






一、概要
这篇文章主要解决的问题是如何有效减少基于机器学习的恶意流量检测系统中的误报问题。误报指的是由良性流量错误触发的警报,这类问题在实际部署中会导致高成本的资源浪费,并对良性流量造成干扰。而对于误报这种情况是需要专家进行手动分析假阳性的,这会导致一个巨大的劳动成本。
文章提出了一个名为pVoxel的新型无监督学习方法再不需要先验知识的情况下识别误报。
具体而言就是把与报警相关的交通特征向量视为交通特征空间中的一个点,用点云分析来捕获各个点之间的拓扑特征。他通过把alarm都聚合成一个高位立方体(体素),通过密度特征来实现显示假阳性。
二、问题背景
这篇文章主要解决的问题是如何有效减少基于机器学习的恶意流量检测系统中的误报问题。
误报(FP,False Positive)指的是由良性流量错误触发的警报,指的是由系统错误地将正常或良性的网络流量识别为恶意流量的情况。
这类问题在实际部署中会导致高成本的资源浪费,并对良性流量造成干扰。
三、相关工作
现有研究通过重新训练或使用白名单来减少误报。具体对比如下表所示:
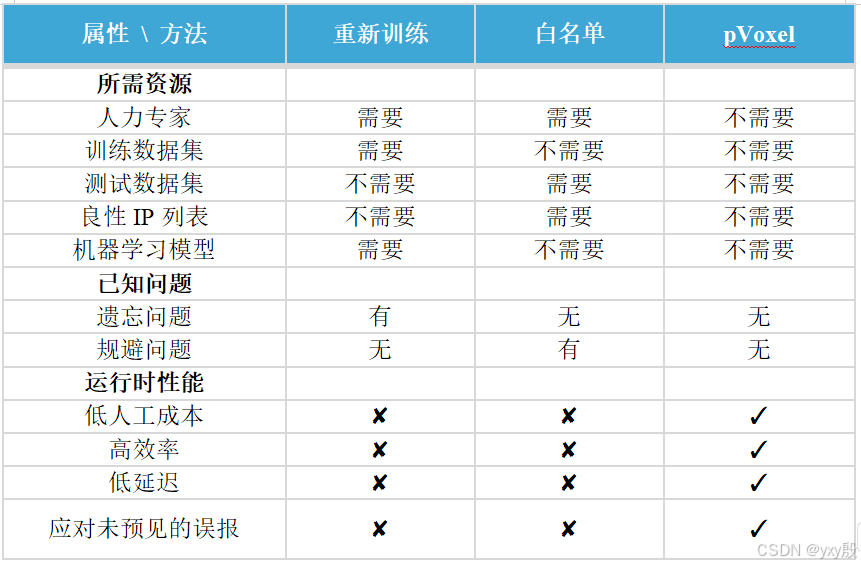
总体而言,这些方法需要人工专家付出巨大努力来识别大多数误报。例如,重新训练方法需要手动识别误报并将它们包含在训练集中以重新训练模型,而白名单方法根据手动识别的误报制定固定规则来排除类似的误报。然而,由于警报数量众多,几乎不可能手动识别误报。此外,这些方法仅减少与手动识别的误报相似的误报警报,但无法处理无法由专家识别的未预见的误报警报。
总的来说这篇文章解决的问题就是在机器学习(ML)方法用于网络安全中恶意流量检测时面临的高假阳性率(False Positive Rate, FPR)问题。
因此整个模型设计的目标如下:
(1)这个框架能够在不获取的任何关于流量监测系统的信息的情况下
(2)这个框架能够在事先不知道测试数据集任何先验知识的情况下
(3)需要低延迟
也就是说,pvoxel只能根据检测到的流量的相关特征来识别误报。
pVoxel可以在检测系统的测试阶段识别误报(FP),而不影响模型的训练过程。也就是说,pVoxel并不需要参与到模型的训练之中来识别误报,避免了对原有模型训练流程的干扰。然而,如果需要,也可以将pVoxel集成到检测方法的训练流程中。这样的设计能够避免“灾难性遗忘”(即模型在重训练后丧失对某些原有特征的识别能力)等问题。
四、模型假设
1. 机器学习(ML)基础的恶意流量检测系统通常部署在安全操作中心(SOC),使用各种ML模型来处理通过端口镜像(如Cisco SPAN技术)从网络设备复制的互联网流量。
具体过程:我们假设安全运营中心(SOC)使用各种基于机器学习的恶意流量检测系统,这些系统通过端口镜像(例如 Cisco SPAN【19】)从不同路由器中复制的互联网流量数据中进行检测。当这些系统接收到复制的流量后,它们会为每条流量(例如流量完成时间)或每个数据包(例如包长度)提取一个流量特征向量,并利用机器学习模型判断这些特征向量代表的流量是正常还是恶意流量。一旦检测系统将特征向量分类为恶意流量,它们会将特征向量发送到安全信息和事件管理系统(SIEM),触发可能是“真警报”或“误报”。
