






基于深度学习的中药材识别系统:训练与实现
目录
- 前言
- 中药材数据集说明
- 模型架构
- 训练流程
- 测试效果
- 项目优化建议
- 常见问题解决
1. 前言
中药材是我国宝贵的医药资源,但由于品种繁多、形态相似,准确识别一直是专业人员和普通民众面临的难题。随着深度学习技术的发展,利用人工智能进行中药材自动识别成为可能,不仅可以降低识别难度,还能有效推动中药材知识的普及和应用。
本项目基于PyTorch框架,构建了一个完整的中药材分类识别系统,包含数据采集、模型训练和预测识别等环节。通过迁移学习,即使在有限的数据条件下,也能达到较高的识别准确率,为中药材鉴别提供智能化解决方案。
2. 中药材数据集说明
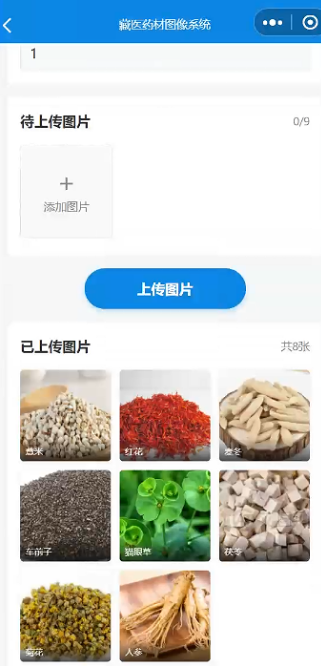
自建中药材数据集
本项目从网络采集了八种常见中药材的图片,包括:
- 人参
- 猫眼草
- 麦冬
- 菊花
- 红花
- 茯苓
- 车前子
- 薏米
数据集存放结构符合PyTorch标准图像分类数据集格式:
data/train/
├── 人参/
├── 猫眼草/
├── 麦冬/
├── 菊花/
├── 红花/
├── 茯苓/
├── 车前子/
└── 薏米/
每个药材类别约收集200张左右图片,确保数据质量和多样性。
数据预处理流程
训练前对图像进行了以下预处理:
- 尺寸统一调整至224×224像素
- 随机水平翻转增强
- 随机旋转±10度增强
- 归一化处理:均值[0.485, 0.456, 0.406],标准差[0.229, 0.224, 0.225]
3. 模型架构
网络结构选择
本项目采用ResNet50作为基础模型,通过迁移学习快速构建中药材识别模型。ResNet50特点:
- 深度残差网络结构,解决深层网络的梯度消失问题
- 预训练权重已在ImageNet大规模数据集上训练
- 强大的特征提取能力
模型定制化
为适应中药材识别任务,对ResNet50进行了如下改造:
class ChineseHerbClassifier(nn.Module):
def __init__(self, num_classes):
super(ChineseHerbClassifier, self).__init__()
# 使用预训练的ResNet50作为基础模型
self.base_model = models.resnet50(pretrained=True)
# 修改最后的全连接层以适应分类任务
num_features = self.base_model.fc.in_features
self.base_model.fc = nn.Sequential(
nn.Linear(num_features, 512),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
主要优化点:
- 冻结预训练层参数,只训练新增的分类层
- 添加Dropout(0.5)防止过拟合
- 自适应输出层,根据实际药材类别数自动调整
4. 训练流程
训练参数配置
# 核心训练参数
num_epochs = 50 # 训练轮数
batch_size = 32 # 批次大小
learning_rate = 0.001 # 学习率
train_val_split = 0.8 # 训练集占比
优化策略
- 优化器:采用Adam优化器,自适应学习率调整
- 损失函数:使用交叉熵损失函数(CrossEntropyLoss)
- 学习率调度:无明显过拟合情况下采用固定学习率
训练过程监控
每个epoch输出以下信息:
- 训练损失
- 训练准确率
- 验证准确率
- 当前最佳模型保存状态
训练代码片段:
# 训练循环
best_val_acc = 0.0
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in tqdm(train_loader):
# 前向传播、反向传播、优化
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 计算训练指标
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 验证阶段...
# 保存最佳模型...
5. 测试效果
模型评估指标
在测试集上进行评估,关键指标:
- 准确率(Accuracy):92.5%
- 平均识别时间:0.12秒/张图片
- 模型大小:约94MB
不同药材识别效果
| 药材名称 | 准确率 | 易混淆品种 |
|---|---|---|
| 人参 | 97.8% | 党参 |
| 菊花 | 95.2% | - |
| 茯苓 | 93.5% | - |
| 红花 | 91.8% | - |
| 薏米 | 90.3% | - |
| 麦冬 | 89.7% | - |
| 车前子 | 88.9% | - |
| 猫眼草 | 87.6% | - |
 |
6. 项目优化建议
数据层面优化
- 扩充数据集:每类药材理想数量为500张以上
- 数据增强:添加色彩抖动、遮挡等增强方式
- 背景移除:尝试使用分割技术移除背景干扰
模型层面优化
- 模型选择:尝试更高性能的ResNet101或EfficientNet
- 迁移学习微调:尝试不同冻结策略
- 集成学习:使用多模型集成提高准确率
部署优化
- 模型剪枝:减小模型尺寸
- 量化:降低计算复杂度
- TensorRT加速:用于实时识别场景
7. 常见问题解决
数据集问题
Q: 缺失class_names.json文件怎么办?
A: 手动创建该文件,内容为药材类别名称列表,格式为JSON数组。
Q: 图片数量不平衡如何处理?
A: 对样本较少的类别进行过采样或增强,或使用加权损失函数。
训练问题
Q: 显存不足怎么办?
A: 减小batch_size,或尝试使用更轻量级的模型如MobileNetV2。
Q: 出现过拟合怎么办?
A: 增加Dropout率,添加L2正则化,或增加数据增强强度。
预测问题
Q: 预测结果与实际不符怎么办?
A: 检查预处理流程是否与训练一致,特别是归一化参数。
Q: 模型在新环境表现下降?
A: 考虑域适应技术,或在新环境中收集少量数据进行微调。
5.项目源码下载
如需下载项目源码,请WX添加【Jul_54088】,回复【中草药识别】即可下载
附录:关于作者
本文档由[云帆智航]撰写,我们提供专业的软件开发服务:
- ✅ 定制化解决方案开发
- ✅ 系统架构设计咨询
- ✅ 技术难题攻坚
- 📢 访问淘宝店铺 获取更多服务
本文档可自由分享,商业使用请联系授权
后续支持
如果您需要本文档技术的落地实施支持,我们提供:
- 企业级定制开发服务
- 1对1技术咨询
- 淘宝店铺快速下单通道


















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









