









承接上文 顺序观看,效果更佳
官网,英语好的,请直接食用。![]() https://dgraph.io/docs/tutorial-2/#deleting-a-predicate
https://dgraph.io/docs/tutorial-2/#deleting-a-predicate
目录
一、基本类型和操作
让我们从构建一个简单的博客应用程序的图形开始。下面是我们应用程序的Graph
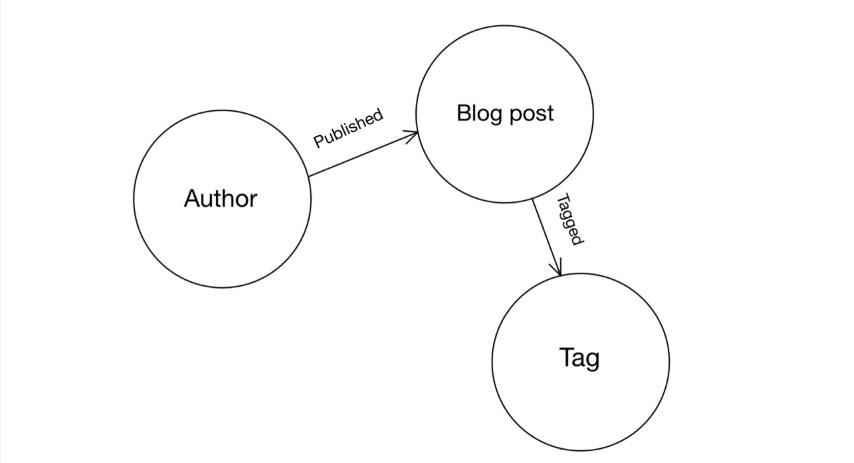
上图有三个实体:作者、博客帖子和标签。图中的节点表示这些实体。在本教程的其余部分,我们将把表示博客的节点称为博客文章节点,将表示标记的节点称称为标记节点,依此类推。
从图形模型中可以看出,这些实体是相关的:
每个作者都有一个或多个博客帖子。
已发布的边缘将博客与其作者联系起来。这些边从作者节点开始,指向博客文章节点。
每个博客帖子都有一个或多个标签。
标记边缘将博客文章与其标记关联起来。这些边从博客文章节点中出现并指向标记节点。
让我们构建图表。
转到Ratel,单击mutate选项卡,粘贴以下突变,然后单击Run。
{
"set": [
{
"author_name": "John Campbell",
"rating": 4.1,
"published": [
{
"title": "Dgraph's recap of GraphQL Conf - Berlin 2019",
"url": "https://blog.dgraph.io/post/graphql-conf-19/",
"content": "We took part in the recently held GraphQL conference in Berlin. The experience was fascinating, and we were amazed by the high voltage enthusiasm in the GraphQL community. Now, we couldn’t help ourselves from sharing this with Dgraph’s community! This is the story of the GraphQL conference in Berlin.",
"likes": 100,
"dislikes": 4,
"publish_time": "2018-06-25T02:30:00",
"tagged": [
{
"uid": "_:graphql",
"tag_name": "graphql"
},
{
"uid": "_:devrel",
"tag_name": "devrel"
}
]
},
{
"title": "Dgraph Labs wants you!",
"url": "https://blog.dgraph.io/post/hiring-19/",
"content": "We recently announced our successful Series A fundraise and, since then, many people have shown interest to join our team. We are very grateful to have so many people interested in joining our team! We also realized that the job openings were neither really up to date nor covered all of the roles that we are looking for. This is why we decided to spend some time rewriting them and the result is these six new job openings!.",
"likes": 60,
"dislikes": 2,
"publish_time": "2018-08-25T03:45:00",
"tagged": [
{
"uid": "_:hiring",
"tag_name": "hiring"
},
{
"uid": "_:careers",
"tag_name": "careers"
}
]
}
]
},
{
"author_name": "John Travis",
"rating": 4.5,
"published": [
{
"title": "How Dgraph Labs Raised Series A",
"url": "https://blog.dgraph.io/post/how-dgraph-labs-raised-series-a/",
"content": "I’m really excited to announce that Dgraph has raised $11.5M in Series A funding. This round is led by Redpoint Ventures, with investment from our previous lead, Bain Capital Ventures, and participation from all our existing investors – Blackbird, Grok and AirTree. With this round, Satish Dharmaraj joins Dgraph’s board of directors, which includes Salil Deshpande from Bain and myself. Their guidance is exactly what we need as we transition from building a product to bringing it to market. So, thanks to all our investors!.",
"likes": 139,
"dislikes": 6,
"publish_time": "2019-07-11T01:45:00",
"tagged": [
{
"uid": "_:annoucement",
"tag_name": "annoucement"
},
{
"uid": "_:funding",
"tag_name": "funding"
}
]
},
{
"title": "Celebrating 10,000 GitHub Stars",
"url": "https://blog.dgraph.io/post/10k-github-stars/",
"content": "Dgraph is celebrating the milestone of reaching 10,000 GitHub stars 🎉. This wouldn’t have happened without all of you, so we want to thank the awesome community for being with us all the way along. This milestone comes at an exciting time for Dgraph.",
"likes": 33,
"dislikes": 12,
"publish_time": "2017-03-11T01:45:00",
"tagged": [
{
"uid": "_:devrel"
},
{
"uid": "_:annoucement"
}
]
}
]
},
{
