






这周的主要工作是对之前微调好的大模型的模型量化和部署
TurboMind是LMDeploy团队开发的一款关于LLM推理的高效推理引擎,它的主要功能包括:LLaMa 结构模型的支持,continuous batch 推理模式和可扩展的 KV 缓存管理器
TurboMind推理引擎仅支持推理TurboMind格式的模型。因此,TurboMind在推理HF格式的模型时,会首先自动将HF格式模型转换为TurboMind格式的模型
使用W4A16量化

命令中 w_bits 表示量化的位数,w_group_size 表示量化分组统计的尺寸,work_dir 是量化后模型输出的位置。这里需要特别说明的是,因为没有 torch.int4,所以实际存储时,8个 4bit 权重会被打包到一个 int32 值中
使用KV cache量化
第一步:

在这个命令行中,会选择 128 条输入样本,每条样本长度为 2048,数据集选择 C4,输入模型后就会得到上面的各种统计值
第二步:
通过 minmax 获取量化参数。主要就是利用下面这个公式,获取每一层的 K V 中心值(zp)和缩放值(scale)
zp = (min+max) / 2
scale = (max-min) / 255
quant: q = round( (f-zp) / scale)
dequant: f = q * scale + zp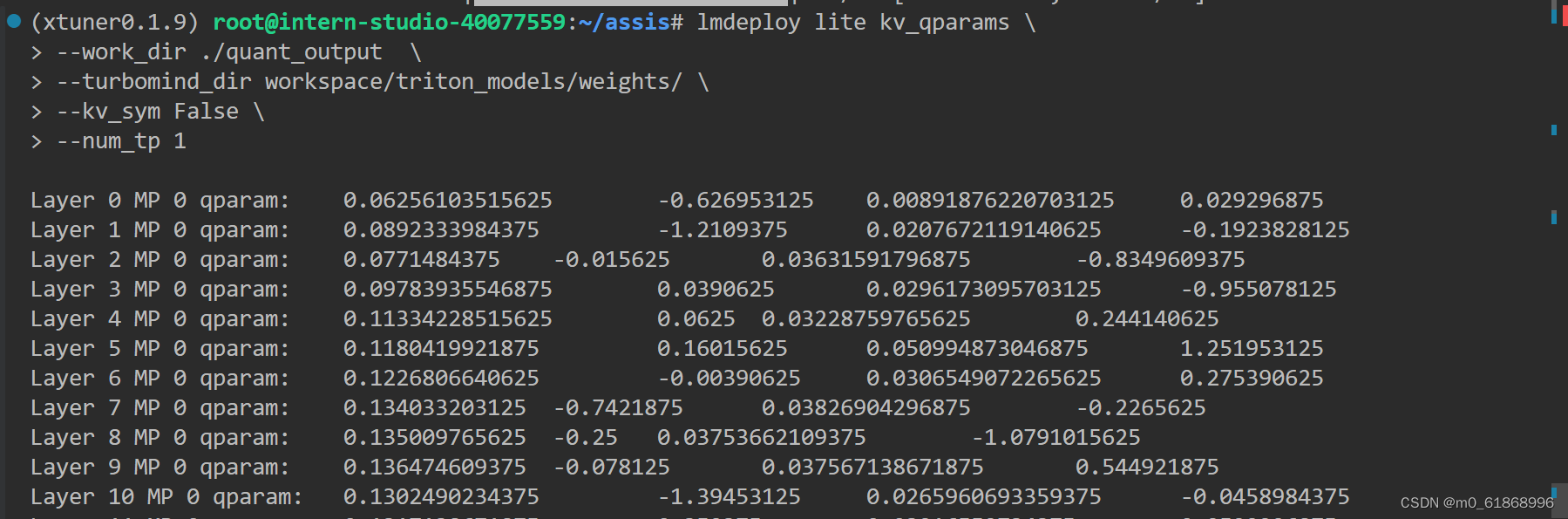
在这个命令中,num_tp 表示 Tensor 的并行数。每一层的中心值和缩放值会存储到 workspace 的参数目录中以便后续使用.
