







实践准备
赛题链接:讯飞平台的用户新增预测挑战赛
https://challenge.xfyun.cn/topic/info?type=subscriber-addition-prediction&option=ssgy&ch=j4XWs7V
datawhale提供的学习手册:
https://datawhaler.feishu.cn/docx/HBIHd7ugzoOsMqx0LEncR1lJnCf
赛题解析与解题思路
赛题任务
根据讯飞平台提供的数据集构建模型,用来预测某一行为记录是否是新增用户所为
赛题数据集
赛题数据由约62万条训练集、20万条测试集数据组成,共包含13个字段。其中uuid为样本唯一标识,eid为访问行为ID,udmap为行为属性,其中的key1到key9表示不同的行为属性,如项目名、项目id等相关字段,common_ts为应用访问记录发生时间(毫秒时间戳),其余字段x1至x8为用户相关的属性,为匿名处理字段。target字段为预测目标,即是否为新增用户。
根据分析,赛题数据字段可以分为用户行为记录唯一标识uuid,行为相关字段eid、udmap,时间标识common_ts,用户身份相关字段x1到x8
评价指标
f1_score
关于解题思路的思考
在解决机器学习问题时的流程:

- 对于这个问题,我们为什么不选择深度学习?
首先,我们这里的数据量并不足够做深度学习,根据阿水竞赛大佬的分享,训练数据集小于200w的情况下,我们一般不考虑用深度学习做,因为当数据量少的情况下,其自动提取特征的效果并不好
其次,如果我们在进行特征工程时,有效捕捉了数据的关键特征,机器学习算法也能够表现得很好。
并且对于特定问题,手动设计特征往往会带来意想不到的效果。 - 为什么决策树而非逻辑回归是很多机器学习问题的偏好模型
首先,决策树既可以解回归问题,又可以解分类问题,功能强大
其次,决策树能够处理非线性关系,并且可以自动不好特征之间的交互作用
