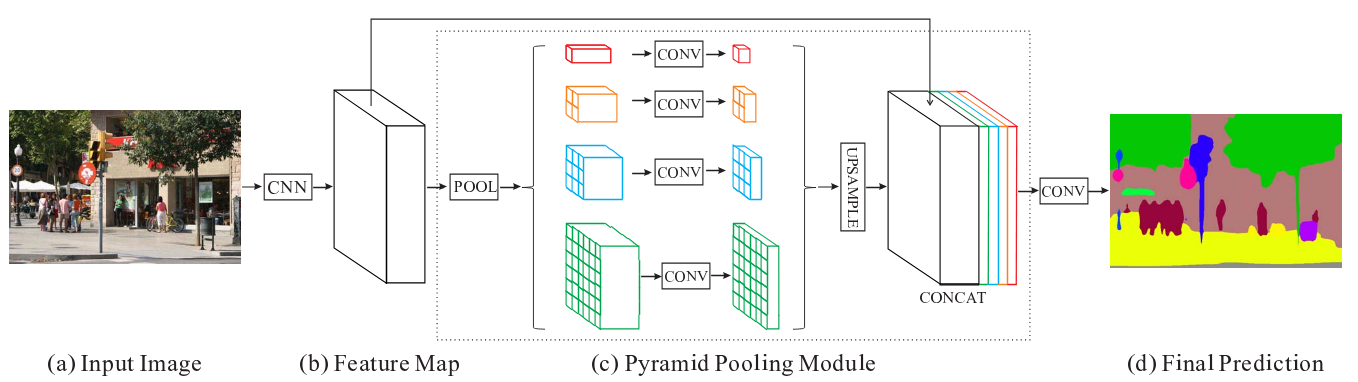
代码实现
class PSPNet(SegBaseModel):
r"""金字塔场景解析网络
参数
----------
nclass : int
训练数据集的类别数量。
backbone : string
预训练的膨胀骨干网络类型(默认:'resnet50';可选 'resnet50'、'resnet101' 或 'resnet152')。
norm_layer : object
骨干网络中使用的归一化层(默认::class:`nn.BatchNorm`;支持同步跨GPU批归一化)。
aux : bool
是否使用辅助损失。
"""
def __init__(self, nclass, backbone='resnet50', aux=False, pretrained_base=True, **kwargs):
super(PSPNet, self).__init__(nclass, aux, backbone, pretrained_base=pretrained_base, **kwargs)
self.head = _PSPHead(nclass, **kwargs)
if self.aux: #
self.auxlayer = _FCNHead(1024, nclass, **kwargs)
# 设置需要特殊处理的模块(如训练时的参数冻结)
self.__setattr__('exclusive', ['head', 'auxlayer'] if aux else ['head'])
def forward(self, x):
# 保存原始输入尺寸用于最终上采样
size = x.size()[2:]
# 通过骨干网络获取多尺度特征 即使用CNN提起得到的特征
# c3:浅层特征(空间分辨率高, 语义信息少)
# c4: 深层特征(空间分辨率低, 语义信息丰富)
_, _, c3, c4 = self.base_forward(x)
outputs = []
# 主分支:处理最高层级特征 c4 => 金字塔池化 => 分割预测
x = self.head(c4)
x = F.interpolate(x, size, mode='bilinear', align_corners=True) # 回复原尺寸
outputs.append(x)
# 辅助分支(如果启用):处理中间层级特征 c3 => 额外预测(可选)
if self.aux:
auxout = self.auxlayer(c3)
auxout = F.interpolate(auxout, size, mode='bilinear', align_corners=True)
outputs.append(auxout)
return tuple(outputs)
def _PSP1x1Conv(in_channels, out_channels, norm_layer, norm_kwargs):
# 1x1卷积块:用于特征降维和非线性变换
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False), # 1x1卷积减少通道数
# 归一化
norm_layer(out_channels, **({} if norm_kwargs is None else norm_kwargs)),
nn.ReLU(True) # 激活函数
)
class _PyramidPooling(nn.Module):
"""金字塔池化模块:通过不同尺度的池化捕获多尺度上下文信息"""
def __init__(self, in_channels, **kwargs):
super(_PyramidPooling, self).__init__()
# 每个分支的输出通道数
out_channels = int(in_channels / 4)
# 不同尺度的自适应平均池化
self.avgpool1 = nn.AdaptiveAvgPool2d(1) # 全局池化
self.avgpool2 = nn.AdaptiveAvgPool2d(2) # 2x2网格
self.avgpool3 = nn.AdaptiveAvgPool2d(3) # 3x3网格
self.avgpool4 = nn.AdaptiveAvgPool2d(6) # 6x6网格
# 每个分支的1x1卷积,统一通道数
self.conv1 = _PSP1x1Conv(in_channels, out_channels, **kwargs)
self.conv2 = _PSP1x1Conv(in_channels, out_channels, **kwargs)
self.conv3 = _PSP1x1Conv(in_channels, out_channels, **kwargs)
self.conv4 = _PSP1x1Conv(in_channels, out_channels, **kwargs)
def forward(self, x):