"author_name": "Katie Perry",
"rating": 3.9,
"published": [
{
"title": "Migrating data from SQL to Dgraph!",
"url": "https://blog.dgraph.io/post/migrating-from-sql-to-dgraph/",
"content": "Dgraph is rapidly gaining reputation as an easy to use database to build apps upon. Many new users of Dgraph have existing relational databases that they want to migrate from. In particular, we get asked a lot about how to migrate data from MySQL to Dgraph. In this article, we present a tool that makes this migration really easy: all a user needs to do is write a small 3 lines configuration file and type in 2 commands. In essence, this tool bridges one of the best technologies of the 20th century with one of the best ones of the 21st (if you ask us).",
"likes": 20,
"dislikes": 1,
"publish_time": "2018-08-25T01:44:00",
"tagged": [
{
"uid": "_:tutorial",
"tag_name": "tutorial"
}
]
},
{
"title": "Building a To-Do List React App with Dgraph",
"url": "https://blog.dgraph.io/post/building-todo-list-react-dgraph/",
"content": "In this tutorial we will build a To-Do List application using React JavaScript library and Dgraph as a backend database. We will use dgraph-js-http — a library designed to greatly simplify the life of JavaScript developers when accessing Dgraph databases.",
"likes": 97,
"dislikes": 5,
"publish_time": "2019-02-11T03:33:00",
"tagged": [
{
"uid": "_:tutorial"
},
{
"uid": "_:devrel"
},
{
"uid": "_:javascript",
"tag_name": "javascript"
}
]
}
]
}
]
}
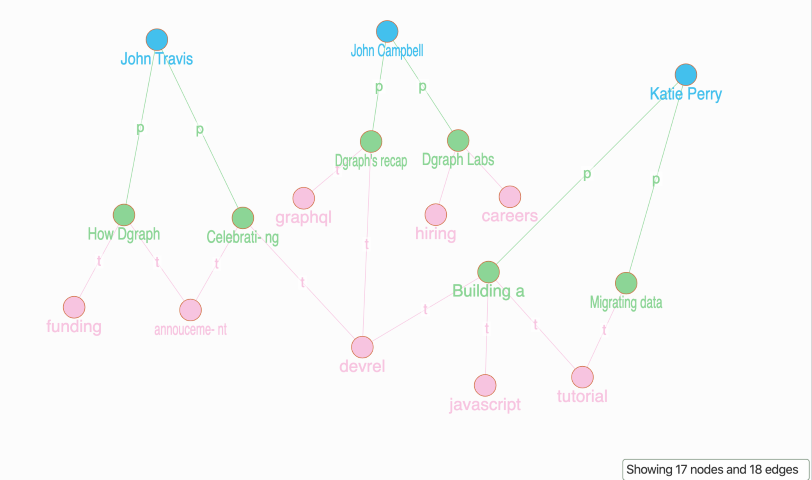
我们的图表具有:
三个蓝色作者节点。
每个作者都有两篇博文,共六篇,由绿色节点表示。
博客帖子的标签是粉红色的。您可以看到有8个独特的标签,并且一些博客共享一个通用标签。
1、谓词的数据类型
Dgraph自动检测其谓词的数据类型。您可以使用Ratel UI查看自动检测到的数据类型。
单击左侧的模式选项卡,然后选中类型列。您将看到谓词名称及其对应的数据类型。
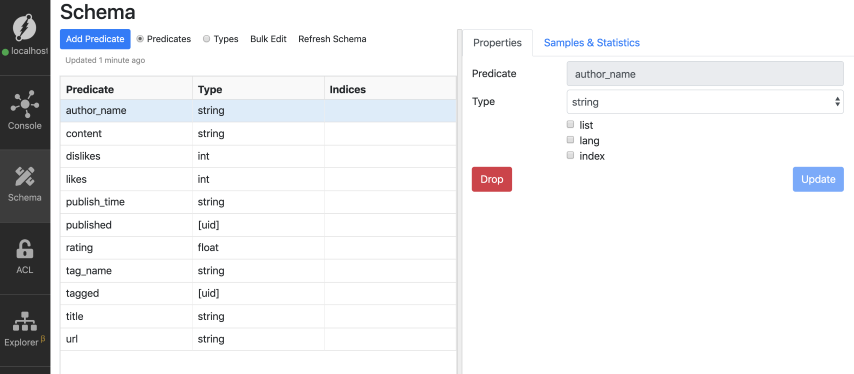
这些数据类型包括string、float、int和uid。除此之外,Dgraph还提供了三种更基本的数据类型:geo、dateTime和bool。
uid类型表示两个节点之间的谓词。换句话说,它们表示连接两个节点的边。
您可能已经注意到,已发布和标记的谓词是uid数组([uid])类型。UID数组表示UID的集合。这用于表示一对多关系。
例如,我们知道一个作者可以发布多个博客。因此,给定的作者节点可能会出现多个已发布的边缘,每个边缘指向作者的不同博客文章。
2、查询谓词值
首先,让我们查询所有作者及其评分:
{
authors_and_ratings(func: has(author_name)) {
uid
author_name
rating
}
}

我们的数据集中总共有3位作者。现在,让我们找到最好的作者。让我们查询评分为4.0或更高的作者。
为了实现我们的目标,我们需要一种方法来选择满足特定标准(例如,评级>4.0)的节点。您可以使用Dgraph的内置比较器函数来实现这一点。以下是Dgraph中可用的比较器函数列表:
比较器函数名 完整形式
eq 等于
lt 小于
le 小于或等于
gt 大于
ge 大于或等于
Dgraph中总共有五个比较器函数。在查询中,可以将它们中的任何一个与func关键字一起使用。
比较器函数接受两个参数。一个是谓词名称,另一个是其可比值。这里有几个例子。
示例用法说明
func:eq(age,60)返回age谓词等于60的节点。
func:gt(likes,100)返回likes谓词值大于100的节点。
func:le(dislikes,10)返回不喜欢谓词值小于或等于10的节点。
现在,猜猜我们应该使用哪个比较器函数来选择评分为4.0或更高的作者节点。
如果你认为它应该是大于或等于(ge)函数,那么你是对的!
让我们试试看。
{
best_authors(func: ge(rating, 4.0)) {
uid
author_name
rating
}
}
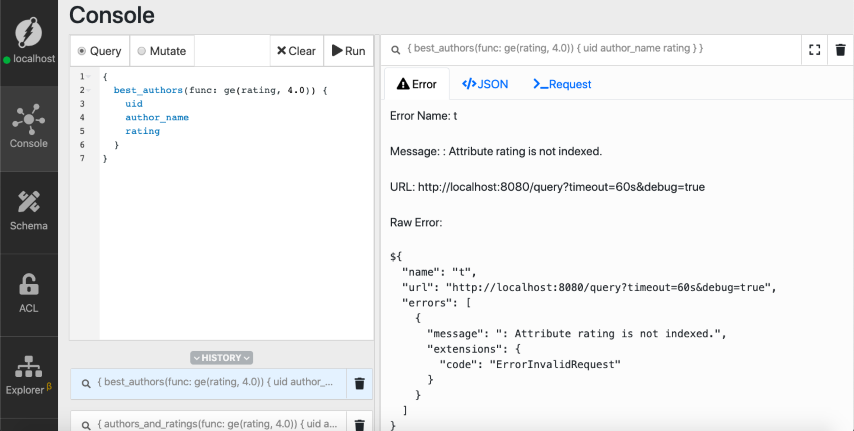
我们出错了!缺少评级谓词的索引。除非为谓词添加了索引,否则无法查询谓词的值。
让我们进一步了解Dgraph中的索引以及如何添加索引。
3、Dgraph中的索引
索引用于加快对谓词的查询。当需要时,必须将它们显式添加到谓词中。也就是说,只有当您需要查询谓词的值时。
此外,没有必要在一开始就预测要添加的索引。您可以在继续时添加它们。
Dgraph提供了不同类型的索引。索引的选择取决于谓词的数据类型。
下面是包含数据类型和可应用于数据类型的索引集的表。
| 数据类型 | 索引类型 |
|---|---|
| int | int |
| float | float |
| string | hash, exact, term, fulltext, trigram |
| bool | bool |
| geo | geo |
| dateTime | year, month, day, hour |
只有string和dateTime数据类型可以选择多个索引类型。
让我们在评级谓词上创建一个索引。Ratel UI使添加索引变得非常简单。
以下是步骤顺序:
转到左侧的模式选项卡。
单击列表中的评级谓词。
勾选右侧“属性”UI中的索引选项。
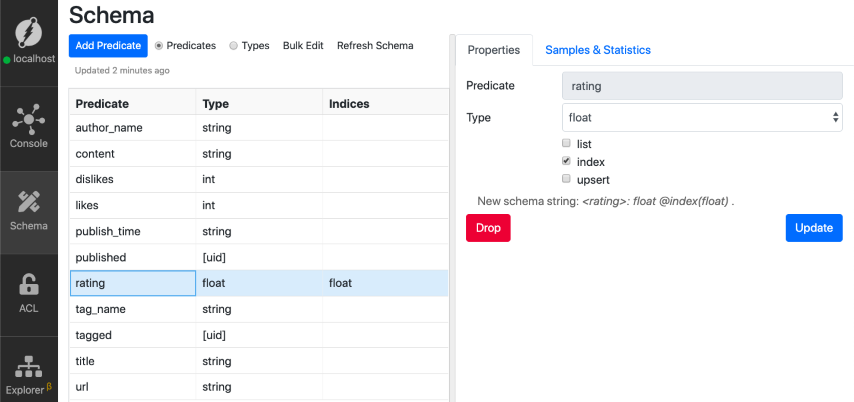
我们成功添加了评级谓词的索引!让我们重新运行上一个查询。
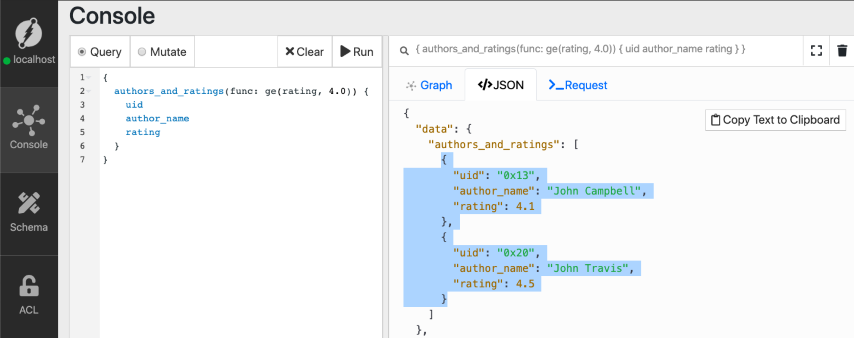
我们成功查询了评分为4.0或更高的Author节点。我们还可以获取这些作者的博客帖子吗?
