







目录
直接内存深入辨析
在所有的网络通信和应用程序中,每个 TCP 的 Socket 的内核中都有一个发送缓冲区(SO_SNDBUF)和一个接收缓冲区(SO_RECVBUF),可以使用相关套接字选项来更改该缓冲区大小。
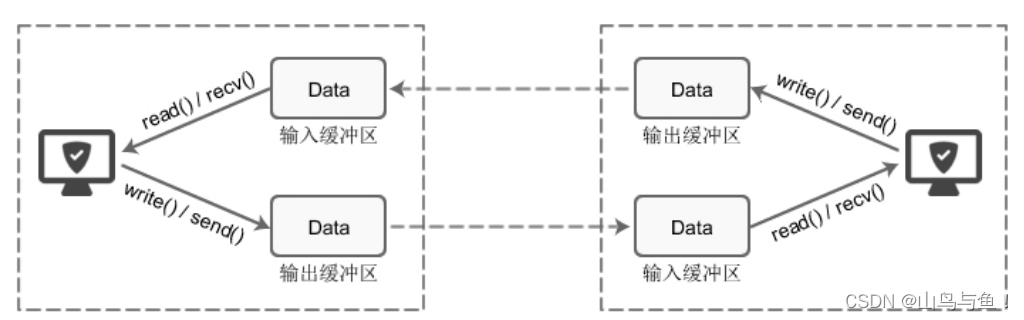
当某个应用进程调用 write 时,内核从该应用进程的缓冲区中复制所有数据到所写套接字的发送缓冲区。如果该套接字的发送缓冲区容不下该应用进程的所有数据(或是应用进程的缓冲区大于套接字的发送缓冲区,或是套接字的发送缓冲区中已有其他数据),假设该套接字是阻塞的,则该应用进程将被投入睡眠。
内核将不从 write 系统调用返回,直到应用进程缓冲区中的所有数据都复制到套接字发送缓冲区。因此,从写一个 TCP 套接字的 write 调用成功返回仅仅表示我们可以重新使用原来的应用进程缓冲区,并不表明对端的TCP或应用进程已接收到数据。
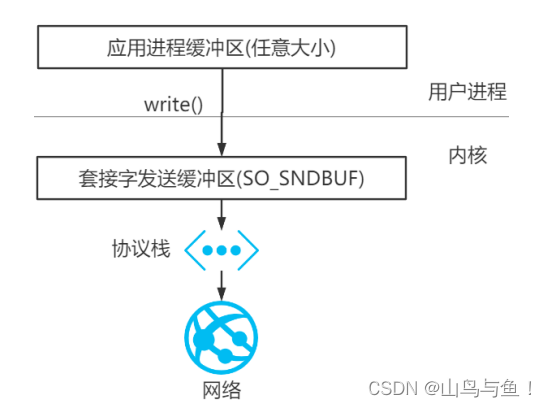
Java 程序自然也要遵守上述的规则。但在 Java 中存在着堆、垃圾回收等特性,所以在实际的IO中,在 JVM 内部的存在着这样一种机制:
在IO读写上,如果是使用堆内存,JDK 会先创建一个 DirectBuffer,再去执行真正的写操作。这是因为,当我们把一个地址通过 JNI 传递给底层的C库的时候,有一个基本的要求,就是这个地址上的内容不能失效。然而,在 GC 管理下的对象是会在 Java 堆中移动的。也就是说,有可能我把一个地址传给底层的 write,但是这段内存却因为GC整理内存而失效了。所以必须要把待发送的数据放到一个 GC 管不着的地方。这就是调用 native 方法之前,数据—定要在堆外内存的原因。
站在网络通信的角度 DirectBuffer 并没有节省什么内存拷贝,只是Java网络通信里因为HeapBuffer必须多做一次拷贝,使用 DirectBuffer 就会少一次内存拷贝。相比没有使用堆内存的 Java程序,使用直接内存的Java程序当然更快一点。从垃圾回收的角度而言,直接内存不受 GC(新生代的 Minor GC) 影响,只有当执行老年代的Full GC时候才会顺便回收直接内存,整理内存的压力也比数据放到HeapBuffer要小。
堆外内存的优点和缺点
优点:
1. 减少了垃圾回收的工作,因为垃圾回收会暂停其他的工作(可能使用多线程或者时间片的方式,根本感觉不到)
2. 加快了复制的速度。因为堆内在 flush 到远程时,会先复制到直接内存(非堆内存),然后在发送,而堆外内存相当于省略掉了这个工作。
缺点:
1. 堆外内存难以控制,如果内存泄漏,那么很难排查。
2. 堆外内存相对来说,不适合存储很复杂的对象。一般简单的对象或者扁平化的比较适合。
零拷贝
什么是零拷贝?