2.误报识别方法:将一批警告输入,例如在20秒内生成的告警,并根据与每个告警相关联的特征向量将其分类为真警报或误报。最后,它会在安全信息和事件管理系统中对真警报设置高优先级,使SOC(安全运营中心)操作员能够立即响应攻击流量。
3. 假设攻击者可能使用不同的技术和策略来逃避检测或欺骗流量监控系统。也就是说能够发起规避攻击(也就是能够伪装成正常的行为)。
五、解决方案
pVoxel的目标就在于:自动化地识别假阳性警报,无需任何先验知识或人工干预。强调pVoxel的设计旨在克服现有方法的局限,提高恶意流量检测系统的实用性和效率。
5.1 设计动机
(1)正常流量(即假阳性警报所对应的流量)在特征空间中通常呈现出稀疏分布,因为它们是由多种多样的正常用户行为产生的。相反,由攻击工具生成的恶意流量特征则呈现出密集分布,因为这些流量往往具有高度相似的特征
(2)在此基础上,作者观察到可以通过分析流量特征向量在特征空间中的分布密度来区分FP和TP。密集区域的特征向量更可能表示真正的恶意流量(TP),而稀疏区域的特征向量则可能对应于误报(FP)。
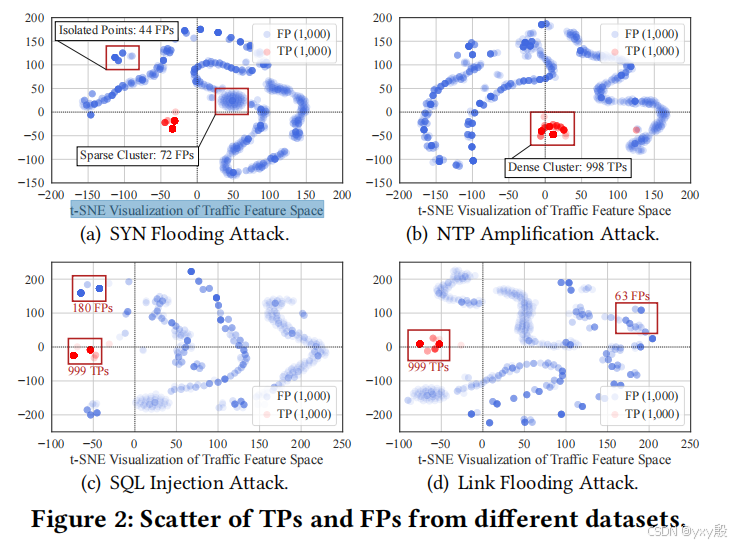
作者使用t-SNE算法生成的散点图,横纵坐标代表的是经过t-SNE处理后的两个主要维度。这两个维度不是原始数据的具体特征,而是由t-SNE算法从高维数据中提取出来的两个最能代表数据分布的新维度。
t-SNE算法学习链接:算法金 | 一个强大的算法模型:t-SNE !!-CSDN博客
构建体素(voxels)的目的在于将复杂和高维的数据集组织成更易于管理和分析的形式。而网络流量数据一般都非常大,为此,pVoxel将与每个警报相关的特征向量视为流量特征空间中的一个点。特别是,它利用点云分析来捕捉这些点之间的拓扑特征,并以无监督的方式学习这些特征,这使得pVoxel能够在无需任何预先知识(例如,手动识别的误报)的情况下识别误报。
5.2 解决方案设计
pVoxel的解决方案分为3步:构建体素、分配社区、密度分析。



5.3 理论证明
证明的目标:pVoxel可以通过检测位于低密度区域的体素识别出误报;同时,pVoxel 确保通过检测位于高密度区域的体素来准确保留真阳性(TPs)。
理论论证的基本思想:
(1)将包序列(良性的、恶意的流量)建模为随机变量序列
(2)特征提取方法作为随机变量的函数,表示提取特征的集合分布
(3)计算一个体素表示的点的期望密度。
具体思路:每种特征提取方法(例如“sum”和“avg”)被视为一个数学函数作用于随机变量上,通过统计学工具来计算这些特征函数生成的“点”的期望密度,可以推导出良性流量(FP)和恶意流量(TP)在特征空间中的密度差异。
首先建立了交通特征空间的密度模型,旨在从随机几何的角度来分析以体素表示的交通特征向量的密度。
首先把原来的流量集合S视作随机变量,根据现有的研究,S中的每个元素都服从正态分布,此外假设在处理签已经对所有的流量特征进行了归一化处理。
Q:为什么说S中的每个元素都服从正态分布?