并且,决策树生成的可解释规则是有助于理解模型的决策过程的,即可解释性好
最后,决策树可以处理包括类别型和数值型在内的不同类型的特征
跑通并理解baseline代码
baseline代码基于百度AI Studio的一键运行链接:
https://aistudio.baidu.com/aistudio/projectdetail/6618108?contributionType=1&sUid=1020699&shared=1&ts=1691406191660
baseline的实践步骤
- 导库:导入了
numpy包和pandas包用于数据处理,从python的机器学习库sklearn决策树分类器DecisionTreeClassifier - 读取数据:使用
pandas中的read_csv()函数从文件中读取数据 - 特征工程:
- 定义
udmap_onehot()函数用于独热表示原始数据集中的udmap字段,得到一个长度为9的one-hot vector - 加入
udmap_isunknown字段作为新特征,表示udmap字段取值为unknown的情况 - 提取
eid特征的频次和均值,作为新特征 - 将原始的毫秒计数的时间戳转换为
pandas中的datetime格式,并提取common_ts的小时部分作为新特征
- 定义
- 使用决策树模型进行训练和预测:创建一个
DecisionTreeClassifier实例,使用fit()函数在train_data上训练模型,使用predict()函数用训练好的模型在test_data上做预测,并将预测结果保存到submit.csv文件中
# 导入库
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
# 读取训练集和测试集文件
train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv')