第三步:
修改配置,修改 weights/config.ini 文件,把 quant_policy 改为 4
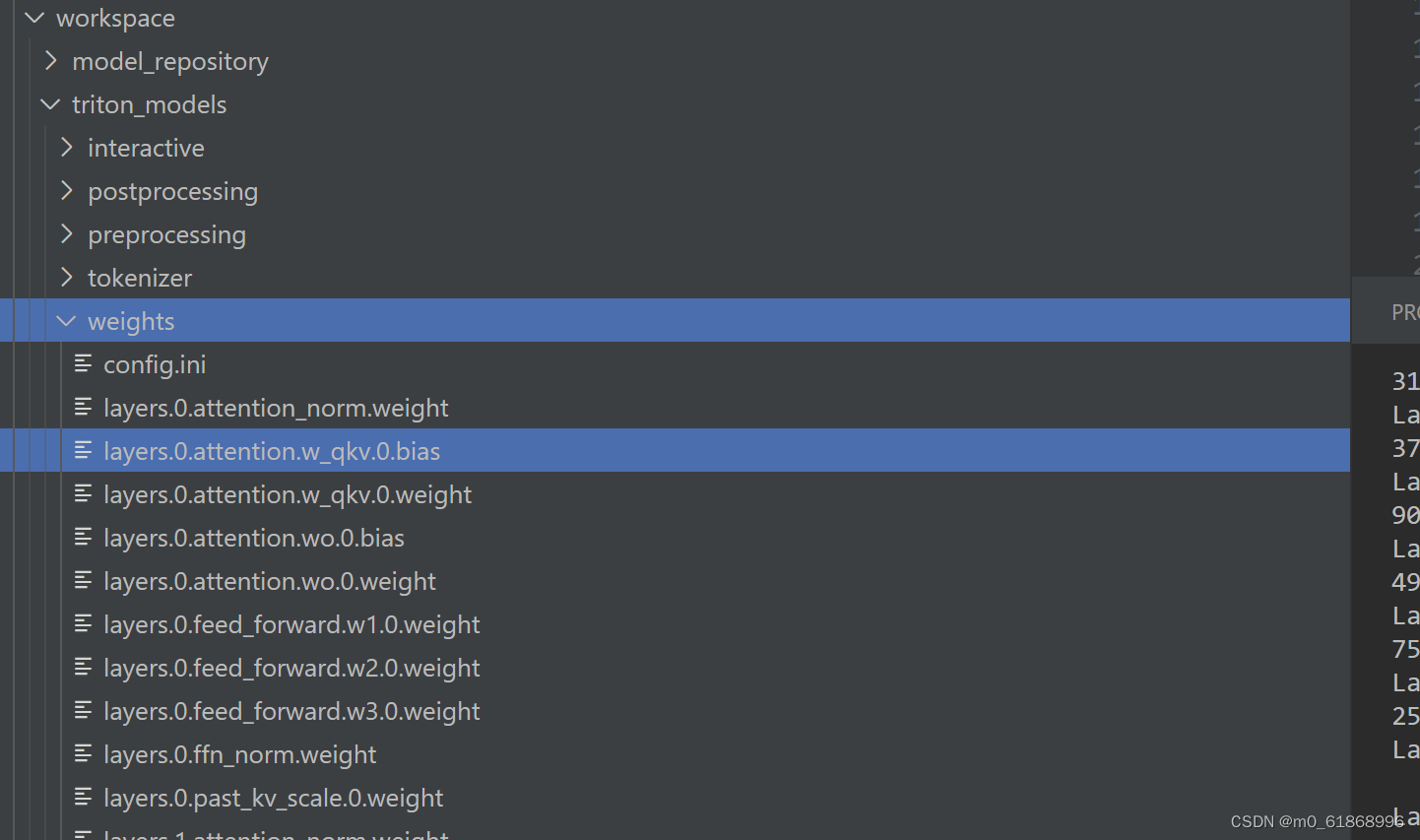
转换:
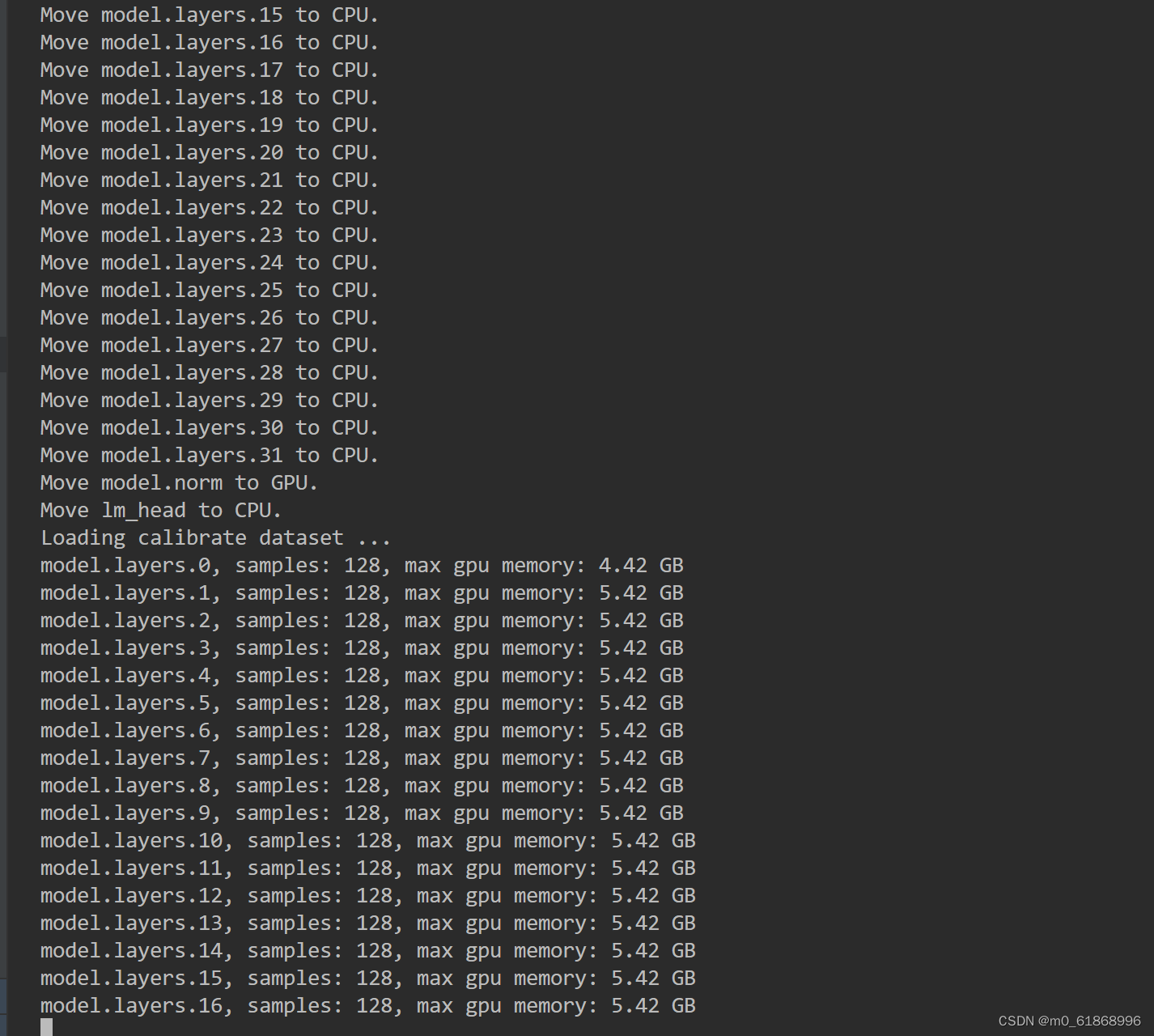
量化后的模型评估:
运行后查看显存占用:
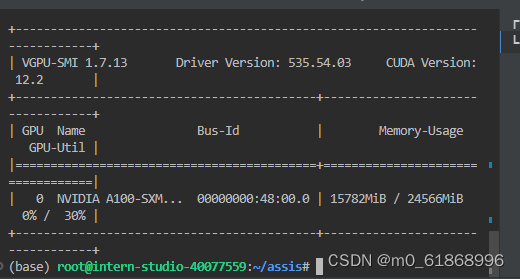
可以看到显存只需要15G了,而且手动测试回答的速度变快了很多,基本输入后输出全部内容间隔不超过1秒















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









