








如

结构体的定义方式和变量以及数组的定义方式相同,只是不能初始化
需要注意的是,大括号后面的分号不能省,因为这是一条完整的语句
结构体也是一种数据类型,它由程序员自己定义,可以包含多个其他类型的数据。像 char、int、float 等是由C语言本身提供的数据类型,不能再进行分拆,我们称之为基本数据类型;而结构体可以包含多个基本类型的数据,也可以包含其他的结构体,我们将它称为复杂数据类型或构造数据类型。

它定义了两个变量 stu1 和 stu2,它们都是 stu 类型,都由 5 个成员组成。注意关键字 struct 不能少。stu 就像一个“模板”,定义出来的变量都具有相同的性质。也可以将结构体比作“图纸”,将结构体变量比作“零件”,根据同一张图纸生产出来的零件的特性都是一样的。
你也可以在定义结构体的同时定义结构体变量,只需将结构体变量放在结构体定义的最后即可:
你也可以在定义结构体的同时定义结构体变量,只需将结构体变量放在结构体定义的最后即可:
struct stu {
char *name; //姓名
int num; //学号
int age; //年龄
char group; //小组
float score; //成绩
} stu1, stu2;
如果只需要 stu1、stu2 两个变量,后面不需要再使用结构体名定义其他变量,那么在定义时也可以不给出结构体名:
struct {
char *name; //姓名
int num; //学号
int age; //年龄
char group; //小组
float score; //成绩
} stu1, stu2;
这样做书写简单,但是因为没有结构体名,后面就没法用该结构体定义新的变量。
理论上讲结构体的各个成员在内存中是连续存储的,和数组非常类似,例如,结构体变量 stu1、stu2 的内存分布就是这样的:

共占用 17 个字节。
但是在编译器的具体实现中,各个成员之间可能会存在缝隙,对于 stu1、stu2,成员变量 group 和 score 之间就存在 3 个字节的空白填充,这样算来,stu1、stu2 其实占用了 20 个字节。

关于成员变量之间存在“裂缝”的原因,是因为 C 语言将内存对齐,能提高寻址效率。
以上为结构体的定义,接下来我们讲结构体如何使用。结构体和数组类似,也是一组数据的集合,整体使用没有太大的意义。数组使用 [] 获取单个元素,一般格式为:
arrayName[index];
结构体使用 . 获取单个成员。获取结构体成员的一般格式为:
sturctName.memberName;
通过这种方式可以获取成员的值,也可以给成员赋值。
例如这段代码:
#include <stdio.h>
int main () {
struct {
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1;
/* 给结构体变量赋值 */
stu1.name = "Tom";
stu1.num = 12;
stu1.age = 18;
stu1.group = 'A';
stu1.score = 136.5;
/* 读取结构体成员的值 */
printf("%s的学号是%d,年龄是%d,在%c组,今年的成绩是%.1f!\n", stu1.name, stu1.num, stu1.age, stu1.group, stu1.score);
return 0;
}
它能给结构体变量 stu1 的成员赋值,并读取出结构体成员的值。运行这段代码,屏幕输出为:
Tom的学号是12,年龄是18,在A组,今年的成绩是136.5!