test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv')
# 提取udmap特征,人工进行onehot
def udmap_onethot(d):
v = np.zeros(9)
if d == 'unknown':
return v
d = eval(d) # 将d中的python表达式提取出来,并返回表达式的结果。这里是字典类型变量
for i in range(1, 10):
if 'key' + str(i) in d:
v[i-1] = d['key' + str(i)]
return v # 返回值为onehot向量,不存在的key值为0,否则为对应的key值
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
# 将udmap_onehot函数作用于train_data的udmap列,对该列元素的数据进行独热编码,
# 并利用numpy中的vstack函数将所有数据得到的独热编码行向量压缩为一个二维矩阵
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 编码udmap是否为空,给train_data和test_data的表中新增一列,表示udmap中数据存在与否
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
# udmap特征和原始数据拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
# 将train_data和train_udmap_df两个数据frame进行水平合并
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 提取eid的频次特征
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
# 统计train_data的eid列中每个不同值的出现次数,返回值为一个pandas series,
# 再利用map函数实现在train_data中新增一列记录当前eid在整个数据集中的出现次数
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())
# 提取eid的标签特征
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 在train_data中新增一列用于分析用户行为eid的标签特征,这里的.mean()是针对分组的聚合函数用于求平均值
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 提取时间戳
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
# 对train_data的common_ts列进行了日期时间形式的转换
# 将 Unix 时间戳(以毫秒为单位)转换为 Pandas 的日期时间格式
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
# 提取小时部分进行训练
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
# 加载决策树模型进行训练
clf = DecisionTreeClassifier()
clf.fit(
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), # 删除了不需要的特征
train_data['target']
)
# 对测试集进行预测,将submit.csv在比赛页面提交
pd.DataFrame({