A:可以方便后续进行计算,且在许多情况下,网络流量数据是多种因素共同作用的结果,而中心极限定理表明,当大量独立随机变量累积时,其总和会接近正态分布,因此流量特征在某些聚合层面上可能接近于正态分布,即便单个数据包不符合这一假设
接着文章把流量级的特征提取方法表示为函数fe,能够把si转变为单一随机变量vi,那fe就可以把每个数据包的长度累加起来得到整个流量的大小(有论文依据)。这里使用的特征提取方法Wie,sum, avg, min, range, var。
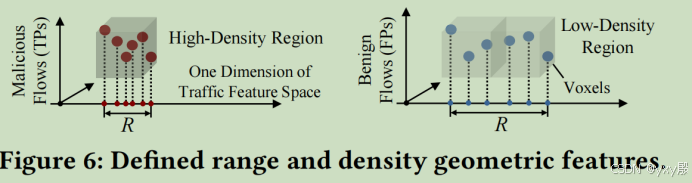
 为了符号简洁,作者每次只分析其中一个流量特征作为整个流量空间的维度,在这里将流量特征点表示为随机分布在无限直线上的点(这只是一个方便的数学模型),因此所有非空的体素空间的平均密度应该等于整个范围R的平均密度。那么整个区间密度就可以用单个体素的密度来估计。
为了符号简洁,作者每次只分析其中一个流量特征作为整个流量空间的维度,在这里将流量特征点表示为随机分布在无限直线上的点(这只是一个方便的数学模型),因此所有非空的体素空间的平均密度应该等于整个范围R的平均密度。那么整个区间密度就可以用单个体素的密度来估计。
正常流量由各种复杂的用户行为触发,具有多样化的模式。因此正常流量的方差一定大于恶意流量的方差,并且通过之前的研究,可以得到正常流量的长度是大于恶意流量的长度的。从这些分析中可以推导以下定理。
(1)当特征函数为sum的时候,FP和TP对应的期望点的密度比率为:
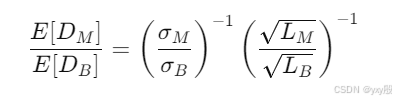
(2)当特征函数是AVG的时候并且LB/LM是常数的时候(LB是指正常流量的长度,LM是值恶意流量的长度),这个密度比率与正常流量的的方差/恶意流量的方差乘反比。
(3)当特征函数为range的时候,体素的期望点目睹的上限为:




可以看到,这几个定理里面表示TP的点通常密度更高,原因是触发TP的攻击流量通常由攻击工具生成,这些工具产生许多相似的短流。
此外正常用户行为生成了多种复杂的长流量,导致FP点分布稀疏。pVoxel通过检测低密度区域中的孤立点和低密度社区来捕捉这些特征。
这些理论分析与真实实验的结果一致,验证了pvoxel在误报识别中的有效性。
5.4 高适应性
pVoxel 系统的适应性,即它不仅能够处理流量级特征的检测方法,还能够适应其他特征类型的检测方法。这一点对于网络安全中的误报检测至关重要,因为不同的检测方法依赖于不同类型的特征(如包级特征、频率域特征和图结构特征)。
pVoxel 的适应性通过以下几个关键步骤实现:
包级特征的处理:在面对包级特征时,pVoxel 通过将多个包的告警合并为单一流的告警,以减少告警的数量。通过这种方式,pVoxel 能够有效地管理大规模的包级告警,减轻系统的处理负担。
频率域特征的转换:对于基于频率域的检测方法,pVoxel 通过将特征矩阵转换为标量,使其能够像处理流量级别特征一样处理频率域特征。这种转换使得系统在处理不同特征时具有统一性。
图结构特征的应用:图结构特征被用来表示复杂的攻击流量模式,通过提取源和目的节点的入度和出度,pVoxel 能够准确捕捉这些特征,进而检测和识别误报。