除了可以对成员进行逐一赋值,也可以在定义时整体赋值,例如这段代码
#include <stdio.h>
int main () {
struct {
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1, stu2 = {"Tom", 12, 18, 'A', 126};
/* 给结构体变量赋值 */
stu1.name = "Tom";
stu1.num = 12;
stu1.age = 18;
stu1.group = 'A';
stu1.score = 136.5;
/* 读取结构体成员的值 */
printf("%s的学号是%d,年龄是%d,在%c组,今年的成绩是%.1f!\n", stu1.name, stu1.num, stu1.age, stu1.group, stu1.score);
return 0;
}
不过整体赋值仅限于定义结构体变量的时候,在使用过程中只能对成员逐一赋值,这和数组的赋值非常类似。需要注意的是,结构体是一种自定义的数据类型,是创建变量的模板,不占用内存空间;结构体变量才包含了实实在在的数据,需要内存空间来存储。
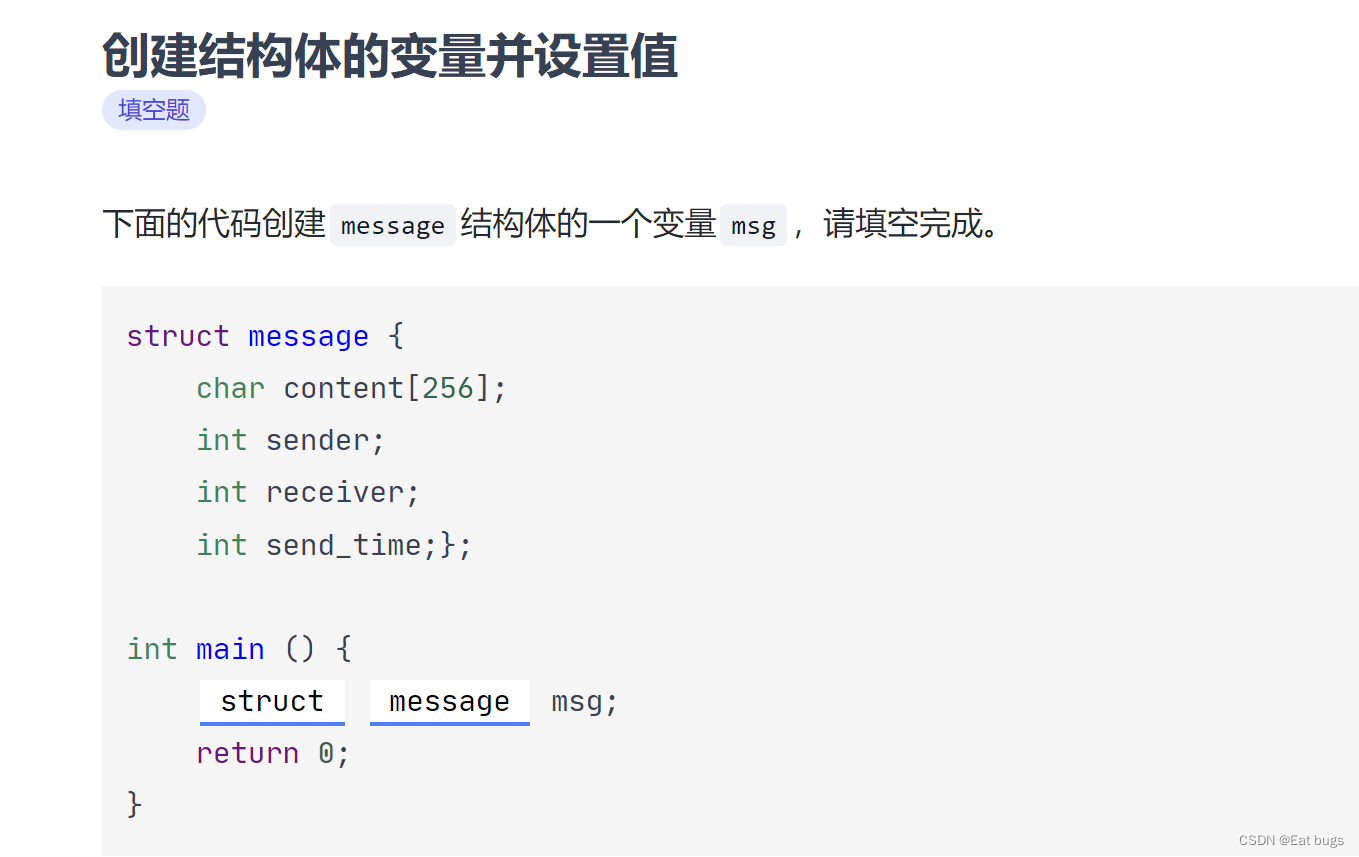
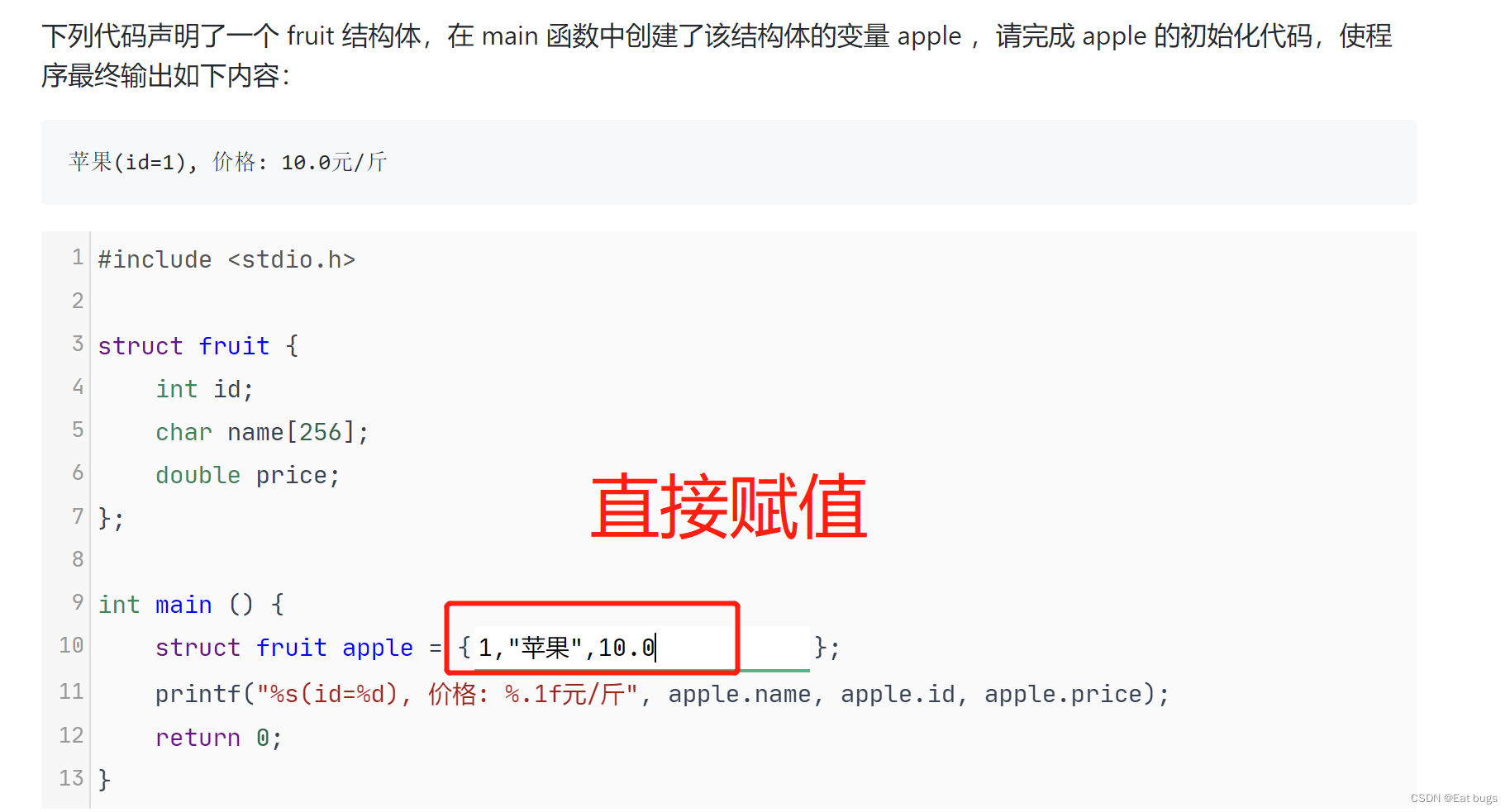
赋值样例
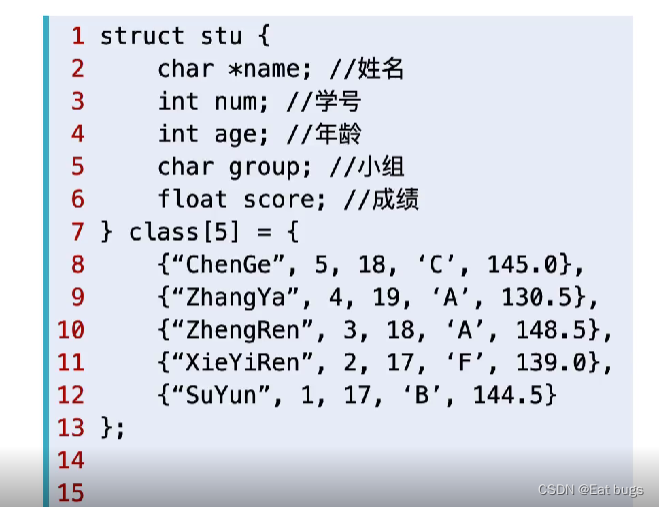
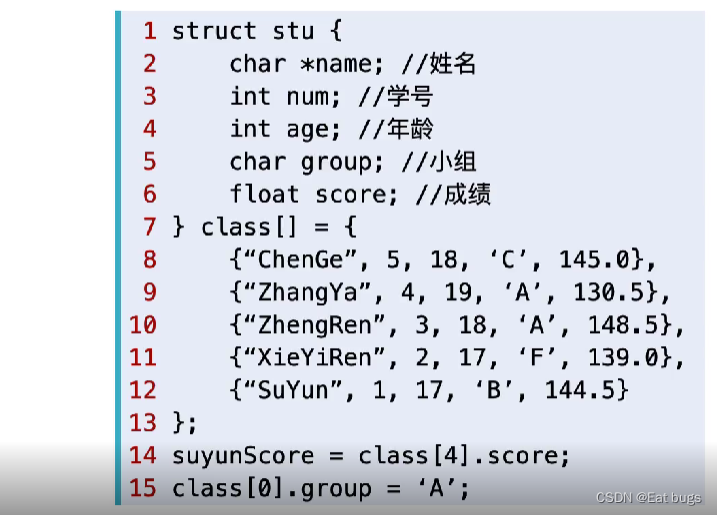
结构体数组的使用也很简单,例如,可以通过 class[4].score; 获取 SuYun 的成绩;可以通过 class[0].group = ‘A’; 修改 ChenGe 的学习小组。
结构体指针

当一个指针变量指向结构体时,我们就称它为结构体指针。C语言结构体指针的定义形式一般为:
struct 结构体名 *变量名;这段代码就是定义结构体指针的实例:
/* 结构体 */
struct stu {
char *name; //姓名
int num; //学号
int age; //年龄
char group; //小组
float score; //成绩
} stu1 = {"Tom", 12, 18, 'A', 136};
/* 结构体指针 */
struct stu *pstu = &stu1;
同样,你也可以在定义结构体的同时定义结构体指针:
/* 结构体 */
struct stu {
char *name; //姓名
int num; //学号
int age; //年龄
char group; //小组
float score; //成绩