size = x.size()[2:]
# 各分支处理:池化->卷积->上采样(双线性插值)
# align_corners=True 是插值的对齐参数,保证边缘像素的位置精度(避免预测偏移)。
feat1 = F.interpolate(self.conv1(self.avgpool1(x)), size, mode='bilinear', align_corners=True)
feat2 = F.interpolate(self.conv2(self.avgpool2(x)), size, mode='bilinear', align_corners=True)
feat3 = F.interpolate(self.conv3(self.avgpool3(x)), size, mode='bilinear', align_corners=True)
feat4 = F.interpolate(self.conv4(self.avgpool4(x)), size, mode='bilinear', align_corners=True)
# 拼接原始特征和所有金字塔特征
return torch.cat([x, feat1, feat2, feat3, feat4], dim=1)
class _PSPHead(nn.Module):
"""PSPNet头部模块:整合金字塔池化特征并生成最终分割结果"""
def __init__(self, nclass, norm_layer=nn.BatchNorm2d, norm_kwargs=None, **kwargs):
super(_PSPHead, self).__init__()
# 金字塔池化模块(输入通道2048来自骨干网络)
self.psp = _PyramidPooling(2048, norm_layer=norm_layer, norm_kwargs=norm_kwargs)
# 特征融合和分类模块
self.block = nn.Sequential(
nn.Conv2d(4096, 512, 3, padding=1, bias=False), # 拼接后的特征融合
norm_layer(512, **({} if norm_kwargs is None else norm_kwargs)), # 归一化
nn.ReLU(True), # 激活
nn.Dropout(0.1), # 正则化
nn.Conv2d(512, nclass, 1) # 最终分类层
)
def forward(self, x):
# 多尺度特征融合
x = self.psp(x)
# 生成最终分割结果
return self.block(x)
# 用作辅助分支
class _FCNHead(nn.Module):
def __init__(self, in_channels, channels, norm_layer=nn.BatchNorm2d, **kwargs):
super(_FCNHead, self).__init__()
inter_channels = in_channels // 4
self.block = nn.Sequential(
nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels), # 批量归一化
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Conv2d(inter_channels, channels, 1) # 通道数转化为类别数
)
def forward(self, x):
return self.block(x)
对于SegBaseModel的实现如下,本质上是直接利用resnet50或者其他resnet模型进行训练并给出对于的特征c1、c2、c3、c4。
import torch
import torch.nn as nn
from ..nn import JPU
from .base_models.resnetv1b import resnet50_v1s, resnet101_v1s, resnet152_v1s
class SegBaseModel(nn.Module):
r"""Base Model for Semantic Segmentation
语义分割基础模型类,作为语义分割任务中更具体模型(如 PSPNet 等)的父类,
负责加载预训练骨干网络、实现基础前向传播逻辑等通用功能
"""
def __init__(self, nclass, aux, backbone='resnet50', jpu=False, pretrained_base=True, **kwargs):
"""
初始化语义分割基础模型
:param nclass: int,语义分割任务的类别数量(包括背景类)
:param aux: bool,是否启用辅助损失分支,辅助训练提升性能
:param backbone: str,骨干网络类型,默认'resnet50'