六、实验
实验的目的是为了能够证明pvoxel的以下五个能力:
(1)识别不同数据集上的不同方法提出的FPS
(2)对具有不同参数设置的ML模型具有鲁棒性(什么鲁棒性)
(3)他是比原有的传统方法要好的
(4)低延迟切高处立吞吐量
(5)能够在逃避攻击下实现较高的鲁棒性
6.1 实验设置
数据集来源和种类:实验使用了8个不同网络中的75个实际攻击,涵盖了多个公开数据集,如CIC-IDS2017、CIC-DDoS2019、Kitsune、NetBeacon、Whisper和HyperVision等。其中无监督方法的误报数高于有监督方法,而基于频域和图的检测方法因仅对相同IP地址流量告警,误报数较少。
攻击方式:实验中将数据集按原始数据包速率重放,以生成告警并测试检测方法。
超参数的选择:为了防止超参数偏移,选择进行了四倍交叉验证。在收集完报警信息后,警报被平均分为四个子集,每一个子集都被用做事验证集来调整参数,最后取四组的平均值。
实验指标:在这里对于有效性的评估是通过使用减少假阳性率(R. FPR)和减少假阳性的数量(R. FPN)来评估pVoxel的有效性。除此之外还有此外,还使用了广泛应用于机器学习流量检测系统的准确性指标,包括:
实验结果
- · AUPRC(精确召回曲线下的面积):用于评估在各种阈值下精确率和召回率的关系。
- · AUROC(接收者操作特征曲线下的面积):用于衡量分类器的整体性能。
- · F1分数:精确率和召回率的调和平均数,平衡了两者的权重。
- · Acc.(准确率):正确分类的比例。
- · Pre.(精确率):分类为正例的样本中,实际为正例的比例。
- · EER(等错误率):假正率和假负率相等时的错误率。
- · MCC(Matthews相关系数):用于二分类问题的衡量指标,综合了TP、TN、FP和FN,能够更准确反映模型表现。
-
6.2 准确率评估
-
实验目的
本实验的主要目的是验证pVoxel在减少误报(False Positive, FP)方面的准确性,以及它在不同检测方法和攻击数据集上的通用性和有效性。实验还旨在评估pVoxel在不误分类真实正例(TP)的前提下提升检测精度的效果,并验证其在无需人工标记或先验知识的情况下减少误报的潜力。
实验过程
- 误报率(R.FPR)测试:测量pVoxel在11种检测方法中的FP减少率。具体分析了pVoxel在不同流量特征提取方法(例如流量、数据包、频域和图特征)上的表现。
- FP数量(R.FPN)测试:测量在不同数据集中pVoxel减少的FP数量。
- TP减少率(R.TPR)测试:测量pVoxel在减少FP时是否会错误地将TP分类为FP。记录了各数据集中被误分类的TP数量。
- 精度提升指标测试:通过PRC和ROC曲线的AUPRC和AUROC值来量化pVoxel的精度改进,还包括其他准确性指标及EER的减少幅度。
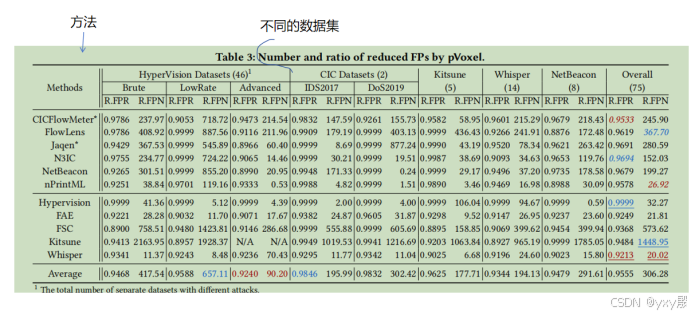