零拷贝(英语: Zero-copy) 技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省 CPU 周期和内存带宽。零拷贝技术可以减少数据拷贝和共享总线操作的次数,消除传输数据在存储器之间不必要的中间拷贝次数,从而有效地提高数据传输效率。零拷贝技术减少了用户进程地址空间和内核地址空间之间因为上下文切换而带来的开销可以看出没有说不需要拷贝,只是说减少不必要的拷贝。
Linux的I/O机制与DMA
早期计算机中,用户进程需要读取磁盘数据,需要 CPU 中断和 CPU 参与,因此效率比较低,发起 IO 请求,每次的 IO 中断,都带来 CPU 的上下文切换。因此出现了——DMA。
DMA(Direct Memory Access,直接内存存取) 是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依赖于CPU的大量中断负载。
DMA 控制器,接管了数据读写请求,减少 CPU 的负担。这样一来,CPU能高效工作了。现代硬盘基本都支持DMA。
传统数据传送机制
比如:读取文件,再用 socket 发送出去,实际经过四次 copy。伪码实现如下: buffer = File.read() Socket.send(buffer)
第一次:将磁盘文件,读取到操作系统内核缓冲区。
第二次:将内核缓冲区的数据,copy 到应用程序的 buffer。
第三步:将 application 应用程序 buffer 中的数据,copy 到 socket 网络发送缓冲区(属于操作系统内核的缓冲区)。
第四次:将 socket buffer 的数据,copy到网卡,由网卡进行网络传输。
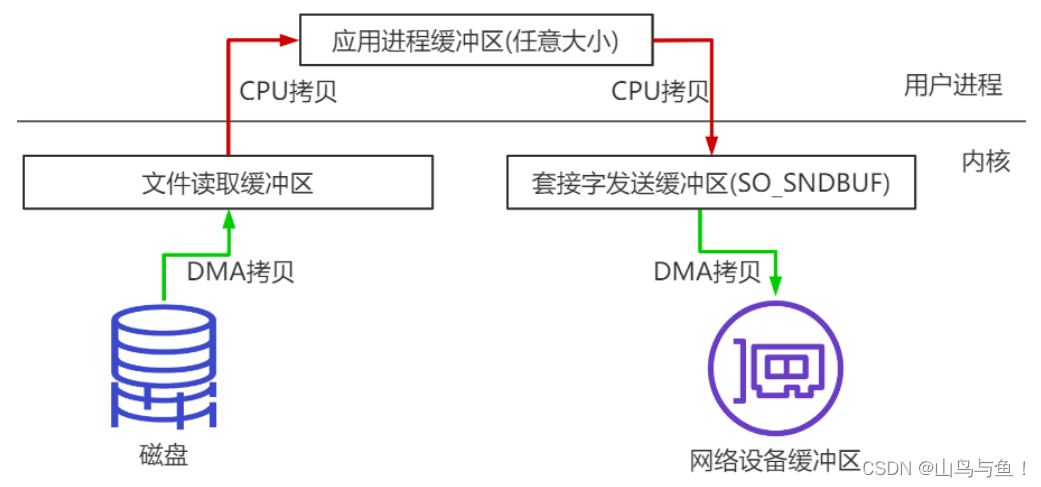
分析上述的过程,虽然引入 DMA 来接管 CPU 的中断请求,但四次 copy 是存在“不必要的拷贝”的。实际上并不需要第二个和第三个数据副本。应用程序除了缓存数据并将其传输回套接字缓冲区之外什么都不做。相反,数据可以直接从读缓冲区传输到套接字缓冲区。第二次和第三次数据 copy其实在这种场景下没有什么帮助反而带来开销,这也正是零拷贝出现的背景和意义。
同时,read 和 send 都属于系统调用,每次调用都牵涉到两次上下文切换:
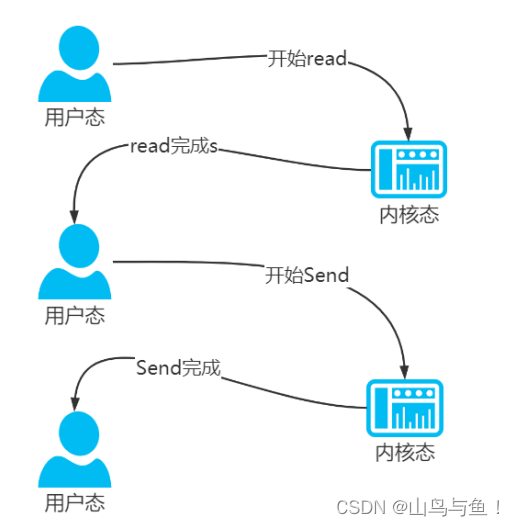
传统的数据传送所消耗的成本:4 次拷贝,4 次上下文切换。4 次拷贝,其中两次是DMA copy,两次是 CPU copy。
Linux支持的零拷贝
mmap内存映射
硬盘上文件的位置和应用程序缓冲区(application buffers)进行映射(建立一种一一对应关系),由于 mmap()将文件直接映射到用户空间,所以实际文件读取时根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了一次数据拷贝,不再有文件内容从硬盘拷贝到内核空间的一个缓冲区。
mmap内存映射将会经历:3次拷贝: 1次 cpu copy,2次DMA copy,以及4次上下文切换,调用mmap函数2次,write函数2次。

sendfile
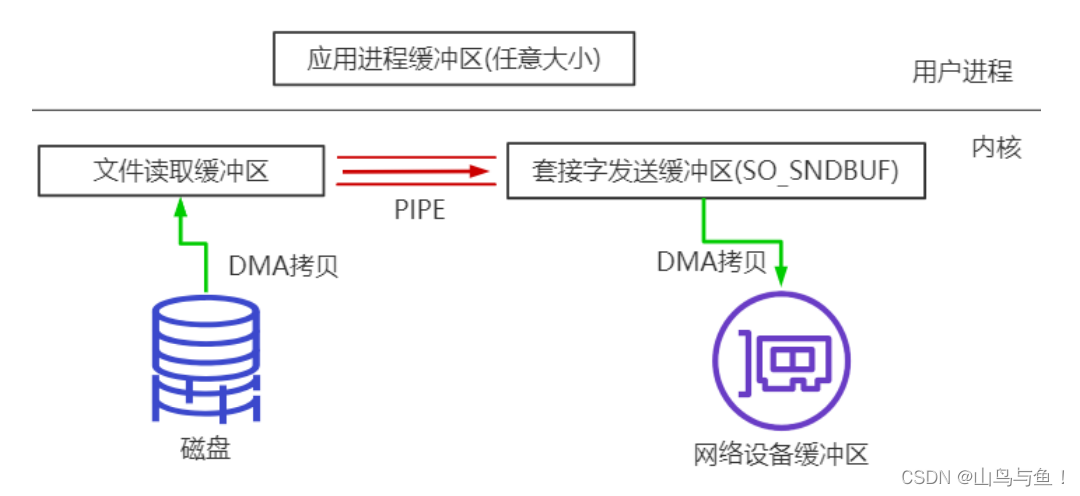