:param jpu: bool,是否启用 JPU(联合金字塔上采样模块),用于特征增强
:param pretrained_base: bool,是否加载骨干网络的预训练权重
:param kwargs: 其他额外关键字参数,可传递给骨干网络等进行定制
"""
super(SegBaseModel, self).__init__()
# 根据是否使用 JPU 决定骨干网络是否采用空洞卷积
# JPU 场景下,骨干网络可能不需要额外空洞卷积,否则启用空洞卷积来增大感受野
dilated = False if jpu else True
self.aux = aux # 记录是否启用辅助损失分支,供后续使用
self.nclass = nclass # 记录类别数量,供后续任务相关模块使用
# 根据传入的骨干网络类型,加载对应的预训练骨干网络模型
if backbone == 'resnet50':
self.pretrained = resnet50_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
elif backbone == 'resnet101':
self.pretrained = resnet101_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
elif backbone == 'resnet152':
self.pretrained = resnet152_v1s(pretrained=pretrained_base, dilated=dilated, **kwargs)
else:
# 若传入不支持的骨干网络类型,抛出运行时错误
raise RuntimeError('unknown backbone: {}'.format(backbone))
# 若启用 JPU,初始化 JPU 模块,用于对不同层级特征进行联合金字塔上采样增强
# JPU 输入是 [512, 1024, 2048] 维度的特征(对应骨干网络不同层输出),输出维度可定制
self.jpu = JPU([512, 1024, 2048], width=512, **kwargs) if jpu else None
def base_forward(self, x):
"""
骨干网络的基础前向传播方法,用于提取不同层级的特征
:param x: torch.Tensor,输入图像张量,形状一般为 [batch_size, 3, height, width]
:return: 若启用 JPU,返回 JPU 处理后的特征;否则返回骨干网络各层输出的特征 c1, c2, c3, c4
"""
# 骨干网络第一层卷积、批归一化、ReLU 激活
x = self.pretrained.conv1(x)
x = self.pretrained.bn1(x)
x = self.pretrained.relu(x)
# 骨干网络最大池化层,进一步缩小特征图尺寸,提取初步特征
x = self.pretrained.maxpool(x)
# 依次经过骨干网络的 layer1 - layer4,得到不同层级的特征
# c1、c2、c3、c4 特征图尺寸逐渐减小,语义信息逐渐丰富,空间细节逐渐减少
c1 = self.pretrained.layer1(x)
c2 = self.pretrained.layer2(c1)
c3 = self.pretrained.layer3(c2)
c4 = self.pretrained.layer4(c3)
# 如果启用了 JPU 模块,将骨干网络输出的四层特征传入 JPU 进行处理,增强特征表达
if self.jpu:
return self.jpu(c1, c2, c3, c4)
else:
# 未启用 JPU 时,直接返回骨干网络各层输出的特征
return c1, c2, c3, c4
def evaluate(self, x):
"""
用于评估阶段的前向传播方法,只返回主分支的预测结果(默认取 forward 结果的第一个输出)
:param x: torch.Tensor,输入图像张量
:return: 主分支的预测结果,形状一般为 [batch_size, nclass, height, width]
"""
return self.forward(x)[0]
def demo(self, x):
"""
用于演示/推理阶段的前向传播方法,返回最终用于可视化等的预测结果
若启用了辅助损失分支,只取主分支的预测结果(即 forward 结果的第一个输出)
:param x: torch.Tensor,输入图像张量
:return: 最终的预测结果,形状一般为 [batch_size, nclass, height, width]
"""
pred = self.forward(x)
if self.aux:
# 若有辅助分支,只保留主分支结果
pred = pred[0]
return pred
参考论文
Pyramid Scene Parsing Network(PSPNet).pdf