- 误报减少效果:pVoxel在所有检测方法中平均减少了95.55%的误报率(R.FPR),且在监督和非监督方法上分别减少了95.33%~96.94%和92.13%~99.99%的误报。此外,在不同特征类型的数据集中,pVoxel对误报的减少效果在92.49%~99.99%之间。
- 误报数量减少:在实验中,pVoxel平均每秒减少306.28个FP,且在Whisper等方法中成功减少大部分误报,使人工分析的负担大大降低。
- TP误分类控制:pVoxel在减少FP的同时,仅误分类了少量TP,平均减少TP的比率(R.TPR)为2.62%。例如,在CICFlowMeter检测HTTP探测和TLS漏洞时,误分类的TP数量仅为41和72个。
- 整体检测精度提升:pVoxel显著提高了检测系统的多项准确性指标,例如AUPRC和AUROC分别提升了1.27%~33.66%和0.43%~40.45%;精确率、准确率、F1和MCC分别提升了44.72%、5.73%、22.85%和96.90%,且EER减少了67.40%。
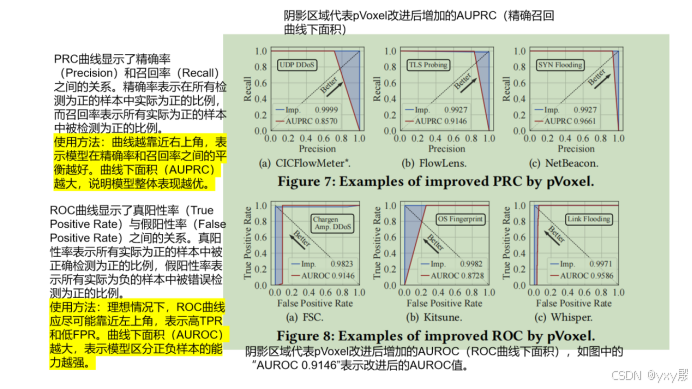
实验解读
实验结果表明,pVoxel能够有效地减少FP而不显著影响TP。这主要是因为pVoxel能够利用特征空间中点的拓扑特征,通过体素(voxels)表示高密度区域的点,区分由恶意流量引起的FP和正常用户行为触发的FP。此外,pVoxel的无监督方法无需依赖人工标记或先验知识,因此在实际部署中表现出更高的通用性和适应性。这一结果表明,pVoxel在减少误报和提升检测系统性能方面具有显著优势。
6.3 鲁棒性评估
实验目的
评估pVoxel在应对不同机器学习模型和不同超参数设置下的鲁棒性,即pVoxel是否能够有效减少由各种模型引发的误报并维持高准确性。
实验设置
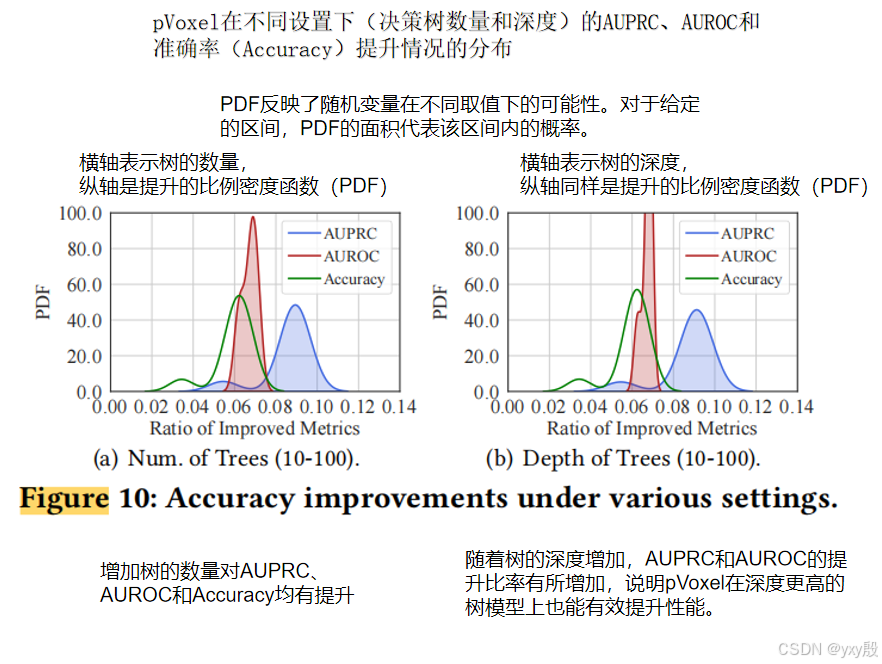
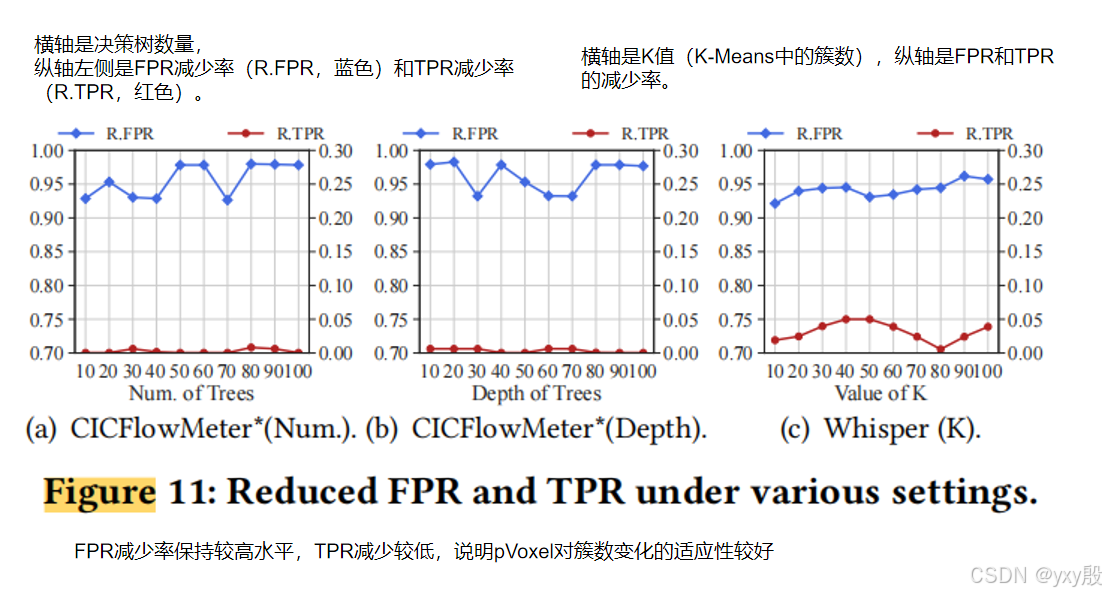
研究者在HyperVision数据集上使用了九种不同的机器学习模型,这些模型包括监督和无监督的各种模型,并基于CICFlowMeter特征进行分类。这些模型涵盖了多种现有的检测方法,确保了实验对pVoxel在不同模型下性能的全面考察。为了进一步测试pVoxel的鲁棒性,实验还调整了随机森林(RF)模型和K-Means模型的超参数,特别是树的数量、深度以及K值等参数。
实验结果
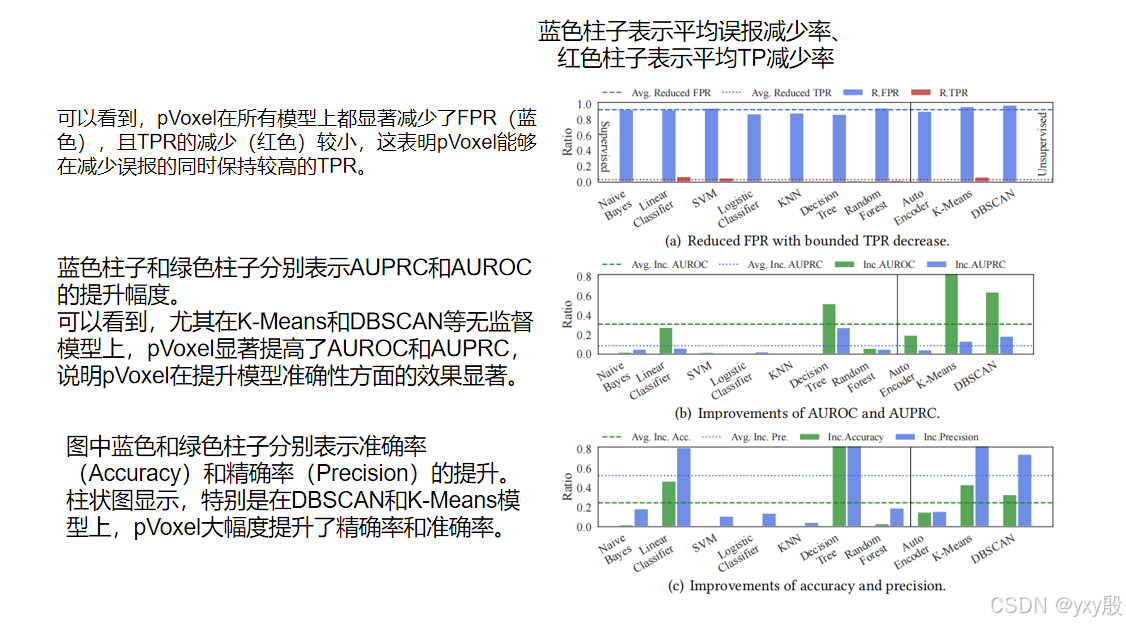
FPR和TPR的减少:实验结果显示,pVoxel在各种机器学习模型上的误报率(FPR)减少范围在87.20%至99.05%之间,展示了其强大的误报减少能力。同时,pVoxel对真警报(TPs)的减少(TPR)平均值较低,保持在合理范围内,表明其在降低误报的同时不会显著误判真警报。
实验结果的意义
实验结果表明pVoxel具有高度的鲁棒性,不受模型类型和超参数设置的显著影响。
这种鲁棒性归因于pVoxel将检测系统视为黑盒,无需依赖模型的先验知识,而是基于流量特征空间中的拓扑特性来识别误报。这种方法确保了pVoxel在多种实际场景中都能可靠工作。
6.4 比较试验
实验目的
