







he file lock 'D:\Download\anaconda\anaconda_exe\envs\python36\lib\site-packages\tldextract\.suffix_cache/publicsuffix.org-tlds\de84b5ca2167d4c83e38fb162f2e8738.tldextract.json.lock' could not be acquired.
大概问题就是在目录下面publicsuffix.org-tlds文件打不开
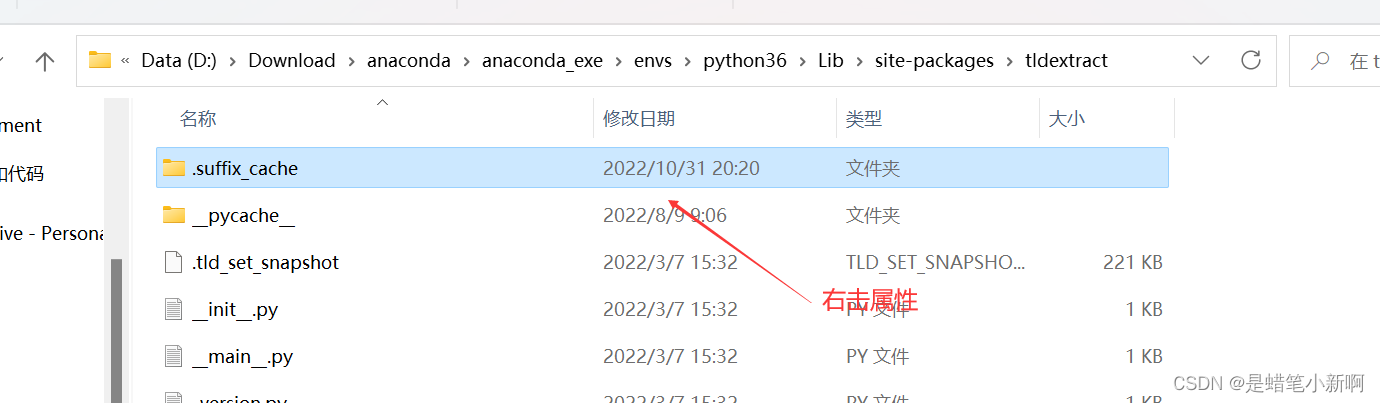