'uuid': test_data['uuid'],
'target': clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1))
}).to_csv('submit.csv', index=None)
模型训练与验证
数据分析与可视化
数据分析与可视化实践
- 导库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
- 读取数据
train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv')
test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv')
- 对训练集数据和测试集数据进行分析
# 数据形状查看
print(train_data.shape)
print(test_data.shape)
# 数据概览
print(train_data.head().append(train_data.tail()))
print(test_data.head().append(test_data.tail()))
# 数据整体信息
print(train_data.info())
print(test_data.info()
# 数据统计信息 train_data和test_data的整体统计信息是差不多的
print(train_data.describe())
print(test_data.describe()))
# 针对object类型
print(train_data['udmap'].describe())
print(test_data['udmap'].describe())
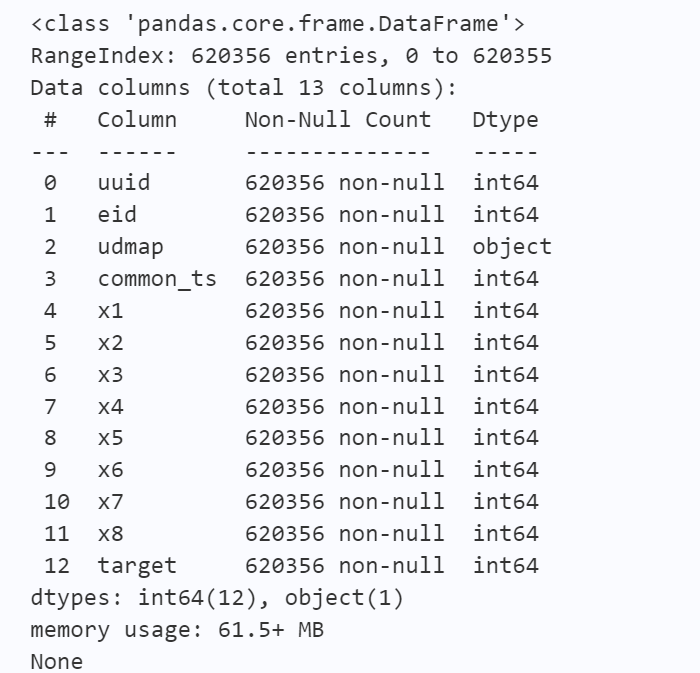