将pVoxel与传统的重新训练方法进行比较,检验在部分FP(误报)被手动标识并加入训练集进行重新训练的情况下,pVoxel是否能够更有效地减少FP。此外,实验还评估了pVoxel是否能避免重新训练过程中常见的“灾难性遗忘(catastrophic forgetting)”问题,进而提升检测模型的性能。
实验设置
重新训练方法的对比:随机选择25%、50%和75%的FP,并将相同比例的TP(真实正例)一起加入训练集中,对ML模型重新训练。重新训练后的模型在原测试集上再次进行流量检测(不包含用于重新训练的样本)。
与灾难性遗忘缓解方法的对比:使用带正则项的缓解方法来重新训练三种基于DNN的检测方法。设置不同的λ值(正则项权重)来调节正则化效果,以观察其对FP和TP的影响。
带正则项的缓解方法是一种在模型训练中添加正则化项以减轻或避免灾难性遗忘的技术。这种方法通过在损失函数中加入额外的约束来调节模型参数的更新,以便在学习新任务时尽量保留旧任务的知识。
灾难性遗忘是一种在机器学习(尤其是神经网络)模型重新训练或增量学习中常见的问题。当模型在新数据上进行训练时,它往往会“遗忘”之前学到的知识,从而导致对旧数据的表现变差。
与白名单方法的对比:评估传统白名单方法减少FP的效果,并比较其与pVoxel的效果。
白名单(Whitelist)是一种安全策略,用于允许经过信任验证的实体(如IP地址、域名、应用程序或用户)访问系统资源或执行特定操作。相对于阻止特定不可信实体的黑名单策略,白名单是通过明确允许哪些可以访问的实体来提升安全性。
实验结果
-
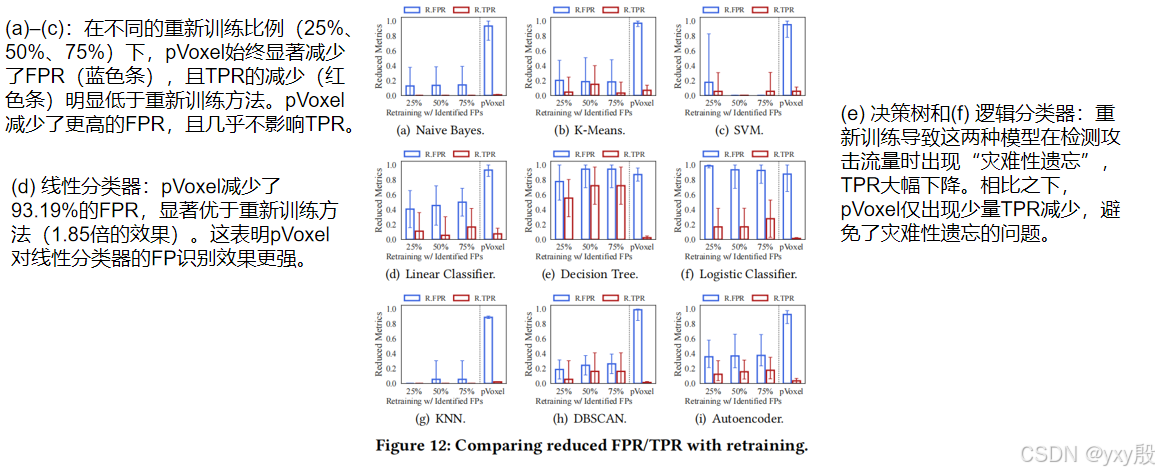
与重新训练方法的对比:pVoxel在减少FP方面效果显著,平均减少了2.51倍的FP,且TP减少率仅为重新训练方法的1/4。例如,在线性分类器上,pVoxel减少了93.19%的FP,比重新训练的最佳效果高出1.85倍。图12展示了pVoxel与重新训练方法在不同模型上的FPR和TPR变化情况。
- 重新训练方法在决策树和逻辑分类器上出现“灾难性遗忘”,即模型在重新训练后无法有效检测攻击流量,导致TPR显著下降。
-
与灾难性遗忘缓解方法的对比:pVoxel在减少FP方面优于灾难性遗忘缓解方法,FP减少率提升了79.36%至84.64%,且TPR保持相似水平。特别是当λ值较大时(如λ = 5 × 10^4),模型的参数几乎不更新,导致重新训练方法无法进一步减少FP。
-
与白名单方法的对比:传统白名单方法在减少FP方面效果有限,因为大部分FP并非由信誉良好的组织流量触发。例如,根据实验结果,少于0.1%的FP是由Alexa排名前100网站的AS(自治系统)流量引起的,而pVoxel不依赖白名单,避免了白名单可能带来的IP欺骗等问题。
实验结果的意义
pVoxel之所以在减少FP方面优于重新训练方法,是因为它不依赖模型的重新训练过程,避免了“灾难性遗忘”问题。pVoxel将机器学习检测模型视为“黑盒系统”,基于流量特征空间的拓扑关系来识别FP,因此不依赖于任何先验知识(如手动标注的FP、训练数据集或模型的原始参数)。