ICNet
概述
图像级联网络(ICNet),该网络在适当的标签指导下合并了多分辨率分支。作者对ICNet进行了深入分析,并引入级联特征融合单元以快速实现高质量的分割。ICNet用于多支路轻量化分割网络。
模型结构
ICNet采用了级联特征融合单元并结合级联标签指导进行训练,对于底部使用轻量级CNN将分辨率降为1/8,对于中部和顶部先采用1/2和1/4的下采样,在经过backbone的base_forward来下采样1/8,分别得到中部的1/16分辨率,用于平衡语义和细节;顶部得到1/32分辨率,用于强化语义,其顶部层部分还使用金字塔池化融合多尺度上下文。得到底部(Sub1)、中部(Sub2)、顶部(Sub4)后,使用级联特征融合,先将Sub2和Sub4融合得到1/16的融合特征和辅助预测,并将1/16的融合特征放入结果,再将1/16融合特征与Sub1进行级联融合得到1/8的融合特征和辅助预测,并将1/8的融合特征放入结果。最后再通过两次上采样分别得到1/4和1/1分辨率图片,放入结果中,再对结果翻转就得到最终的结果。
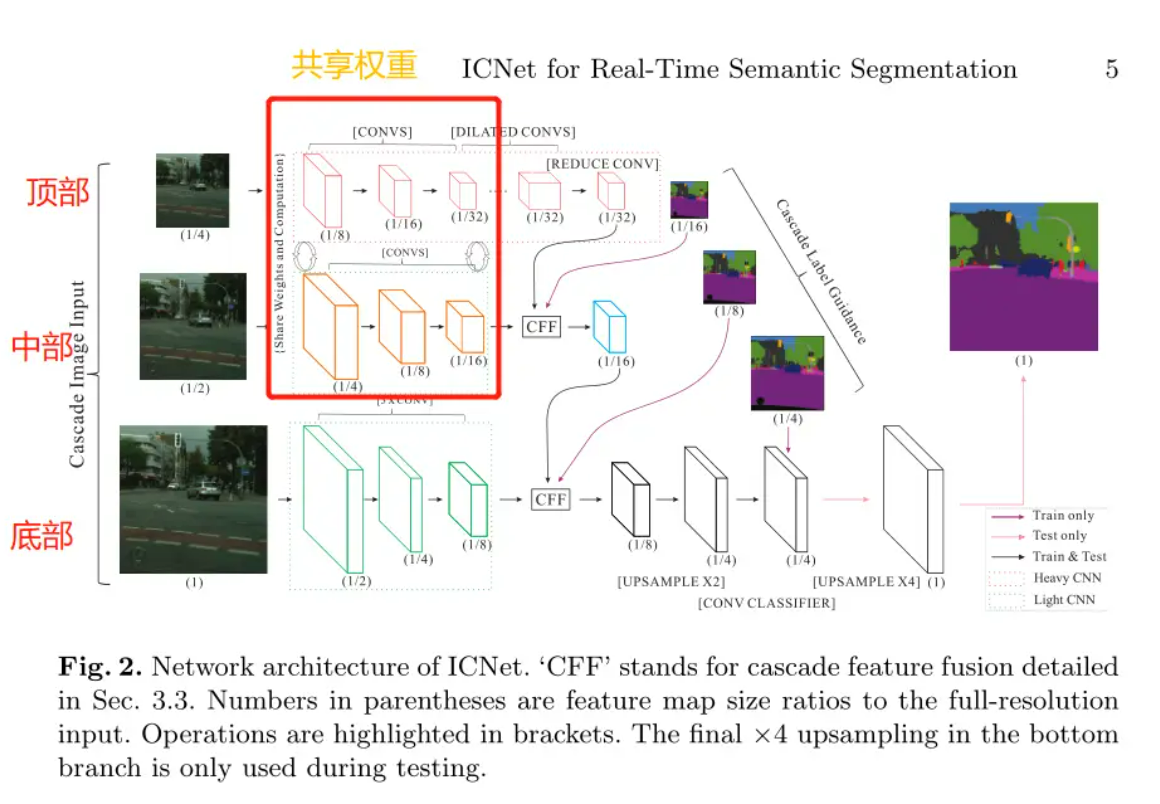
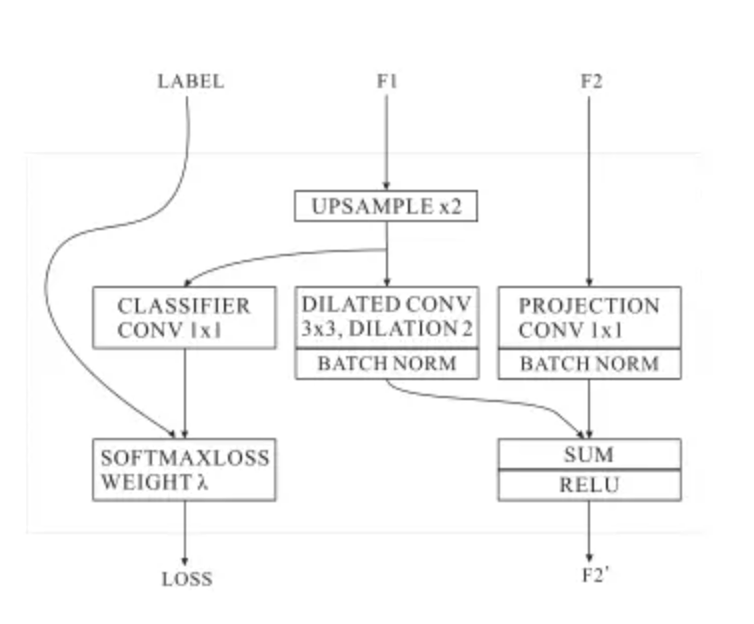
为了融合不同分辨率的特征,作者提出了CFF模块,输入包含了三部分,两个特征图$ F1(C1 \times H1\times W1) 和 和 和 F2(C2 \times H2\times W2) 以及一个标签 以及一个标签 以及一个标签 (1 \times H2\times W2) 。 F 2 的分辨率是 F 1 的两倍。作者首先使用双线性插值将 。F2的分辨率是F1的两倍。作者首先使用双线性插值将 。F2的分辨率是F1的两倍。作者首先使用双线性插值将 F1 的分辨率提升两倍,变成 的分辨率提升两倍,变成 的分辨率提升两倍,变成 F2 相同的分辨率,然后使用卷积核大小为 相同的分辨率,然后使用卷积核大小为 相同的分辨率,然后使用卷积核大小为 (C3 \times 3\times3) 和空洞率为 2 的卷积核来精修上采样特征。此时特征变为了 和空洞率为2的卷积核来精修上采样特征。此时特征变为了 和空洞率为2的卷积核来精修上采样特征。此时特征变为了 (C3 \times H3\times W3) . 空洞卷积结合了来自几个原本相邻像素的特征信息。 < f o n t s t y l e = " c o l o r : r g b ( 64 , 64 , 64 ) ; " > 对于特征 < / f o n t > .空洞卷积结合了来自几个原本相邻像素的特征信息。<font style="color:rgb(64, 64, 64);">对于特征</font> .空洞卷积结合了来自几个原本相邻像素的特征信息。<fontstyle="color:rgb(64,64,64);">对于特征</font> F2 < f o n t s t y l e = " c o l o r : r g b ( 64 , 64 , 64 ) ; " > ,采用卷积核为 < / f o n t > <font style="color:rgb(64, 64, 64);">,采用卷积核为</font> <fontstyle="color:rgb(64,64,64);">,采用卷积核为</font> C3\times1\times1 < f o n t s t y l e = " c o l o r : r g b ( 64 , 64 , 64 ) ; " > 的卷积来讲 < / f o n t > <font style="color:rgb(64, 64, 64);">的卷积来讲</font> <fontstyle="color:rgb(64,64,64);">的卷积来讲</font> F2 < f o n t s t y l e = " c o l o r : r g b ( 64 , 64 , 64 ) ; " > 进行映射,映射后的特征数量和 < / f o n t > <font style="color:rgb(64, 64, 64);">进行映射,映射后的特征数量和</font> <fontstyle="color:rgb(64,64,64);">进行映射,映射后的特征数量和</font> F1 < f o n t s t y l e = " c o l o r : r g b ( 64 , 64 , 64 ) ; " > 相同。接着采用 < / f o n t > <font style="color:rgb(64, 64, 64);">相同。接着采用</font> <fontstyle="color:rgb(64,64,64);">相同。接着采用</font> BN < f o n t s t y l e = " c o l o r : r g b ( 64 , 64 , 64 ) ; " > 对 < / f o n t > <font style="color:rgb(64, 64, 64);">对</font> <fontstyle="color:rgb(64,64,64);">对</font> F1 < f o n t s t y l e = " c o l o r : r g b ( 64 , 64 , 64 ) ; " > 和 < / f o n t > <font style="color:rgb(64, 64, 64);">和</font> <fontstyle="color:rgb(64,64,64);">和</font> F2 $特征进行归一化,然后讲两个特征图进行相加并采用Relu激活函数处理。