把.suffix_cache文件删掉就好了,之后再重新创建一个相同的文件
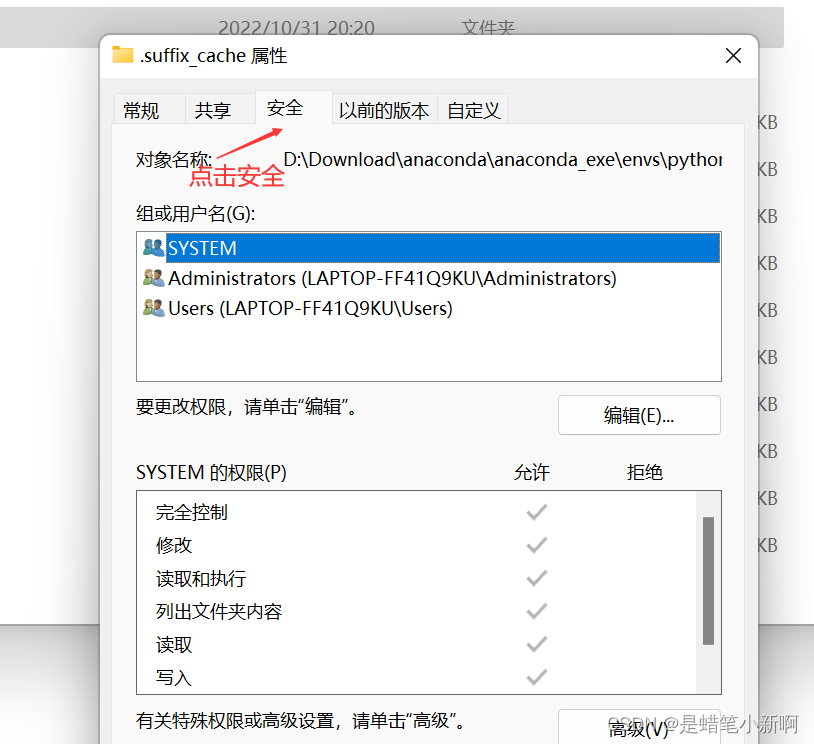
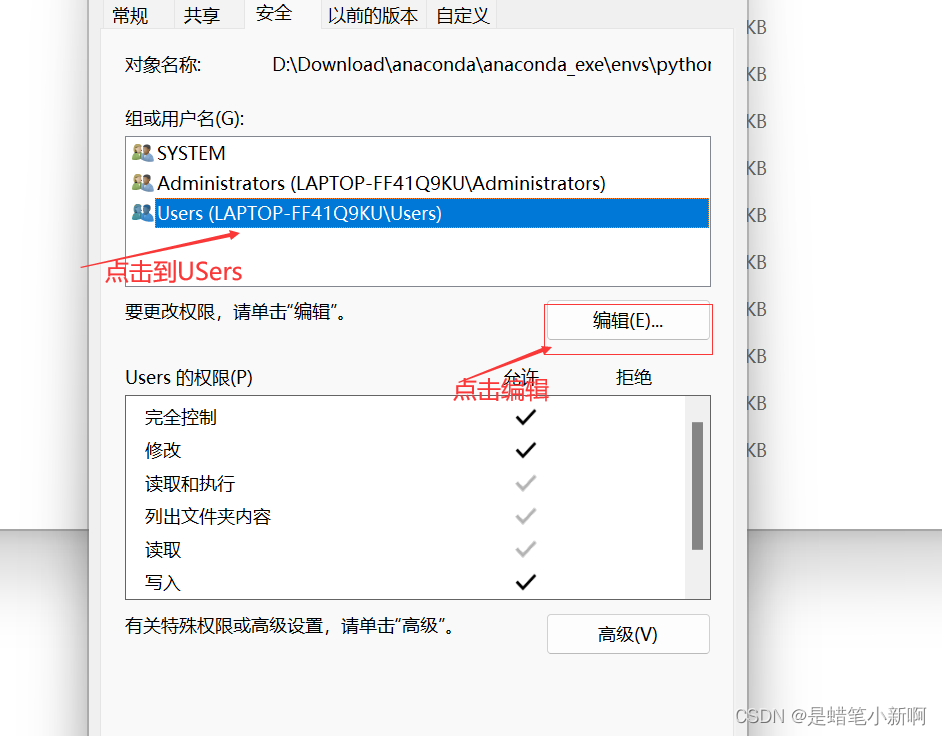
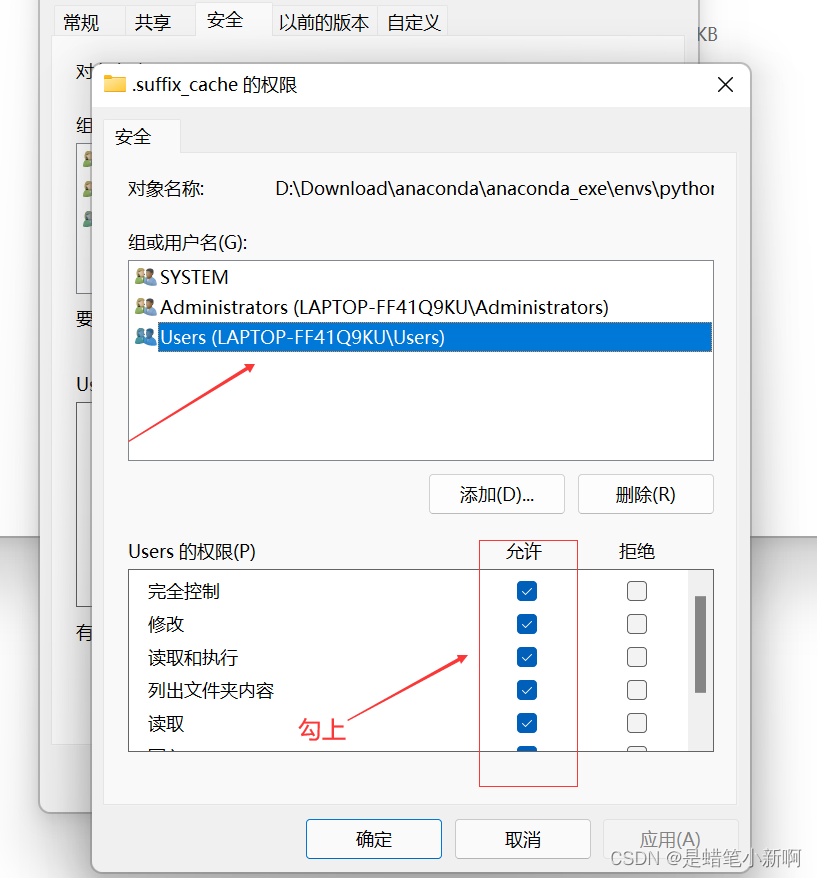
创建好之后,最好设置一下文件的属性,以免再报相同的错误,或者其他的错误















 5588
5588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