我们已经知道,发布的边从作者节点指向博客文章节点。因此,获取作者节点的博客帖子很简单。我们需要从作者节点开始遍历已发布的边。
{
authors_and_ratings(func: ge(rating, 4.0)) {
uid
author_name
rating
published {
title
content
dislikes
}
}
}
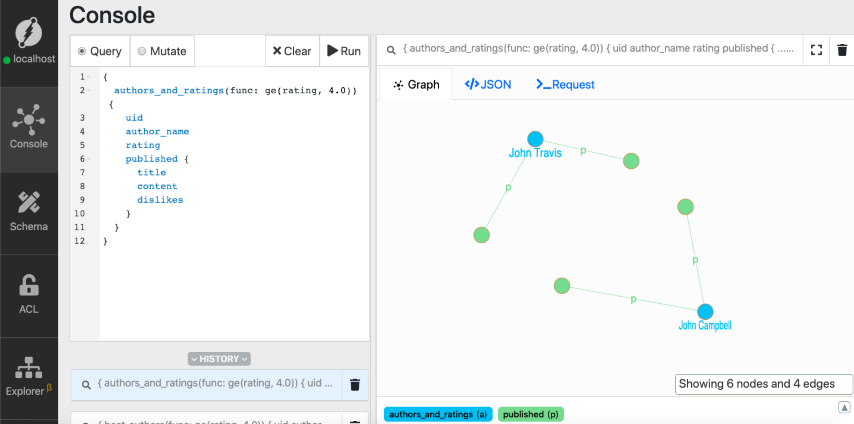
如果您对图遍历查询有疑问,请查看我们之前的教程。
同样,让我们扩展前面的查询以获取这些博客文章的标签。
{
authors_and_ratings(func: ge(rating, 4.0)) {
uid
author_name
rating
published {
title
content
dislikes
tagged {
tag_name
}
}
}
}
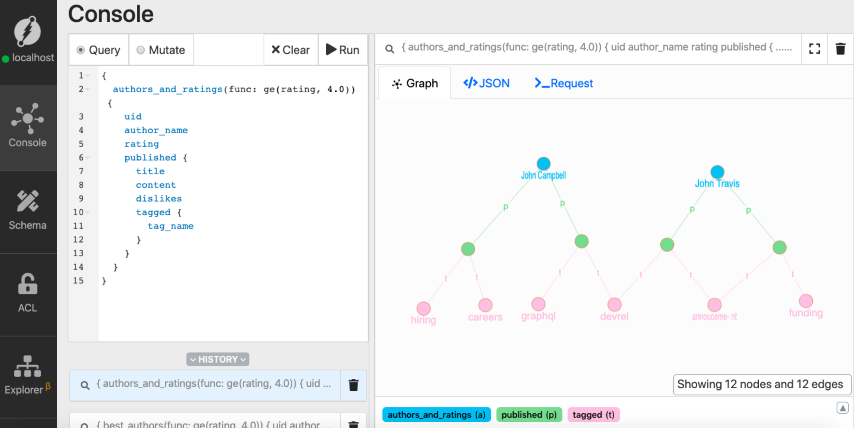
注意:作者节点为蓝色,博客帖子为绿色,标签为粉色。
我们有两位作者,四篇博客文章,以及他们的标签。如果你仔细观察一下结果,会发现有一篇博客文章有12个不喜欢的地方。
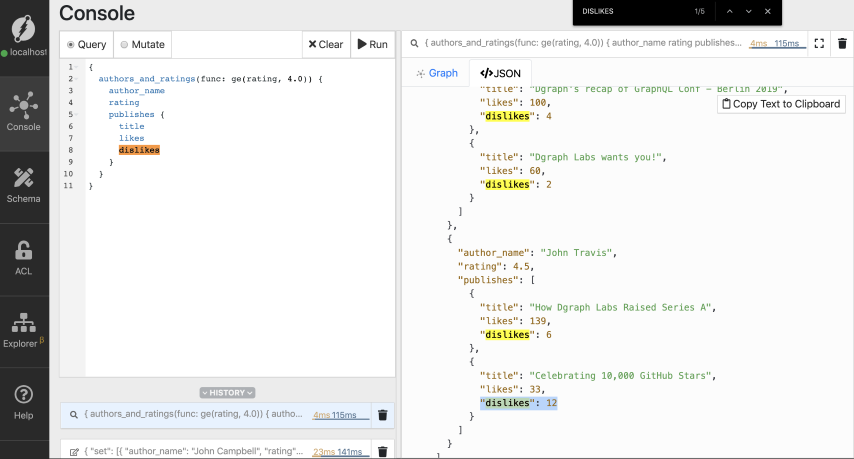
让我们只过滤和获取流行的博客帖子。让我们只查询那些不喜欢的博客帖子。
为了实现这一点,我们需要将以下语句表达为对Dgraph的查询:
嘿,遍历已发布的边缘,但只返回那些不喜欢的博客少于10个
4、过滤遍历
我们可以使用@filter指令过滤遍历的结果。您可以将Dgraph的任何比较器函数与@filter指令一起使用。你应该使用lt比较器来过滤那些不喜欢的博客帖子,这些帖子少于10个。这是一个问题。
{
authors_and_ratings(func: ge(rating, 4.0)) {
author_name
rating
published @filter(lt(dislikes, 10)) {
title
likes
dislikes
tagged {
tag_name
}
}
}
}
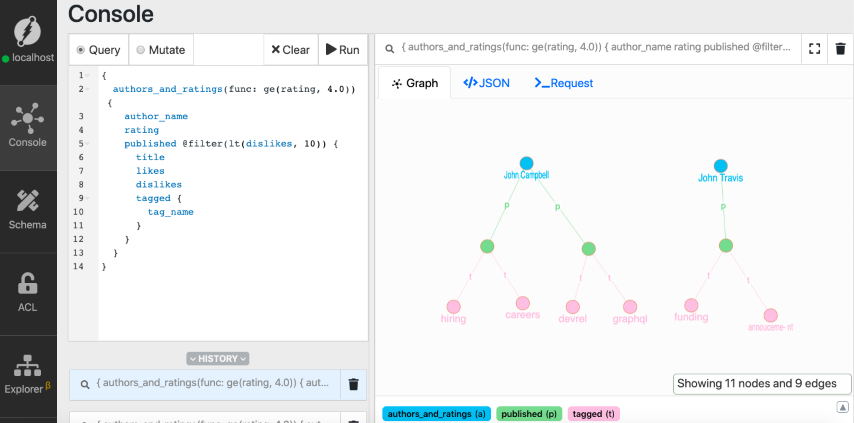
现在,我们的结果只有三个博客。有12个不喜欢的博客被过滤掉了。
注意,博客文章与一系列标签相关联。
让我们运行以下查询并查找数据库中的所有标记。
{
all_tags(func: has(tag_name)) {
tag_name
}
}
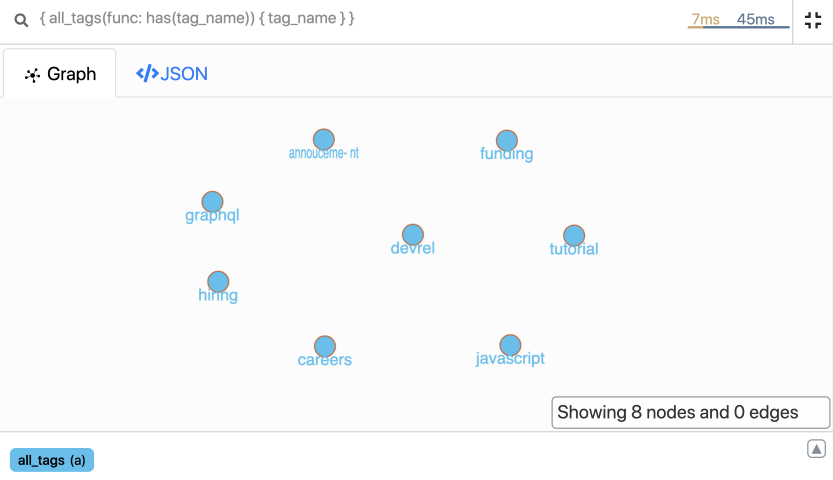
我们在数据库中找到了所有的标签。我最喜欢的标签是devrel。你的是什么?
