







 本文介绍了1998年由YannLeCun提出的LeNet,它是多层卷积网络在图像识别领域的开创性工作。文章详细描述了LeNet-5模型结构,包括卷积层、池化、全连接层及其在MNIST数据集上的应用。实现了基于PyTorch的LeNet代码示例。
本文介绍了1998年由YannLeCun提出的LeNet,它是多层卷积网络在图像识别领域的开创性工作。文章详细描述了LeNet-5模型结构,包括卷积层、池化、全连接层及其在MNIST数据集上的应用。实现了基于PyTorch的LeNet代码示例。
LeNet
引入
LeNet是是由深度学习巨头Yann LeCun在1998年提出,可以算作多层卷积网络在图像识别领域的首次成功应用。我们现在通常说的LeNet是指LeNet-5,最早的LeNet-1在1988年即开始研究,前后持续十年之久。但是,受限于当时计算机算力的发展,以及本有的SVM技术效果就十分优秀,这一技术并没有得到广泛重视。然而,在以卷积神经网络为基础构建起的计算机视觉的今天,不得不感慨,二十年后今天的LLM或者是什么模型,会成为曾经的CNN/LeNet。
模型结构

LeNet的模型结构如上图所示,LeNet最初是用在MNIST手写数据集上,对手写数字进行分辨。对于输入的32×32像素的手写数据图,首先利用卷积核为5×5的卷积层转化成28×28×6的特征图,通道数为6(就是有6个不同卷积核),再使用Sigmoid和2×2的最大池化Maxpool提取最为关键的特征信息,维度变成14×14。接着在使用卷积核为5×5的卷积层转化成10×10的特征图,通道数为16,再使用Sigmoid和2×2的最大池化Maxpool提取最为关键的特征信息,维度变成5×5×16。再将其全部展开成一维,并连接三个卷积层和Softmax激活函数得到10分类的概率值,选取概率最大的分类作为最终预测分类。更为详细的结构图如下所示:
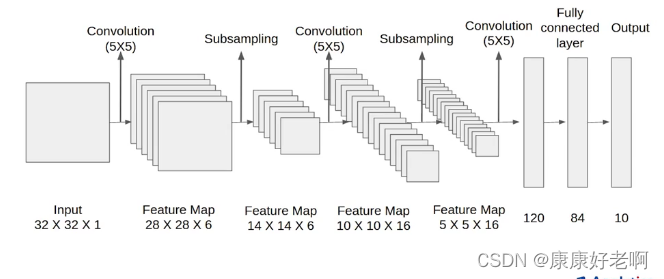
值得注意的是,通过查阅维基百科(2024.4.30),其中卷积层之间以及全连接层之间是使用Sigmoid进行连接的而不是像网上一些博客中提到的ReLU,在此进行更正。
LeNet可以说为后续的特征提取器提供了一个范式。这个范式是先使用卷积层提取特征,通过不断缩小特征图尺寸以及增加通道数提取特征,并使用池化层提升泛化性防止过拟合。之后将这些特征展开成一维使用全连接层进行分类并使用Softmax输出预测概率。
实现代码
import torch
import torch.nn as nn
import torch.nn.functional  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