} stu1 = {"Tom", 12, 18, 'A', 136}, *pstu = &stu1;
注意,结构体变量名和数组名不同,数组名在表达式中会被转换为数组指针,而结构体变量名不会,无论在任何表达式中它表示的都是整个集合本身,要想取得结构体变量的地址,必须在前面加 &,所以给 pstu 赋值只能写作:
struct stu *pstu = &stu1;
而不能写作:
struct stu *pstu = stu1;
还应该注意,结构体和结构体变量是两个不同的概念:结构体是一种数据类型,是一种创建变量的模板,编译器不会为它分配内存空间,就像 int、float、char 这些关键字本身不占用内存一样;结构体变量才包含实实在在的数据,才需要内存来存储。
所以,这两行代码是错误的:
struct stu *pstu = &stu;
struct stu *pstu = stu;

因为不可能去取一个结构体名的地址,也不能将它赋值给其他变量。
通过结构体指针可以获取结构体成员,一般形式为:
(*pointer).memberName;
或者:
pointer->memberName;
第一种写法中,.的优先级高于*,(*pointer)两边的括号不能少。如果去掉括号写作*pointer.memberName,那么就等效于*(pointer.memberName),这样意义就完全不对了。
第二种写法中,->是一个新的运算符,习惯称它为“箭头”,有了它,就可以通过结构体指针直接取得结构体成员;这也是 -> 在 C 语言中的唯一用途。这两种写法是等效的,但我们通常采用第二种写法,这样更加直观。
例如这段代码:
#include <stdio.h>
int main () {
struct {
char *name; //姓名
int num; //学号
int age; //年龄
char group; //所在小组
float score; //成绩
} stu1 = {"Tom", 12, 18, 'A', 136.5}, *pstu = &stu1;
/* 读取结构体成员的值 */
printf("%s的学号是%d,年龄是%d,在%c组,今年的成绩是%.1f!\n",(*pstu).name,(*pstu).num,(*pstu).age,(*pstu).group,(*pstu).score);
printf("%s的学号是%d,年龄是%d,在%c组,今年的成绩是%.1f!\n", pstu->name, pstu->num, pstu->age, pstu->group, pstu->score);
return 0;
}

运行这段程序,可以发现,输出的两行内容是一样的。