5、查询字符串谓词
tag_name谓词表示标记的名称。它的类型为string。以下是获取所有标记为devrel的博客文章的步骤。
查找tag_name谓词值设置为devrel的根节点。我们可以使用eq比较器函数这样做。
在运行查询之前,不要忘记向tag_name谓词添加索引。
从devrel标记的节点开始沿标记边缘遍历。
让我们从向tag_name谓词添加索引开始。转到Ratel,从列表中单击tag_name谓词。
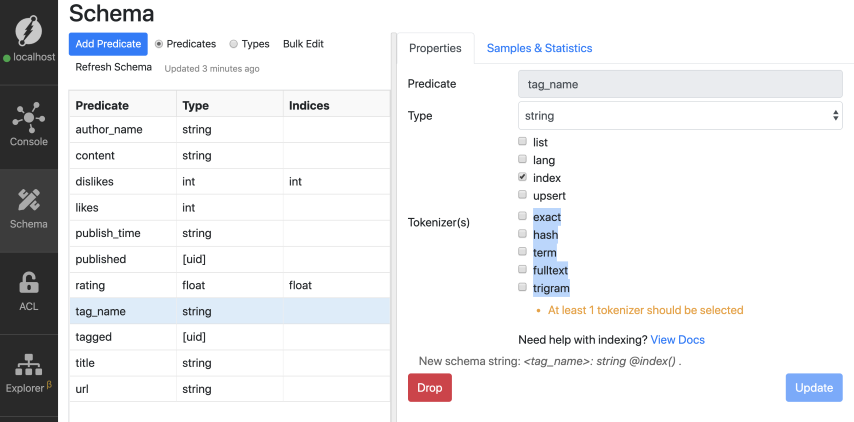
您可以看到,有五种索引选项可以应用于任何字符串谓词。全文、术语和三元组是高级字符串索引。我们将在下一集详细讨论它们。
字符串类型索引和比较器函数的使用有一些限制。
例如,只有精确索引与le、ge、lt和gt内置函数兼容。如果使用任何其他索引设置字符串谓词并运行上述比较器,则查询将失败。
尽管五个字符串类型索引中的任何一个都与eq函数兼容,但与eq比较器一起使用的哈希索引通常是性能最好的。
让我们将哈希索引添加到tag_name谓词中。

让我们使用eq比较器并获取tag_name设置为devrel的根节点。
{
devrel_tag(func: eq(tag_name,"devrel")) {
tag_name
}
}

我们终于有了我们想要的节点!
我们知道博客文章节点通过标记的边连接到它们的标记节点。您认为从节点到devrel标记的遍历应该为我们提供博客文章吗?让我们试试看!
{
devrel_tag(func: eq(tag_name,"devrel")) {
tag_name
tagged {
title
content
}
}
}
看起来查询不起作用!它没有给我们回博客帖子!不要惊讶,这是意料之中的。
让我们再次观察Graph模型。
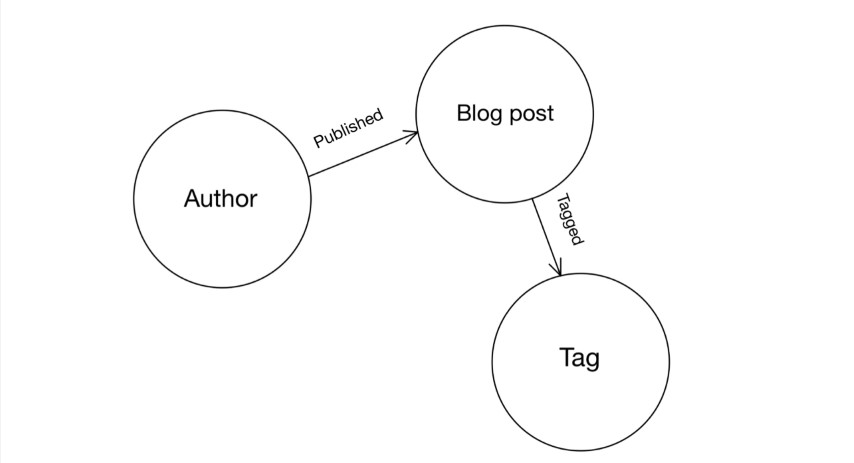
我们知道Dgraph中的边有方向。您可以看到标记的边从博客文章节点指向标记节点。
沿着边的方向进行遍历对于Dgraph来说是很自然的。因此,您可以通过标记边缘从任何博客文章节点遍历到其标记节点。
但是,要从另一个方向来回移动,需要与边的方向相反。您仍然可以通过在查询中添加波浪号(~)来完成此操作。波浪号(~)必须添加在要遍历的边的名称的开头。
让我们在标记边的开头添加波浪号(~),并启动反向边遍历。
{
devrel_tag(func: eq(tag_name,"devrel")) {
tag_name
~tagged {
title
content
}
}
}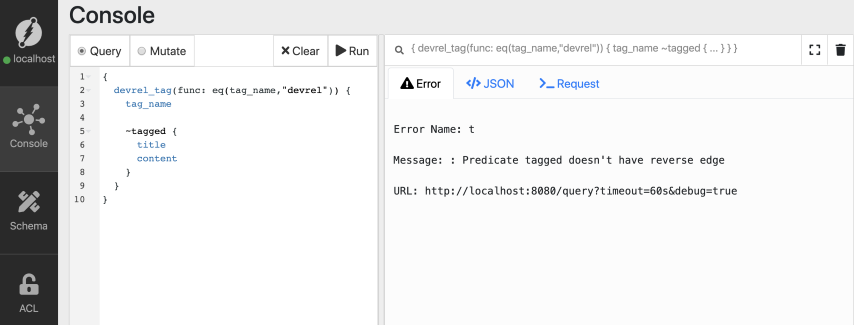
我们出错了!