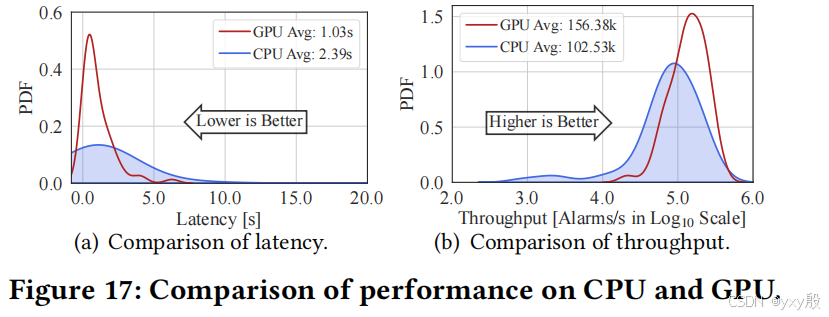
6.5 吞吐量和延迟评估
实验目的
这是为了pVoxel在处理大量误报时的吞吐量和延迟表现。通过测量pVoxel在一秒内能处理的警告数量和处理每个警告所需的时间,验证其在实际应用中应对海量数据的适用性。
实验设置
- · 吞吐量测量:实验测量了pVoxel在一秒内能够处理的告警数量。实验涉及多种检测方法,包括流量级、数据包级、图形和频率特征方法,并分别记录了这些不同方法下的吞吐量表现。
- · 延迟测量:实验测量了pVoxel处理每个告警的平均延迟时间,进一步细分了在不同特征数据(如流量、数据包、图形、频率特征)上的延迟,以观察不同特征方法对延迟的影响。
- · 模块化延迟分析:pVoxel的工作流程被分为三个模块(体素构建、社区构建和密度分析),并分别测量了每个模块的延迟,以了解各模块对总延迟的贡献。
- · GPU与多核CPU实现对比:为了提升效率,实验还对比了pVoxel在GPU和多核CPU并行C++实现下的表现,观察不同硬件实现对延迟和吞吐量的影响。
实验结果
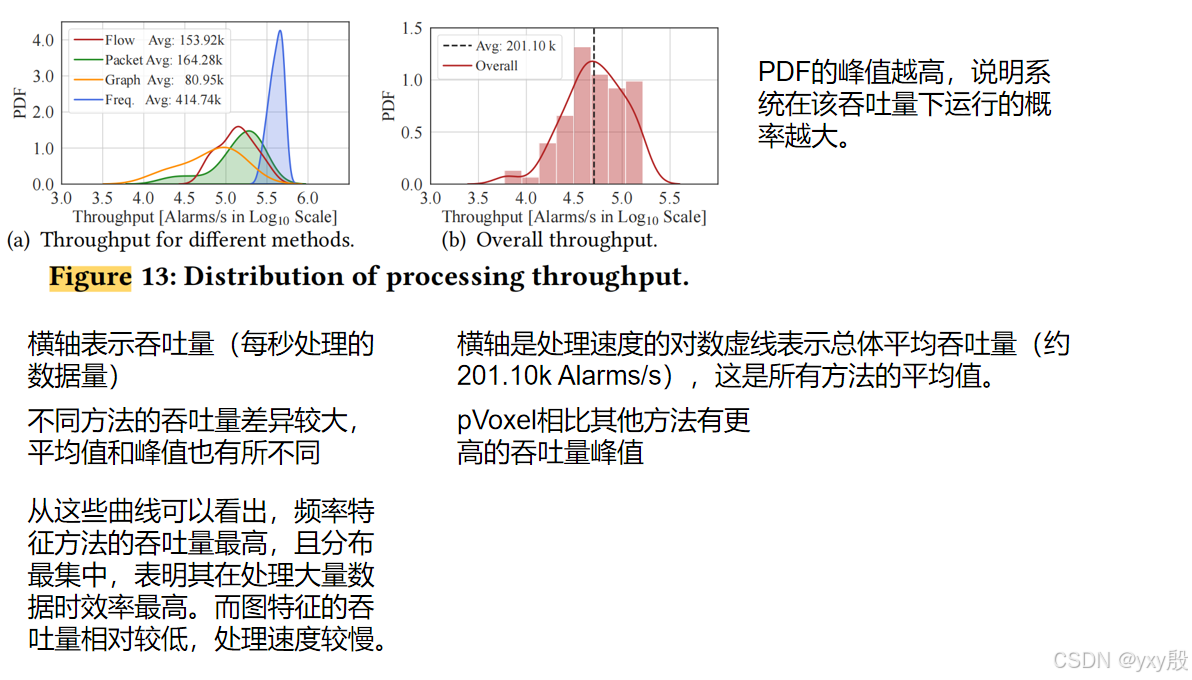
- 吞吐量:实验结果表明,pVoxel在不同特征方法上达到了较高的吞吐量。例如,基于频率特征的方法可实现每秒414.74k的告警处理,平均吞吐量超过201.10k告警/秒。
- 延迟:pVoxel在不同特征方法上的平均延迟分别为0.779秒(总体),其中基于流量和数据包特征的方法延迟较高(约0.946秒和1.310秒),而基于图形和频率特征的方法延迟显著较低(约0.116秒和0.002秒)。
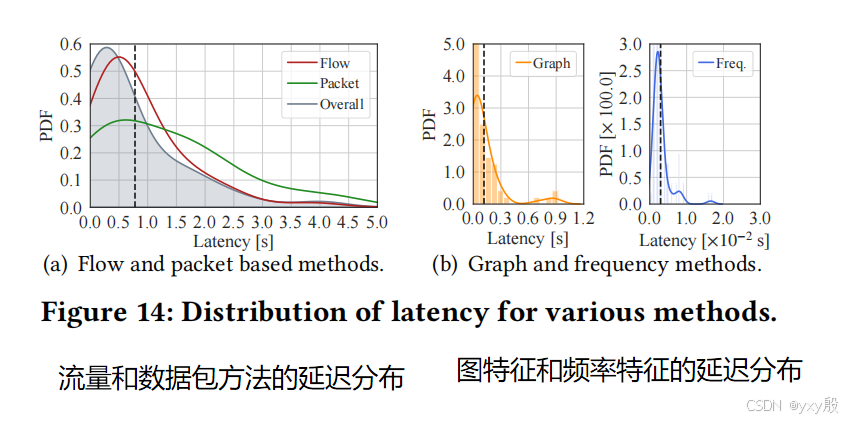
- 模块化延迟分析:三个模块中,体素构建模块消耗了大部分时间(64.07%),而社区构建和密度分析模块的延迟相对较小,分别占19.41%和16.50%。

- GPU vs. 多核CPU:GPU实现比CPU实现减少了56.90%的延迟,且吞吐量比CPU高出1.52倍。这表明在处理大规模数据时,使用GPU加速可以显著提升pVoxel的效率。
6.6 应对逃避攻击
实验目的
攻击者无法通过简单地模仿正常用户来轻易规避pVoxel的检测。
实验设置
具体而言,我们根据最近的研究验证了pVoxel对三种规避技术的鲁棒性:
(i) 流量混淆:在恶意流量中注入正常流量;
(ii) 自适应流量速率:攻击者调整数据包速率以模仿正常流量;
(iii) 操控流量特征:攻击者操控数据包长度以生成正常的流量模式。
需要注意的是,这些自适应攻击可以绕过许多现有方法,这些方法在规避攻击下不会产生告警。因此,我们收集了三种现有方法在规避攻击下引发的告警,并使用pVoxel分析这些告警。规避攻击生成的流量仍然位于高密度区域,因此这些高密度区域仍能被pVoxel有效捕捉。
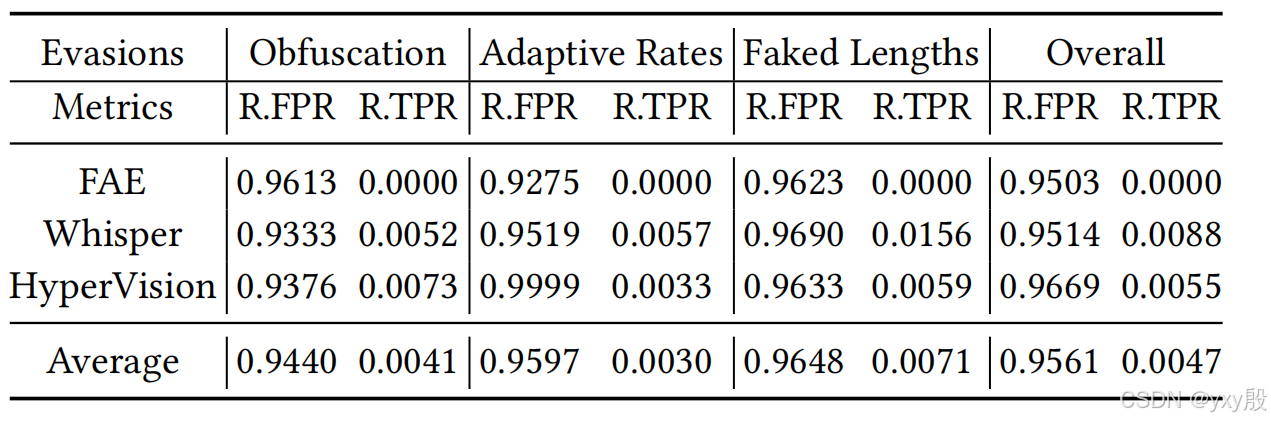