如果将结构体作为函数参数传递,结构体变量名代表的是整个集合本身,作为函数参数时传递的整个集合,也就是所有成员,而不是像数组一样被编译器转换成一个指针。
如果结构体成员较多,尤其是成员为数组时,传送的时间和空间开销会很大,影响程序的运行效率。所以最好的办法就是使用结构体指针,这时由实参传向形参的只是一个地址,非常快速。
例如这段代码:
#include <stdio.h>
struct stu {
char *name; //姓名
int num; //学号
int age; //年龄
char group; //小组
float score; //成绩
} stus[] = {
{"ChenGe", 5, 18, 'C', 145.0},
{"ZhangYa", 4, 19, 'A', 130.5},
{"ZhengRen", 3, 18, 'A', 148.5},
{"XieYiRen", 2, 17, 'F', 139.0},
{"SuYun", 1, 17, 'B', 144.5}
};
void average (struct stu *ps, int len);
int main () {
int len = sizeof(stus) / sizeof(struct stu);
average(stus, len);
return 0;
}
void average (struct stu *ps, int len) {
int i, num_140 = 0;
float average, sum = 0;
for (i=0; i<len; i++) {
sum += (ps + i) -> score;
if ((ps + i) -> score < 140) num_140++;
}
printf("sum=%.2f\naverage=%.2f\nnum_140=%d\n", sum, sum/5, num_140);
}
它将计算全班学生的总成绩、平均成绩 以及 成绩在 140 分以下的人数。
结构体变量构成链表
这一节,我们讲《结构体变量构成链表》。
之前我们使用数组存放数据时,必须事先定义固定的数组长度,如果有的班级有 100 个人,有个班级有 50 个人,若用同一个数组先后存放不同班级的学生数据,就必须定义长度为 100 的数组。那如果事先很难确定哪个班的人数最多,就必须把数组长度定义的足够大才行,这样显然很浪费内存。为了解决这个问题,C语言的开发者们设计了链表。
链表也是一种数据类型,它能动态的进行存储分配。也就是说,它能根据需要开辟内存单元。一个链表就像一条铁链一样,一环扣一环,中间不能断开。