反向遍历需要谓词上的索引。
让我们转到Ratel并将反向索引添加到边缘。

让我们重新运行反向遍历。
{
devrel_tag(func: eq(tag_name, "devrel")) {
tag_name
~tagged {
title
content
}
}
}
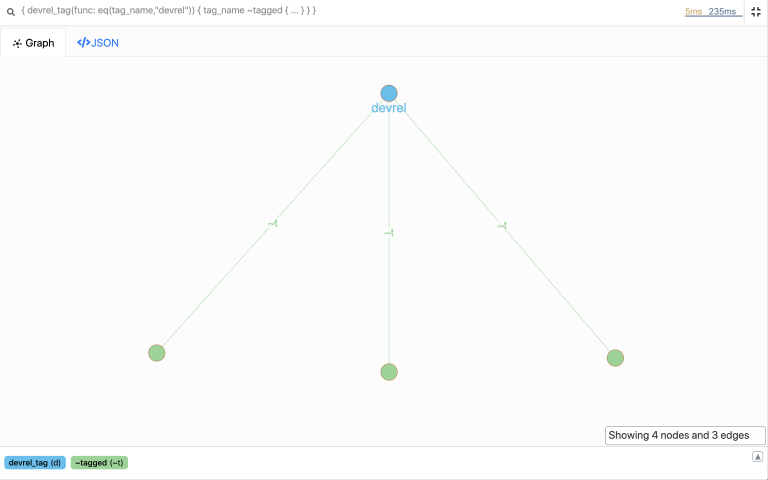
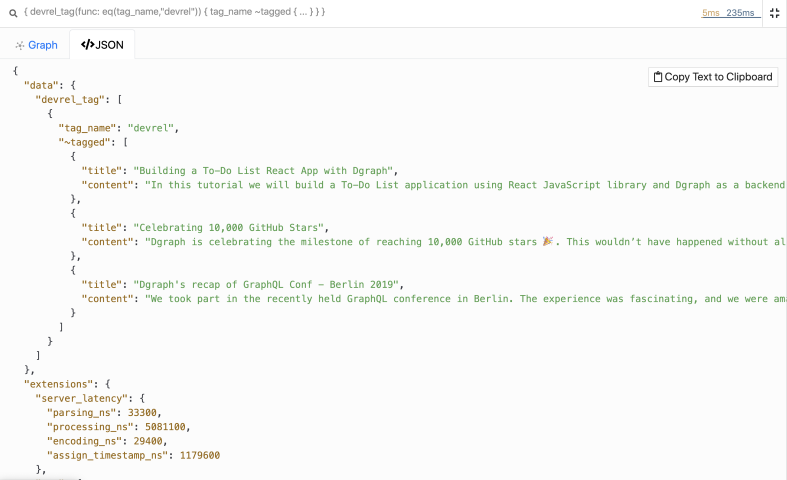
现在我们得到了所有标记为devrel的博客帖子。
同样,您可以扩展查询以查找这些博客文章的作者。它要求您反向遍历已发布的谓词。
让我们将反向索引添加到已发布的边。
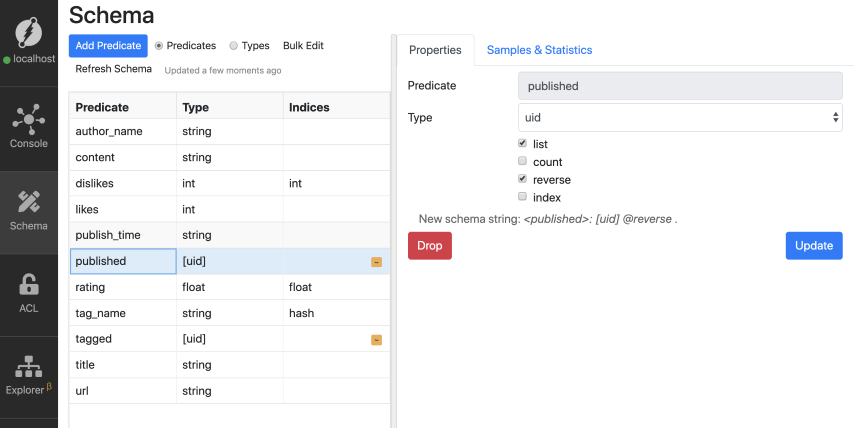
现在,让我们运行以下查询。
{
devrel_tag(func: eq(tag_name,"devrel")) {
tag_name
~tagged {
title
content
~published {
author_name
}
}
}
}
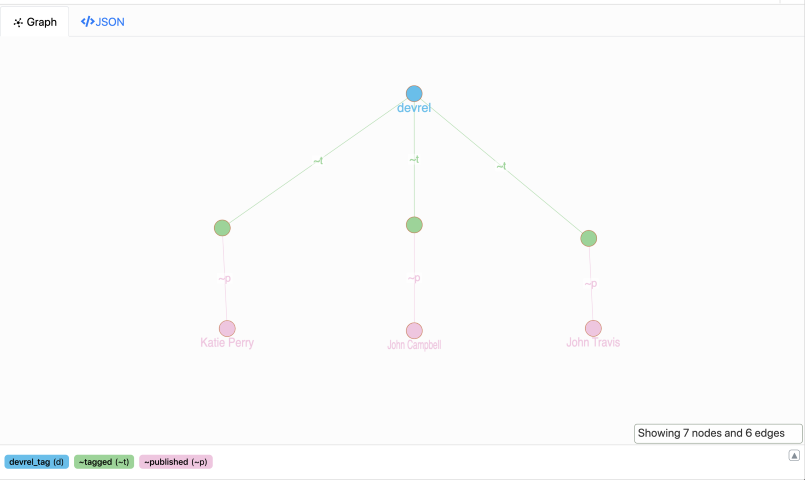
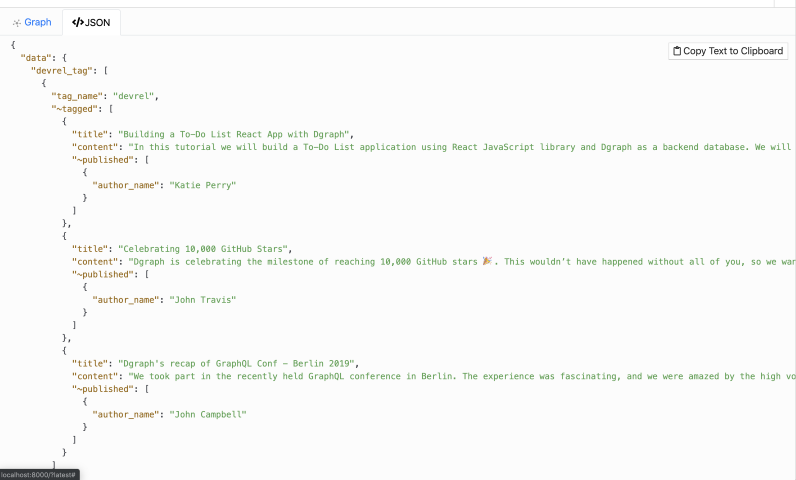
在前面的查询中,我们以相反的顺序遍历了整个图。从标记节点开始,我们遍历到作者节点。
二、多语言字符串
1、字符串和语言
Dgraph中的字符串值采用UTF-8格式。Dgraph还支持多种语言中字符串谓词类型的值。多语言功能对于构建特性特别有用,这需要您以多种语言存储相同的信息。
让我们进一步了解他们!
让我们从构建一个简单的食物回顾图开始。这是Graph模型。
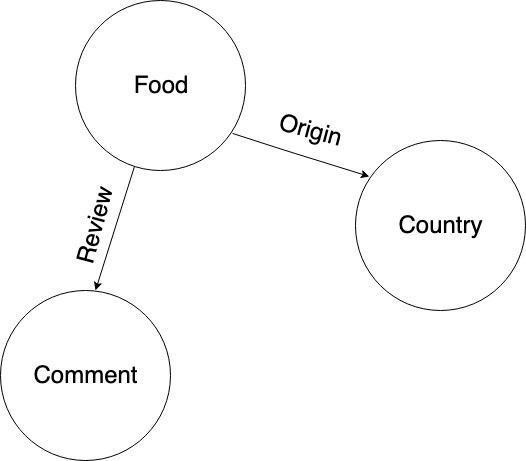
上图有三个实体:食物、评论和国家。
图表中的节点表示这些实体。
在本教程的其余部分,让我们将表示食物项的节点称为食物节点。将评审意见表示为评审节点的节点,将原产国表示为国家节点的节点。
以下是它们之间的关系:
每个食物都通过评论边缘与评论相关联。
每种食物都通过原产地边缘与原产国相连。
让我们为一些很棒的菜肴添加一些评论!
