







接着上述内容继续更新,这篇开始讲解数学统计函数
八、数学统计函数
1、常用的数学统计函数
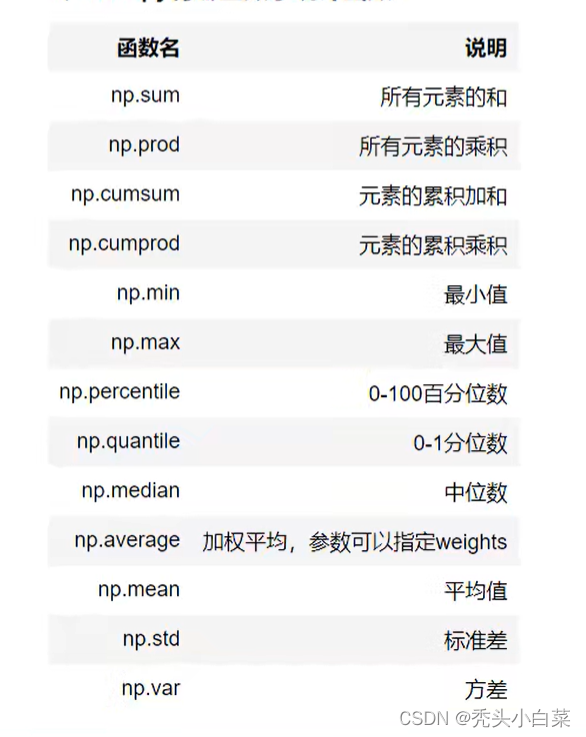
如下声明了一些函数并展示结果:
import pandas as pd
import numpy as np
arr= np.arange(12).reshape(3,4)
data = [['sum',np.sum(arr)],
['prod',np.prod(arr)],
['cumsum',np.cumsum(arr)],
['cumprod',np.cumprod(arr)],
['min',np.min(arr)],
['max',np.max(arr)],
['percentile',np.percentile(arr,[25,50,75])],
['quantile',np.quantile(arr,[0.25,0.5,0.75])],
['median',np.median(arr)],
['mean',np.mean(arr)],
['std',np.std(arr)],
['var',np.var(arr)]]
df = pd.DataFrame(data, columns=[ 'type','result'])
df为了更直观的显示结果,我们用表格进行展示:
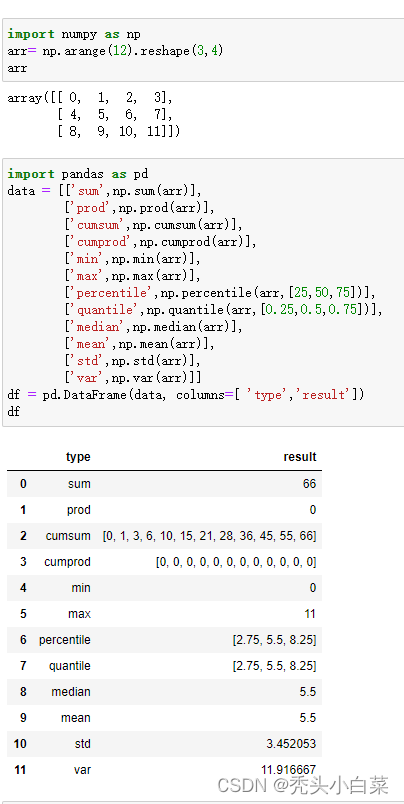
扩展:加权平均函数averge,weight就是加权系数,指的是每个数组的系数
2、如何根据不同的axis(轴)进行计算
以上函数,都有一个参数叫做axis用于指定计算轴为行还是列,如果不指定,那么会计算所有元素的结果
对于低维数组来说(例如二维数组)axis=0代表行、axis=1代表列
对于sum/mean/media等聚合函数:
理解1:axis=0代表把行消解掉,跨行计算(行索引),axis=1代表把列消解掉,跨列计算(列索引)
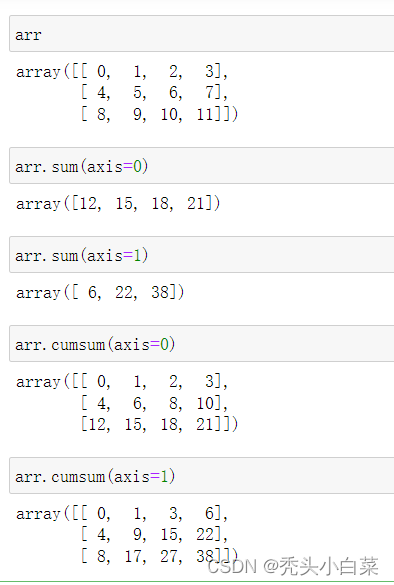
但是对于高维数组来说(例如三维或更多维度),asix相当于是立体的面,x,y,z,也有了axis=0,1,2...