为了增强对$ F1 < f o n t s t y l e = " c o l o r : r g b ( 64 , 64 , 64 ) ; " > (小分辨率)的学习,对 < / f o n t > <font style="color:rgb(64, 64, 64);">(小分辨率)的学习,对</font> <fontstyle="color:rgb(64,64,64);">(小分辨率)的学习,对</font> F1 $的上采样特征使用辅助标签进行指导。
参考论文
DeepLabv3
主要改进
相比于DeepLabv2来说,DeepLabv3主要做出了改变:引入了<font style="color:rgb(199, 37, 78);background-color:rgb(249, 242, 244);">Multi-grid</font>、改进了<font style="color:rgb(199, 37, 78);background-color:rgb(249, 242, 244);">ASPP</font>结构、移除了<font style="color:rgb(199, 37, 78);background-color:rgb(249, 242, 244);">CRFs</font>后处理。
模型结构
DeepLabv3主要给出了两种模型,其分别是<font style="color:rgb(199, 37, 78);background-color:rgb(249, 242, 244);">cascaded model</font>和<font style="color:rgb(199, 37, 78);background-color:rgb(249, 242, 244);">ASPP model</font>,在<font style="color:rgb(199, 37, 78);background-color:rgb(249, 242, 244);">cascaded model</font>中是没有使用ASPP模块的,在<font style="color:rgb(199, 37, 78);background-color:rgb(249, 242, 244);">ASPP model</font>中是没有使用cascaded blocks模块的。主要使用是<font style="color:rgb(199, 37, 78);background-color:rgb(249, 242, 244);">ASPP model</font>,这里也主要了解ASPP model。
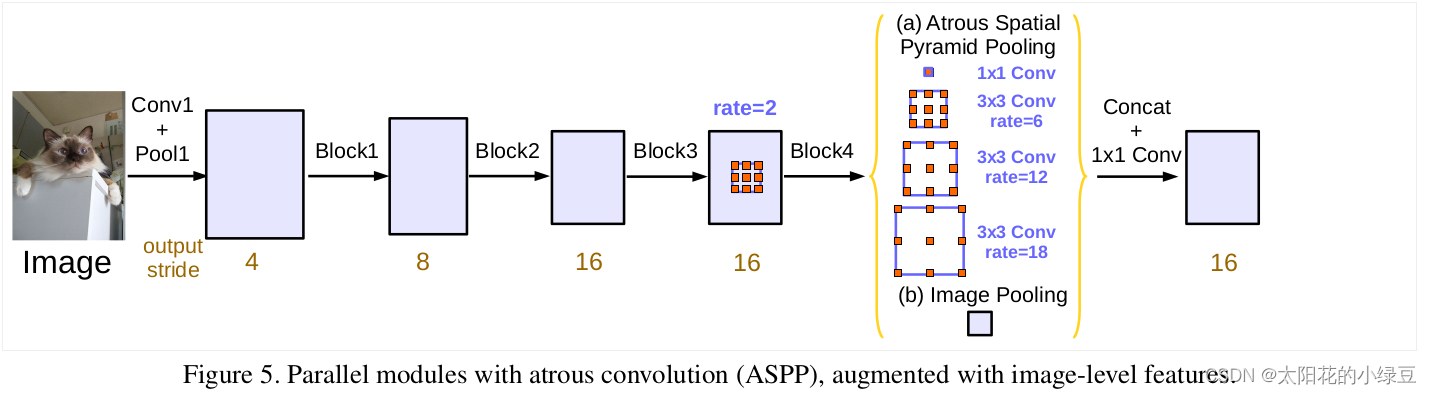
ASPP model结构如下图所示:
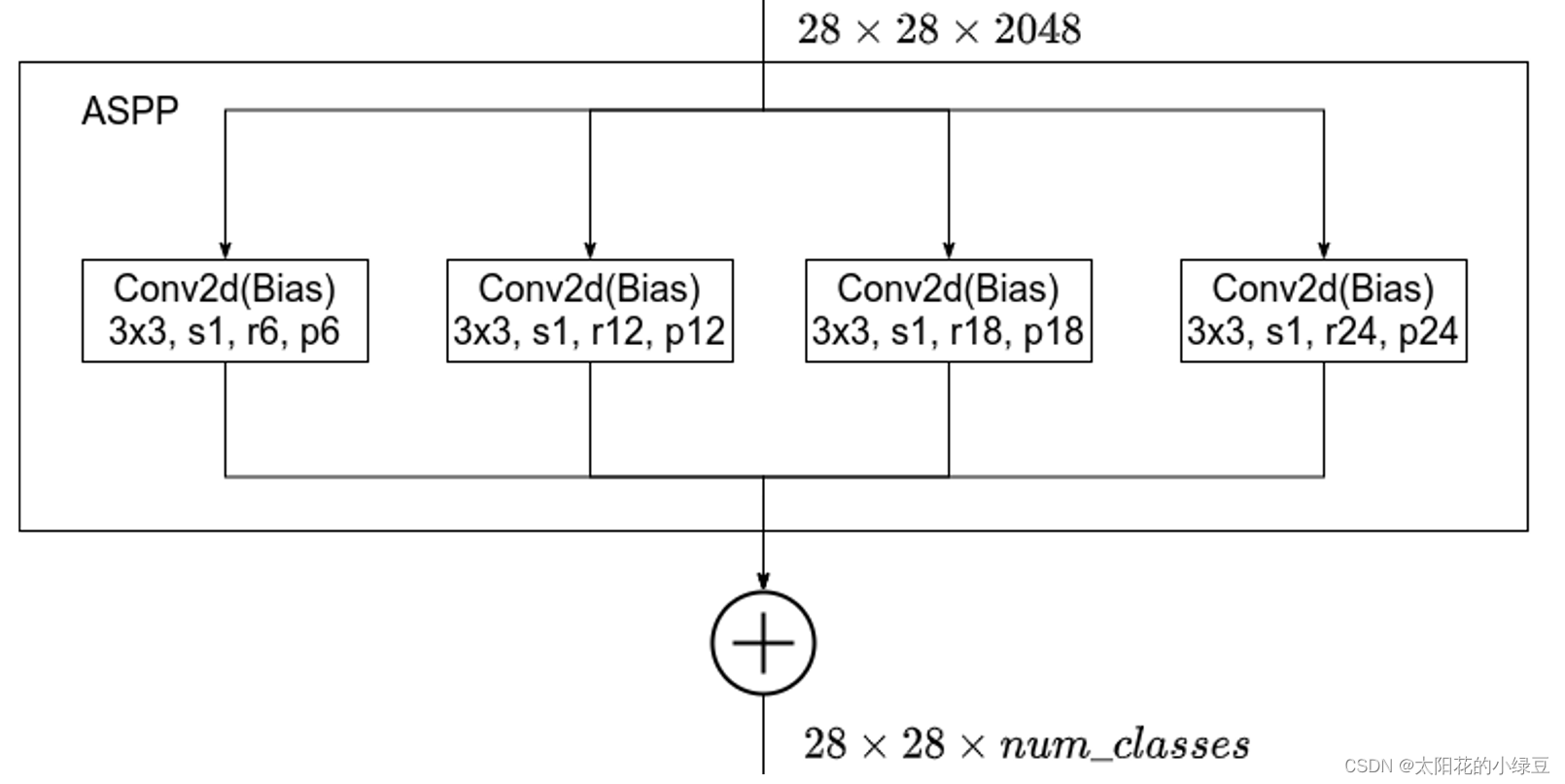
DeepLab V2中的ASPP结构其实就是通过四个并行的膨胀卷积层,每个分支上的膨胀卷积层所采用的膨胀系数不同(注意,这里的膨胀卷积层后没有跟BatchNorm并且使用了偏执Bias)。接着通过add相加的方式融合四个分支上的输出。
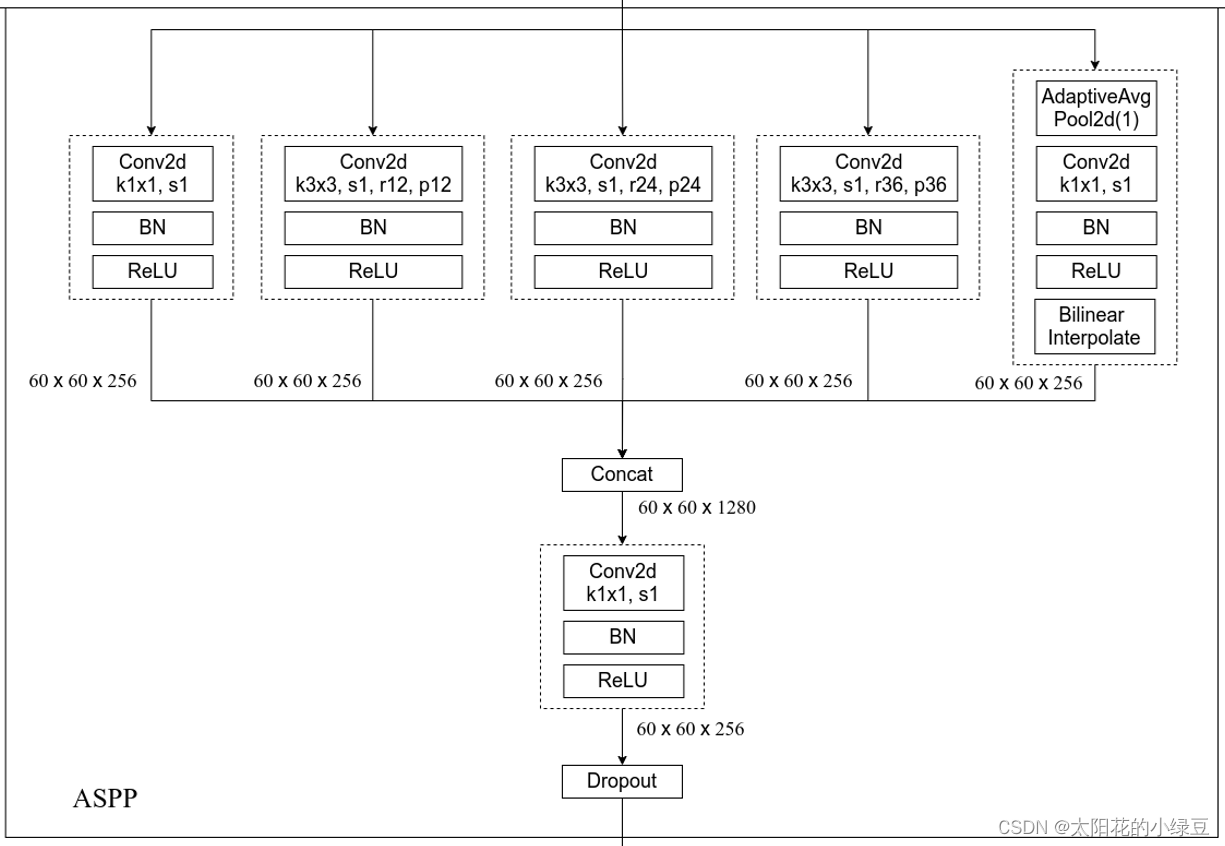
ASPP model中的ASPP结构有5个并行分支,分别是一个1x1的卷积层,三个3x3的膨胀卷积层,以及一个全局平均池化层(后面还跟有一个1x1的卷积层,然后通过双线性插值的方法还原回输入的W和H)。关于最后一个全局池化分支作者说是为了增加一个全局上下文信息。然后通过Concat的方式将这5个分支的输出进行拼接(沿着channels方向),最后在通过一个1x1的卷积层进一步融合信息。
DeepLabv3模型的整体结构图如下,其中也可也选择是否使用FCNHead作为辅助分支。其中把ASPP和处理输出部分作为DeepLabHead。
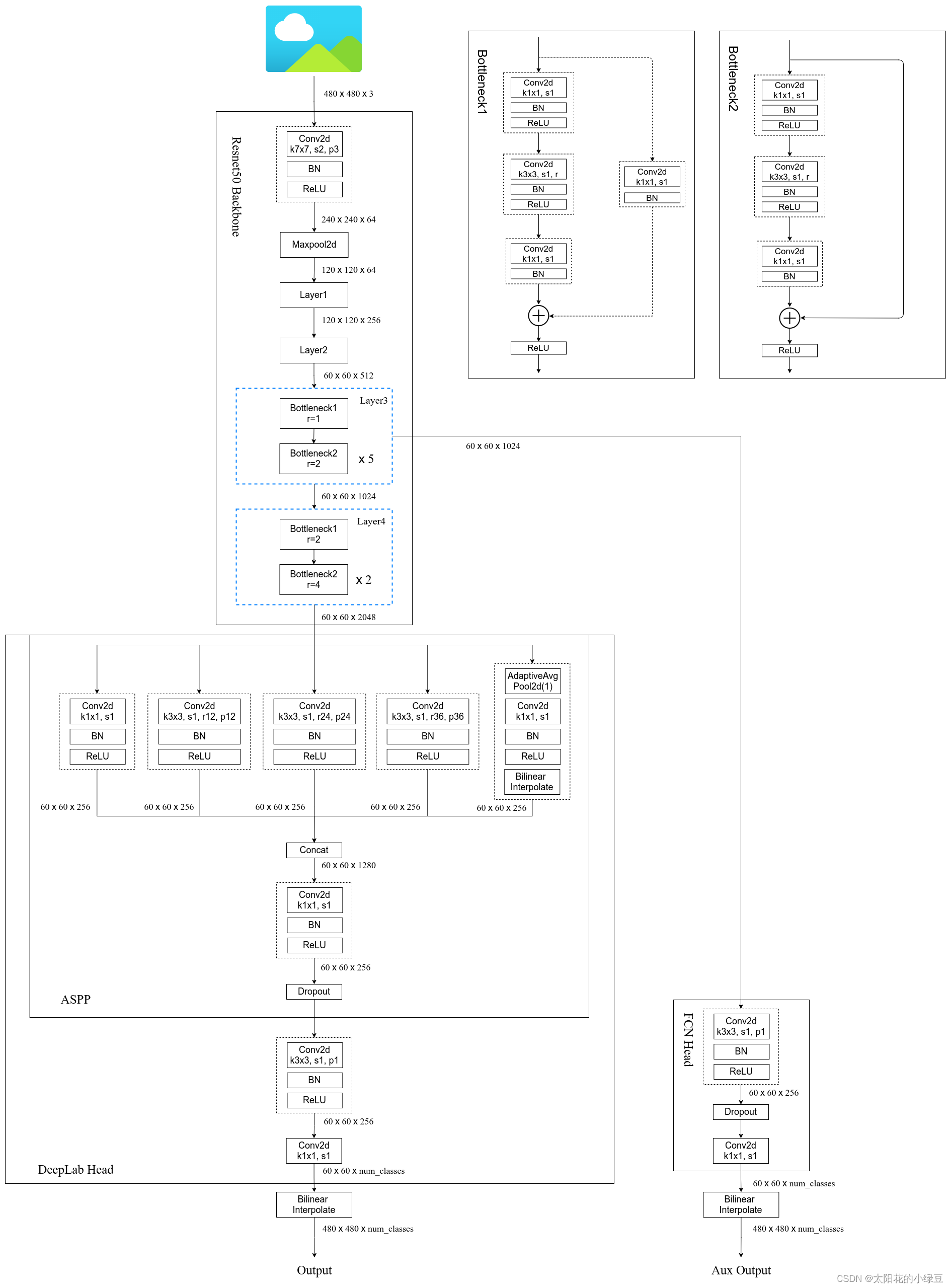
参考文章
DeepLabV3网络简析_deeplabv3网络结构-CSDN博客
DeepLabv3+
主要改进
DeepLabv3+ 最大的改进是将 DeepLab 的 DCNN 部分看做 Encoder,将 DCNN 输出的高语义特征和骨干网络输出的低层次特征融合部分看做 Decoder ,构成 Encoder+Decoder 。
模型结构