一条铁链有链首,链表也是这样,它也有一个链首,它保存一个地址,这个地址就是链表的起始地址,通过链表的起始地址,我们访问到链表的第一元素,这个元素,称为链表的结点,之后的每一个链表的元素都称为链表的结点,每一个结点都有不同的地址。每个结点都分为两部分,一部分用来保存用户需要用到的实际数据,可以称它为数据域,另一部分用来保存访问下一个节点的地址,可以称它为地址域。链表中的结点一个连着一个,直到最后一个结点,该结点不再指向其他元素,它称为表尾,它的地址域放一个空地址,链表到此结束。
需要注意的是,链表中各个元素在内存中的地址可以是不连续的。因为要找某个结点,只能先找到它的上一个结点,通过上一个结点提供的地址才能找到下一个结点,因此,只能通过这个起始地址,才能访问链表,否则,将无法访问整个链表。
因为一个结点即包含用户需要的数据,又包含下一个结点的地址,因此,用结构体变量创建链表是最合适的。
例如这个结构体:
#include <stdio.h>
struct Student {
int num;
float score;
struct Student * next;
};
其中,num 保存学生的学号,socre 保存学生的成绩,next 是指针类型的成员,它指向 struct Student 类型数据。因为 next 是 struct Student 类型的成员,它又指向 struct Student 类型的数据,因此构成了链表。
需要注意的是,这只是定义了一个 struct Student 类型,并未分配存储空间,只有定义了变量才分配存储单元。
也就是说,需要先给 struct Student 类型定义变量:
struct Student a, b, c, *head;
a.num = 1; a.score = 89.5;
b.num = 2; b.score = 90;
c.num = 3; c.score = 85;
然后将它们一环一环连起来:
head = &a;
a.next = &b;
b.next = &c;
c.next = NULL;
这样就构成了一个链表。其中,head 是链表的首地址。
类似这种所有结点都是在程序中定义,不是临时开辟,也不能用完后释放的链表,称为“静态链表”。与之对应的是“动态链表”。所谓动态链表,就是指在程序执行过程中,从无到有的建立一个链表,即一个一个的开辟结点和输入各结点数据,并建立前后相链的关系。
例如这段程序:
#include <stdio.h>
#include <stdlib.h>
struct Student {
int num; /* 学号 */
float score; /* 成绩 */
struct Student * next;/*地址*/
};
int main () {
struct Student *head, *p1, *p2;