在我们做那件事之前把它弄得更香一点怎么样?
让我们用原产国的母语添加这些菜肴的评论。
走吧,朋友!
{
"set": [
{
"food_name": "Hamburger",
"review": [
{
"comment": "Tastes very good"
}
],
"origin": [
{
"country": "United states of America"
}
]
},
{
"food_name": "Carrillada",
"review": [
{
"comment": "Sabe muy sabroso"
}
],
"origin": [
{
"country": "Spain"
}
]
},
{
"food_name": "Pav Bhaji",
"review": [
{
"comment": "स्वाद बहुत अच्छा है"
}
],
"origin": [
{
"country": "India"
}
]
},
{
"food_name": "Borscht",
"review": [
{
"comment": "очень вкусно"
}
],
"origin": [
{
"country": "Russia"
}
]
},
{
"food_name": "mapo tofu",
"review": [
{
"comment": "真好吃"
}
],
"origin": [
{
"country": "China"
}
]
}
]
}
注意:如果这种变异语法对您来说是新的,请参考第一个教程来学习Dgraph中变异的基础知识。
这是我们的图表!
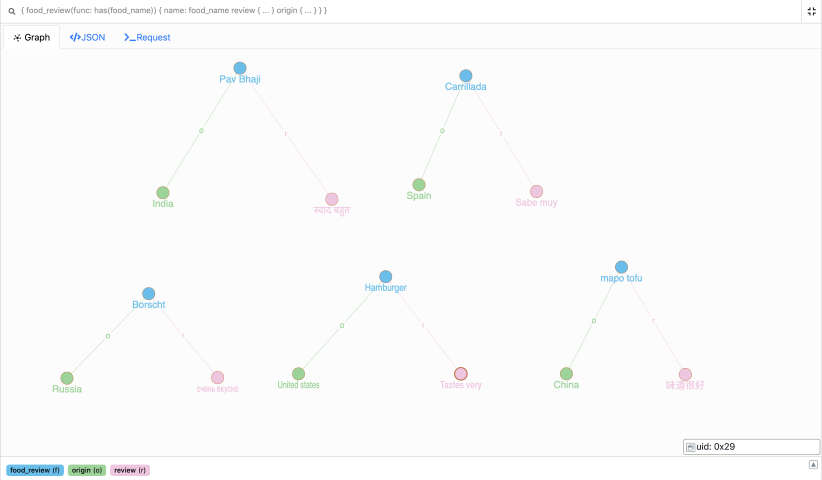
我们的图表具有:
五个蓝色食物节点。
绿色节点表示这些食品的原产地。
食品的评论是粉红色的。
您还可以看到Dgraph已经自动检测到谓词的数据类型。您可以从模式选项卡中查看。
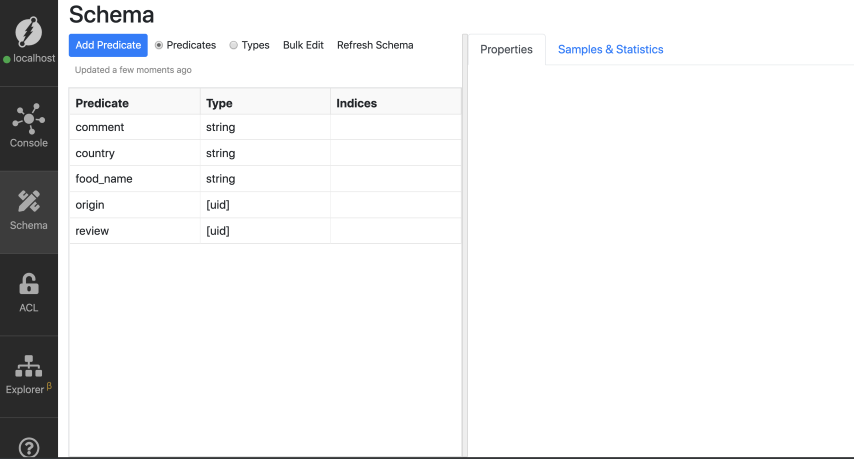
注意:查看前面的教程,了解Dgraph中数据类型的更多信息。
让我们编写一个查询来获取所有食品、它们的评论和它们的原产国。
转到查询选项卡,粘贴查询,然后单击运行。
{
food_review(func: has(food_name)) {
food_name
review {
comment
}
origin {
country
}
}
}
现在,让我们只取食物和他们的评论,
{
food_review(func: has(food_name)) {
food_name
review {
comment
}
}
}不出所料,这些评论使用了不同的语言。
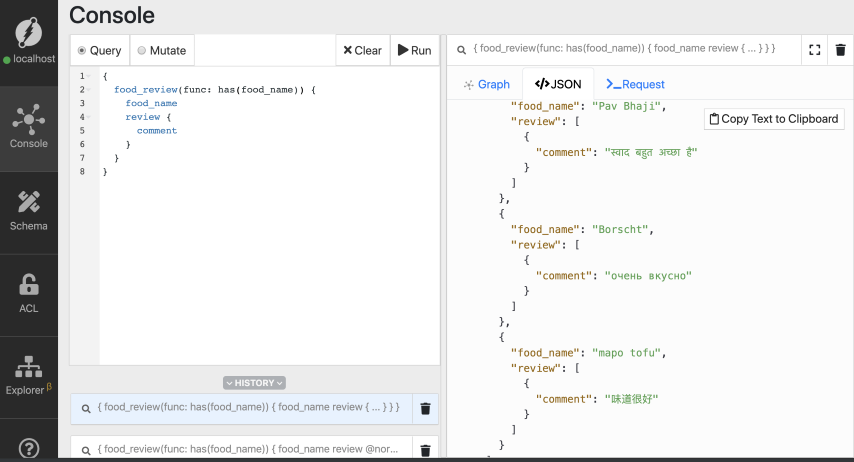
但是我们可以根据他们的语言来获取评论吗?我们可以写一个查询,说:嘿,Dgraph,你能只给我中文写的评论吗?
这是可能的,但前提是必须提供有关字符串数据语言的附加信息。您可以通过使用语言标记来实现。使用突变添加字符串数据时,可以使用语言标记指定字符串谓词的语言。
让我们看看语言标签的作用!
我听说寿司很好吃!让我们用多种语言为Sushi添加评论。我们将用三种不同的语言撰写评论:英语、日语和俄语。
这里有这样做的突变。
{
"set": [
{
"food_name": "Sushi",
"review": [
{
"comment": "Tastes very good",
"comment@jp": "とても美味しい",
"comment@ru": "очень вкусно"
}
],
"origin": [
{
"country": "Japan"
}
]
}
]
}
让我们更仔细地看看我们如何为不同语言的注释谓词赋值。
我们使用语言标记(@ru,@jp)作为注释谓词的后缀。
在上述突变中:
我们使用@ru语言标签添加俄语评论:“comment@ru": "очень вкусно".
我们使用@jp语言标签添加日语注释:“comment@jp": "とても美味しい".
