







1.GroupBy机制
groupby分为三个步骤: 拆分-应用-合并
- 拆分操作是在特定轴向上进行的,dataframe可以在 行方向(axis=0)/ 列方向 上分组
- 分组后会产生groupby对象,我们就可以将函数应用在groupby对象的各个组中,产生新的值
- 最终,所有函数的应用结果会合并为一个结果对象
1.1 数据分组
1.1.1 遍历各个分组(了解)
groupby对象支持迭代,会生成一个包含组名和数据块的2维元组序列
import pandas as pd
road = "E:\python 资料\孙兴华 数据分析教程\Pandas课件\课件\pandas教程\课件026\分组聚合.xlsx"
data = pd.read_excel(road)
# 遍历 城市 和 区 这两列
for (i,j),group in data.groupby(["城市","区"]): #城市列赋值给i,区列赋值给j
print((i,j))
print(group)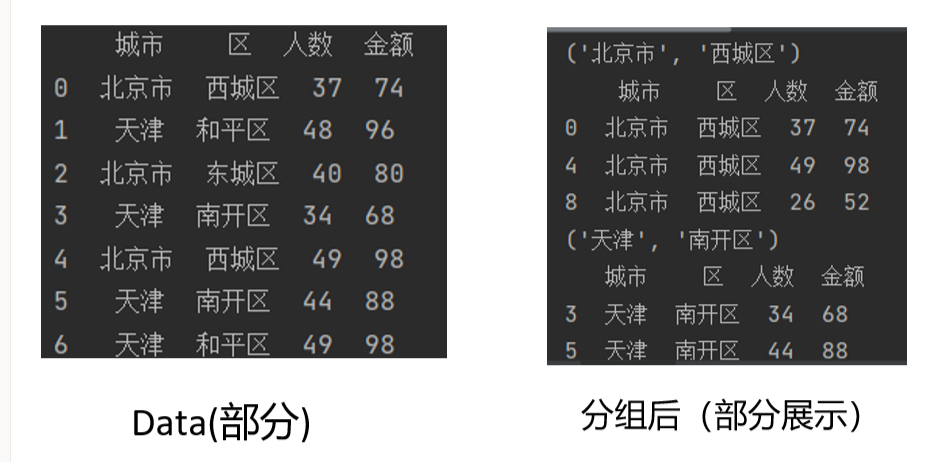
1.1.2 选择一列或所有列的子集
对于由DataFrame产生的GroupBy对象,如果用单个列名或一组列名对其进行索引,就能实现选取部分列进行聚合的目的
- 语法:df.groupby([ df列名1,df列名2 ])[ [ gb列名 ] ] . 聚合函数
参数说明:
黄色部分:dataframe的列名,指要根据哪些列分组;也可传入一个判断语句
如:data.序号%2 == 0 一一> 筛选出偶数序号
红色部分:产生的groupby对象的列名,指要对哪些列去做聚合
蓝色部分:聚合的方式
as_index:是否用分组键作为索引(默认True)
juhe = data.groupby(['城市','区'])[['人数','金额']].sum()
print(juhe)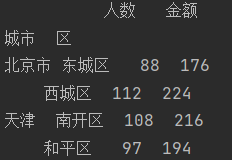
1.1.3 使用字典和series分组
如果我们的分组信息,是以某种对应关系的方式给定,那么我们就可以利用字典来进行分组
import pandas as pd
road= "E:\python 资料\孙兴华 数据分析教程\Pandas课件\课件\pandas教程\课件026\分组聚合2.xlsx"
data = pd.read_excel(road,index_col='店号') #指定店名这一列,用作行名
print(data)
Correspondence = {'1月':'一季度','2月':'一季度','3月':'一季度','4月':'二季度'} #根据对应关系分组
data2 = data.groupby(Correspondence,axis=1) # 传入对应关系,按行分组
print(data2.sum()) # 聚合
1.1.4 根据函数分组(了解)
我们要对哪个列进行分组,就把哪个列设为索引,然后直接在groupby中传入函数即可
- 案例:按城市的名字字数进行分组聚合
import pandas as pd
road = "E:\python 资料\孙兴华 数据分析教程\Pandas课件\课件\pandas教程\课件026\分组聚合.xlsx"
data = pd.read_excel(road,index_col='城市') #对哪个列进行分组,就把他设成索引
data2 = data.groupby(len)[['人数','金额']].sum()
print(data2) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