int n = 0;
p1 = p2 = (struct Student)malloc(sizeof(struct Student));
scanf("%d %f", &p1->num, &p1->score);
head = NULL;
while (p1->num != 0) {
n = n + 1;
if (n == 1) head = p1;
else p2->next = p1;
p2 = p1;
p1 = (struct Student)malloc(sizeof(struct Student));
scanf("%d %f", &p1->num, &p1->score);
}
p2->next = NULL;
return 0
}
因为要动态开辟结点,所以定义两个结构体指针变量 p1 和 p2 来保存动态分配的内存,这样,就能使用 scanf() 读取数据保存到 结点 p1 中。然后判断是否是起始地址,如果是起始地址,就将第一个结点的地址保存到 head 中,否则,将 p1 的地址保存 p2 的 next 中,然后将 p1 的其他的数据保存到 p2 中,接着就可以重新开辟一个结点,用来保存新输入的学生信息。一直循环,直到输入为 0 时,结束循环,然后让 p2 的 next 指向 NULL,结束链表。如此,动态链表就创建好了。head 是链表的起始地址。
链表创建好了,那如何将各个链表结点中的数据输出呢?
输出相对比较简单,例如这段程序:
#include <stdio.h>
struct Student {
int num; /* 学号 */
float score; /* 成绩 */
struct Student * next;/*地址*/
};
void print_link (struct Student * head) {
struct Student * p;
p = head;
if (head != NULL) {
do {
printf("%d %5.1f\n", p->num, p->score);
p = p->next;
} while (p != NULL);
}
}
新建一个输出链表的函数 print_link(),并将链表的首地址传给它,如果起始地址不为空,那么第一个结点的数据可以直接输出,然后将下一个结点的地址取出,再循环打印即可,直到最后一个结点为空的时候停止。
链表是一个比较深入的内容,如果你想成为计算机专业领域人员,就必须掌握这部分内容。















 124
124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