先通过base_forward分别提取浅层、中层、深层特征,对于深层特征通过ASPP捕获多尺度上下文,浅层特征降维+特征提取后再给到Decoder,再Decoer中将处理过的深层特征和浅层特征进行拼接融合、修改通道数为类别、上采样,得到最终的结果。
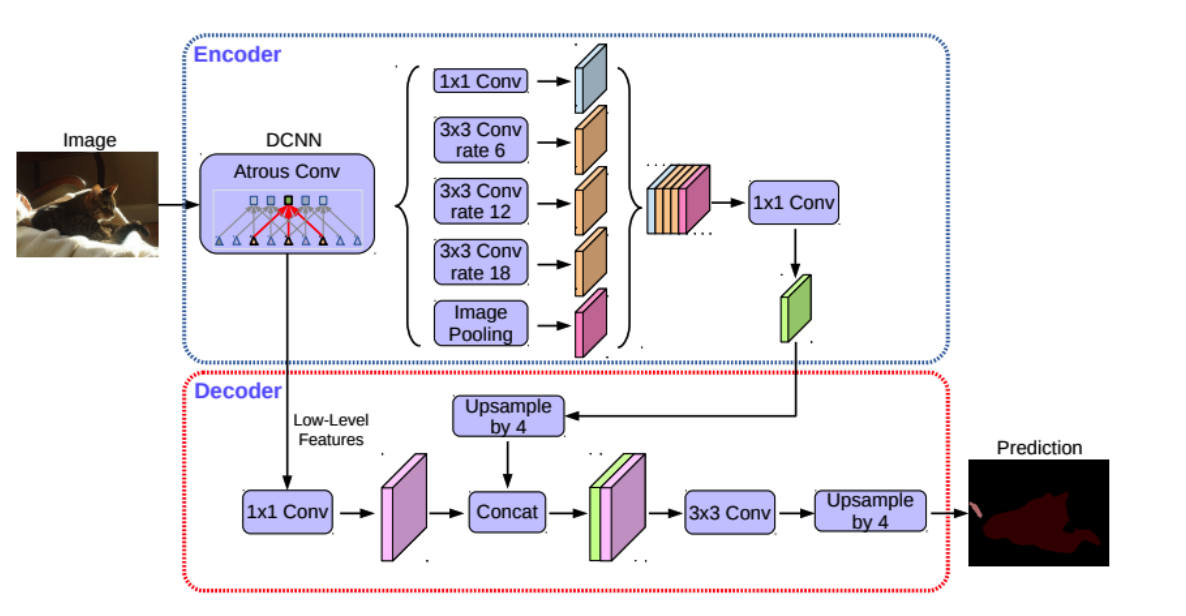
其中DCNN + Atrous Conv使用修改过的Xception 骨干网络来实现对浅层、中层、深层特征的提取,其具体的内部构造如下图:
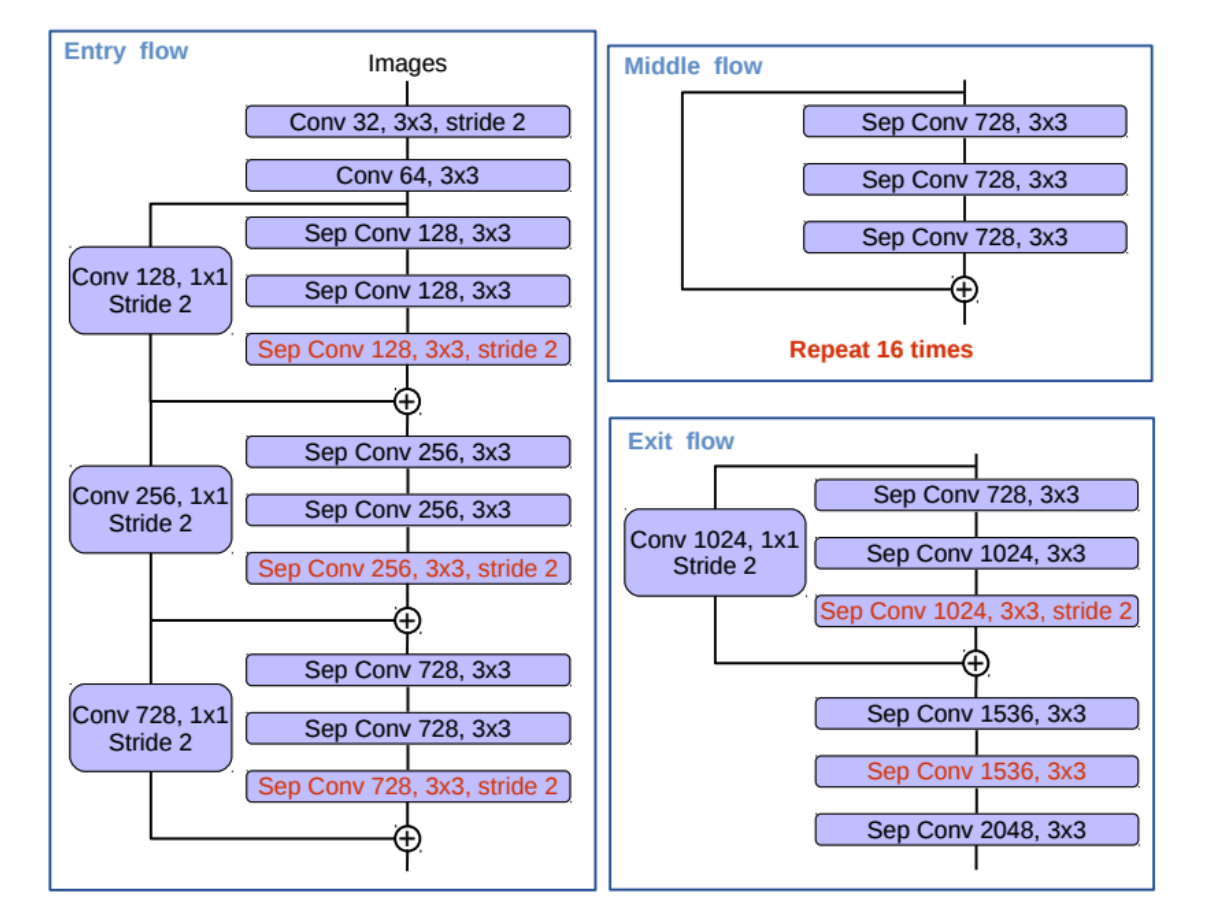
参考文章
DenseASPP
简介
DenseASPP将DeepLab系列中的ASPP和DenseNet中的密集连接相结合,构成了DenseASPP。新的模块具有更大的接收野和更密集的采样点,使得特征表示更加丰富和全面,在语义分割等任务中能显著提高分割精度 。
ASPP
扩张卷积用于解决特征图分辨率和接收野之间的矛盾,ASPP利用了多尺度信息进一步强化了分割效果。DeepLabv2中的ASPP模块如下:
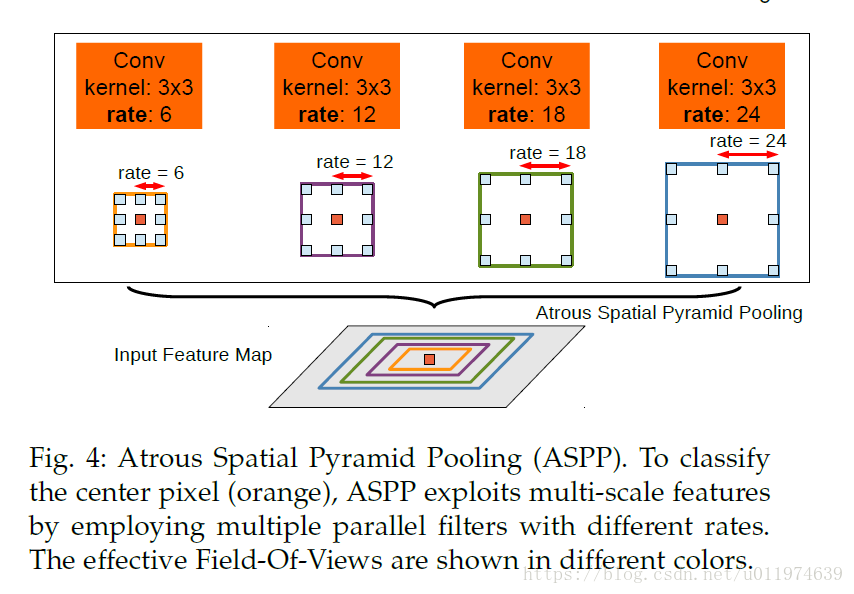
DenseNet
在DenseNet中用密集连接获得更佳的性能。
- 密集连接:梯度在反向传播时拥有更多路径到达浅层,缓解了深层网络的梯度消失问题。
- 特征重用:后面的层可以学习到前面层学习到的特征,从而加快网络的收敛。
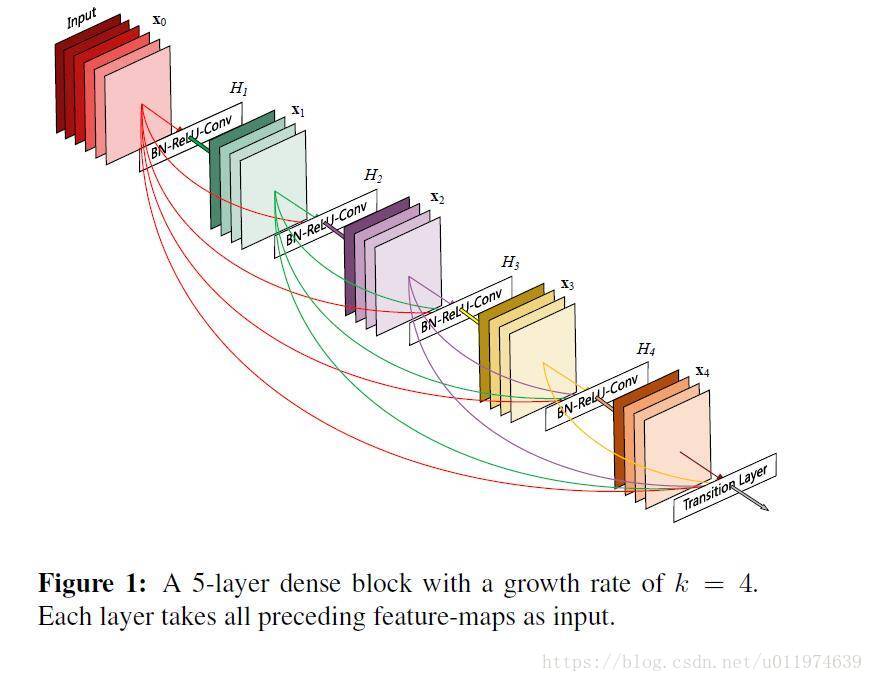
模型结构
DenseASPP中主要部分是中间的多层膨胀卷积密集连接部分,图b中给出DenseASPP的详细结构,首先通过backbone进行特征提取,然后在_DenseASPPBlock中经过五个不同膨胀卷积的率(3、6、12、18、24)的密集连接模块(_DenseASPPConv),其中每个密集连接模块的输入都是前面所有模块的融合结果(DenseNet利用)。
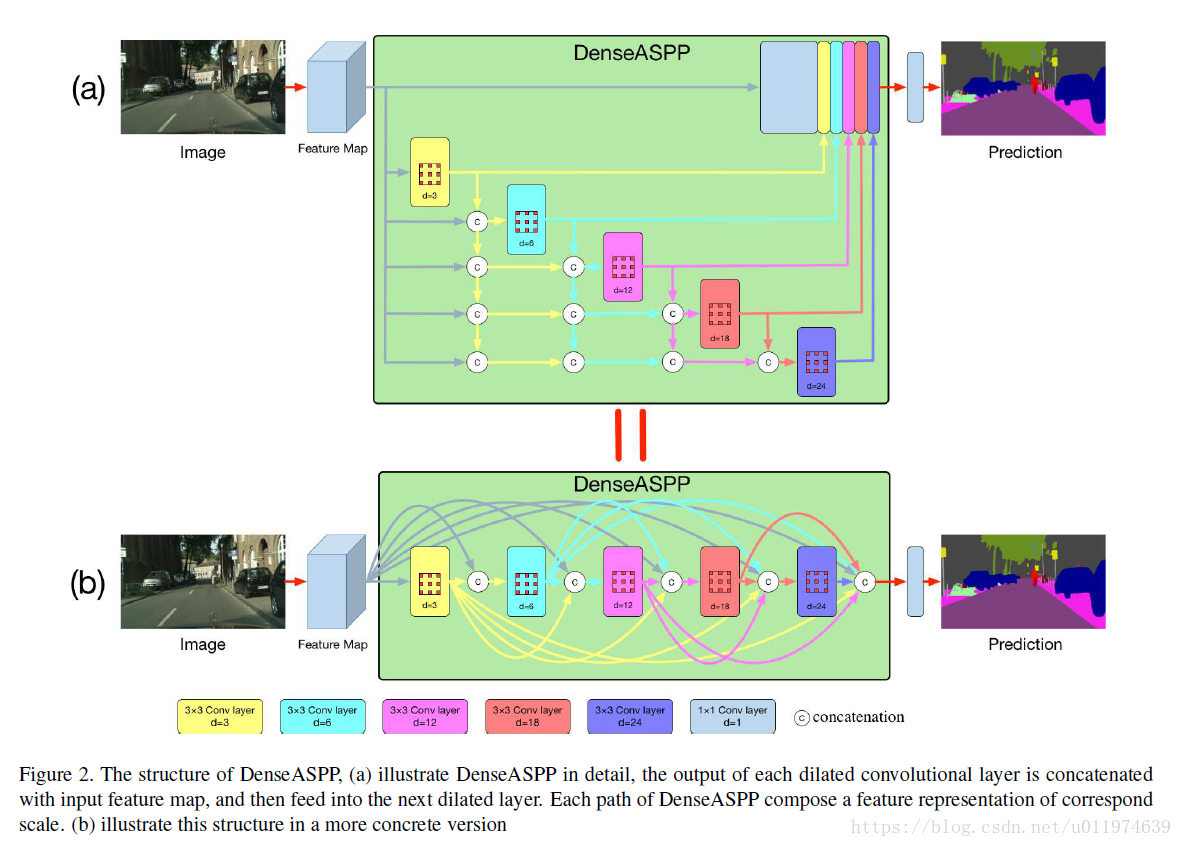
参考文章
EncNet
简介
EncNEt 是一种用于语义分割的网络结构,其核心思想是引入 **上下文编码模块(**Context Encoding Module) 来对上下文信息进行编码,并利用编码后的语义特征进行通道注意力调制,同时结合一个称为 SE-loss(Semantic Encoding Loss) 的辅助损失来增强对类别全局上下文的学习能力。
模型结构
EncNet 是基于主干网络(如 ResNet)提取特征后,再使用 编码模块 EncModule 提升特征的判别能力。
主要组成:
- Backbone CNN(如 ResNet):提取多层次特征(如 C2, C3, C4, C5)。
- _EncHead:包括:
- 主干顶层卷积处理
- 可选的 lateral 特征融合(中间层)
- 上下文编码模块
EncModule - 分类预测层
conv6
- EncModule:
- 编码层
Encoding - 通道注意力权重分支
- 可选的 SE-loss 分类分支
- 编码层
首先使用backbone对原始图片进行特征提取,若采用lateral则对C2 + C3浅层特征融合后,再和C5特征进行融合,否则直接使用C5特征,通过EncModule处理特征后,再通过conv6修改通道数,得到最终结果图。
EncModule中使用Encoding得到编码后特征,然后通过注意力分支得到通道权重gamma,然后使用对输入特征和通道权重相乘得到主输出放入到output中,若使用SE-loss分类分支,则通过selayer后添加到output中。
Encoding中
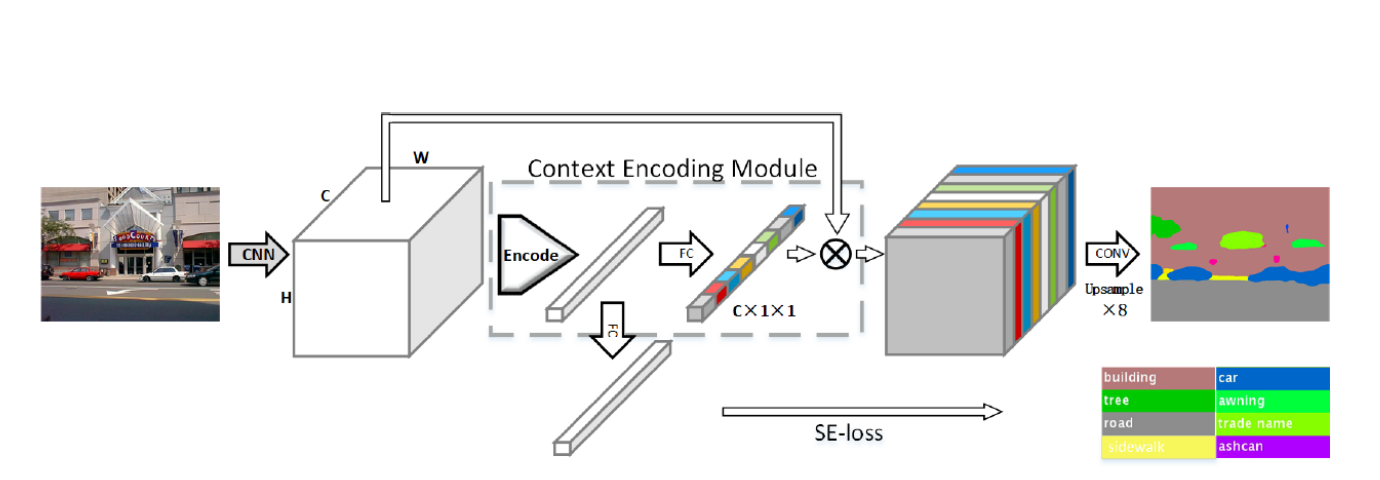
如图示:所提出的 EncNet 的概述。给定一幅输入图像,我们首先使用一个预训练的 CNN 来提取密集的卷积特征图。我们在其之上构建一个上下文编码模块(Context Encoding Module),该模块包含一个编码层(Encoding Layer),用于捕捉编码后的语义信息,并预测以这些编码语义为条件的缩放因子。这些学习到的因子有选择性地突出与类别相关的特征图(以颜色可视化展示)。在另一个分支中,我们采用语义编码损失(SE - loss)来规范训练过程,该损失使上下文编码模块能够预测场景中类别是否存在。最后,将上下文编码模块的表示输入到最后一个卷积层,以进行逐像素预测。(注释:FC 为全连接层,Conv 为卷积层,Encode 为编码层 [58],⊗为逐通道乘法。 )
参考文章
BiSeNet
简介
为了获得丰富的空间信息和相当大的感受野同时兼顾性能,使用新颖的双边分割网络(BiSeNet)。我们首先设计了一个小步幅的空间路径,以保留空间信息并产生高分辨率的特征。同时,采用快速下采样策略的上下文路径,以获得足够的感受野。在这两条路径的基础上,使用一个新的特征融合模块来有效地结合特征。
模型结构