linux 2.1 支持的 sendfile,当调用 sendfile()时,DMA将磁盘数据复制到kernel buffer,然后将内核中的 kernel buffer 直接拷贝到 socket buffer。但是数据并未被真正复制到 socket关联的缓冲区内。取而代之的是,只有记录数据位置和长度的描述符被加入到 socket 缓冲区中。DMA 模块将数据直接从内核缓冲区传递给协议引擎,从而消除了遗留的最后一次复制。但是要注意,这个需要 DMA 硬件设备支持,如果不支持,CPU 就必须介入进行拷贝。
一旦数据全都拷贝到 socket buffer,sendfile()系统调用将会 return、代表数据转化的完成。socket buffer里的数据就能在网络传输了。sendfile 会经历:3(2,如果硬件设备支持)次拷贝,1(0,,如果硬件设备支持)次 CPU copy, 2 次 DMA copy,以及 2 次上下文切换。

splice
Linux 从 2.6.17 支持splice数据从磁盘读取到OS内核缓冲区后,在内核缓冲区直接可将其转成内核空间其他数据 buffer,而不需要拷贝到用户空间。
从磁盘读取到内核 buffer 后,在内核空间直接与socket buffer建立pipe管道。和sendfile()不同的是,splice()不需要硬件支持。
注意splice和sendfile的不同,sendfile是DMA硬件设备不支持的情况下将磁盘数据加载到 kernel buffer后,需要一次CPU copy,拷贝到socket buffer。而splice是更进一步,连这个CPU copy也不需要了,直接将两个内核空间的buffer进行pipe。
splice会经历2次拷贝: 0 次 cpu copy 2 次 DMA copy,以及2次上下文切换。
Java生态圈中的零拷贝
Linux提供的零拷贝技术Java并不是全支持,支持 2 种(内存映射 mmap、sendfile)。
NIO提供的内存映射MappedByteBuffer
NIO中的FileChannel.map()方法其实就是采用了操作系统中的内存映射方式,底层就是调用 Linux mmap()实现的。将内核缓冲区的内存和用户缓冲区的内存做了一个地址映射。这种方式适合读取大文件, 同时也能对文件内容进行更改,但是如果其后要通过SocketChannel发送,还是需要CPU进行数据的拷贝。
NIO提供的sendfile
Java NIO 中提供的 FileChannel 拥有 transferTo 和 transferFrom 两个方法,可直接把 FileChannel 中的数据拷贝到另外一个 Channel,或者直接把另外一个 Channel 中的数据拷贝到 FileChannel。该接口常被用于高效的网络/文件的数据传输和大文件拷贝。在操作系统支持的情况下,通过该方法传输数据并不需要将源数据从内核态拷贝到用户态,再从用户态拷贝到目标通道的内核态,同时也避免了两次用户态和内核态间的上下文切换,也即使用了“零拷贝”,所以其性能一般高于Java IO中提供的方法。
Kafka中的零拷贝
Kafka两个重要过程都使用了零拷贝技术,且都是操作系统层面的狭义零拷贝,一是Producer生产的数据存到broker,二是Consumer从broker读取数据。
Producer生产的数据持久化到broker,broker里采用mmap文件映射,实现顺序的快速写入。
Customer从broker读取数据,broker里采用sendfile,将磁盘文件读到 OS 内核缓冲区后,直接转到socket buffer进行网络发送。














 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