表格展示了pVoxel在面对不同规避攻击(Evasion)手段下的误报率减少(R.FPR)和真警报率减少(R.TPR)的表现。具体来说,表格列出了在三种规避攻击技术(流量混淆、速率自适应和伪造长度)下的R.FPR和R.TPR,数据分为三种检测方法(FAE、Whisper和HyperVision)以及平均值(Overall和Average)进行展示。
高误报减少率(R.FPR):pVoxel在所有检测方法和规避攻击下都表现出较高的误报减少率,说明它能够有效识别并排除误报。
低真警报误判率(R.TPR):pVoxel在所有情况下的R.TPR都非常低,表明在面对规避攻击时,pVoxel能够保持对真警报的准确识别,几乎不受规避技术影响。
总体来说,表格展示了pVoxel在不同规避攻击方式下的鲁棒性,说明即使攻击者尝试伪装恶意流量为正常流量,pVoxel依然能够高效识别出误报而不影响真警报的检测。
七、总结
(1)这是一种基于密度分析的流量监测模型。但是实验表明不能够直接分析流量密度,因为这会导致高延迟和低精度。所以povel只分析了警告的流量。
(2)pvoxel可以促进模型再训练。他可以将误报的流量作为输入进行再培训pVoxel通过在测试阶段进行误报检测,避免了对训练流程的依赖。这意味着pVoxel不需要知道系统在训练阶段用到的数据和模型参数,也不需要参与模型的训练。这种方式使得pVoxel可以与闭源系统兼容,在不改变现有检测系统的前提下减少误报。
使用范例
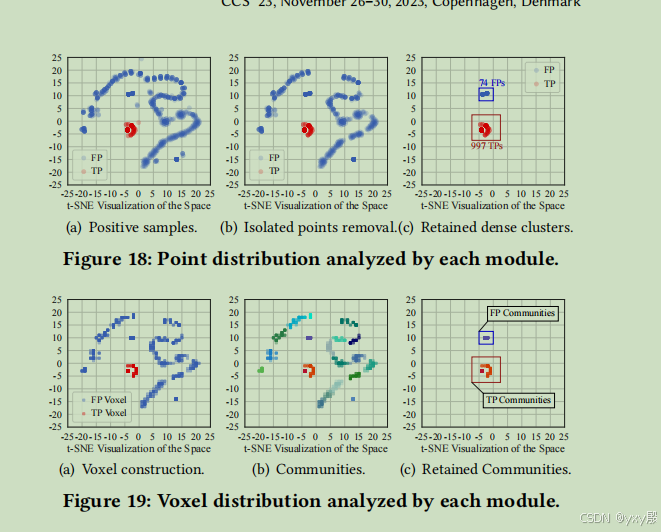
我们从TLS漏洞利用数据集【31】中,随机选择了CICFlowMeter生成的1,000个真警报(TPs)和1,000个误报(FPs)。CICFlowMeter提取了84种流量特征【15】(例如数据包/字节数量、流量持续时间),并在这些特征向量被分类为攻击流量时产生警报。pVoxel对这些警报进行分类,区分出真警报和误报。我们使用t-SNE将高维特征映射到二维进行可视化,并绘制了表示警报的点和体素,分别在图18和图19中展示。
pVoxel的第一个模块构建了196个体素,用于表示这2,000个警报点。为了排除孤立点,pVoxel识别出38个代表稀疏分布点的体素,例如每个体素包含少于8个点。最终,1,809个保留的点由158个体素表示(见图18(b)和图19(a))。与此同时,191个孤立点被排除,其中包括3个真警报和187个误报。需要注意的是,这3个真警报之所以被误分类,是因为它们的流持续时间特征显著更高。这三个点偏离了其他攻击流量点,因此被标记为误报的孤立点。我们推测这些流量是用来检查受害网站的可达性,因此与实际的漏洞利用流量有所不同。
pVoxel的第二个模块将体素合并为19个社区,这些社区在图19(b)中展示;最后一个模块识别出16个代表稀疏误报聚类的社区,这些社区密度较低,即每个社区包含22到57个点。pVoxel将其他三个社区标记为真警报,这些社区的密度显著更高,例如每个社区包含908个点(见图19(c))。
(见图18(c))。最终,pVoxel将误报率减少了92.60%,真警报率的减少仅为0.30%,可以忽略不计。

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