从info()函数得到的结果可以看出,数据集中的13个字段当中有一个object字段,这是需要单独处理的,并且此数据集中没有以NaN为标记的缺失值
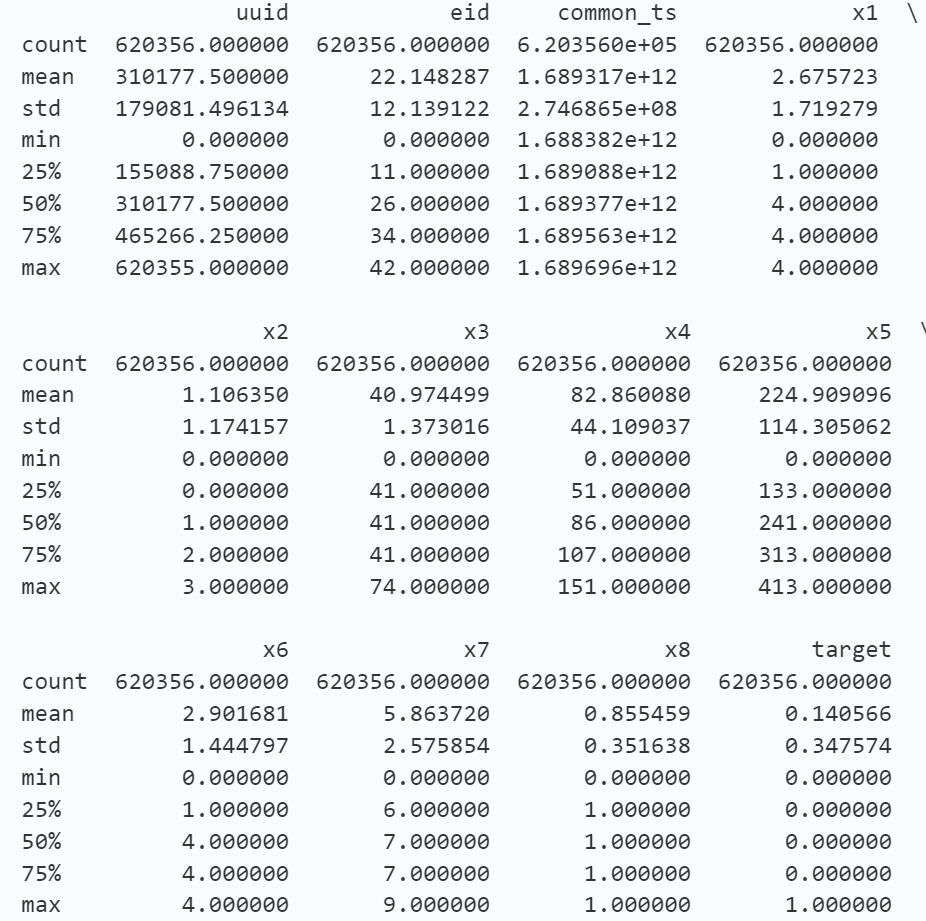
从describe()函数得到的结果来看,在各个字段的均值、方差、最大最小值以及四分位数方面,训练集和测试集都是非常类似的。
由于本数据集中各个字段的值大多是数字,因此难以简单地通过数值来判断变量类型
这里使用各个字段的唯一值数量来判断,根据得到的结果,我这里将x3、x4、x5、key1、key2、key3、key6当作数值型变量来处理,其余的x1、x2、x6、x7、x8、key4、key5、key7、key8、key9作为类别型变量来处理。
按照学习手册中的提示,对数值型变量绘制标签分组下的箱线图,对类别型变量绘制的直方图,展示各个类别的标签均值
print(train_data.nunique())
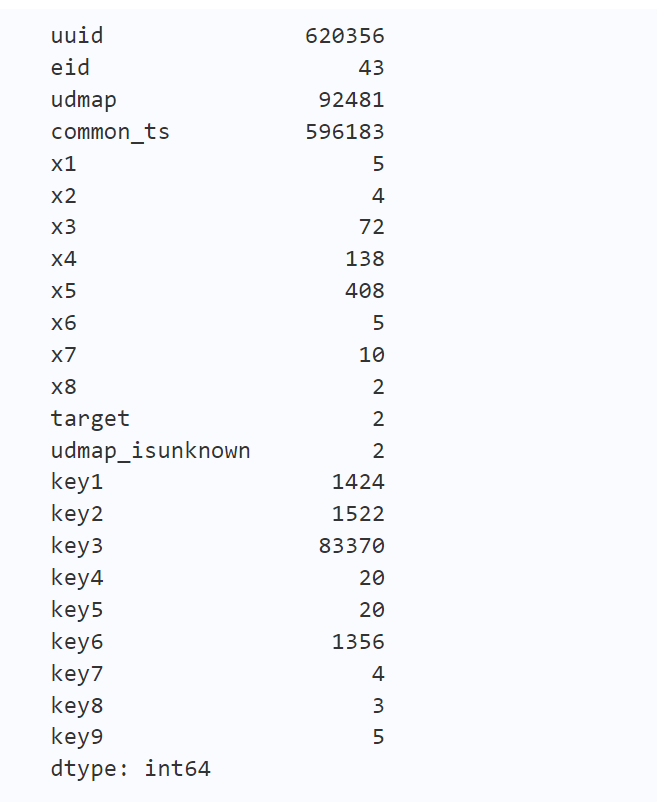
对于x3变量
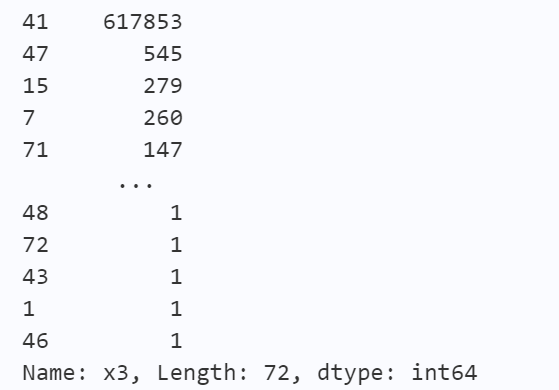
print(train_data['x3'].value_counts())
# value_couns()函数结果显示 此变量的分布极为不均衡 接近30:1的比例, 此字段并不能带来足够的有效信息,故删去
# 尝试绘制x3变量的箱线图
plt.subplot(121)
sns.boxplot(x='target', y='x3', data=train_data)
# 尝试对x3变量进行取对数处理后绘制其箱线图
train_data['log_x3'] = np.log(train_data['x3'])
plt.subplot(122)
sns.boxplot(x='target', y='log_x3', data=train_data)