英文评论没有标注:“comment”:“味道很好”。
在上面的变异中,Dgraph为评论创建了一个新节点,comment@ru和comment@jp在同一节点内的不同谓词中。
注意:如果您不清楚谓词等基本术语,请阅读第一篇教程。
让我们运行上面的突变。
转到突变选项卡,粘贴突变,然后单击运行。
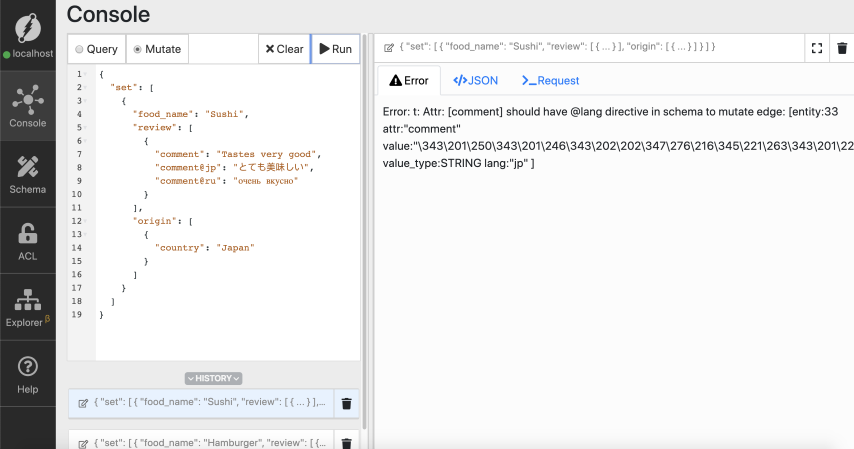
我们出错了!使用language标记需要将@lang指令添加到模式中。
按照以下说明将@lang指令添加到注释谓词。
转到“架构”选项卡。
单击注释谓词。
勾选lang指令。
单击更新按钮。

让我们重新运行突变。
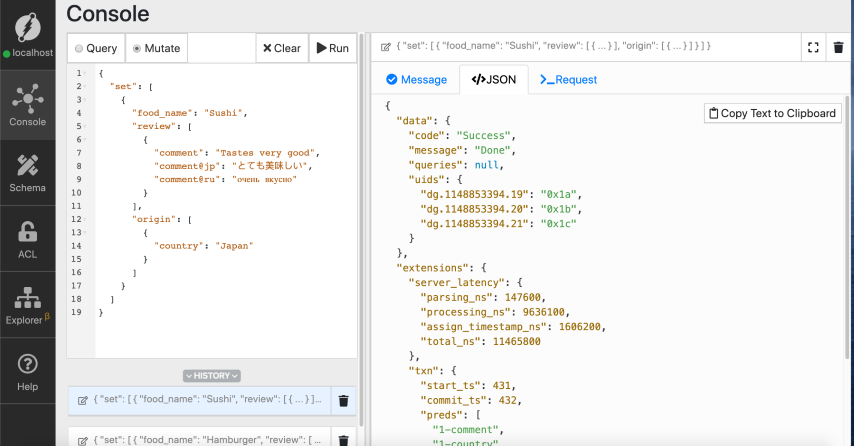
成功
再次,请记住,使用上述突变,我们只为Sushi添加了一个评论,而不是三个不同的评论!
但是,如果你想添加三个不同的评论,下面是你的做法。
以以下格式添加评论将创建三个节点,每个节点对应一条评论。但是,只有在添加新评论时才这样做,而不是用不同的语言表示相同的评论。
"review": [
{
"comment": "Tastes very good"
},
{
"comment@jp": "とても美味しい"
},
{
"comment@ru": "очень вкусно"
}
]
Dgraph允许将任何字符串用作语言标记。但是,强烈建议只对语言标签使用ISO标准代码。
通过遵循标准,您就不需要将标签传达给您的团队或将其记录在某个地方。
2、使用语言标记进行查询。
让我们只获取Sushi的评论。
在上一篇文章中,我们了解了如何使用eq运算符和哈希索引来查询字符串谓词值。
使用这些知识,我们首先为food_name谓词添加哈希索引。
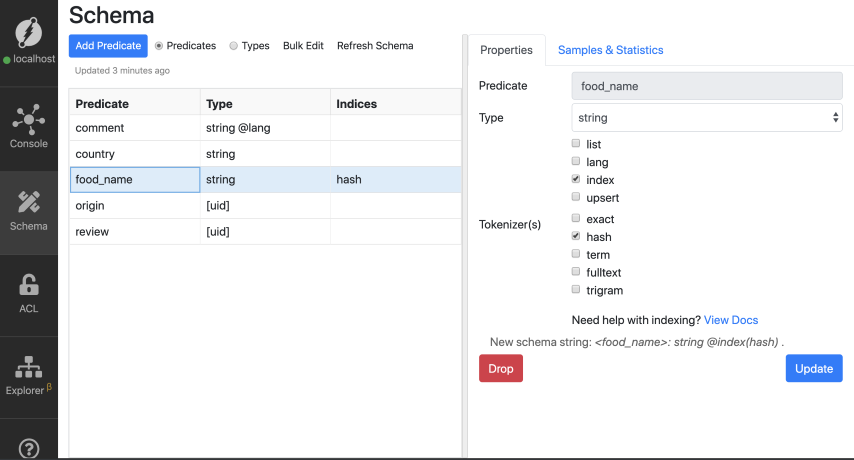
现在,转到查询选项卡,将查询粘贴到文本区域,然后单击运行。
{
food_review(func: eq(food_name,"Sushi")) {
food_name
review {
comment
}
}
}
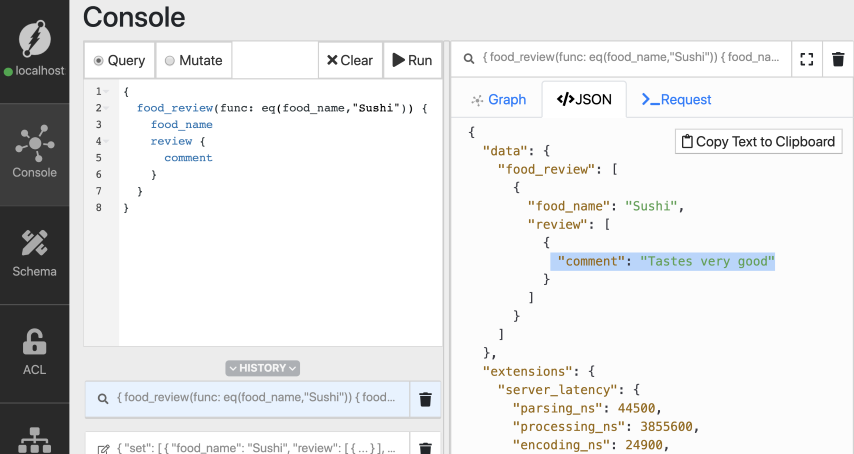
默认情况下,查询只返回未标记的注释。
但您可以使用语言标记专门查询给定语言的评论。
让我们查询一下寿司的日语评论
{
food_review(func: eq(food_name,"Sushi")) {
food_name
review {
comment@jp
}
}
}
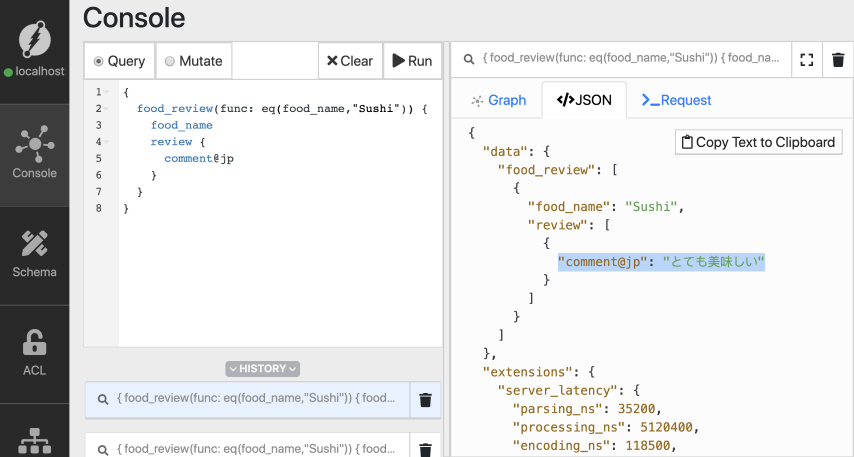
现在,让我们查询一下俄语版的寿司评论。
{
food_review(func: eq(food_name,"Sushi")) {
food_name
review {
comment@ru
}
}
}
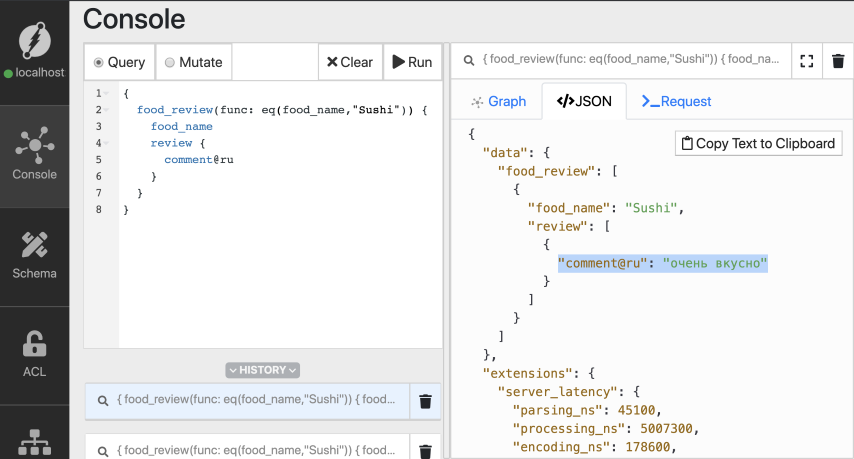
您还可以获取所有用任何语言编写的寿司评论。
{
food_review(func: eq(food_name,"Sushi")) {