多维数组不是很好理解,这涉及到了一些数学方面的内容,axis就代表了[ ]的维度,这样计算的话可能需要深入理解,一下两位博主有了很好的总结,大家可以进行参考:
Python中axis=0与axis=1指的方向有什么不同详解_python_脚本之家
Python的numpy中axis=0、axis=1、axis=2解释-CSDN博客
简单来说,对于多维数组来说,axis=0代表第一维度,axis=1代表第二维度,axis=2代表第三维度,我就不具体举例子了,平时项目没用到这么深 ,有需要的话我回来后续更新
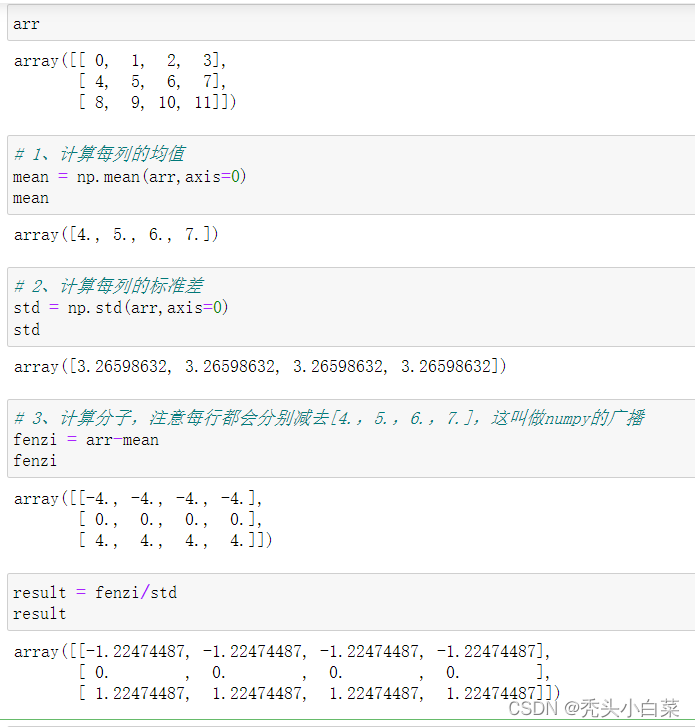
3、实例:机器学习将数据进行标准化
arr如果对应到现实世界的一种解释:
行:每行对应一个样本数据
列:每列代表样本的一个特征
数据标准化(就是统一相同的维度,就像秦始皇统一度量衡的道理,同种类型的数据进行比较或计算):
对于机器学习、神经网络来说,不同列的量纲应该相同,训练收敛的更快; 比如商品的价格是0到100元、销量是1万到10万个,这俩数字没有可比性,因此需要先都做标准化; 不同列代表不同的特征,因此需要axis=0做计算
标准化一般使用A=(A-mean(A,axis=0))/std(A,axis=0)公式进行
# 1、计算每列的均值
mean = np.mean(arr,axis=0)
mean
# 2、计算每列的标准差
std = np.std(arr,axis=0)
std
# 3、计算分子,注意每行都会分别减去[4.,5.,6.,7.],这叫做numpy的广播
fenzi = arr-mean
fenzi
result = fenzi/std
result结果如下:
扩展,numpy的广播broadcast
在Python中,NumPy的广播(broadcasting)是一种机制,用于在算术运算中处理不同形状的数组。当进行运算时,NumPy会自动扩展较小数组,以便它们的形状相匹配。这种扩展过程不会修改原始数组,只会在计算过程中临时展开它们。
广播的规则简单来说有以下几点:
-
如果两个数组在任何维度上都没有相同的大小,则其中一个数组会在最小的维度上广播。
-
如果一个数组的形状是1的,那么它可以被广播成任何形状。
-
如果一个数组的形状在某个维度上是1,它可以在这个维度上和任何其他维度的数组进行广播操作。
-
当两个数组在对应维度上的大小有一个是1,或者其中一个数组在某个维度上没有存在时,可以进行广播。
下面是一个使用NumPy广播的例子:
import numpy as np
# 创建两个形状不同的数组
a = np.array([[1, 2, 3], [4, 5, 6]]) # 形状为 (2, 3)
b = np.array([1, 2, 3]) # 形状为 (3,)
# 广播机制会使得 b 在第一维上广播,与 a 的形状相匹配
result = a + b # 等价于 a + b[:, np.newaxis]
print(result)输出结果将会是:
[[2 4 6]
[5 7 9]]
在这个例子中,数组 b 被广播以匹配数组 a 的形状,b 在第一维上广播成形状为 (1, 3),也就是复制成[[1, 2, 3],[1, 2, 3]],然后与 a 进行加法运算。有兴趣的小伙伴可以自己搜索深入了解一下。
九、一些关于Numpy常用的简单示例
1、Numpy增加维度
例如我们收到的是一维数组[1,2,3],但是我们需要使用二维数组作为数据源绑定,例如在机器学习中,多增加一个维度表示会多一个样本数据,如何在不改变数据的情况下升级成[[1,2,3]]的形式呢?有如下三种方法:
(1)np.newaxis:关键字,使用索引的语法给数组添加维度(np.newaxis 其实就是 None,也可以用None来代替)
# 首先声明一个一维数组
import numpy as np
arr = np.arange(5)
#在行的基础上添加维度
arr[np.newaxis,:] # 结果 array([[0, 1, 2, 3, 4]]) shape (1, 5)
#在列的基础上添加维度
arr[:,np.newaxis] # 结果 array([[0],[1],[2],[3],[4]]) shape(5, 1)
(2)np.expand_dims(arr,axis):方法,和np.newaxis实现一样的功能给arr在axis位置添加维度

(3)np.reshape(a,newshape):方法,给一个维度设置为1完成升维,newshape是一个数字时就是一维,是元组时就代表多维。
# newshape是一个数字时就是一维
np.reshape(arr,5) # 结果:array([0, 1, 2, 3, 4])
# 在行的基础上添加维度 ,一行5列
np.reshape(arr,(1,5)) 结果:array([[0, 1, 2, 3, 4]])
# 但是很多时候我们不能确定一维数组里面有多少数据的时候,就可以用(1,-1)来表示
np.reshape(arr,(1,-1)) 结果:array([[0, 1, 2, 3, 4]])
# 在列的基础上添加维度 ,一列5行
np.reshape(arr,(-1,1)) # 结果 array([[0],[1],[2],[3],[4]]) shape(5, 1)
