






第1章 绪论
1.1 引言
机器学习正是这样一门学科,它致力于研究如何通过计算的手段,利用经验来改善系统自身的性能,在计算机系统中,“经验”通常以“数据”形式存在,因此,机器学习所研究的主要内容,是关于在计算机上从数据中产生“模型”(model)的算法,即“学习算法”(learning algorithm)。
1.2 基本术语
整个数据集称一个“样本”,因为它可看作对样本空间的一个采样;通过上下文可判断出“样本”是指单个示例还是数据集。
从数据中学得模型的过程称为“学习”(learning)或“训练”(training),这个过程通过执行某个学习算法来完成。
若我们欲预测的是离散值,例如“好瓜”“坏瓜”,此类学习任务称为“分类”(classification)。
若欲预测的是连续值,例如西瓜成熟度0.95、0.37,此类学习任务称为“回归”(regression)。
根据训练数据是否拥有标记信息,学习任务可大致划分为两大类:“监督学习”(supervised learning)和“无监督学习”(unsupervised learning)。
泛化能力:学得模型适用于新样本的能力,称为“泛化”(generalization)能力。
1.3 假设空间
归纳(induction)与演绎(deduction)是科学推理的两大基本手段。
归纳学习有狭义与广义之分,广义的归纳学习大体相当于从样例中学习,而狭义的归纳学习则要求从训练数据中学得概念(concept),因此亦称为“概念学习”或“概念形成”。
概念学习中最基本的是布尔概念学习,即对“是”“不是”这样的可表示为0/1布尔值的目标概念的学习 。
1.4 归纳偏好
机器学习算法在学习过程中对某种类型假设的偏好,称为“归纳偏好”(inductivebias),或简称为“偏好。归纳偏好可看作学习算法自身在一个可能很庞大的假设空间中对假设进行选择的启发式或“价值观"。
这部分涉及概率的知识
没有免费午餐定理:没有免费午餐定理_百度百科
NFL定理最重要的寓意,是让我们清楚地认识到,脱离具体问题,空泛地谈论“什么学习算法更好”毫无意义,因为若考虑所有潜在的问题,则所有学习算法都一样好 。
1.5 发展历程
1965年,Feigenbaum主持研制了世界上第一个专家系统DENDRAL。机器学习是人工智能(artificial intelligence)研究发展到一定阶段的必然产物
从二十世纪七十年代中期开始,人工智能研究进入了“知识期。在这一时期,大量专家系统问世,在很多应用领域取得了大量成果。
在二十世纪八十年代,“从样例中学习”的一大主流是符号主义学习,其代表包括决策树(decisiontree)和基于逻辑的学习。
二十世纪九十年代中期之前,“从样例中学习”的另一主流技术是基于神经网络的连接主义学习。
二十世纪九十年代中期,“统计学习”(statistical learning)闪亮登场并迅速占据主流舞台,代表性技术是支持向量机(Support Vector Machine,简称SVM)以及更一般的“核方法”(kernel methods)。
二十一世纪初,连接主义学习又卷土重来,掀起了以“深度学习”为名的热潮。所谓深度学习,狭义地说就是“很多层”的神经网络。
1.6 应用现状
在计算机科学的诸多分支学科领域中,无论是多媒体、图形学,还是网络通信、软件工程,乃至体系结构、芯片设计,都能找到机器学习技术的身影,尤其是在计算机视觉、自然语言处理等“计算机应用技术”领域,机器学习已成为最重要的技术进步源泉之一。
1.7 阅读材料
WEKA是著名的免费机器学习算法程序库,由新西兰Waikato大学研究人员基于JAVA开发:http://www.cs.waikato.ac.nz/ml/weka/。
第2章 模型评估与选择
2.1 经验误差与过拟合
误差:我们把学习器的实际预测输出与样本的真实输出之间的差异称为“误差”(error)
经验误差:学习器在训练集上的误差称为“训练误差”(training error)或“经验误差”(empirical error)
泛化误差:在新样本上的误差称为“泛化误差”(generalization error)
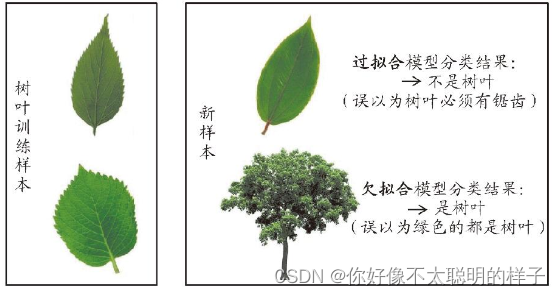
过拟合:当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降。这种现象在机器学习中称为“过拟合”(overfitting)。
欠拟合:指对训练样本的一般性质尚未学好。
如下图为两者的区别
2.2 评估方法
通过对样本集进行适当的处理,从中产生出训练集S和测试集 T。
2.2.1 留出法
留出法”(hold-out)直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即D=S∪T,S∩T=空。
在使用留出法时,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
2.2.2 交叉验证法
亦称“k倍交叉验证”
①将数据集D划分为k个大小相似的互斥子集,即D=D1∪D2∪...∪Dk,Di∩Dj=空(i≠j),每个子集都要确保数据分布的一致性,从D中通过分层采样得到。
分层采样是分别对每个类别进行随机采样。分层采样往往是为保证在采样空间或类型选取上的均匀性及代表性所采用的方法。分层的依据可因精度评价的目标而异,常用的分层有地理区、自然生态区、行政区域或分类后的类别等。
②然后,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集。
③进行k次训练和测试,最终返回的是这k个测试结果的均值。
交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值,为强调这一点,通常把交叉验证法称为“k折交叉验证”(k-fold cross validation)。
特例(留一法)假定数据集D中包含m个样本,若令k=m,则得到了交叉验证法的一个特例:留一法(Leave-One-Out,简称LOO)。
留一法使用的训练集与初始数据集相比只少了一个样本,这就使得在绝大多数情况下,留一法中被实际评估的模型与期望评估的用D训练出的模型很相似。
2.2.3 自助法(bootstrapping)
自助采样亦称“可重复采样”或“有放回采样。
2.3 性能度量
2.3.1 错误率与精度
错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