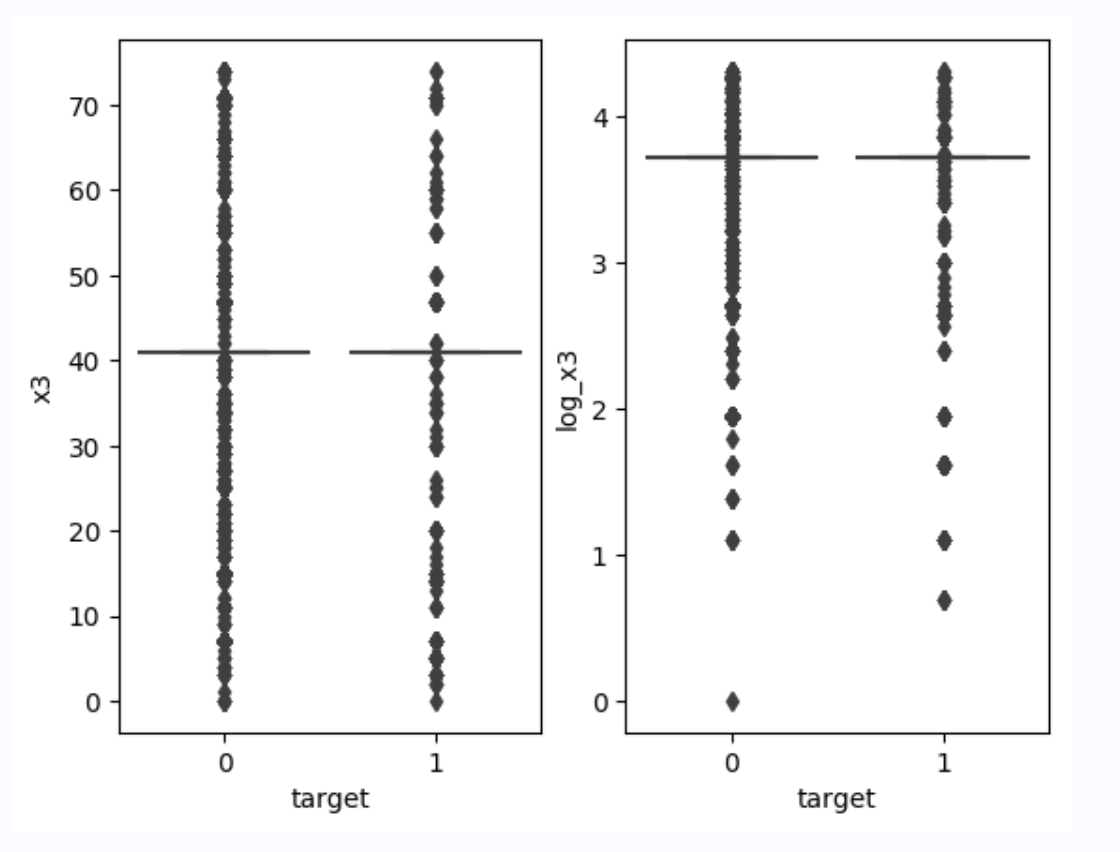
对于x3变量,由于其分布极不均衡,导致很多数据都被判断为了异常值,其箱线图的参考价值不大
# 对train_data中的数值型变量绘制箱线图进行分析
# 绘制x4在标签分组下的箱线图
sns.boxplot(x= 'target', y= 'x4', data=train_data)
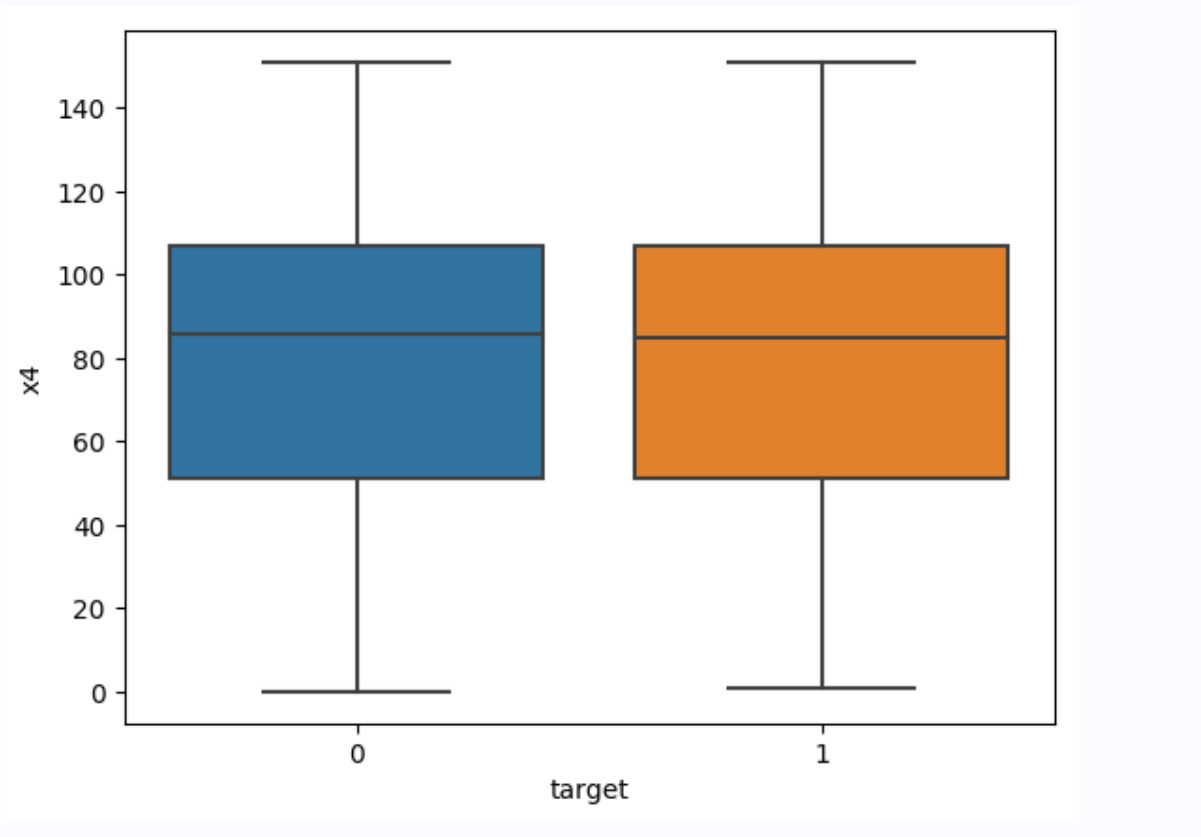
针对x4变量的箱线图,正例和负例在波动范围,x4字段取值平均值都没有太大的差异,因此x4变量的统计信息并没有太大的价值
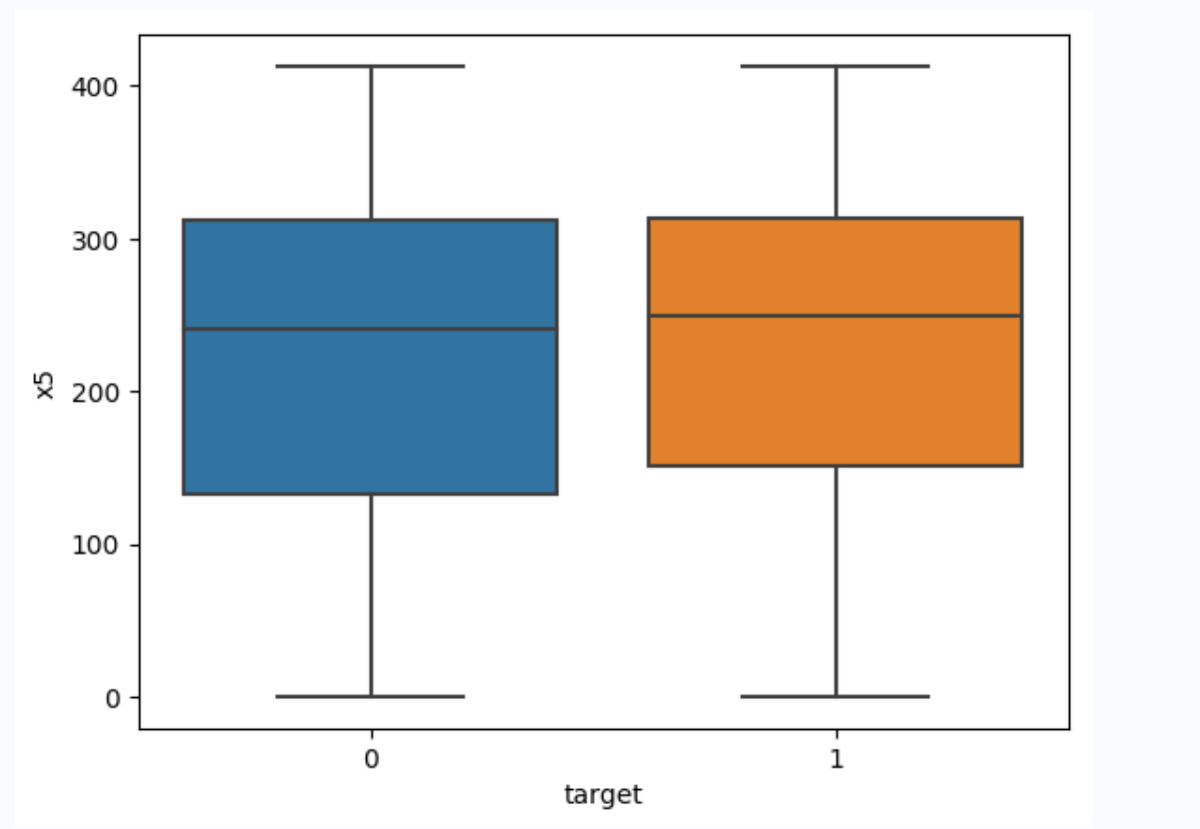
针对x5变量的箱线图,可以看出正例负例在数据均值和波动程度上是有差别的,可以将x5变量的统计信息作为新特征加入train_data进行模型训练
模型交叉验证
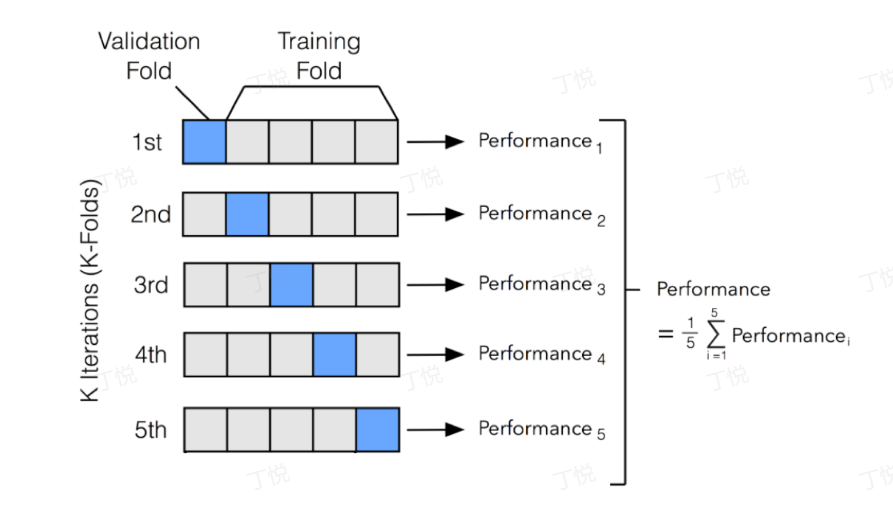
关于交叉验证:将训练数据集划分为多个子集,将模型训练和验证进行多次循环,每一次都将某个子集作为验证集,其他子集一起作为训练集。每次验证会得到一个模型的性能指标,取这些指标的平均值作为最终的模型性能评估结果
这里直接利用sklearn包中的模型交叉验证模块中的cross_val_predict()函数,传入模型,原始训练数据集,原始标签进行训练和交叉验证,使用classification_report()函数得到当前训练模型的交叉验证报告
# 训练并验证DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
# 导入交叉验证和评价指标
from sklearn.model_selection import cross_val_predict from sklearn.metrics import classification_report