同时有升维也就意味着有降维,我们可以用flatten函数、ravel函数、squeeze函数、reshape来实现降维
使用.flatten()方法:这个方法会返回一个新的数组,其中包含原始数组的元素,但是已经被扁平化(降低到1维)。
import numpy as np
# 创建一个二维数组
array = np.array([[1, 2, 3], [4, 5, 6]])
# 使用flatten方法降维
flattened_array = array.flatten()
print(flattened_array) # 输出: [1 2 3 4 5 6]
使用.ravel()方法:这个方法也会返回扁平化后的数组,但是如果原数组是非连续的,.ravel()会进行复制,而.flatten()则会首先试图返回视图。
import numpy as np
# 创建一个二维数组
array = np.array([[1, 2, 3], [4, 5, 6]])
# 使用ravel方法降维
raveled_array = array.ravel()
print(raveled_array) # 输出: [1 2 3 4 5 6]
使用reshape方法:这个方法可以返回一个具有新形状的数组,但是原始数组的元素个数必须保持不变。
import numpy as np
# 创建一个二维数组
array = np.array([[1, 2, 3], [4, 5, 6]])
# 使用reshape方法降维
reshaped_array = array.reshape(-1)
print(reshaped_array) # 输出: [1 2 3 4 5 6]
使用squeeze方法:这个方法可以删除数组形状中单维度为1的轴。
import numpy as np
# 创建一个二维数组,其中一个维度大小为1
array = np.array([[1], [2], [3]])
# 使用squeeze方法降维
squeezed_array = array.squeeze()
print(squeezed_array) # 输出: [1 2 3]
使用np.ndarray.item方法:如果数组只有一个元素,你可以使用item()方法来获取这个元素的值。
import numpy as np
# 创建一个一维数组
array = np.array([1])
# 使用item方法获取单个元素
item = array.item()
print(item) # 输出: 1
选择哪种方法取决于你的具体需求和数组的状态。例如,如果你想要修改原始数组,那么.flatten()将不适用,因为它返回的是原始数据的副本。而如果你不需要修改原始数组,那么.flatten()或.ravel()将更为合适。下面这个博主总结的比较好,大家可以参考一下:
[Python] numpy - 如何对数组进行降维或者升维_numpy 降维-CSDN博客
2、Numpy中非常有用重要的数据合并操作
我们在机器学习的过程中可能会遇到添加数组的过程,例如在原有的基础上添加行或者添加列,添加完之后我们就用到了合并的功能。
以下操作均可以实现数组合并:
(1)np.concatenate(array_list,axis=0/1):沿着指定axis进行数组的合并
(2)np.vstack或者np.row_stack(array_list):垂直vertically、按行row wise进行数据合并 (3)np.hstack或者np.column_stack(array_list):水平horizontally、按列column wise进行数据合并
下面从两方面分别介绍函数:
(1)添加新的多行(注意此时要合并的两个数组列的数量需要保持一致)
import numpy as np
# 首先声明两个二维数组
a = np.arange(6).reshape(2,3)
b = np.random.randint(10,20,size = (4,3))
# concatenate 方法实现行合并
np.concatenate([a,b])
# vstack 方法实现行合并
np.vstack([a,b])
# row_stack 方法事项行合并
np.row_stack([a,b])(2)添加新的多列(此时两个要合并的数组的行数要保持一致)
import numpy as np
# 首先声明两个新的二维数组
a = np.arange(9).reshape(3,3)
b = np.random.randint(10,20,size = (3,2))
# concatenate 方法实现列合并
np.concatenate([a,b],axis=1)
# hstack 方法实现列合并
np.hstack([a,b])
# column_stack 方法事项列合并
np.column_stack([a,b])好了,Numpy的基础我们就先讲到这里了,后续会在有时间的情况下继续总结Panada和Matplotlib,大家可以收藏关注一下。















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