对于空间路径,采用三个卷积归一化激活函数模块将特征图大小降低为原图的1/8;对于上下文路径,使用ARM(注意力提取模块)进行不同层特征进行特征提取融合,在上下文路径中会对每一层的特征进行提取强化,采用refines(特征细化模块)对特征进行进一步处理最终返回特征存入输出表给到BiSeNet主网络结构中。进行空间路径和上下文路径后使用FFM(FeatureFusion,特征融合模块),最后再修改通道数至类别数和上采样至原图大小,即可得到最终结果。
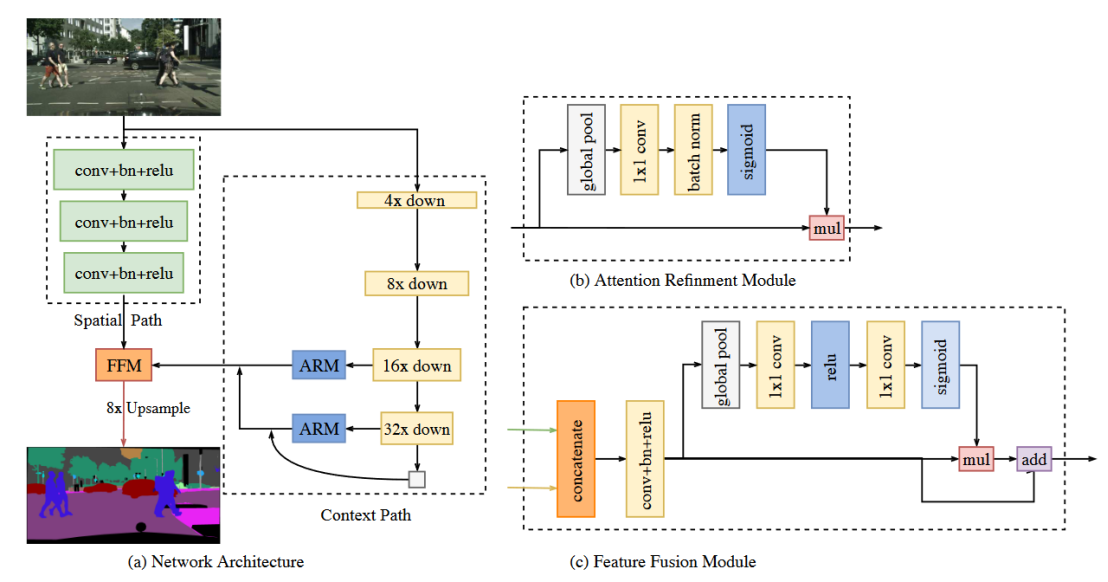
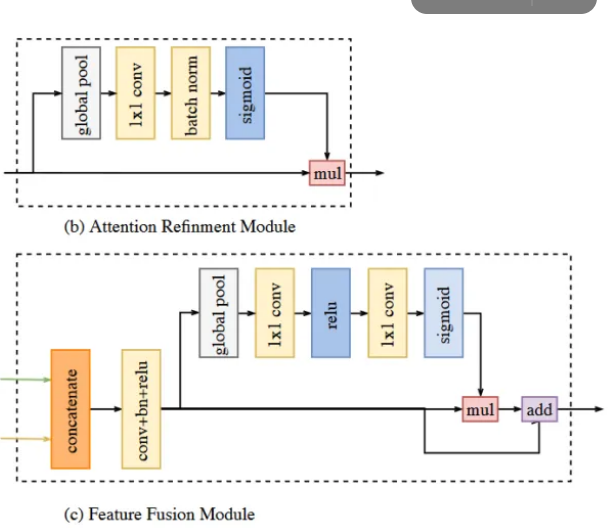
参考文章
PSANet
简介
为了放宽局部邻域的限制,提出了逐点空间注意力网络(PSANet)。特征图上的每个位置通过自适应学习的注意力掩码与所有其他位置相连。此外,还开启了双向信息传播用于场景解析。其他位置的信息可以帮助当前位置的预测。
模型结构
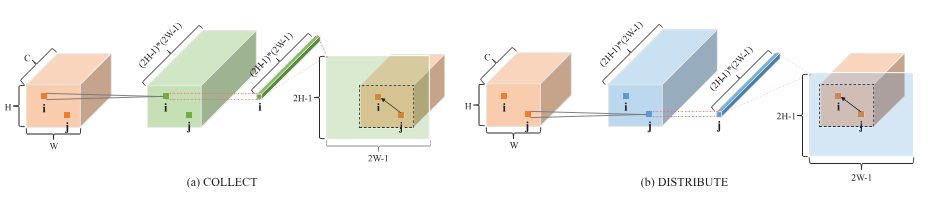
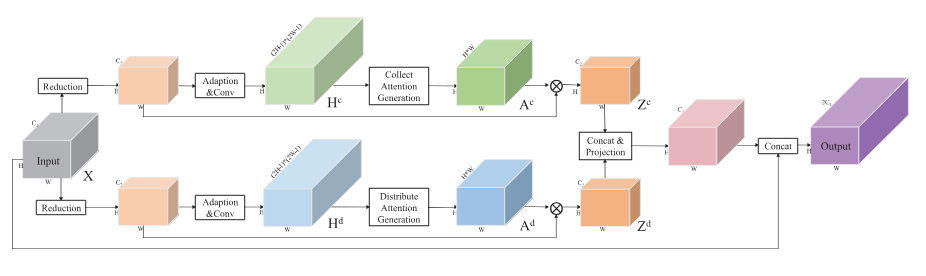
PSANet主要有_PSAHead(主分割头)和aux(辅助分支),首先使用backbone,这里采用resnet作为backbone来首先提取特征,辅助分支直接使用c3层输出作为辅助损失使用;_PSAHead(主分割头)先进行_PointwiseSpatialAttentio(点向空间注意力(PSA)模块)将Collect Attention(收集注意力分支) 和 Distribute Attention(分布注意力分支)两个分支进行注意力计算后进行融合返回。
关于_AttentionGeneration(注意力生成模块中),其步骤为降维 → 生成注意力权重 → 矩阵乘法聚合/分发特征。
参考文章
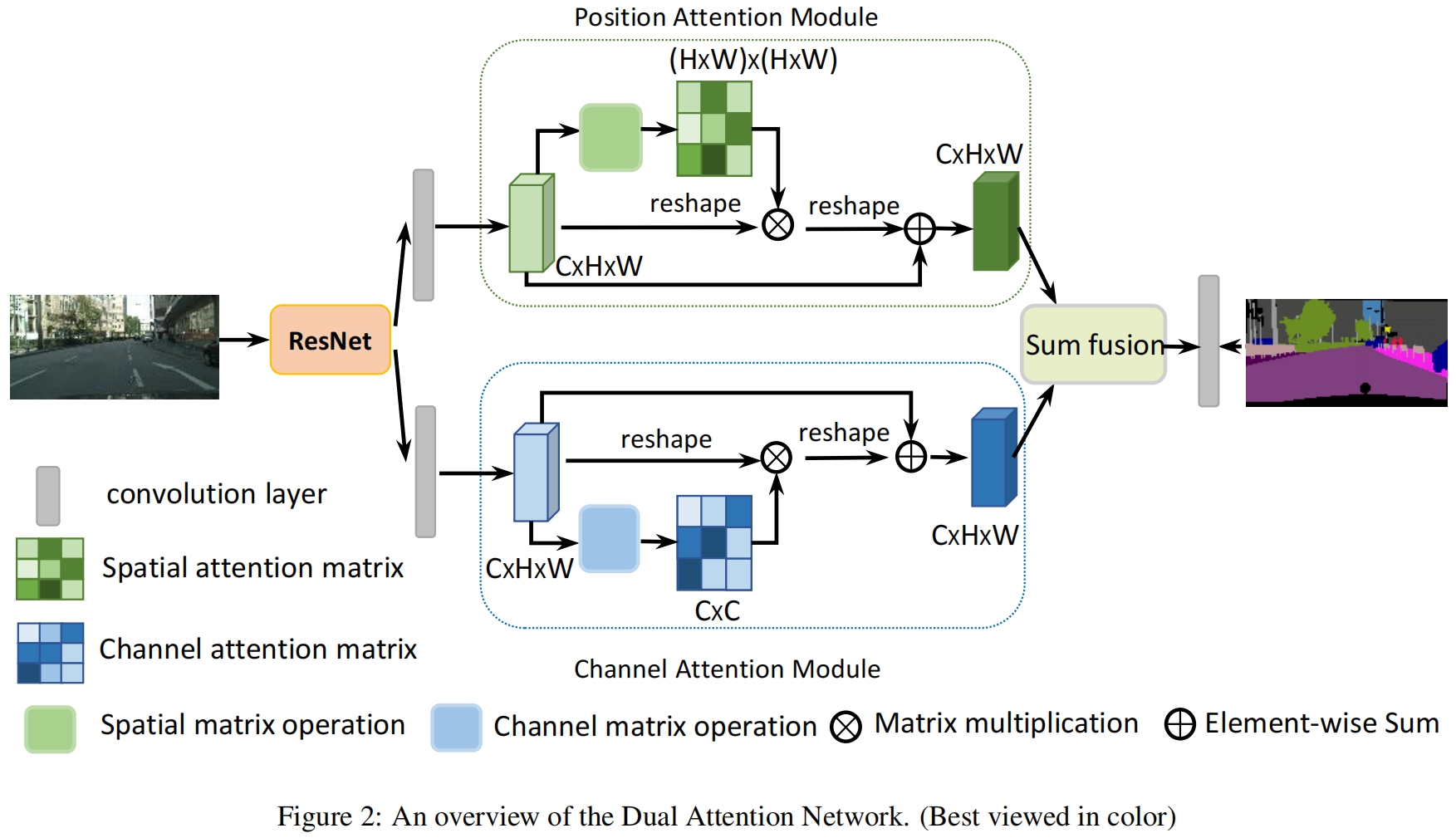
DANet
简介
DANet(双注意力网络),使用两个注意力模块:位置注意力模块和通道注意力模块,其中位置注意力模块用于学习特征的空间依赖关系,通道注意力模块用来构建通道依赖关系,通过构建丰富的上下文依赖关系,从而提升分割结果。
模型结构
网络结构首先通多backbone进行得到c4的特征图,然后将c4分别传给位置注意力模块和通道注意力模块进行依赖关系的构建。
在位置注意力模块中,其具体步骤:
(1)特征降维:输入特征图通过两个 1×1 卷积(<font style="color:rgba(0, 0, 0, 0.85);">conv_b</font>和<font style="color:rgba(0, 0, 0, 0.85);">conv_c</font>)降维,得到低维度特征(通道数为输入的 1/8),减少计算量。
(2)计算空间注意力矩阵:将降维后的特征展平为向量,通过矩阵乘法(<font style="color:rgba(0, 0, 0, 0.85);">bmm</font>)计算不同位置间的相似度,得到空间注意力矩阵(尺寸为<font style="color:rgba(0, 0, 0, 0.85);">H×W × H×W</font>,其中<font style="color:rgba(0, 0, 0, 0.85);">H、W</font>为特征图高宽),再通过 Softmax 归一化得到注意力权重。
(3)特征加权聚合:用注意力矩阵对原始特征(经<font style="color:rgba(0, 0, 0, 0.85);">conv_d</font>处理)进行加权求和,得到融合全局全局空间信息的特征。
在通道注意力模块中,其具体步骤:
(1)特征展平:将输入特征图展平为向量(尺寸为<font style="color:rgba(0, 0, 0, 0.85) !important;">C × H×W</font>,<font style="color:rgba(0, 0, 0, 0.85) !important;">C</font>为通道数),忽略空间维度,聚焦通道间关系。
(2)计算通道注意力矩阵:通过矩阵乘法(<font style="color:rgba(0, 0, 0, 0.85) !important;">bmm</font>)计算不同通道间的相似度,得到通道注意力矩阵(尺寸为<font style="color:rgba(0, 0, 0, 0.85) !important;">C × C</font>)。为增强差异,用矩阵最大值减去原矩阵,再通过 Softmax 归一化得到注意力权重。
(3)特征加权聚合:
用注意力矩阵对原始特征进行加权求和,得到融合通道依赖关系的特征。
参考文章
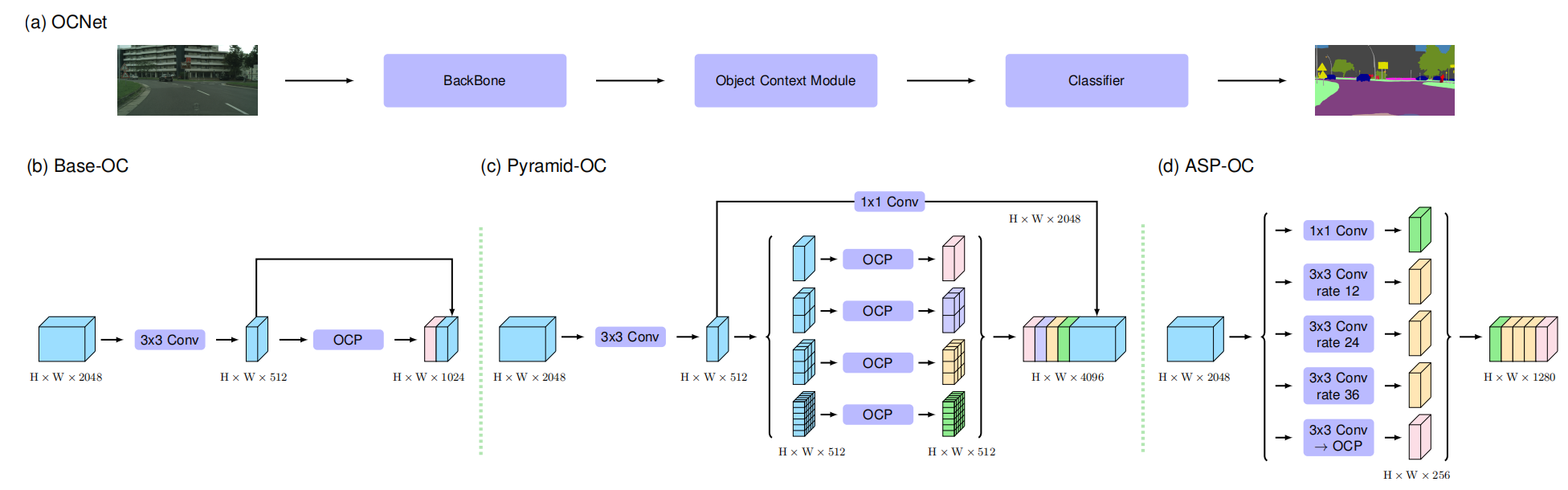
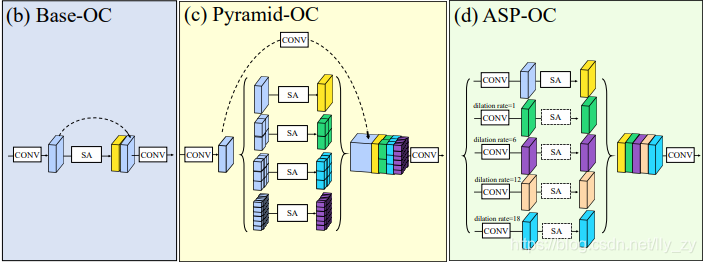
OCNet
简介
OCNet 核心是通过三种对象上下文模块(Base-OC/Pyramid-OC/ASP-OC)捕捉不同尺度的上下文依赖,结合骨干网络特征实现精准分割。根据需求来选择不同的中间上下文模块来处理特征。
模型结构
在OCNet中,首先先通过backbone来初步提取特征,然后选择中间的上下文模块进一步处理特征,最后修改通道数至数据集分类数量,再上采样至原图大小即可得到最终结果图。