# 训练并验证
DecisionTreeClassifier pred =
cross_val_predict( DecisionTreeClassifier(), train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), train_data['target'] ) print(classification_report(train_data['target'], pred, digits=3))
得到的初始验证结果如下
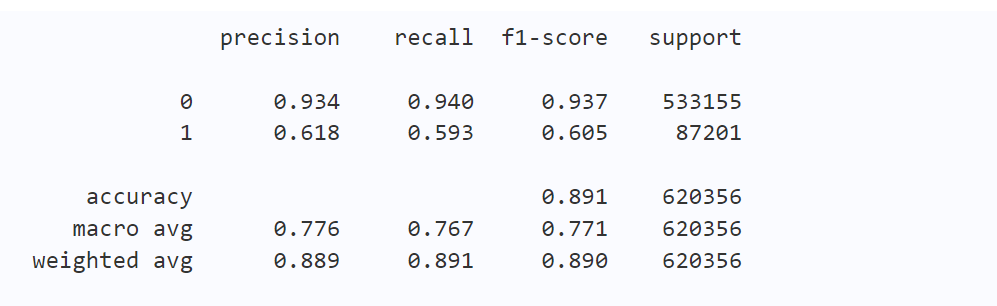
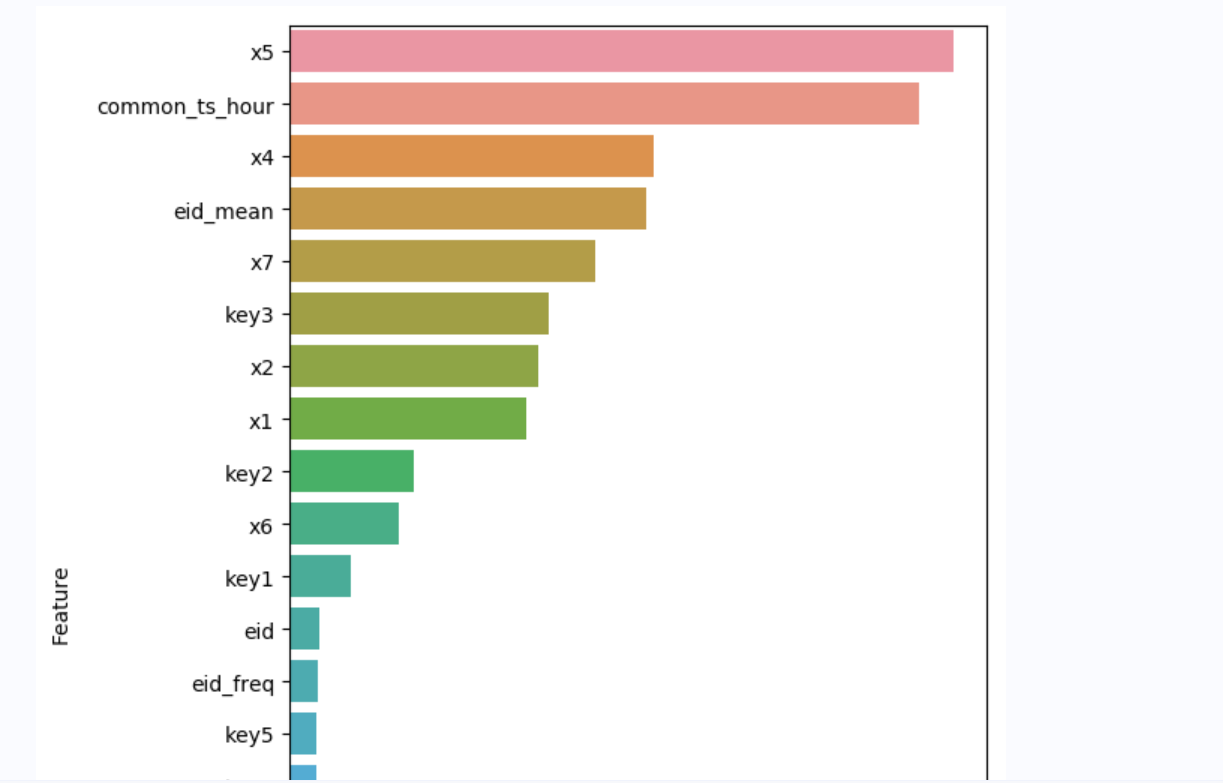
树模型的特征重要性可视化如下
特征工程
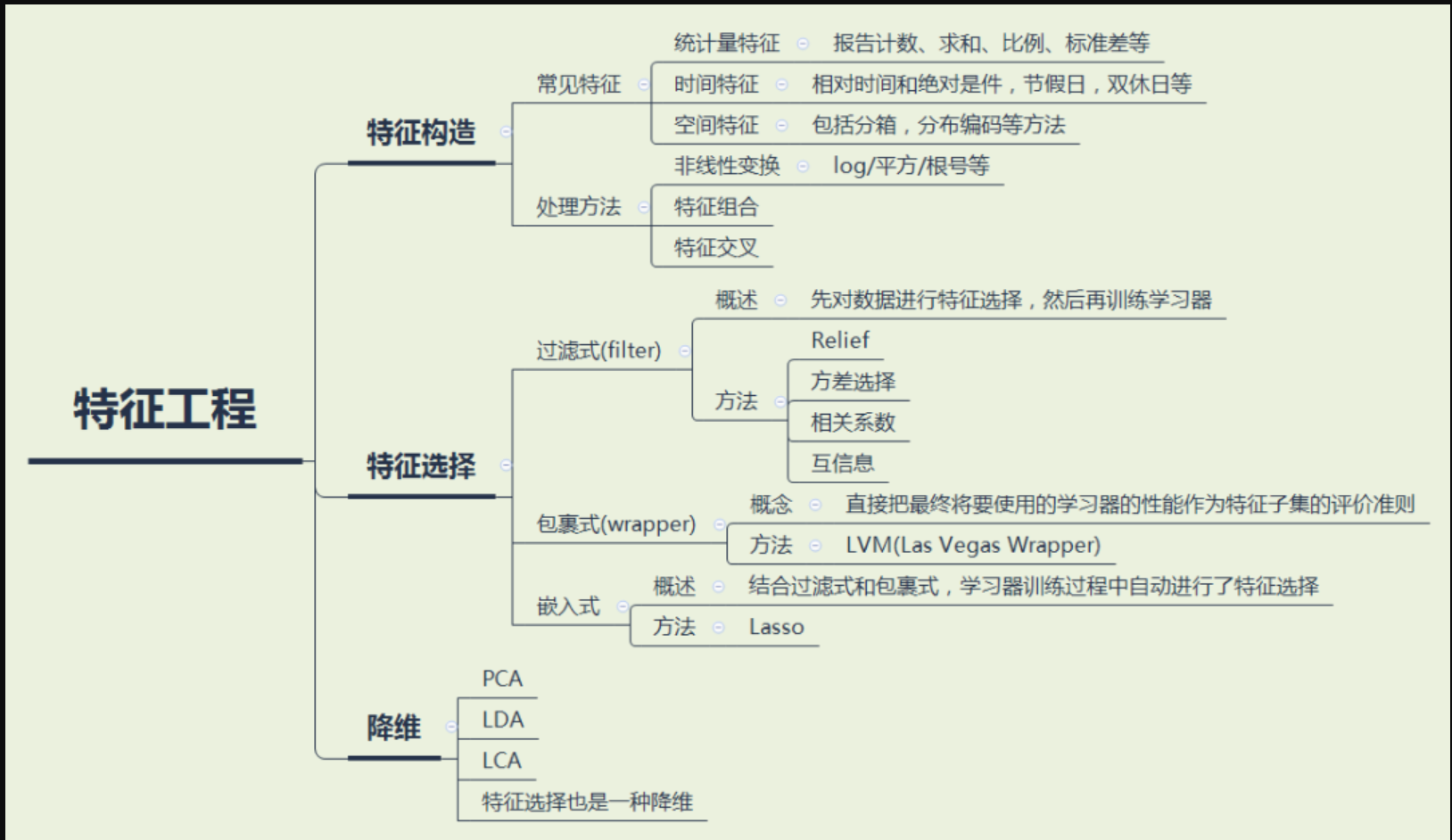
特征工程是什么?
将原始的数据转变为模型训练数据的过程,在这个过程中,机器学习算法工程师需要做的是将有利于模型训练的特征提取出来作为训练数据的新增字段
特征工程包括
- 特征构造
- 特征选择
- 降维
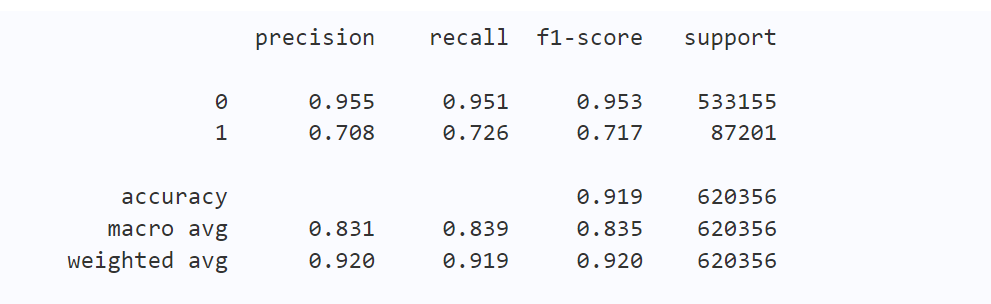
按照学习手册中给的实操步骤,这里将common_ts_day、x1到x8的频次和均值都作为新特征加入训练,得到的训练结果如下。可以看出,加入这些特征后,模型在验证集上的f1-score有了明显提升
模型迭代优化
在datawhale的学习手册中提到模型迭代优化包括但不限于
- 特征选择与删除
- 特征组合与交互
- 数值型特征的分桶
- 类别型特征的编码
- 时间特征的挖掘
- 特征缩放















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