food_name
review {
comment@*
}
}
}
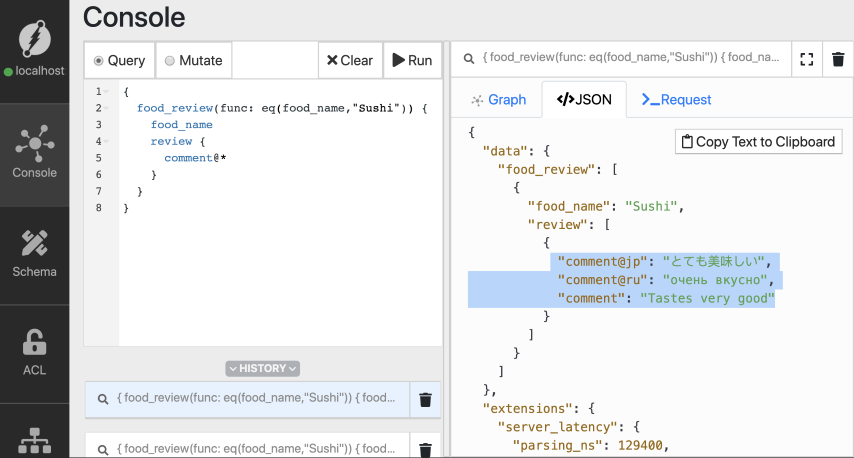
下面是一个表,其中包含查询时使用语言标记的各种方法的语法。
| Syntax | Result |
|---|---|
| comment | 如果不存在未标记的评论,则不返回任何内容。 |
| comment@. | 如果未找到,则返回任何语言的评论。但是,这只返回一个值。 |
| comment@jp | 如果未找到,查询将不返回任何内容。 |
| comment@ru | 如果未找到,查询将不返回任何内容。 |
| comment@jp:. | 如果未找到,则查找未标记的内容。 |
| comment@jp:ru | 查找标记为@jp的评论,然后查找@ru。如果两者都未找到,则不返回任何内容。 |
| comment@jp:ru:. | 找标记为@jp,然后是@ru的评论。如果两者都未找到,则查找未标记的内容。如果没有找到,请返回任何其他注释(如果存在)。 |
| comment@* | 返回所有语言标记,包括未标记的。 |
如果你还记得的话,我们最初添加了一道俄罗斯菜Borscht,并用俄语进行了评论。
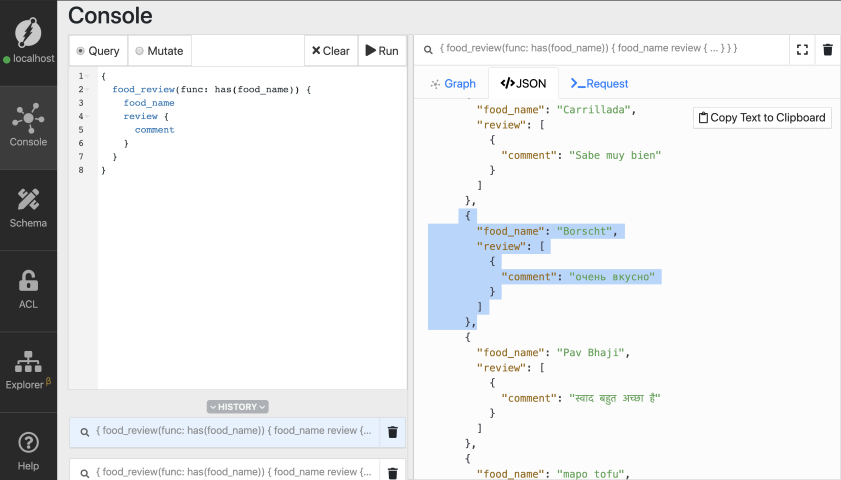
3、语言表
| 语言 | 国家code | 拼写 | 停止词 |
|---|---|---|---|
| 阿拉伯文 | ar | ✓ | ✓ |
| 亚美尼亚语 | hy | ✓ | |
| 巴斯克语 | eu | ✓ | |
| 保加利亚语 | bg | ✓ | |
| 加泰罗尼亚语 | ca | ✓ | |
| 中文 | zh | ✓ | ✓ |
| 捷克语 | cs | ✓ | |
| 丹麦语 | da | ✓ | ✓ |
| 荷兰语 | nl | ✓ | ✓ |
| 英语 | en | ✓ | ✓ |
| 芬兰语 | fi | ✓ | ✓ |
| 法语 | fr | ✓ | ✓ |
| 盖尔语 | ga | ✓ | |
| 加利西亚语 | gl | ✓ | |
| 德语 | de | ✓ | ✓ |
| 希腊语 | el | ✓ | |
| 印地语 | hi | ✓ | ✓ |
| 匈牙利语胡 | hu | ✓ | ✓ |
| 印度尼西亚 | id | ✓ | |
| 意大利语 | it | ✓ | ✓ |
| 日语 | ja | ✓ | ✓ |
| 韩国 | ko | ✓ | ✓ |
| 挪威语 | no | ✓ | ✓ |
| 波斯语 | fa | ✓ | |
| 葡萄牙语 | pt | ✓ | ✓ |
| 罗马尼亚罗 | ro | ✓ | ✓ |
| 俄语 | ru | ✓ | ✓ |
| 西班牙语 | es | ✓ | ✓ |
| 瑞典语 | sv | ✓ | ✓ |
| 土耳其语 | tr | ✓ | ✓ |















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