对于中间三种处理模块特点如下:
- Base-OC :单尺度自注意力
- Pyramid-OC :多尺度金字塔分割特征图
- ASP-OC :结合空洞卷积(多尺度感受野)与上下文模块
参考文章
CGNet
简介
CGNet(Context Grided Network),主要用于移动设备需要,其核心为对CG block的使用,在不使用backbone的情况下,使用堆叠轻量级的CG block来实现对复杂上下文特征的提取。
模型结构
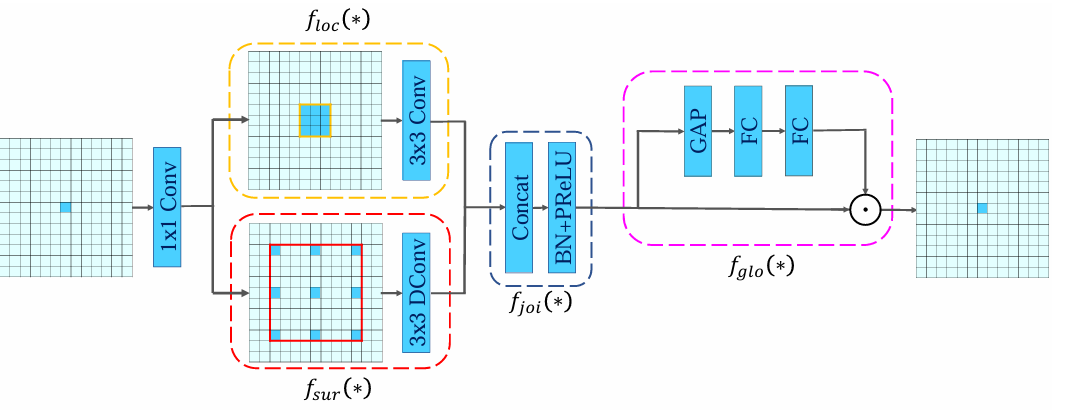
其中最终的部分为CG block,在上下文引导特征提取阶段和深层特征提取阶段都是由CG block组合而成的
CG block由4部分组成:
- 局部特征提取器 $ f_{loc}(*) $:以常规卷积实现
- 周围上下文特征提取器$ f_{sur}(*) $:以膨胀卷积实现
- 联合特征提取器$ f_{joi}(*) $:一个简单的拼接层,后面加上BN层和PReLU激活
- 全局特征提取器$ f_{glo}(*) $:全局池化层后面跟两个全连接层抽取特征,得到一个权重向量,以此向量指导联合特征融合
CGNet的主要模型结构如下,包括基础特征提取部分、上下文引导特征提取部分、深层特征提取部分这三部分构成,其中后两部都是由若干CG block构成,最后通过一个分割头得到最终的结果。
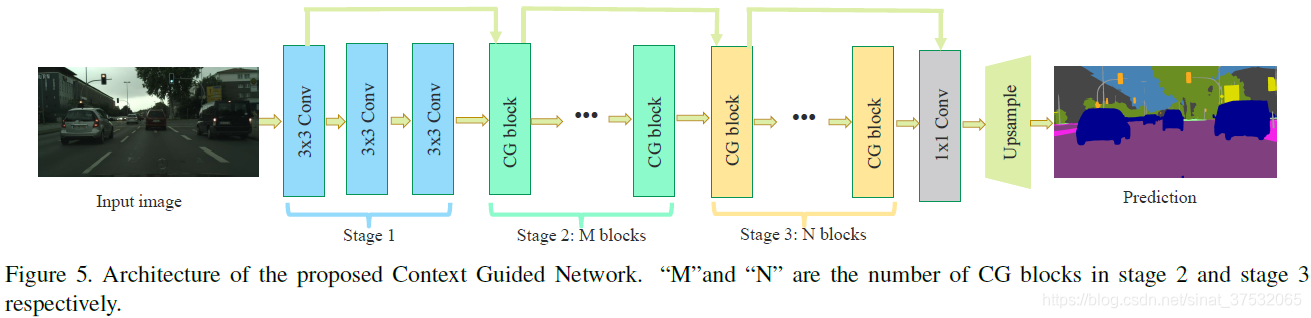
参考文章
ESPNetv2
简介
ESPNetv2提出在ESP模块的基础上进一步改进,提出了一种具有深度的可分离卷积EESP模块。
模型结构
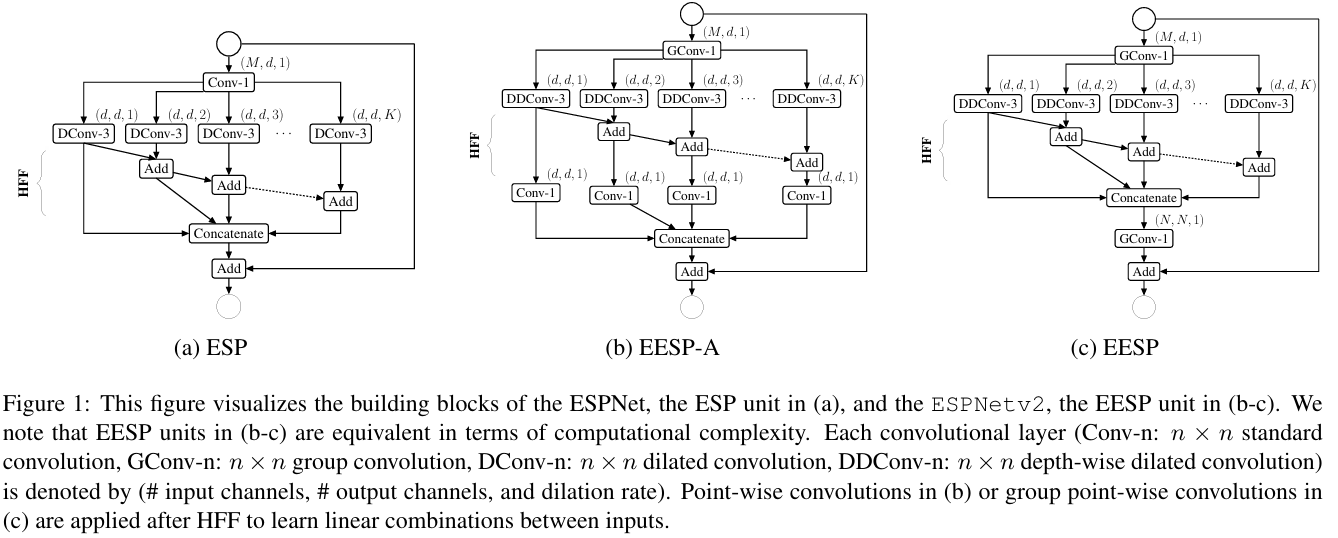
论文中提出EESP模块(Strided EESP with shortcut connection to an input image)模块,EESP模块在ESP模块的基础上做出了:
(1)跨步卷积替换深度扩张卷积
(2)添加平局池化操作
(3)用连接操作替换直接相加操作

ESPNetv2模型结构,首先通过EESP得到四个层级的特征,首先将将L4降维并上采样到L3尺度,然后将L3与刚才处理的L4进行PSP模块融合,再将结果进行投影、激活后,将merge_l3上采样到L2相同尺寸后,与L2融合,再将merge_l2上采样到L1尺寸,与L1融合,最终上采样到原图大小。
参考文章
DUNet(DUpsampling)
简介
DUNet是一种解码器-编码器模型,其重点在解码器,通过对数据的学习得到上采样权重,以此实现更高效的特征提取和分割精度,也降低了计算复杂度。
模型结构
首先通过backbone得到c1, c2, c3, c4,通过FeatureFused模块对c2、c3、c4进行特征融合,然后进一步卷积进行特征细化,最后通过数据依赖的上采样方法进行解码,最终得到结果特征图。
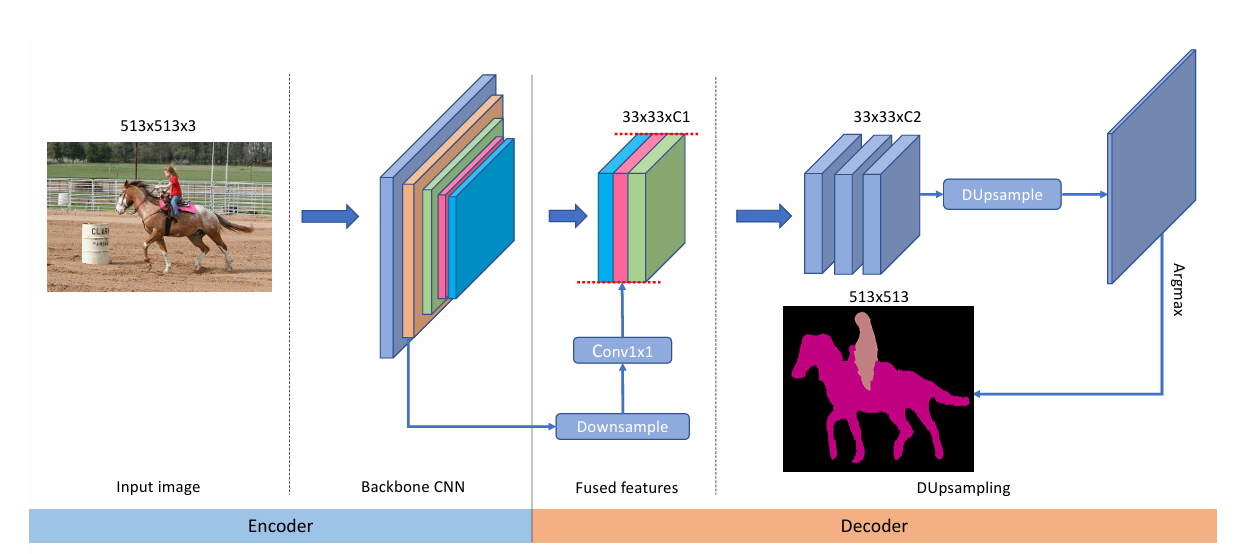
DUNet解码器上采样总结四步:
(1)权重生成
(2)维度重排和高度扩展
(3)维度重排和宽度扩展
(4)恢复最终维度
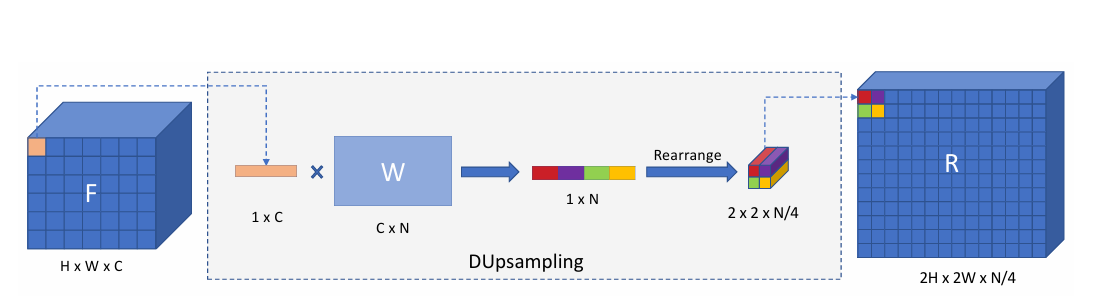
参考文章
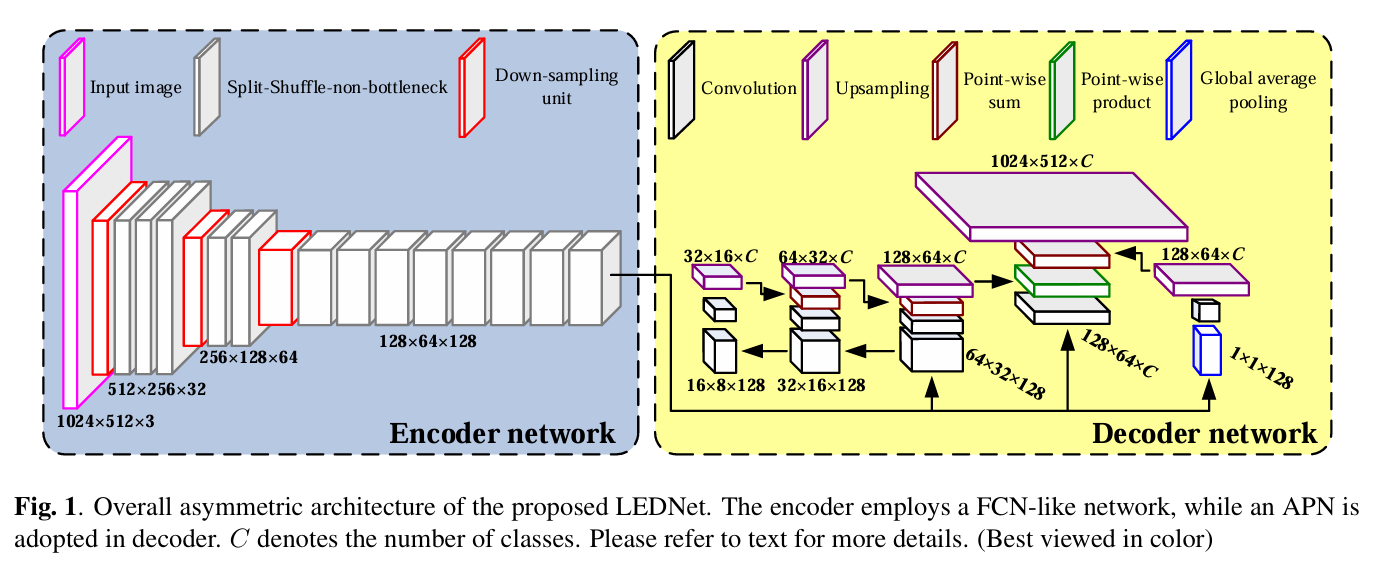
LEDNet
简介
LEDNet采用解码器-编码器结构,解码器部分使用ResNet作为backbone,并在残差块中使用通道分离和通道混洗,解码器部分使用注意金字塔网络(APN)。
模型结构
LEDNet并没有采用backbone,编码器部分由下采样模块和多个 SSnbt 模块组成,对图像进行多尺度特征提取,解码器部分使用注意力金字塔(APN),进行多尺度特征融合和分割预测。
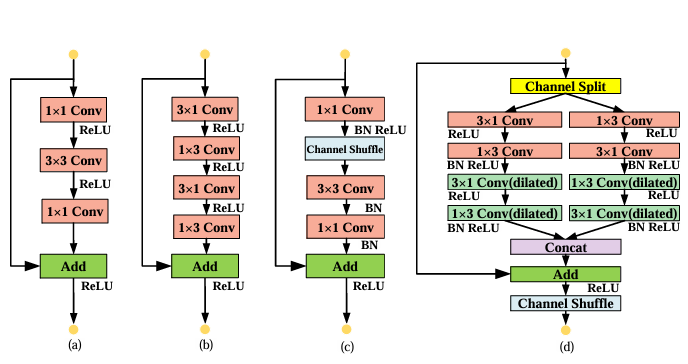
主要介绍的下面四种解码器模块:
(1)bottleneck(瓶颈模块):是经典的残差瓶颈结构,通过 1×1 卷积降维、3×3 卷积特征提取、1×1 卷积升维,再与 shortcut 相加
(2)****non - bottleneck - 1D(一维非瓶颈模块):采用 3×1 和 1×3 卷积的组合,
(3)ShuffleNet( shuffle 网络模块):引入了通道打乱(Channel Shuffle)操作
(4)SS - nbt 模块(本文提出的模块):先进行通道分割(Channel Split),然后分别通过不同的卷积分支(包括扩张卷积,用于增大感受野)处理,接着拼接(Concat)、残差相加(Add),最后进行通道打乱(Channel Shuffle),整合了通道分割、多分支卷积(含扩张卷积)、通道打乱等操作,以在轻量级的同时提取更丰富的特征

















 1854
1854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









